
基于比特重组快速模约简的高面积效率椭圆曲线标量乘法器设计
2024-01-27 06:57刘志伟杨晓秋陈冠百赵石磊
电子与信息学报 2024年1期
刘志伟 张 琦 黄 海 杨晓秋 陈冠百 赵石磊 于 斌
(哈尔滨理工大学计算机科学与技术学院 哈尔滨 150080)
1 引言
椭圆曲线密码(Elliptic Curve Cryptography,ECC)已经被美国国家标准学会(American National Standards Institute, ANSI)[1]、美国国家标准与技术研究所(National Institute of Standards and Technology, NIST)[2]、电气电子工程师协会(Institute of Electrical and Electronics Engineers,IEEE)[3]等国际标准组织广泛接受和部署[4],应用在各种各样的场景。在比特币的基础技术区块链中,广泛应用ECC中的secp256k1作为区块链的认证机制[5];我国自主研发的密码算法SM2密码标准,是国密体系中重要环节之一。ECC的应用日益增加,不同应用性能需求各异。例如在服务器和大型计算平台等,需要密码芯片具有较高的运算性能。在微控制器等设备中,一般要求密码芯片具有更小的面积。此外不同的标准通常使用不同的椭圆曲线,所以对多种曲线的兼容也一直是椭圆曲线的重点研究目标。
标量乘架构的研究成为热点,Hu等人[6]提出SCA-256曲线的二阶段快速模约简方法,利用半字乘法器5个周期计算大数乘法实现高速标量乘的设计;文献[7]和文献[8]都对wNAF算法进行了优化,降低了标量乘的计算复杂度,提高了标量乘计算速度;Liu等人[9]利用软硬结合的方式以较低的面积实现了支持任意曲线的双域ECC处理器;Hossain等人[10]设计了同时适用于专用集成电路(Application Specific Integrated Circuit, ASIC)和现场可编程逻辑门阵列(Field Programmable Gate Array, FPGA)的标量乘操作步骤,适用于两条曲线;Liu等人[11]优化了非相邻形式算法,以高资源消耗实现了支持P256的高速ECC标量乘设计;Hu等人[12]和Choi等人[13]都提出高度资源复用的设计,以极低的硬件资源实现标量乘法器;Zhang等人[14]改进了蒙哥马利阶梯算法,提出了支持SCA-256的抗功耗攻击的高性能处理器。文献[15]改进了基2交叉模乘算法,提出了一种高面积时间效率的新型标量乘法器架构。这些设计的时间面积(Area·Time, AT)普遍较差,部分仅适用于特定曲线,ECC处理器需要兼顾速度和面积两者之间的关系,为解决此问题本文提出了全新的设计。
本文提出了一种基于比特重组快速模约简的高面积效率ECC标量乘法器,支持secp256k1,secp256r1和SCA-256 3条曲线。本文的主要工作为:
(1)设计了一种兼顾乘法和模逆两种功能的硬件复用运算单元,提高硬件资源使用率。同时采用Karatsuba-Ofman算法提高运算单元计算性能;
(2)设计了基于比特重组快速模约简算法,实现了支持secp256k1, secp256r1和SCA-256快速模约简计算的硬件架构;
(3)优化了点加和倍点的模运算操作调度,使乘法和快速模约简排布尽量紧密,减少标量乘计算需要的周期数量。
2 研究背景
