
复杂设备环境下的多状态负荷运行状态辨识方法
2024-02-21 09:40柳青刘小平陈浩张振宇朱彦卿李勇
电测与仪表 2024年2期
柳青,刘小平,陈浩,张振宇,朱彦卿,李勇
(1.国网湖南省电力有限公司供电服务中心,长沙 410004; 2.湖南大学 电气与信息工程学院,长沙 410082)
0 引 言
非侵入式负荷监测(Non-intrusive Load Monitoring,NILM)是指在用户用电入口处安装测量设备,采集电压、电流、频率、功率等电力数据,并将其分解为独立设备的用电状态、用电电量等信息的方法[1]。根据负荷监测得到的用户用电行为信息,可为电网公司的调度,需求响应等高级用电策略制定提供依据,也可为用户自我制定合理的用电规划提供参考[2]。
自从文献[3]在20世纪80年代提出非侵入式负荷监测的基本思想后,国内外学者已经针对该问题进行了大量的研究分析。对于这些研究,可以从使用的特征类型与算法类型两个角度对其进行分类。文中着重讨论使用的特征对负荷辨识的影响。从特征角度,可以分为稳态度量(电压、电流、谐波等有效值数据)、暂态度量(电压、电流等暂态波形数据)两大类。在其中,最典型的稳态度量是Hart提出的在有功功率与无功功率构成的复功率平面上进行聚类对设备分类的方法[3]。有功功率与无功功率可以说是最常见的特征,在文献[4-12]中均有提及与分析。文献[13]增广了稳态电流、暂态电流等典型负荷特征,进行降维后形成了负荷空间,并在负荷空间中进行设备的划分。文献[14-16]对设备特征进行了分析,使用了谐波特征进行负荷的分类,结果表明效果优于仅使用有功功率与无功功率。然而,这些基于谐波的方法仅是对于部分设备可区分特征的经验性总结,缺乏可拓展性。
另一类基于暂态波形的负荷辨识方法,一般基于每周波高达几十次至几百次不等的高频率采样与存储,在这种高频采样的情况下,很容易分辨出不同设备的特定波形与振幅特点[17]。但是由于高频采样对通信,存储与计算带来的压力,仅有少量的方法直接基于暂态波形进行负荷辨识[18]。然而,基于高频测量转化后的新特征方法被得到了广泛的应用。包括基于傅立叶变换的特征表达[19-22],基于小波的特征表达[23-25],基于高斯滤波与工业检测累加求和的边缘检测方法[26],以及基于V-I曲线的特征表达[27-31]。另外,这类方法通过对原始高频采样数据的加工,从中提取出可辨别性强的特征,并进一步的加以处理。
对于复杂运行状态中的设备辨识,常用于家庭环境下的聚类模型无法正常工作。来自中科院的结果表明,使用聚类的方法,无法从中得到具体设备的运行信息,仅能获得多设备整体的运行行为分析[32]。伯明翰大学[33]与牛津大学[34],早稻田大学[35]等进行的类似研究也表明,聚类等方法在较高的测量层级上能够分析负荷的整体行为,但却难以分离出具体到设备的行为。因此,较为合理的方法应是在合理的特征层级上,使用具备强特征提取能力的方法进行数据分析。
并且,在复杂设备环境下,由于多种变频负荷同时运行,会导致负荷的功率状态在一个较大的范围内波动,并且,多设备间可能存在运行状态耦合,从而产生仅与该环境相关,与具体设备无关的额外特征。对此,一种合理的解决方案是针对每一种设备进行针对性的建模与辨识,从而规避模型学习到多台设备间运行关联造成的额外特性,影响模型的迁移能力。也即是说,所谓的“单输入单输出”模型,在针对复杂设备环境下的负荷辨识,具备积极的意义。
