
Uni-LSDPM:基于预训练的统一在线学习会话退出预测模型
2024-02-20 08:22王占全
计算机研究与发展 2024年2期
陈 芮 王占全
(华东理工大学信息科学与工程学院 上海 200237)
(y30201053@mail.ecust.edu.cn)
大数据时代的到来和人工智能技术的发展为教育领域的改革和发展提供了新的思路,随着互联网+教育的普及和网络学习技术及策略的发展,在线教育成为了全民学习的高效途径之一. 智能辅导系统(intelligent tutoring system,ITS)除了为学习者提供学习资源、建立师生桥梁、维护学习交流社区,还应尽可能帮助学习者更好地学习与掌握知识,使每个学生的学习效果最大化.ITS 的普遍做法是通过人工智能对学习者的知识体系进行追踪建模,诊断学生的学习问题,生成学习者个性化学习路径,并提供适合学习者的个性化补充学习材料[1-4]. 然而,ITS 不仅要考虑学习者参与各学习项目的学习效率,还要考虑学习者的学习参与度[5],使其能够最大限度地提高学习的整体效率. 即使ITS 确定了效率最高的最优学习路径,但学习者在学习过程中出现的频繁中断或在学习初期就辍学的情况,将成为实现教育目标的巨大阻碍.
学习者在ITS 中学习的时间越长,对学习者与ITS 产生的正向价值就越大. 在学习者的知识获取方面,基于平台上的学习资源与系统推荐学习路径,学习者能够更高效地获取更多知识技能[6];在ITS 教育方式及教育过程的优化方面,ITS 能够以更大概率通过学习者行为特征获取用户需求、用户关系等信息,以便生成用户画像,针对性地提供个性化服务,继而反向促进学习者学习活动,使学习效率加倍. 学习者每次的学习时间越长,学习者最终辍学的可能性越低[7]. 因此,如何尽可能地延长学习者单次会话的学习时间是值得探究的问题. 有研究表明,学习者与课程内容之间的交互,与学习者的辍学结果在统计学上具有显著的直接和间接关系[8]. 因此,为了监督和帮助学习者不中断学习任务,ITS 需要在学习者退出学习概率较大时采取措施使其继续保持学习状态.通常,系统会采取措施促使学习者完成当前学习项目或继续学习路径推荐的下一个学习项目,以辅助学习者对知识点的获取、巩固和拓展.
为了防止学习者退出,若ITS 较频繁地在学习者每次执行完1 轮或几轮动作后就推荐引导学习者参与下一学习活动,可能会引起学习者的反感而导致学习者流失;ITS 若较长时间不采取干预措施,则容易导致学习者退出学习状态,无法最大限度地提高学习效率. 因此,如何在适当的时间对学习者进行提醒监督或推荐、引导、反馈是一个值得关注的问题.ITS 需要准确地发现学习者在何时会有退出的风险,才能及时采取干预措施[9]. 通过预测学习者在学习中途退出的时机,ITS 能够动态地修改服务策略,以鼓励学习者继续参与教学活动. 因此,在线教育中的学习会话退出预测是一个值得研究的重要命题.
学习会话是学习者学习阶段中的一个过程. 在此过程中,学习者连续参与学习活动,对平台各模块访问互动进行连续请求动作,同时保留其最近行为的历史记录. 在每个学习阶段中,当学习者在足够长的时间内不出现新的学习动作和活动时,表示发生了学习中途退出,标志着学习会话的结束,记为学习会话退出. Halfaker 等人[10]研究了各个领域的用户行为数据,提出了一种用于识别用户活动集群的方法,研究得出对用户行为聚类效果最好的时间阈值为1 h,我们引用其研究结果作为学习会话退出的阈值. 图1所示为学习者行为活动、学习会话和学习会话退出的示例.

Fig. 1 Examples of behavior activities, learning sessions and learning session dropout图1 行为活动、学习会话和学习会话退出示例
为了改善ITS 辍学率高的问题,我们将学习过程中的中途退出预测任务定义为学习会话辍学预测(learning session dropout prediction,LSDP)任务. 根据预测结果,ITS 可以在每个学习者退出会话概率较大的节点及时给予学习者干预措施,激励、引导学习者继续学习,帮助学习者更好地掌握当前知识点或更多地拓展其他知识点. 该任务旨在预测学习者在执行当前学习行为后退出当前学习会话的概率.
此前,随着大规模在线开放课程(massive online open courses,MOOC)的发展和海量用户活动数据的可用性增强,研究者针对学生辍学预测(student dropout prediction,SDP)[11]展开了大量研究.SDP 的具体目标是通过分析与模拟学生与ITS 交互的行为来分析在线学习环境中的课程辍学情况[12]. 其中涉及各种传统机器学习技术[13-15]与基于神经网络的模型[16-17].
然而,虽然使用学习分析构建辍学预测模型有望为这些有风险的学生提供干预设计信息,但当前预测模型构建方法的结果并不能为学习者提供个性化干预[18]. 而LSDP 可以提供更细粒度的预测结果,能够为及时干预学习者辍学提供依据. 尽管已经对在线教育的辍学预测进行了广泛的研究,但在线学习过程中的阶段性辍学与在线课程辍学不同. 在线学习过程中途退出发生的频率更高,单次学习时长更短. 在线学习的碎片性在课程辍学预测研究中并没有得到充分考虑. 直接应用学生课程退学预测方法来预测学习过程中的阶段会话退出,预测效果不佳. 因此,相对于SDP 而言,LSDP 需要考虑学习者学习行为的碎片性和预测的即时性. 在有限的行为数据中对学习会话退出状态进行准确预测,是LSDP 的一大挑战.
与线下学习不同,ITS 可以利用自动收集的学生行为数据来实时完成任务, Lee 等人[19]将问答日志作为研究对象. 但在实际在线ITS 中,还应考虑多方面行为特征. 随着学习者行为活动的产生,学习者的学习状态也会发生变化,学习者在动态变化的学习状态下拥有动态变化的最优学习路径. 例如,学习者完成作答后的作答结果是否正确关系到下一行为可能是重新作答或继续作答同一类型其他题目,还可能是查看该题目对应的解析或讲座视频. 这些行为所伴随的特征,如回答结果、观看视频的光标时间、持续时间等,也可以反映学习者对知识点的掌握情况和学习状态. 因此,如何准确地挖掘学习者学习状态的变化及其对学习者会话退出带来的影响是LSDP的又一大挑战.
近年来,基于预训练-微调范式的语言模型在自然语言处理领域取得了突破性的成果[20]. 预训练任务旨在学习上下文语料之间的隐含关系,为下游任务提供基础. 在LSDP 任务中,由于学习行为的碎片性,当仅有少量前序学习行为作为输入时,模型在预训练阶段已经学习过学习行为上下文特征及其隐含关系,有利于在下游学习会话退出预测任务中快速做出更准确的预测. 因此,利用预训练任务全面地挖掘并理解学习者学习行为特征、上下文隐含关联是准确预测学习者学习会话退出的重要基础,预训练-微调范式能够有效解决学习行为碎片性和学习行为状态隐含关联不清楚对学习会话退出预测准确性带来的困难.
在本文中,我们基于学习者在ITS 中的在线学习行为对学习者学习会话退出进行了预测研究. 参考统一语言模型(unified language model,UniLM)[21]框架,提出了一种基于预训练-微调的统一学习会话退出预测模型(unified learning session dropout prediction model,Uni-LSDPM). 该模型采用多层基于多头注意力的Transformer 结构,对同一行为特征之间的上下文与连续动作序列的上下文进行联合关注,以进行在线学习会话的退出预测. 本文的主要贡献有3 点:
1) 由于以往基于在线教育会话退出的任务研究较少,本文明确了在线学习会话及其退出状态的定义,并定义了在线教育学习会话退出预测任务和模型输入序列框架.
2) 提出了基于预训练-微调范式的统一学习会话退出预测模型Uni-LSDPM.该模型包括预训练部分与微调部分,旨在挖掘并理解同一学习行为特征间的上下文关联性和连续学习行为间的上下文隐含关系,并得到预测会话退出状态.Uni-LSDPM 为第1 个将预训练-微调范式应用于在线学习会话退出预测任务的工作.