椭圆曲线有很多种,使用较多的是Weierstrass曲线[16]。这一类曲线满足式(1):
NIST提出的曲线secp256r1和secp256k1以及国密sm2密码算法提出的曲线SCA-256都属于Weierstrass曲线。
标量乘是ECC的核心运算,定义为kP=P+...+P。其中k是整数,P是椭圆曲线上一点。标量乘算法较多,主要有二进制标量乘算法、非相邻形式(Non-Adjacent Form, NAF)标量乘算法等[17]。NAF标量乘算法[18]如算法1所示,通过对k进行重新编码,减少k中非0元素出现的次数以达到提高标量乘性能的目的。
标量乘运算是由一系列的点加(Point Addition, PA)和倍点(Point Doubling, PD)操作实现的。假设P1=(X1,Y1,Z1),P2=(X2,Y2,Z2),P3=(X3,Y3,Z3)是椭圆曲线上的3个点,那么点加操作可以定义为P3=P1+P2,倍点操作可以定义为P3=2P1。为了避免模逆这一复杂的操作,通常使用转换坐标系的方式减少模逆的计算次数。仿射-雅可比混合坐标系可以产生更快的点加操作,雅可比坐标系可以产生更快的倍点操作[19]。
仿射-雅可比混合坐标系下的点加公式如式(2)所示:

算法1 NAF标量乘算法
雅可比坐标系下的倍点公式如式(3)所示:
3 标量乘法器设计
ECC应至少包含3个算术层:有限域运算层、点运算层和标量乘运算层,本节将按照标量乘法器的结构层次,自底向上介绍本文提出的标量乘法器设计。
3.1 资源共享的运算单元设计
本文使用计算速度较快的快速模约简模乘,该模乘分为整数乘法运算和快速模约简运算两部分,整数乘法运算性能对模乘影响较大。使用大位宽乘法器计算乘法只需要一个周期,但是需要消耗大量硬件资源,使用小位宽乘法器计算乘法虽然面积较小,但是需要较多周期计算乘法,速度较慢,因此选择大小合适的乘法器是设计该部分的关键。Karatsuba-Ofman算法[20]可以将两个256 bit的大数乘法转化为3个128 bit的乘法和一些加减及移位操作,如式(4)所示。
该算法虽然可以减少乘法大小,但是同样带来了额外一些额外的计算。为了减少这些额外的计算带来的影响,优化了Karatsuba算法的操作调度方式,如算法2所示。
本文提出的调度方式将式(4)分为3个周期进行计算,前两个周期使用乘法器和加法器可以得到a1b1,a0b0,a0+a1,b0+b1以及-(a1b1+a0b0)的结果,分别存入寄存器s,v,r和u中。第3个周期利用乘法器和加法器c1得到(a0+a1)(b0+b1)-(a1b1+a0b0)的结果。式(3)中可以看出(a1b12256+a0b0)可以通过位拼接直接实现,[(a0+a1)(b0+b1)-(a1b1+a0b0)]2128可以通过c1左移128 bit实现。c1左移128 bit后低位都为0,(a1b12256+a0b0)的低128 bit即a0b0的低128 bit,所以两者相加可以先舍去低128 bit,只相加剩余部分,通过加法器c2得到这一结果,然后将c2与a0b0的低128 bit进行拼接,可以得到最终的乘法结果C。
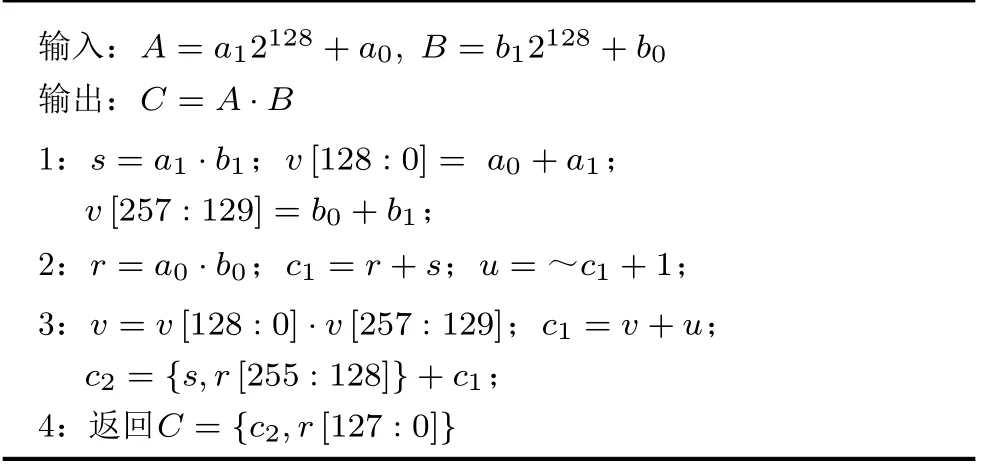
算法2 改进的Karatsuba算法操作调度
优化后的调度方式需要使用1个乘法器和2个加法器,以及4个存储中间结果的寄存器,经过3个时钟周期可以得到512 bit的乘法结果C。