虽然转化后的特征对负荷的辨识具有积极的意义,但是对这些特征的转化计算往往无法在测量同时完成,实质上这无法规避高频采样带来的巨大存储与通信压力。相对的,本文发现大多数较高等级的电能质量分析设备具备符合IEC 61000-4-30标准的测量,其中包括高频谐波的幅值,相角等高层次的信息,并且其相对的分析频率比高频测量要低得多。基于IEC 61000-4-30标准测量的负荷辨识算法有望成为一个合理的、介于高频采样与低频采样中的兼具高表达能力与低存储压力的合理表达方式。
基于IEC 61000-4-30的测量往往会带来巨大的特征空间。以日置的某型号电能质量分析仪为例,对三相电的测量而言,其可以每秒生成高达3 537种特征。极高的特征维度为下游的算法带来了表征的困难,并且显然会产生维度灾难,使得下游的算法面对的数据过于稀疏,降低算法的效率。
为了解决维度过高带来的问题,文中提出了一种使用皮尔逊相关系数的特征提取方法,并且进一步的,在提取的特征基础上,使用深度卷积神经网络作为辨识方法,从而实现了对中压配电网单设备运行状态的辨识。此外,为了表明提出算法的性能,将提出的方法与传统的支持向量机(Support Vector Machine,SVM)、K近邻分类(K-Nearest Neighbor,KNN)和决策树(Decision Tree,DT)算法进行了比较。
1 负荷状态辨识模型
1.1 负荷状态辨识问题定义

(1)
对典型的非侵入式负荷状态辨识任务而言,测量点的位置在待辨识负荷的上游。测量点下游其他负荷产生的特征可以认为是与不同特征相关的干扰噪声,因此式(1)可以添加噪声项后修正为:
(2)
该式可以表示负荷辨识问题的实质。在给定时间,给定测量特征中通过映射,得到指定负荷状态的问题可以定义为负荷状态辨识问题。
1.2 皮尔逊相关系数
皮尔逊相关系数(Pearson Correlation Coefficient)一般用来度量变量之间的线性相关程度。在文中,我们使用皮尔逊相关系数来度量特征时间序列Fi与状态时间序列S的相关性,用以在含噪多维特征中筛选出与负荷状态最相关的特征序列。
对于时长为T的特定的特征序列Fi与状态序列S,为求取两者间的皮尔逊相关系数,首先求取其均值:
(3)
(4)
以及二者的协方差Cov(Fi,S)和标准差σFi,σS:
(5)
(6)
(7)
最终可以求取得到两者间的皮尔逊相关系数:
(8)
皮尔逊相关系数的结果ρFi,S∈[-1,1],由于本文中的应用不关心具体是正相关或负相关,只关心两者间是否有相关关系,因此本文将得到的皮尔逊相关系数取绝对值,使用|ρFi,S|表示二者间的相关程度,该数值越趋于1,则越表示该特征与负荷状态之间的相关度越高。提取与负荷状态相关性最高的特征序列,即可完成特征筛选工作。
1.3 特征重映射
由于卷积神经网络一般需要的输入为二维多通道矩阵,与测量形成的一维时间序列不符,因此需要对原始测量数据特征重映射为二维多通道矩阵。
对于N维特征时间序列F={F1,F2,…,FN},目标是将其重构为形状为n×lw的二维矩阵M,其中n为筛选出的特征数目,lw是选择的时间窗长度。令该二维矩阵表示的特征对应的时间点为tp,则特征重映射过程可用下式表示:
(9)
为了提升特征的表达能力,也可以使用差分特征构建矩阵M:
(10)
经过特征筛选与特征重映射后,特征从多维时间序列变换成为了可供卷积神经网络处理的类图像的矩阵特征。
1.4 深度卷积神经网络
深度卷积神经网络一般由卷积层,池化层,全连接层,输出层以及对应的激活函数组成[36]。对于分类任务来说,卷积神经网络输入一般为二维多通道的矩阵,输出为一维向量。
1.4.1 卷积层
使用N表示输入的批量,Cin表示通道数,H表示矩阵的行数,W表示矩阵的列数。对于一个输入维度为(N,Cin,H,W)的四维矩阵而言,卷积层可以精确的表达为:
input(Ni,k)
(11)
其中*表示2维滑动点积操作符,i,j分别表示输出在矩阵中的位置,weight表示权重。一次完整的卷积操作,需要对输入的每个点周围分别进行式(11)中的运算。
1.4.2 池化层
文中采用的是全局平均池化,该池化层对每个通道进行计算,给定卷积核的尺寸(kH,kW)后,全局平均池化可以表示如下:
(12)
其中,sw,sh分别指池化层在长与宽方向跨步的步长。
1.4.3 全连接层
全连接层即为数据的线性关系。令输入向量为x,输出向量为y,偏置值为b,参数矩阵为A,则线性层可以表示为:
y=xAT+b
(13)
1.4.4 激活函数
本文中采用的激活函数主要为Relu函数,变量含义同上,函数可以表示为:
y=max(0,x)
(14)
1.4.5 深度残差网络
深度残差网络(Residual Neural Network, ResNet)由何凯明在2015年提出,并在同年获得了ImageNet大规模视觉识别赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)中的图像分类和物体识别的优胜。该网络由于采用了残差结构,所以非常容易优化。具体而言,以34层的深度残差网络为例,该网络的结构如图1所示。
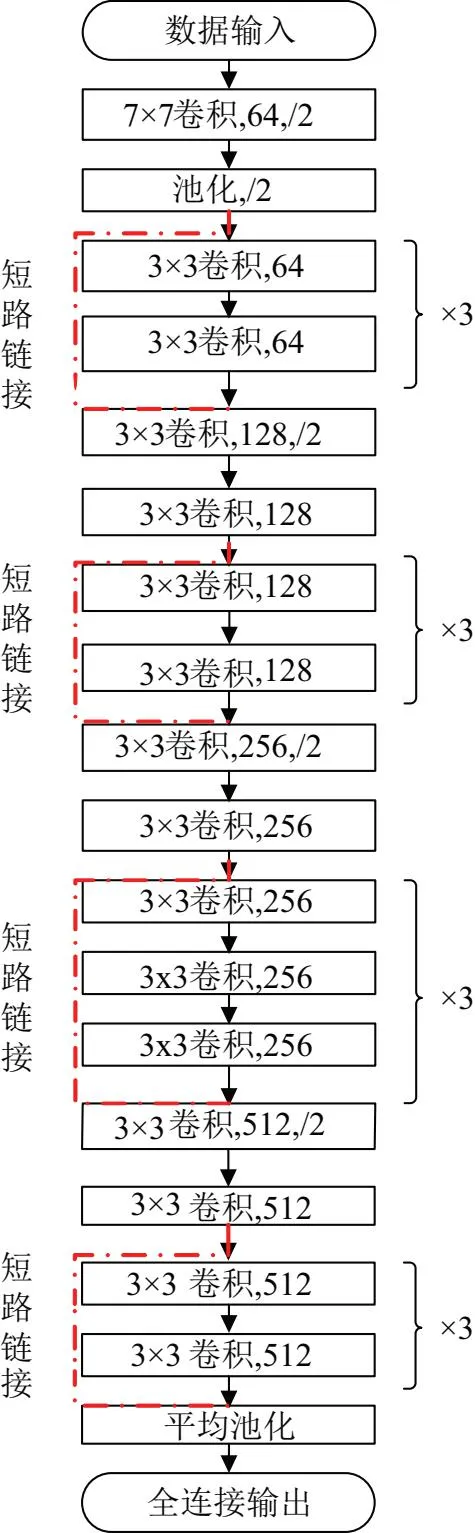
图1 34层的深度残差网络结构
深度残差网络具备卓越的信息提取能力,能够在图像中提取出原始数据的高效表征组合。在文中,使用深度残差网络来寻找隐含的模式,从而辨识出负荷对应的状态。并且,通过使用ImageNet预训练模型的方式,提升小样本情况下的模型特征提取能力。
1.5 基于深度学习与特征筛选的负荷状态辨识方法
基于以上几个部分,提出了一种基于深度学习与特征筛选的负荷状态辨识方法,如图2所示。首先针对原始数据,选择目标测量中可以表征负荷状态的特征,一般来讲可以选择电流特征。其次,对该负荷状态表达特征与辨识测量点所产生的特征进行差分,计算两两的皮尔逊相关系数,选取相关系数最高的n条数据作为筛选后的特征。随后,经过特征重映射,将其转化为深度残差网络可以处理的格式,然后进行训练,最终得到预测模型。
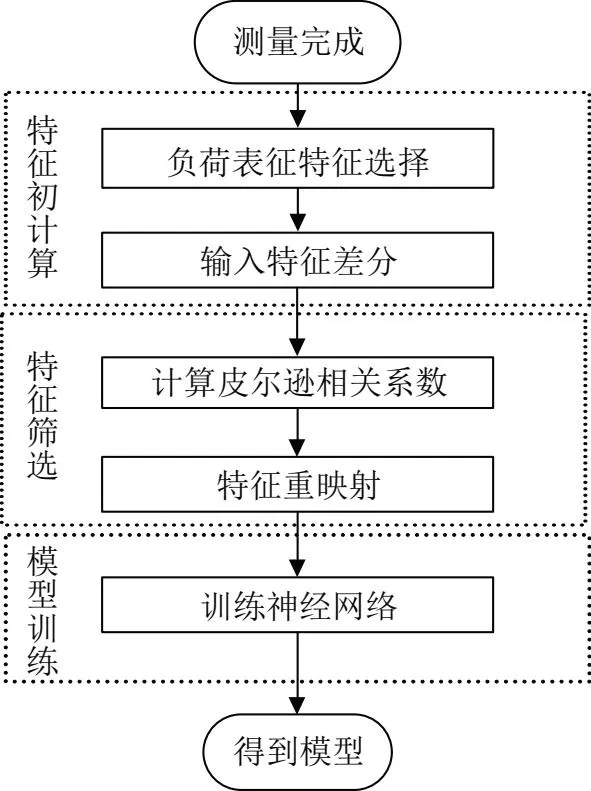
图2 所提方法的流程图
在特征重映射与特征筛选过程中,可以通过差分的方式来增强特征的表达能力,从而避免持续的背景功率噪声对负荷状态辨识的影响。
值得注意的是,图2中所述的负荷辨识训练方法是针对单种负荷而言,对于多测量装置下接入的不同负荷,可以采取并行的方法进行多设备识别的处理,具体的流程如图3所示。左侧部分是进行训练的方法,具体而言应将不同设备的运行时在对应的测量表中进行标注,随后根据设备种类来保存设备的模型,并最终保存入多设备模型库中。在推理阶段,根据需求识别设备的不同,分别对多个表计采集的数据进行推理,并最终合并结果获取多设备的运行状态。