3) 进行了大量的消融实验和对比实验来评估所提出模型的效果. 实验结果表明,Uni-LSDPM 在AUC 和ACC 方面优于现有的模型.
1 相关工作
本节首先介绍了近年来SDP 的相关工作. 其次,介绍了教育及其他领域中基于时间序列的会话退出研究. 最后,描述了现有的LSDP 研究方法.
1.1 学生辍学预测
在在线教育领域,LSDP 研究还处于起步阶段.以往SDP 相关研究工作的研究目标大多注重于在线课程的辍学,即预测学习者中途是否会退出当前学习的课程[12-13].
机器学习技术曾被广泛地应用于课程辍学预测方面的研究. 其中一些传统机器学习的算法被广泛应用[22-25],包括随机森林(random forest,RF)、支持向量机(support vector machine,SVM)、逻辑回归(logistic regression,LR)、决策树(decision tree,DT)、朴素贝叶斯(naive Bayes,NB) 、 隐马尔可夫模型(hidden Markov model,HMM)等. Dass 等人[22]应用RF 来预测MOOC 课程中的学生辍学. Hong 等人[23]采用2 层级联分类器进行辍学预测,该分类器由RF,SVM,LR这3 种不同的机器学习分类器组合而成.Coussement等人[24]将DT 与LR 模型构成的混合模型(logit leaf lodel,LLM)与LR、SVM、DT、RF、提升树(Boost)、HMM、NB、神经网络这8 种算法进行实验对比分析,总结出LLM 算法在辍学预测中的有益影响. Lee 等人[25]使用LR、DT、NB 和多层感知器(multilayer perceptron,MLP)生成学生辍学的预测模型. 通过方差分析得出选择的自变量多层感知器模型比其他模型具有更好的性能.Boudjehem 等人[26]利用分布式人工智能分析学生的行为活动,以此来识别有辍学危险的学生.
许多研究者在特征获取方面也进行了大量的研究. Alamri 等人[27]使用“学习者的跳跃行为”作为特征,通过检查学生下周的学习活动和行为来预测学生辍学率,获得了较高的辍学预测精度.Jin[28]研究了每个学生样本初始权值的计算和实现算法,利用智能优化方法进一步研究了学生样本初始权值的优化方法,并利用加权训练样本训练预测分类器. 这些特征获取的创新在提升SDP 的精度上有很大帮助.
另外,还有许多基于神经网络的技术和方法用于SDP[29], 包括长短期记忆网络( long short-term memory,LSTM)、卷积神经网络(convolutional neural network,CNN)等. Wu 等人[30]提出了名为 CEDN(classmates enhanced diversity-self-attention network) 的方法来预测学生的辍学.CEDN 利用年龄、性别、教育程度、课程类别等多样性信息和用户的活动序列,构建了一个多样性自注意模型,用于生成用户课程特征. Goel 等人[31]采用半监督学习模式的自我训练建立辍学预测模型,该模型具有利用少量标记数据的灵活性. Zhang 等人[32]提出了一种混合深度神经网络来建模和预测学习者的辍学. 该网络通过CNN 和SE-Net(squeeze-and-excitation networks)提取行为矩阵的局部特征. 通过门控循环单元(gate recurrent unit,GRU)网络提取学习行为之间的序列关系. Wu 等人[33]提出了一种深度神经网络模型,它是CNN、LSTM 和SVM 的组合. Feng 等人[34]提出了一种情境感知的特征交互网络(context-aware feature interaction network,CFIN)来建模和预测用户的退出行为. CFIN 利用上下文平滑技术对不同上下文的特征值进行平滑处理,并利用注意力机制将用户和课程信息结合到建模框架中.Fu 等人[35]提出了基于学习者行为数据的深度模型CLSA;Mubarak 等人[36]提出了一个卷积神经网络和长短期记忆的超模型CONV-LSTM,用于自动从MOOC 的原始数据中提取特征,并预测每个学生是否会辍学. Wang 等人[37]基于MOOC 中大量用户-项目交互数据来预测辍学行为,提出了面向MOOC 中辍学应用的联合动态user-item embedding 来预测算法. Nitta 等人[38]提出了一种基于图的辍学预测模型,该模型是利用学生各行为之间的图结构关系,使用张量分解和Transformer 方法构建的, 该模型性能与图卷积网络的性能相当. 神经网络的创新在SDP 任务中也普遍取得了较好的效果.
1.2 学习序列分析及标注问题
学习会话退出预测任务的本质是对学习者学习序列进行挖掘分析. 在在线教育领域,知识追踪(knowledge tracing,KT)[39]、教育资源推荐[40]等任务同样以学习者在线学习行为序列挖掘作为重点.
近年来,除了传统机器学习方法,知识追踪任务也拓展了深度学习方面的研究[41]. 在神经网络方面,Shen 等人[42]提出了一种卷积知识追踪(convolutional knowledge tracing,CKT)方法对学习过程进行个性化建模,该方法基于学生历史上连续学习交互的分层卷积层来提取学习速率和个体化先验知识,获得更好的知识追踪结果. Sun 等人[43]将学生行为特征与学习能力特征相结合,以加强知识追溯的性能,提高了经典知识追踪模型动态键值记忆网络(dynamic keyvalue memory network,DKVMN)的预测效果.
在注意力机制相关研究方面,Ghosh 等人[44]提出了注意力知识追踪(attentive knowledge tracing,AKT)模型,该模型通过上下文感知计算注意力权重,利用注意力机制将学习者对评估问题的未来反应与其过去的反应联系起来,具有较好的知识追踪预测效果和可解释性. Liu 等人[45]提出了一个通用的练习增强递归神经网络(exercise-enhanced recurrent neural network,EERNN)框架,并在其基础上设计了应用注意力机制的学生成绩预测模型,通过注意力机制跟踪学生在多个知识概念上的知识获取,其在一般场景和冷启动场景下均能取得较好的预测效果. Pandey 等人[46]提出了一种基于自注意力的知识追踪方法,利用自注意力机制识别知识概念之间的相关性,从学生过去较少的活动中对学生的知识掌握程度进行预测,其在数据稀疏的情况下仍能获得较准确的结果.Zhang 等人[47]提出了一种基于协同注意力机制的知识追踪模型,并引入焦点损失函数,解决了知识追踪中问题标注划分不平衡的问题,提高了模型预测的准确性.
在预训练相关研究方面,Tan 等人[48]提出了基于大规模预训练语言模型BERT(bidirectional encoder representations from Transformers)的深度知识追踪模型BiDKT,取得了良好的效果. Ma 等人[49]提出了预训练方法SPAKT,利用自监督学习来预训练学习者所做习题与技能之间的相似度关系表示,该预训练模型可以整合到现有的基于深度神经网络的KT 框架中以简化标注过程.
预训练框架也在教育资源推荐任务上取得了突破.Schrumpf 等人[50-51]先后提出了基于双向预训练模型BERT 的神经网络SidBERT[50]和SemBERT[51],用于教育资源分类和推荐.SidBERT 已在一个典型的在线学习系统中得到积极应用. SemBERT 在SidBERT的基础上进行了优化,能够在更细粒度的级别上比较教育资源.
1.3 多领域会话中的会话退出预测
会话阶段性退出预测研究除了应用于在线教育领域,也是流媒体、电子商务、在线游戏等多个领域研究的重要问题. 在流媒体领域,Lebreton 等人[52]基于视频直播平台Puffer 的使用数据,研究服务与视频质量和用户退出行为之间的关系,提出用户退出预测模型以识别出用户退出视频的原因和事件,以此预测用户的退出. 在电子商务领域,Hatt 等人[53]提出了一种马尔可夫调制标记点过程(Markov modulated marked point process,M3PP)模型,用于检测用户从点击流数据中不购买就退出的风险. 在医疗领域,Karumbaiah 等人[54]为了提高学生用户的学习效果和参与度,基于学习游戏《物理操场》提出了学生用户在玩该游戏时的退出预测模型. 在多个领域中,预测短期内的退出能够动态更新服务策略,为及早发现用户退出的风险并进行干预提供了机会,进而促使用户的会话长度变长,以帮助达到用户或平台理想使用效果.