为进一步提高设计的面积效率,本文提出了一种乘法与模逆可以实现资源共享的运算单元设计,此设计尽可能地复用加法器和寄存器实现乘法和模逆两种运算。模逆使用RS-A模逆算法[21],结合算法2及RS-A模逆算法设计出的新的运算单元如图1所示。此运算单元通过控制信号切换功能,当使用乘法功能时,进位保存加法器(Carry Save Adder,CSA)相当于算法2中的加法器c1,只需将第3个输入置0即可,加法器1相当于算法2中的加法器c2。然后根据算法2中的调度方式控制乘法器和加法器选择不同的输入实现乘法计算的功能,最后512 bit乘法结果分为高256 bit和低256 bit分别存入4个寄存器中,方便后续快速模约简模块进行比特重组。

图1 资源共享的运算单元
使用模逆功能时,CSA加法器负责RS-A模逆算法中加减模数p的相关计算,除2操作通过移位实现。加法器1负责RS-A模逆算法中的其他加减计算,除2也通过移位实现。然后根据RS-A模逆算法中的不同条件控制寄存器的输入输出选择和加法器的输入选择,最终实现模逆功能。
此运算单元在不同功能的各个工作阶段,通过数据选择器选择不同的数据来源,即可实现乘法功能或模逆功能。因为乘法和模逆运算过程中都需要使用加法器,所以两种运算不能同时进行。通过转换坐标系的方式,标量乘运算过程中模乘和模逆不会同时进行,所以不会影响整体性能。与文献[6]相比,我们提出的结构乘法速度更快,也不需要额外的资源实现单独的模逆;与文献[22]相比乘法运算消耗周期数相同,但本文资源共享的结构使得面积更有优势。
3.2 基于比特重组的快速模约简设计
模约简需要根据曲线特点进行单独设计,不能直接套用其他曲线模约简公式。对于secp256k1,p=2256-232-29-28-27-26-24-1=2256-232-210+26-24-1,p的位宽为256 bit。乘法结果最高为512 bit,将乘法结果表示为C=c1272508+c1262504+...+c124+c0,其中ci位宽为4 bit。根据p的特点,secp256k1有如式(5)同余关系式:
乘法结果的高256 bit可以通过式(6)右半部分的式子相加得到约简后的结果,然后再与乘法结果的低256 bitc632252+...+c0相加。将其按幂次由高到低排列,整理为和项和差项后,得到算法3。本文使用两个步骤完成secp256k1快速模约简的计算。首先第1步将乘法结果C分解为128个4位数据段,然后重组为s1~s16,此过程为比特重组。然后将重组后的16个数据段进行计算得到z1∈(-3p,8p)。第1步的结果可能产生进位或借位,所以第二阶段需要对其再进行处理。当z1大于0时,我们将z1高位补0然后重复一次第1步操作,约简结果z2∈[0,2p),最多还需要一次减法就能得到最终约简结果。当z1小于0时,通过最多3次累加可以得到最终约简结果。
文献[1 4]和文献[2 3]提供了S C A-2 5 6 和secp256r1的快速模约简公式,是将512 bit数据拆分为16个32 bit数据段,32 bit数据段可以进一步拆分为8个4 bit数据段,因此同样可以使用比特重组方法进行快速模约简算法的设计。