1.4 学习会话退出预测
许多研究者试图使用定量和定性方法进行学生流失分析,并对学生的辍学概率进行预测,然而预测辍学行为或退出事件发生时间的研究较少[55],准确挖掘辍学干预实施的恰当时机,才能为最大限度地提高学生保留率提供机会. Lee 等人[19]在2020 年经调研发现当时还未有关于MOOC 中学习环节退出的预测研究,并对移动学习环境下的学习环节辍学预测问题进行了定义与研究. 在该研究以后,Liu 等人[56]提出了一种特征生成方法,分析每个学习者跨时间的行为,并根据最近性和相关性为每个时间片确定适当的行为权重,允许现有的机器学习模型从跨学习者的不同行为中提取模式,以利用当前的学习者行为数据来预测学习过程中的辍学. Rzepka 等人[57]将MLP 应用于会话退出预测,其准确率能够达到87%.
以往的研究大多将在线学习行为建模为时间序列进行挖掘,在处理顺序信息时,LSTM 及它的变体GRU 很受欢迎[58]. 近年来,注意力机制[59]及以注意力结构为核心的模型表现出了更出色的性能,在辍学退出预测研究上也显示了更高的预测效果[60].Pulikottil 等人[61]提出了一种基于注意力元嵌入的深度时间网络来预测MOOC 中的用户辍学,不必为不同的数据集使用不同的架构,且获得了与之前最好的方法相当的结果;Lee 等人[19]提出基于单层Transformer 的深度注意学习会话退出预测模型(deep attention session dropout prediction model, DAS),仅通过单层编码器和解码器对多头注意力网络进行掩码,对学习行为特征和会话退出状态进行同步训练.DAS比LSTM 和GRU 模型的表现好12.2%,但仍有很大的提升空间.
为了区别于传统的SDP 任务,对ITS 中的学习退出事件进行更细粒度的预测,本文对基于ITS 的LSDP 问题进行定义,并提出了基于预训练和微调范式的Uni-LSDPM 模型. 本文提出的Uni-LSDPM 与Lee 等人[19]提出的DAS 模型均基于Transformer 结构[59],它们都能够通过多头注意力机制捕捉学生交互的复杂关系. 与DAS 单层Transformer 结构不同的是,Uni-LSDPM 采用预训练和微调架构,2 阶段均采用多层Transformer 结构. 将学习行为特征上下文学习作为预训练任务目标,将会话退出预测训练作为微调任务目标,在充分学习在线学习行为特征隐含关联的预训练基础上进行退出预测,能够一定程度上提升预测准确率,达到小样本行为作为输入时的准确判断.Uni-LSDPM 是目前第1 个将预训练-微调范式应用于LSDP 任务的工作.
2 基于智能辅导系统的学习会话退出预测
本节对LSDP 任务进行形式化定义,并对模型的输入特征表示进行描述.
2.1 问题定义
在LSDP 中,不仅要关注学习者执行同一动作的特征上下文,也要注意学习者前后动作的特征上下文. 在此设置下,我们将学习者在线学习会话相关属性形式化为:
Sm为学习者Un的第m组连续动作序列,包含T个学习行为.At为一个学习行为的描述,由I个特征组成学习行为特征.fi属于交互项目特征(fitem)、行为响应特征(fresponse)与行为会话特征(fsession)这3 大类型,其中fitem表示与课程静态属性相关的特征,例如交互项目类型、所属的课程章节、所回答题目的知识点范围等;fresponse表示与学习者响应状态相关的特征,例如学习者的行为类型、当前动作与前一动作的时间差、所回答问题的答案结果判定、视频观看的起始光标等;fsession表示当前行为会话相关特征,例如当前行为所处会话在学习者整体学习活动的位置、当前行为在当前会话所处的位置、当前行为的退出状态等.
LSDP 任务即对学习者在线学习过程中退出概率的估计,di表示会话退出状态,如式(5)所示,当学习者Un在当前发生行为At并退出当前会话时,di=1,否则di=0.
2.2 输入表示
Uni-LSDPM 根据学习者学习行为特征fi,预测学习者在执行当前学习行为后的辍学概率. 学习者的学习行为特征fi可以分为3 种类型:fitem,fresponse,fsession.表1 显示了特征fi的详细信息,详细说明有12 点:
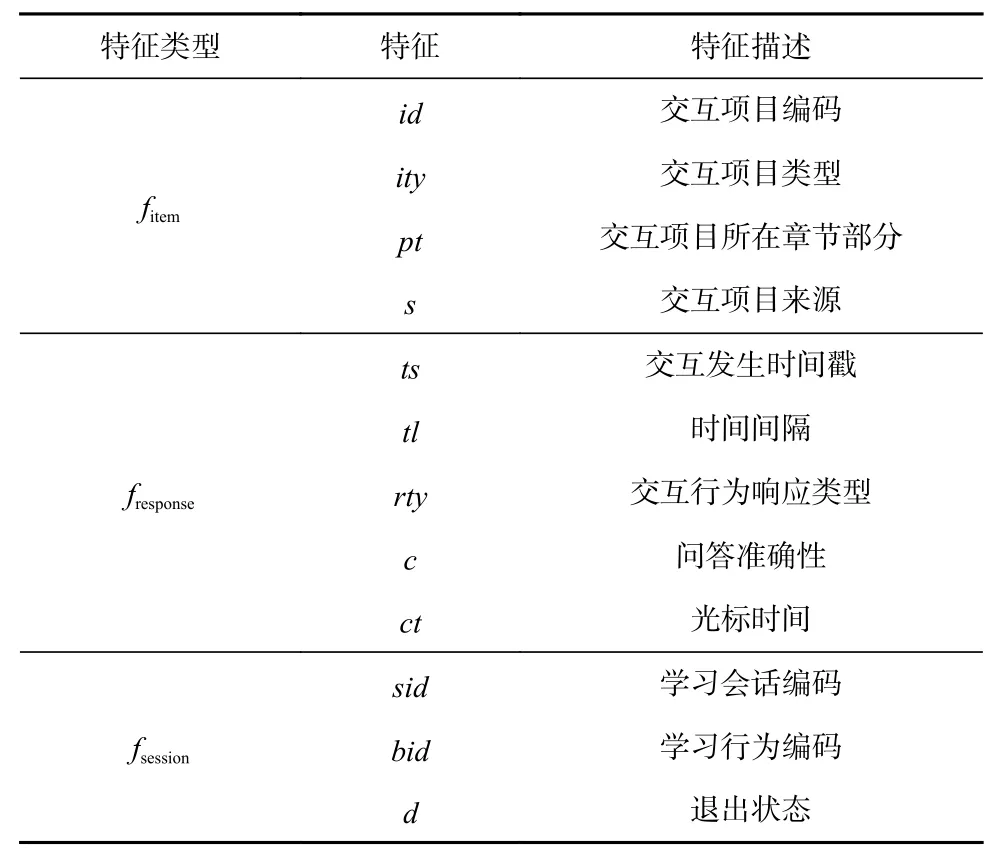
Table 1 Description of Learner’s Learning Behavior Features表1 学习者学习行为特征描述
1) 交互项目编码(item id). 与学习者动作交互相关项目的id.
2) 交互项目类型(item type). 交互项目包括试题、试题解析、讲座视频等类型.
3) 交互项目所在章节部分(item part). 交互项目所属知识点领域.
4) 交互项目来源(item source). 学习者对该项目进行交互的来源. 例如学习者对某一道试题进行交互,试题来源可能是课程配套的课后习题、系统推荐的每日练习、在个人笔记中收藏的题目等.
5) 交互发生时间戳(timestamp). 交互行为发生的时间.
6) 时间间隔(time lag). 当前交互行为与上一交互行为发生的时间差.
7) 交互行为响应类型(response type). 学习者的行为类型. 例如做试题时排除一个答案(erase choice)、观看视频讲座时播放视频(play video)、暂停音频(pause audio)等.
8) 问答准确性(correctness). 学习者作答后的答案正确与否,反映学习者对当前知识点的掌握程度,对学习者的下一学习行为具有指导作用.
9) 光标时间(cursor time). 学习者播放视频、音频的光标时间,反映学习者对学习资源的应用模式和学习者的学习状态.
10) 学习会话编码(session id). 学习者当前行为所处会话在学习者整体学习活动的位置.
11) 学习行为编码(behavior id). 学习者当前行为在当前会话所处的位置.
12) 退出(dropout). 学习者在完成当前行为后的退出状态.
3 Uni-LSDPM 模型
3.1 Uni-LSDPM 模型概述
UniLM 是一个基于多层Transformer 网络的统一预训练语言模型,它利用大量文本数据,针对单向(unidirectional)、双向(bidirectional)、序列到序列(sequence-to-sequence,Seq2Seq)这3 种模式进行无监督联合预训练,能够通过不同掩码方式实现不同的训练任务.Uni-LSDPM 采用与UniLM 相同的预训练框架从在线学习行为数据中得到具有上下文语义信息的词向量表示.
Uni-LSDPM 的结构如图2 所示,Uni-LSDPM 包括预训练阶段与微调阶段2 部分. 在预训练阶段,Uni-LSDPM 利用大量学习者连续学习行为特征组序列集,基于双向掩码矩阵,对学习者学习行为特征上下文信息与连续行为上下文信息进行编码学习,得到单一学习行为特征间及连续学习行为数据间的向量表示,预训练收敛后的模型权重参数将作为微调的基础. 在微调阶段,学习行为特征部分采用双向掩码矩阵,而退出状态部分采用单向掩码矩阵. 即在微调阶段运用Seq2Seq 自注意掩码方式,对由行为特征组-退出状态组成的序列对数据进行学习. 针对学习会话中行为碎片性的难点,Uni-LSDPM 将连续学习行为以特征为单位拆解进行分析,着重挖掘学习者最近发生新行为的隐状态即可获取大量行为隐含状态信息. 在学习行为单位上进行退出判别,在下游预测任务中能够做到预测及时性. 在针对学习行为特征的预训练基础上对LSDP 任务进行微调,在预训练阶段充分挖掘特征之间的隐含关联信息,能够为下游任务会话退出预测准确率的提升提供支持.

Fig. 2 Overview of the Uni-LSDPM framework图2 Uni-LSDPM 框架概述
3.2 预训练阶段
在预训练中,连续学习行为特征组数据来自智能辅导系统中学习者的历史学习数据. 学习者每进行一个学习动作,即会产生一系列相应的学习活动特征,连续学习行为特征组包含多个连续学习行为特征信息. 预训练阶段旨在挖掘和理解学习者同一学习行为中的特征上下文相关性以及连续学习行为之间的隐含上下文关系. 在下游任务LSDP 中无需对下一动作特征进行预测,且在学习者进行到当前动作时,之前的学习行为皆为已知. 由于单向掩码注意力机制只能注意到前面的信息或后面的信息,而双向掩码注意力机制可以同时注意到上下文信息. 因此,在预训练阶段,深度双向模型比单向的浅层串联更合适[20],故采用双向掩码注意力机制进行预训练.
Uni-LSDPM 的预训练阶段主体过程如图3 所示,以将掩码为例,将无标签连续学习行为特征组以键值对的形式序列化,以词(token)向量的形式输入.将[ACT]定义为不同行为之间的特殊分隔符,将[SOS]作为起始符添加在每个输入序列前,将[EOS]用于标记输入序列的结束.
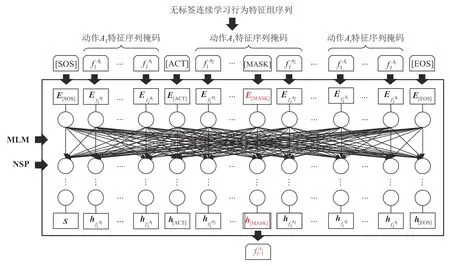
Fig. 3 Pre-training procedures for Uni-LSDPM图3 Uni-LSDPM 预训练过程
预训练模型使用完形填空(masked LM,MLM)和下一句预测(next sentence prediction,NSP)这2 个无监督任务进行训练. 将一定比例的输入token 随机掩码为[MASK],然后通过预测这些掩码token 对行为特征序列关系进行学习和理解. 行为特征隐藏向量的深度双向表示通过多层 Transformer 进行训练.
由学习者的学习会话中的2 个连续行为和组成的行为组是从未标注的连续学习行为特征组的序列集中随机选取的,其中p用于标注预训练中使用的学习行为数据.图4 以其作为示例输入展示了Uni-LSDPM 的预训练框架.

Fig. 4 Example of the pre-training stage of Uni-LSDPM图4 Uni-LSDPM 预训练阶段示例
连续学习行为特征序列首先以词嵌入(token embedding)、分段嵌入(segment embedding)和位置嵌入(position embedding)这3 种形式嵌入获得3 个层次的向量表示. 其中词嵌入将各个行为特征值转换成固定维度的token 向量;分段嵌入将学习行为序列分段标记为向量表示,以区分不同学习行为;位置嵌入的向量表示让模型学习到输入序列token 的顺序属性,不同位置上的向量可能存在相同token 内容,但具有不同的含义. 这3 种形式的向量表示被元素相加后得到合成向量表示作为模型的输入向量,其中{x}|x|表示向量x的3 种嵌入方式总和. 向量首先被打包为式(6),输入如式(7)所示的L层Transformer 网络中,学习如式(8)所示的每个第l层上下文表示.
对于第l层,计算自注意头Attnl来聚合前一层的输出,如式(9)(10)所示,对应于掩码token 的最终隐藏向量被输入到softmax 分类器中.
其中矩阵Q,K,V分别表示自注意力机制中的查询(query)、键(key)、值(value),通过前一层的输出Hl−1∈R|x|×dh分别由参数矩阵,∈Rdh×dK和∈Rdh×dV线性投影得到,其中dh为模型维度,dK为注意力键值矩阵维度,dV为注意力查询矩阵维度. 该阶段通过双向训练来获得行为特征隐藏向量的深度双向表示.
3.3 微调阶段
为了对学习者在执行完当前学习行为活动后的退出状态进行预测,需将学习行为与相应退出状态组合,建立序列对集合进行训练,即将学习者当前行为特征At+N及其前序行为特征At,At+1,…,At+N−1与当前行为对应的退出状态dt+N进行组合,得到新的行为特征-退出状态对联合序列At,At+1,…,At+N−1,dt+N.图5 显示了微调阶段由行为特征-退出状态对组成的输入数据形式的示意图.该微调模型是为下游任务LSDP 设计的,其旨在通过一个连续的行为特征组来预测最后一个行为的 dropout 状态. 其中会话行为特征以键值对形式序列化,联合序列以token 词向量的形式输入模型.Uni-LSDPM 的微调主体过程如图6所示.

Fig. 5 The schematic diagram of the input data form in the fine-tuning stage图5 微调阶段输入数据形式示意图

Fig. 6 Fine-tuning procedures for Uni-LSDPM图6 Uni-LSDPM 微调过程
由于在学习者完成当前行为之前,无法确定当前行为完成后的退出状态,故在学习行为特征和退出状态的联合序列中,使用了Seq2Seq 的自注意力掩码方法,即学习行为特征部分需要双向关注,辍学状态部分需要单向关注,使用不同的自注意力掩码来控制每个行为特征标记对上下文的访问. 在对行为特征-退出状态对的联合序列进行掩蔽后,以词嵌入,分段嵌入,位置嵌入这3 种方式嵌入到向量x中,如式(11)所示:
其中xf表示行为特征序列映射的向量,xd表示退出状态序列映射的向量. 从行为特征-退出状态对联合序列集中随机选取2 个连续行为,组成的行为组与对应退出状态.图7 以其为例展示了Uni-LSDPM 的微调框架,其中f用于标记微调所用的学习行为相关数据.