本文利用比特重组方法提出兼容3条曲线的快速模约简结构,如图2所示。比特重组模块根据不同曲线的快速模约简公式将乘法结果进行拆分与重组,华莱士树模块负责快速模约简算法中第1步和第2步中z1≥0时的计算,加法器阵列负责第2步z1<0时的计算。为减少资源消耗和路径延迟,将两个步骤的快速模约简分为3个时钟周期计算。首先第1个时钟周期利用比特重组模块将输入进行重组,重组为s1~s16,其中secp256r1只有s1~s11为有效值,s12~s16为全0。然后使用CSA加法器组计算快速模约简公式的第1步中的s1+s2+s3+s4+s5+s6+s7-s12-s13,减法通过补码加法实现,结果存入w中。第2个周期计算w+s8+s9+s10+s11-s14-s15-s16,结果存入w中,此时已经计算完毕z1。第3个时钟周期先判断w的符号位,若w ≥0则使用比特重组模块将w重组为t1~t4,然后使用华莱士树计算得到z2。若z2超过p-1则通过加法器完成减p操作。若w <0,则使用加法器阵列进行累加,通过判断每一级加法器中间结果的符号位选择正确的约简结果。

图2 兼容3条曲线快速模约简结构

算法3 secp256k1快速模约简算法
虽然快速模约简相比常规方式需要周期数更多,但是本文通过对点加和倍点的模运算操作调度进行优化降低了其负面影响,将在下一节详细介绍。
3.3 高速点加和倍点设计
标量乘运算通过点加和倍点运算实现,因此对于点加和倍点的优化也十分重要。仿射-雅可比混合坐标系下的点加和雅可比坐标系下的倍点公式模乘计算次数较少[22],结合上文中提出的设计对点加和倍点的模运算操作调度进行了优化。为使乘法与模约简的排布尽量紧密,减少标量乘运算所需周期数量,本文提出了倍点和点加两种操作合一的模运算操作调度方案。
倍点和倍点点加合一的模运算操作调度如图3所示,图3(a)为倍点的模运算操作调度,图3(b)为倍点点加合一的模运算操作调度。其中雅可比坐标系输入点(X1,Y1,Z1) 用(t5,t6,t7)表示,仿射坐标系输入点用(x2,y2)表示,得到的雅可比坐标系下点(X2,Y2,Z2)也用(t5,t6,t7),t1~t7为寄存器。

图3 高速点加和倍点的模运算操作调度
通过优化后的调度方法,1次模乘平均只需要3个周期,消除了因快速模约简计算需要3个周期带来的影响。标量乘运算过程中点加和倍点操作是连续进行的,我们提出的两种调度方式在最后3个周期可以开始下一次运算的第1次乘法,此时需要额外的周期计算第1次模加。故1次倍点平均需要27个周期,1次倍点点加需要60个周期。
3.4 总体设计
本文将secp256k1, secp256r1, SCA-2 563条曲线的标量乘集成为1个单元进行设计,图4给出了标量乘法器的硬件架构。标量乘法器由标量乘控制模块、倍点和倍点点加控制模块、NAF编码器、模运算单元和寄存器组5部分组成。
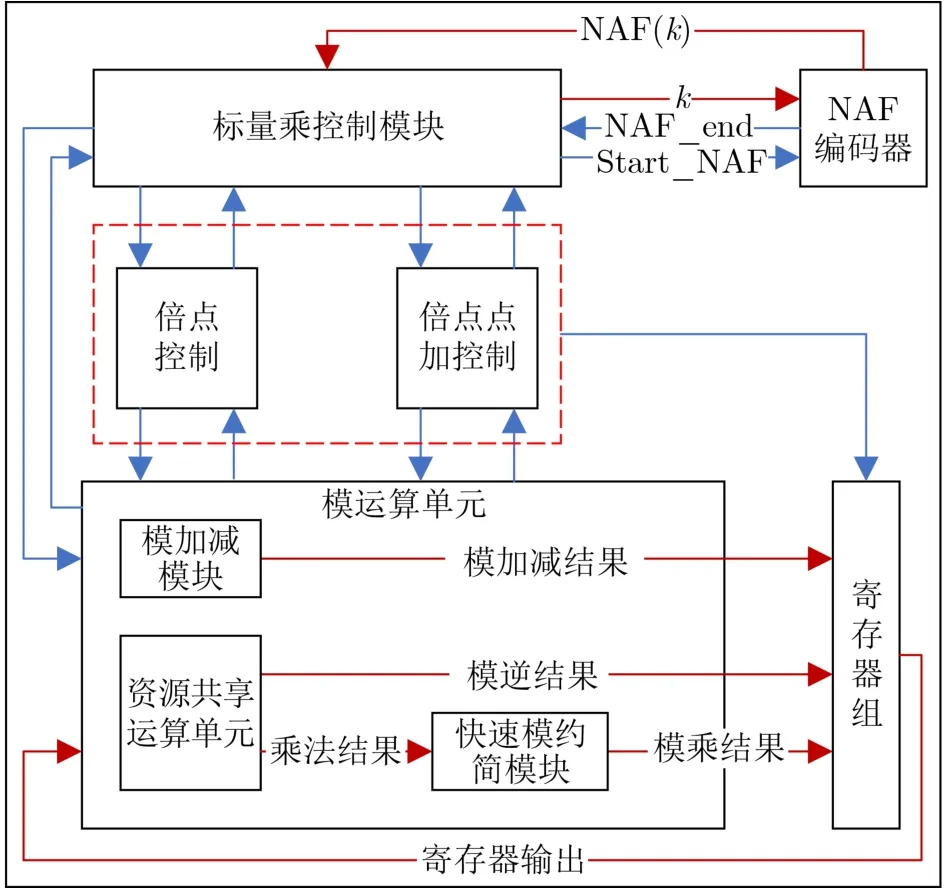
图4 标量乘法器
标量乘控制模块对标量乘法器整体进行控制,控制NAF编码器、点运算和有限域运算的开始和结束,使标量乘法器可以准确地完成标量乘运算。切换曲线也通过该模块实现,当切换不同曲线时,标量乘控制模块控制点运算和有限域运算选取不同的曲线参数。倍点控制和倍点点加控制模块负责点运算的顺利完成,控制底层模运算单元的开始和结束、模运算单元和寄存器组的输入与输出选择。模运算单元包括模加减模块、资源共享的运算单元和快速模约简模块,负责有限域运算。寄存器组存储模运算单元产生的所有中间结果。
4 实验结果