Fig. 7 Example of the fine-tuning stage of Uni-LSDPM图7 Uni-LSDPM 微调阶段示例
其中M∈R|x|×|x|,表示学习者行为特征采用了Seq2Seq的注意力掩码方式. 掩码矩阵M的左边部分设置为“0”,使行为特征的所有token 都可以相互关注. 右上部分设置为“−∞”以阻止注意力从行为特征段到退出状态段. 对于右下部分,上三角部分设置为“−∞”,其他元素设置为“0”.退出状态能够注意到左边的特征内容,但学习行为特征无法注意到退出状态. 例如,给定一个由学习特征序列,,,和当前行为对应的退出状态组成的序列,模型将序列进行随机掩码后,输入token 为[SOS],,, [ACT],,,[EOS],,[EOS],其中[SOS],,,[ACT],,,[EOS]可以相互注意,,[EOS] 只能注意左边的token,而左边的token 无法注意到. 在第l层中,自注意头Attnl计算方式在预训练阶段的基础上引入了自注意掩模矩阵M,如式(13)所示:
LSDP 下游任务的重点是对退出状态概率分布进行预测,即在上述示例中,将进行掩码操作,输入token 即为[SOS],,,[ACT],,,[EOS],[MASK],[EOS]. 这些token 经过多层Transformer 编码为h[SOS],hf1A1,hf2A1,h[ACT],hf1A2,hf2A2,h[EOS],h[MASK],接着隐藏h[MASK]被输入到softmax 分类器中进行线性分类,生成退出状态预测的概率分布. 最后,预测的token 被追加到输入序列以替换[MASK],序列结尾的[EOS]出现即标志着预测结束.
4 实 验
4.1 数据集
实验所用的数据集来自英语在线教育系统Santa,它是一个帮助学生准备国际交流英语听力和阅读考试(TOEIC)的ITS,提供13 169 道试题和1 021 节讲座课程资源. 该系统提供Android 系统、iOS 系统、Web应用3 种途径以进行学习活动.
EdNet[62]是目前最大的关于学生总数、交互次数和交互类型的教育公共数据集,它收集了Santa 中大规模的学生-系统交互日志数据. 其中,EdNet-KT4 中包含了2018-8-27—2019-11-27 记录的学习者学习活动最细粒度的交互数据,详细地记录了每个学生的行为细节特征. EdNet-KT4 原始版本数据集中统计了297 915 名学习者共131 441 538 条学习行为记录.
为了避免平台不同对实验结果的影响,剔除Web 与Android 平台下的用户数据,仅对移动平台上的用户行为数据进行研究,并以记录行为个数小于等于5 为标准,剔除学习活动过少的学习者数据. 预处理后的数据集包括共202 774 名学习者的93 189 667条学习行为数据. 根据以1 h 为阈值[10]的识别学习会话退出标准,划分得到共979 498 组学习会话,平均每个会话包含95.1 个学习行为交互. 以每组会话包含的行为交互个数作为学习会话大小,以每组会话持续的时间作为学习会话的长度,得到会话大小与长度的数量统计如图8 所示.
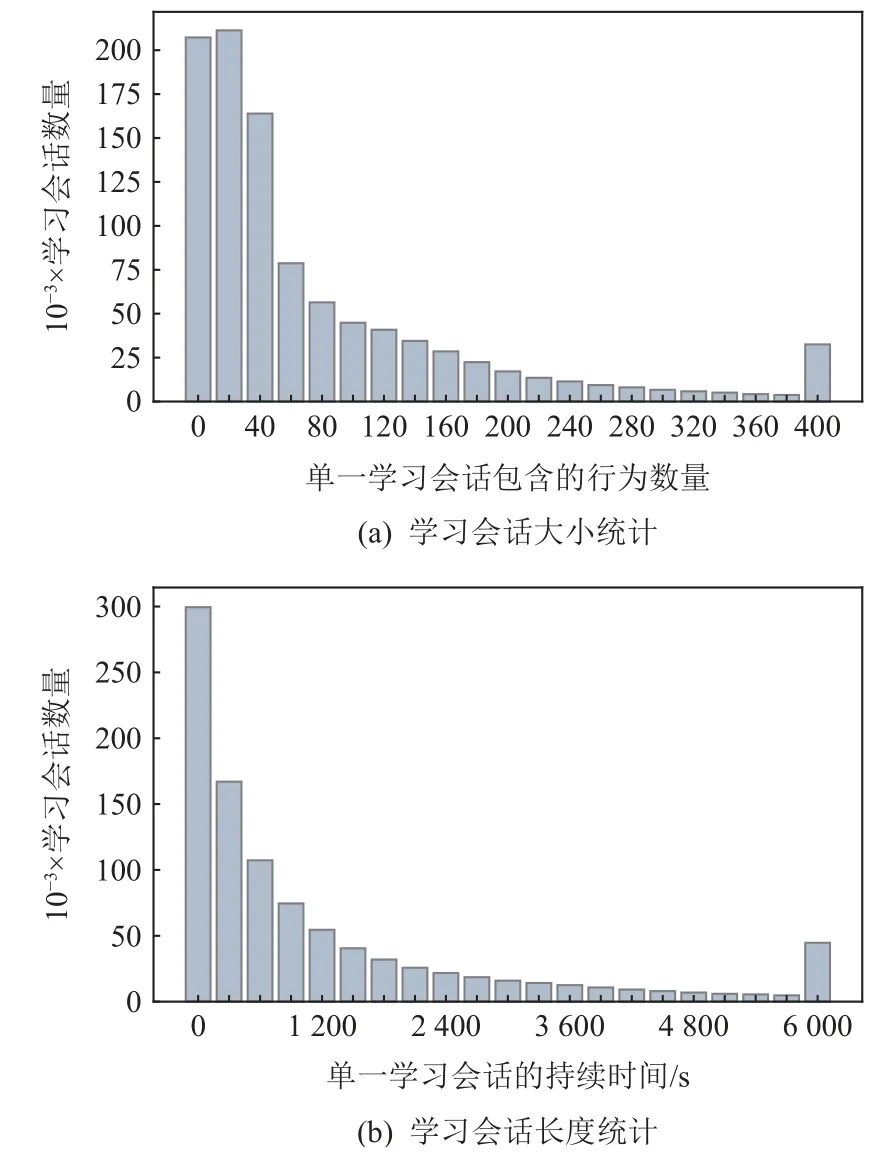
Fig. 8 Learning session size and length statistics图8 学习会话大小和长度统计
据统计,执行不到60 个学习行为就中断学习的学习会话数量占学习会话总数的51.45%,学习会话持续900 s 以内就中断学习的学习会话数量占学习会话总数的58.58%,故在执行60 个学习行为以内或持续900 s 以内的情况下,学习者更可能中断学习.可以推测,学习行为活动数量及学习会话持续时间这类学习会话特征与会话退出预测结果具有一定相关性. 因此,我们将学习行为在当前会话中的相对位置(sid)及当前会话在学习者整体学习活动中的相对位置特征(bid)作为学习行为对应的会话特征,其与学习者学习行为本身特征相结合,作为Uni-LSDPM输入字段以进行综合分析.
我们对原始数据集中的字段进行了处理:
1) 结合EdNet 中的课程、讲座、试题解析等项目信息,将学习者的学习交互所涉及到的项目与项目特征进行对应,补长学习行为特征序列;
2) 根据试题标准答案,获得学习者作答结果判定;
3) 为同一学习者的每个会话分配会话位置id,以标记会话所处学习者整个学习过程中的位置;
4) 为每个交互分配交互位置id,以标记交互所处当前会话中的位置;
5) 将每个会话的最后一次行为交互标记为退出交互,即dropout=1.
表2 为一个学习者学习行为交互响应特征数据示例.
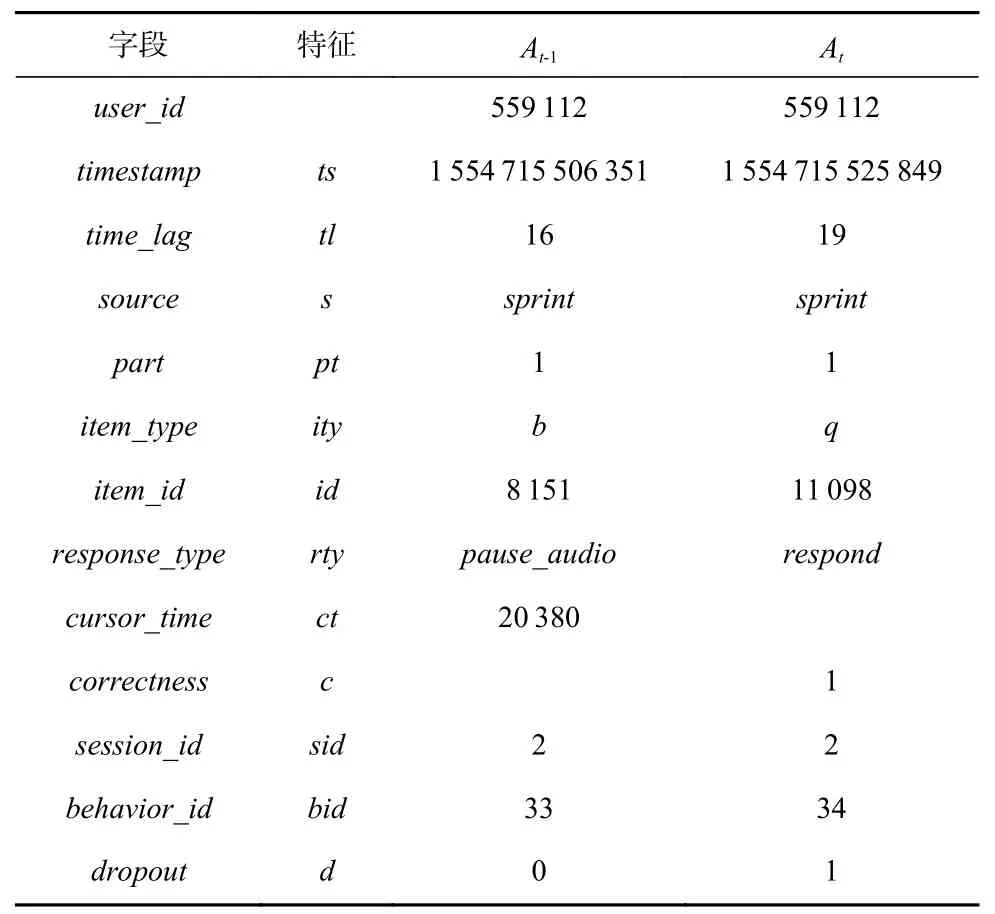
Table 2 Processed Dataset Fields and Examples of Continuous Learning Behavior表2 处理后数据集字段和连续学习行为示例
处理后的 EdNet 数据集字段描述为:
1)user_id为用于识别不同学习者的编码.
2)timestamp为交互发生时的时间戳,以 Unix 时间戳表示.
3)time_lag为当前交互与上一交互之间的时间差.
4)source为交互项目来源,记录了学生解决问题或观看讲座的来源位置, 包括sprint,tutor,in_review,my_note等.
5)part为交互项目所属课程部分,Santa 包括7个部分.
6)item_type为交互项目类型. 包括4 种项目类型q,b,e,l.q表示题目试题(question),b表示包含题目的题目组(bundle),e表示题目解析(explanation),l代表讲座(lecture).
7)item_id为用于识别不同交互项目的编码.
8)response_type为交互行为的响应类型,包括enter,response,submit,erase_choice,play_audio,undo_erase_choice,pause_audio,play_video,pause_video等.
9)cursor_time为音频/视频的光标时间,当action_type为play_audio,pause_audio,play_video,pause_video时记录.
10)correctness为作答准确性,当action_type响应时记录. 答案正确时,correctness=1, 否则correctness=0.
11)session_id为会话位置编码,它能够表示当前会话在学习者整个学习过程中的相对位置.
12)behavior_id为交互位置编码,它能够表示当前行为在当前会话中的相对位置.
13)dropout为学习者当前行为对应的退出状态.当学习者在当前行为后退出时,dropout=1,否则dropout=0.
为了训练和测试Uni-LSDPM, EdNet 数据集将以10∶8∶1∶1 的学习者数量比例被划分为预训练训练集、微调训练集、验证集、测试集,其中各部分数据集中划分的学习者数量与交互响应数量如表3所示.

Table 3 Dataset Statistics for Experiments表3 实验数据集统计
4.2 实验设置
在训练之前, 采用合成少数过采样技术(synthetic minority oversampling technique, SMOTE)[63]对dropout标签进行过采样,将dropout标签比率保持在 1∶1 左右.
我们使用在验证集中获得最佳 AUC 的模型参数在测试集上进行测试. 在每个Transformer 层中,每个多头注意力层由 8 个头组成. 模型采用的是 Adam优化器,学习率为 1E−3,超参数β1=0.9,β2=0.999.每组实验包含 10 个 Epoch,其中每个 Epoch 包含 100 个step,batch size 设置为 32.
4.3 实验设计和实验结果
4.3.1 输入序列长度与特征组合的消融实验
为了探究模型在什么情况下预测效果最好,我们对Uni-LSDPM 的输入交互序列长度l与输入特征组合进行了消融实验. 输入交互序列长度l指学习者特征序列涉及的学习者连续交互行为数,预训练与微调采用相同长度的输入交互序列. 输入特征组合具体的实验组情况如表4 所示,在基础实验组上增加目标特征,探究输入特征对预测结果的影响.

Table 4 Input Feature Combination Ablation Experimental Group表4 输入特征组合消融实验组
处理后的部分数据集、消融实验组训练后产生的最优训练权重参数及部分实现代码已公开至github①https://github.com/kabu-rui/Uni-LSDPM. 我们通过ROC 曲线下的面积(AUC)和预测准确率(ACC)指标对模型效果进行衡量. 不同时期消融实验的预测性能如图9 所示,该图描述了相应实验组中不同迭代次数下的 AUC 情况. 当模型欠拟合或过拟合时,AUC 值均约等于 0.5,且它们不会显示在图中. 每组消融实验的最佳结果如表5 所示.
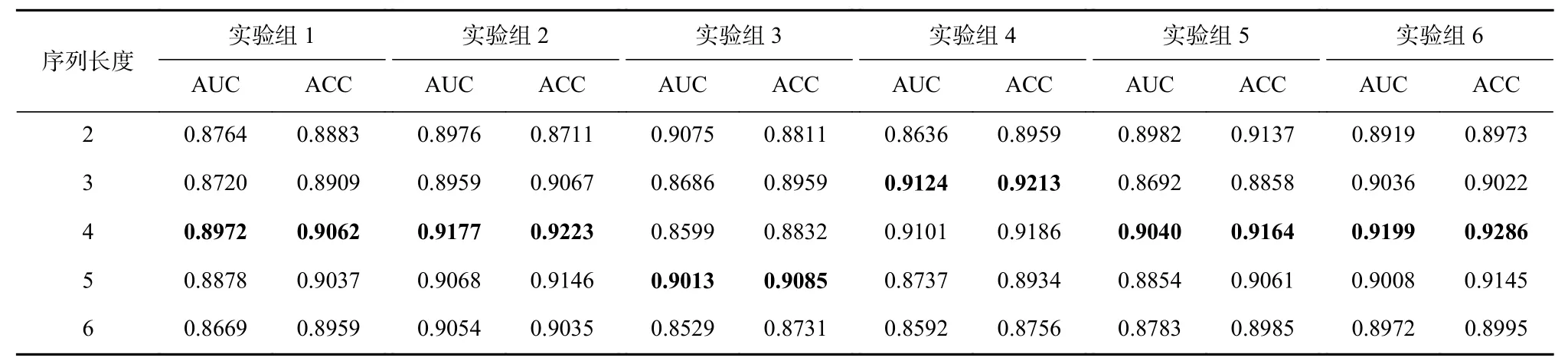
Table 5 Ablation Experiment Results for the Combination of Input Interaction Sequence Length and Input Feature表5 输入交互序列长度与输入特征相结合的消融实验结果
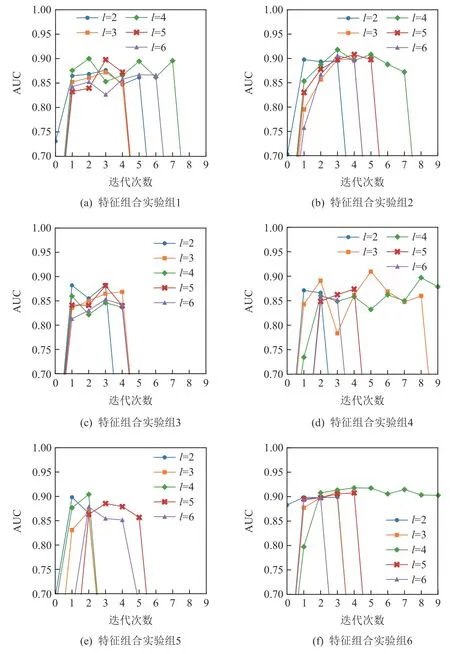
Fig. 9 Ablation experiments for different feature combinations and sequence lengths图9 针对不同特征组合和序列长度的消融实验
在不同序列长度和不同输入特征组合的情况下,模型均能够在经历不同个迭代次数后达到AUC 峰值. 结果表明,交互序列长度l=4 时,预测性能最好.这可能是由于l=2 和l=3 时,容易发生过拟合,虽然最高预测AUC 仍然能够达到0.9 左右,但不够稳定.因此能够得出,模型需要足够的上下文量来进行有效地预测. 随着学习行为数的增加,序列向量数呈倍数增长,导致模型需要学习的token 更多,使效果适得其反.