表1是使用55 nm CMOS工艺综合得到标量乘法器中主要模块面积,可以看到资源共享的运算单元为151k等效二输入与非门,占整个标量乘法器面积的54%,是占比最大的模块。表2给出了每个椭圆曲线操作需要的周期数量。1次标量乘共需要10 366个周期,在500 MHz的频率下计算1次标量乘需要0.02 ms,每秒可以计算48 309次标量乘。

表1 主要模块面积

表2 椭圆曲线操作周期
本文标量乘法器最终性能如表3所示,为了得到合理的对比,在ASIC平台使用55 nm和130 nm的工艺进行了前端逻辑综合,在FPGA平台使用Virtex-7进行了实现,并与类似工作进行了比较。

表3 256位素数域下椭圆曲线标量乘法器的性能比较
文献[22]使用快速模约简方式模乘,支持单曲线secp256r1,使用滑动窗口NAF标量乘算法,标量乘消耗周期数少,但是主频较低而且面积更大,所以本文AT值更有优势。文献[9]使用基4交错模乘,标量乘法器面积较小,但一次模乘需要大量周期,导致吞吐量和AT较差。文献[10]提出新的倍点和点加并行技术减少操作步骤,主频是所有设计中最高的,但是面积大,而且标量乘计算速度慢,与之相比本文的设计在AT值和吞吐量都很有优势。文献[11]采用128 bit的分段模乘,一次标量乘仅需0.0125 ms,每秒可实现80 000次标量乘,是所有设计中吞吐量最高的,但是标量乘法器面积是本文的12倍,AT值远大于本文提出的设计。文献[6]设计面积比本文小,但一次乘法需要5个周期计算,计算标量乘需要的周期比本文多,所以标量乘计算速度比本文慢,AT值比本文高。文献[12]和文献[13]都以硬件资源消耗最少为目标,所以速度都较慢,AT值都远远大于本文。文献[14]通过改进蒙哥马利阶梯算法,使得点加和倍点同时进行,虽然面积较小,但标量乘速度慢,吞吐量和AT值都差于本文。文献[24]采用蒙哥马利阶梯算法实现标量乘,虽然采用了转换坐标系方式提高标量乘计算速度,但是基2交错模乘速度慢,吞吐量和AT都不高。文献[25]提出了一种基于RNS的ECC处理器,可同时处理多个标量乘操作,但AT差于本文设计。
5 结论
本文提出了一种基于比特重组快速模约简的高面积效率ECC标量乘法器设计。利用Karatsuba-Ofman算法设计出仅需3个时钟周期的乘法器,提升了乘法的计算速度。基于此乘法器,又提出乘法与模逆资源共享的运算单元设计,在原乘法器结构基础上只增加一个CSA加法器可实现乘法或模逆的计算,在不影响两者速度的情况下进一步降低硬件资源消耗。推导了secp256k1曲线的快速模约简公式,基于比特重组方法与secp256r1和SCA-256两条曲线融合,设计了兼容3条曲线的快速模约简结构。最后根据所设计的运算单元和快速模约简结构提出了新的点加和倍点的操作调度方法,提高了乘法与快速模约简的并行性,从而获得了更高的吞吐量。实验结果表明,该标量乘法器的AT值比现有的大部分设计更低,此外在吞吐量方面也具有优越性。
猜你喜欢
宁波大学学报(理工版)(2022年6期)2022-12-01
小型微型计算机系统(2021年12期)2021-12-08
中国电子科学研究院学报(2019年8期)2019-12-23
电子设计工程(2018年18期)2018-10-09
计算机与现代化(2018年2期)2018-03-13
电子世界(2018年1期)2018-01-26
网络安全与数据管理(2017年4期)2017-03-10
光学精密工程(2016年2期)2016-11-07
数学物理学报(2014年3期)2014-03-11
长春大学学报(2012年8期)2012-11-08