为了探索每组特征对预测效果的影响,我们在仅包含学习者行为静态属性特征的基础实验组上,控制变量加入目标特征(特征组合实验组2,3,4,5),以此来探究每组特征对预测效果的影响,并与设置包含所有特征的实验组6 进行辅助对比. 实验结果表明,实验组2 的AUC 值与实验组1 的最优AUC 值相比提升了2.05 个百分点,与实验组6 相比仅相差0.22 个百分点;实验组4 的AUC 值与实验组1 的最优AUC 值相比提升了1.52 个百分点,与实验组6 相比仅相差0.75 个百分点. 可以得出特征tl,c,ct能够显著提高预测效果,且效果接近添加所有特征的实验组6 的结果. 这表明学习者在相邻学习行为上的时间差、问答准确性和音视频播放光标时间与其会话退出概率具有一定相关性.
4.3.2 实例分析
除了输入特征对学习会话退出的影响,某些学习行为类型也能对学习会话退出预测起到关键作用.表6 为学习会话退出的典型案例之一,该表记录了一位学习者于2019-08-09 晚在Santa 在线学习平台中与id=1 180 的交互项目进行的一系列学习交互. 该学习者在这段学习交互中首先进入该项目题目页,播放音频后于17 378 光标处暂停该音频,作答题目后进行提交;随后进入该项目题目解析页,播放音频后与14 999 光标处暂停该音频,往后不再执行新的动作,发生会话退出.

Table 6 Instance of Learning Session Dropout表6 学习会话退出实例
在大量行为会话数据中,发生学习会话退出前执行的学习行为类型数量能够反映执行该学习行为类型后发生学习会话退出的概率. 我们选取了播放视频(play_video)、暂停视频(pause_video)、播放音频(play_audio)、暂停音频(pause_audio)、选择试题答案(respond)和提交试题答案(submit)这6 个典型的学习行为类型进行分析,学习者在执行这些学习行为后均有一定概率发生会话退出. 我们基于EdNet中93 189 667 条学习行为的真实数据,对其中发生学习会话退出前的学习行为类型和Uni-LSDPM 预测为会话退出前最近执行的学习行为类型进行了数量统计,对比结果如图10 所示.
在真实数据中,执行pause_video,play_audio,submit后的学习会话退出概率分别比执行play_video,play_audio,respond的概率大47.46%,54.38%,55.63%,且执行submit后的学习会话退出概率是执行其他学习行为类型后学习会话退出概率的2 倍以上.
将实例与学习会话退出前的学习行为类型统计结合分析显示,在执行了pause_audio,play_audio,submit这类行为后,学习者退出学习的概率更高. 其原因可能是该类行为标志了学习者已完成阶段性的学习任务,这时学习者具有更高的退出倾向. 反之,play_video,play_audio,respond这类学习行为发生后退出的概率则较低.Uni-LSDPM 预测的学习行为数量统计与真实数据中的学习行为数量统计相比,最大差距仅有7.48%. 该结果表明,Uni-LSDPM挖掘到了不同学习行为类型与学习会话退出概率之间的相关性,证明Uni-LSDPM 预训练-微调的训练模式能够较准确地获取学习行为特征上下文间的隐含关联,以支持模型对学习会话退出的准确预测.
4.3.3 对比实验
为了避免实验的偶然性,验证Uni-LSDPM 的鲁棒性和泛化性,基于其他ITS 中收集的不同数据集进行会话预测对比实验. 对比数据集收集于名为“学堂X”①https://xuetangx.com的ITS,学堂X 是目前中国最大的MOOC 平台之一. 它提供超过 1 000 门课程,并吸引了超过 10 000 000的注册用户. 数据集具体描述为:
1) 数据集1.该数据集包含 39 节教学模式的课程,涉及 112 448 名学习者的学习行为,其中包括1 319 032个视频活动、10 763 225 个论坛活动、2 089 933 个作业活动和 7 380 344 个网页活动.
2) 数据集2.该数据集包含 698 节教学模式课程和 515 节自学模式课程,涉及 378 237 名学习者的学习行为,其中包括 88 904 266 个视频活动、534 369 个论坛活动、10 912 803 个作业活动和 14 727 348 个网页活动.
这2 个数据集的预处理方式与 EdNet 相同. 处理后的数据集分别命名为 XuetangX 1 和 XuetangX 2.
我们将Uni-LSDPM 和7 个模型分别在数据集EdNet,XuetangX 1,XuetangX 2 上进行微调或训练,其中序号1~3 的模型为时序挖掘模型,序号4~5 的模型为预训练-微调范式模型,序号6~7 的模型为最近会话退出研究中性能表现较好的模型. 7 个模型分别为:
1) LSTM.该网络为经典的时序挖掘模型,采用3层结构,每层有 60 个神经元,用 Adam 优化器和交叉熵损失训练了 1 000 次迭代.
2) 可变长度马尔可夫链 (variable length Markov chain, VLMC). 使用 VLMC 对学习者交互项目序列进行建模. 最大上下文长度设置为 4,该设置与 Uni-LSDPM 相同.
3) M3PP.该模型对访问的单个页面的序列和在页面上花费的时间进行建模. 形式上将点击流建模为连续过程. 该模型在在线行为序列分析任务上效果较好[53].
4) UniLM[21]. 该模型为统一预训练语言模型,与Uni-LSDPM 同为预训练-微调范式,在该预训练模型参数的基础上对LSDP 任务进行微调.
5) BERT[20]. 该模型为双向注意预训练语言模型,与Uni-LSDPM 同为预训练-微调范式,在该预训练模型参数的基础上对LSDP 任务进行微调.
6) MLP[57]. 该模型为最新应用于LSDP 任务的有效方法. 该模型将学习行为数据建模为“句子”形式作为输入,以双矩阵结构建模学习行为特征序列,随着学习行为的增加更新矩阵参数.
7) DAS[19]. 该模型基于单层Transformer 实现了LSDP 任务. 在文献[19] 的研究中,效果最好的序列长度是 5,本文应用该结论进行对比实验.
学习会话预测实验对比结果如表7 所示. 在不同数据集上微调的实验结果显示:在数据集 XuetangX1和 XuetangX2 上进行微调的预测最佳 AUC 值也可以达到 0.882 5 和0.8594.基于用 EdNet 训练得到的预训练模型,在其他在线教育行为特征数据集上微调下游任务也能取得不错的效果.
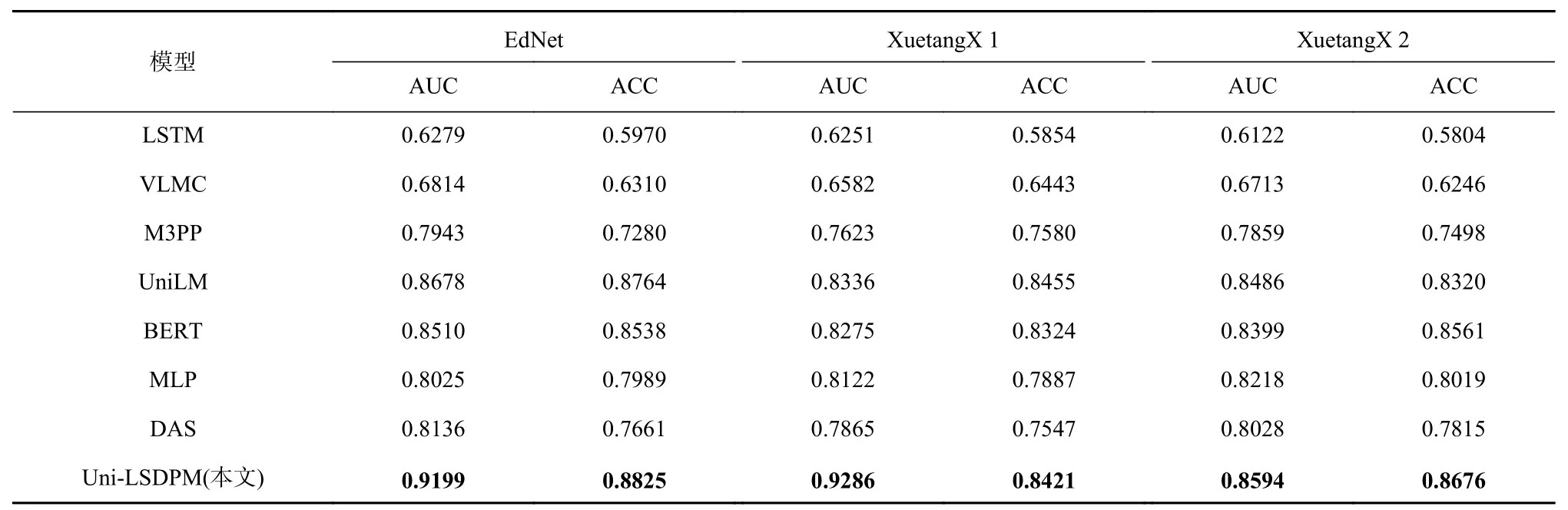
Table 7 Comparative Experiments of Different Models on Different Datasets表7 不同模型在不同数据集上的对比实验
在相同数据集上,Uni-LSDPM 优于其他对比实验模型. 与基于自然语言语料进行训练的UniLM 和BERT 相比,Uni-LSDPM 对学习行为序列挖掘更具有针对性,因此在LSDP 任务的表现上,Uni-LSDPM 比UniLM 和BERT 能得到更好的效果. 而UniLM 和BERT 与其他序列挖掘模型相比具有更突出的表现,证明预训练-微调范式在序列分析及标注问题上能够起到提升作用.
目前在LSDP 任务的现有模型中,MLP 和DAS模型在会话退出预测任务中表现最好. 由于基于EdNet 数据集进行预训练的Uni-LSDPM 对EdNet 数据集的预测更具有针对性,故不具有普遍代表性. 而基于XuetangX1 和XuetangX2 数据集,Uni-LSDPM 的最佳AUC 值与MLP 相比,分别提升了7.03 个百分点和3.76 个百分点;与DAS 模型相比,分别提升了9.60 个百分点和5.66 个百分点.MLP 采用多层感知器方法,利用双矩阵结构,将同一会话内发生的所有行为特征顺序输入,以矩阵形式更新参数进行训练,能够达到较高的预测准确率. 而Uni-LSDPM 通过对行为内部特征关联的预训练,不关注过久的行为特征对退出结果的影响,着重注意最新连续行为特征对预测结果的影响,实验证明Uni-LSDPM 能够达到理想的效果. 原因是预训练能够学习到连续行为特征之间的隐含关联,最新连续行为特征即可包含向前拓展的大量行为信息,能够反映学习者当前的学习状态以进行准确的退出预测. DAS 模型采用了Transformer 结构,通过多头注意力使模型能够同时注意不同位置和不同向量表示的信息,与LSTM,VLMC,M3PP 模型相比,DAS 能够在在线学习行为特征上下文中取得更好的学习效果. 与应用单层Transformer 进行Seq2Seq 的LSDP 任务的DAS 模型相比,Uni-LSDPM 在预训练阶段采用了12 层Transformer 结构,通过双向训练学习行为数据的上下文向量表示,充分学习了学习行为特征内部的隐含关联,并在此基础上再利用12 层Transformer 结构针对LSDP 下游任务进行单向微调,更多的参数量和上下文向量表示预训练对预测任务的准确率起到了很大的提升作用.
4.3.4 扩展性探究
Uni-LSDPM 分为预训练阶段和微调阶段,其中预训练阶段主要任务是对学习者在线学习行为特征中的隐含关联信息进行挖掘学习;微调阶段是针对下游任务LSDP 训练设计的. 为了验证Uni-LSDPM预训练模型是否能够适应更多基于在线学习行为特征的下游任务,将同为学习序列挖掘的KT 任务作为Uni-LSDPM 预训练模型新的下游任务进行探究实验,并将预训练模型在KT 任务中的应用模型SPAKT[49]作为对比. 针对下游任务KT 的微调模型标记为Uni-KT.EdNet 数据集包含学习者学习习题结果及正确答案,因此Uni-KT 和SPAKT 均基于EdNet 数据集进行对比. 与针对LSDP 任务的微调形式相同,Uni-KT 以Seq2Seq 注意力掩码方式进行训练. 引用文献[49]工作中SPAKT 在EdNet 上的实验结果. 实验结果如表8所示.
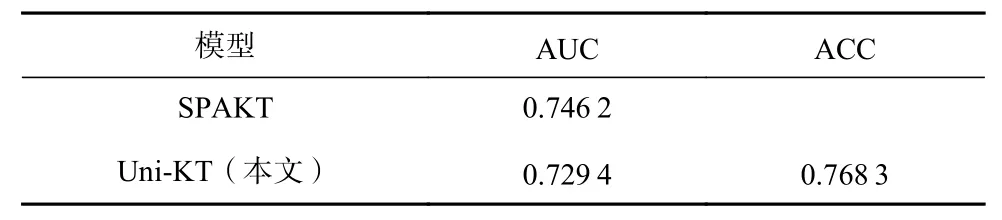
Table 8 Downstream Task Expansion Experiment表8 下游任务扩展实验
实验结果表明,Uni-KT 的最优AUC 值能够接近SPAKT 的AUC 值. 该结果证明,Uni-LSDPM 预训练模型能够适应除了LSDP 以外的其他基于学习行为序列挖掘的下游任务,并能够取得较好的效果,具有较强的扩展性和鲁棒性. 可以推测,若将更多的ITS行为特征数据用于预训练,丰富多平台的学习特征上下文训练语料,Uni-LSDPM 预训练模型将能够适应多样化基于学习行为特征的任务,例如基于学习者学习行为的知识追踪、教育资源推荐、学习路径规划等,并取得更好的效果. 因此,Uni-LSDPM 具有很强的鲁棒性和扩展性.
5 结 论
本文提出了一种基于预训练-微调的统一在线学习会话退出预测模型Uni-LSDPM.该模型在挖掘和理解相同学习行为特征之间上下文相关性以及连续学习行为之间隐含上下文关系的预训练基础上,针对学习会话退出预测任务进行微调. 通过消融实验获得Uni-LSDPM 最佳效果的序列长度和特征组合,实验结果表明,Uni-LSDPM 在EdNet 数据集上微调的最大AUC 值可以达到 0.919 9(+0.106 3),在其他数据集上微调的最大AUC 值可以达到0.882 5 (+0.070 3),均优于现有的模型. 在Uni-LSDPM 预训练模型的基础上微调其他下游任务的实验结果表明,Uni-LSDPM 能够扩展至更多基于学习行为特征的任务,证明Uni-LSDPM 具有很强的鲁棒性和扩展性.
在未来的研究和实际应用中,Uni-LSDPM 仍然有很多空间待进一步优化和拓展. 例如通过补充更多平台、更多种类的特征和行为来丰富预训练数据,得到更强鲁棒性的无监督学习行为特征上下文的向量表示;根据不同平台的特征数据对个性化微调模型进行调整,以适应各个平台的行为特征.
作者贡献声明:陈芮提出模型框架,设计并进行实验,撰写论文;王占全提出研究思路、修改论文框架、指导并修改论文.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
电线电缆(2018年2期)2018-05-19
家庭影院技术(2017年10期)2017-11-23
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
海外华文教育(2016年4期)2017-01-20
教育科学论坛(2014年8期)2014-03-01