2 实验方法
2.1 数据采集方法
文中的数据集采集自某学校的教学楼,其配电间的连接关系图如图4所示。
测量点1为总测量,是该配电所的总进线。测量点2与3测量的是电梯的负荷线。三台设备之间时间同步,采样频率为1 Hz。采样共进行一周,从周五的17:12至下周五的17:01。在采样期间,教学楼正常的进行教学工作。文中将电梯电流大于1 A的状态定义为运行状态。
计算使用的特征为所采集到的特征种类,包括:电压、电流、有功功率、无功功率、各次电压电流的谐波与半谐波的有效值与相角,三相不平衡度等参数的最大值、最小值、平均值。经过统计,每台设备共产生3 537种有效测量特征。
其中,测量点1的数据用于算法训练的输入数据,测量点2与3仅用作算法训练的结果反馈,以及正确率计算的依据。训练中不采用所有数据进行训练,仅采用一周中某几个小时的数据。文中的训练仅取一个小时的测试数据,也就是约占全部采集数据的0.59%的数据量测试其在极端小样本条件下的算法性能。通过仅取白天的运行数据作为训练,可以测试其在夜晚的泛化性能,进而可以推断在其他不同时间的推理性能。
2.2 算法性能测试指标
对非侵入式负荷辨识算法,常用实际为正预测为正的真正例(True Positive, TP),实际为负预测为正的假正例(False Positive, FP),实际为正预测为负的假负例(False Negative, FN),实际为负预测为负的真负例(True Negative, TN)作为分类算法性能度量的标准[37]。使用以上四种定义,可以进一步的定义精确率P(Precision)、召回率R(Recall)、准确率A(Accuracy)以及F1-score[38]。
精确率指真正例与所有预测为正的案例的比值,用来表示算法抗误检的能力,定义为:
(15)
召回率为所有正测试案例中算法识别为正的比例,表示算法抗漏检的能力,定义如:
(16)
准确率表示测试中预测正确的案例占全部案例的比值,一般而言准确率是算法优化的第一目标:
(17)
F1-score为一个平衡了精确率与召回率的指标,可以较综合的反应不平衡数据条件下的算法性能:
(18)
3 实验结果
电梯的负荷辨识属于难以使用传统策略的负荷辨识难题,主要原因在于其有功功率与无功功率的变化范围十分广泛,如图5所示。不同于传统的单状态或多状态负荷,电梯的功率状态受承载人数,上升或下降,楼层跨度等多种因素影响,呈现出复杂的负荷状态。

图5 电梯负荷的有功功率(P)与无功功率(Q)的联合分布
尽管对电梯的高分辨率能耗进行建模是复杂的[39],但是得益于数据驱动的策略,可以略过建模分析而直接提取出对辨识具有作用的相关特征。本文设定两种特征策略,一种是使用皮尔逊相关系数对差分的特征向量进行计算,进行特征提取,另一种是采用常规非侵入式负荷辨识算法中的低次电流谐波有效值及相角,两种特征策略均选择50种特征作为算法的输入。通过皮尔逊相关系数,可以提取出与负荷运行状态高度相关的特征,有助于增强特征的信息密度。
图6展示了使用皮尔逊相关系数筛选出的相关性最高的9组特征,具备高相关性的数据,其分布应近乎在一条直线上。与图7中的低次电流谐波特征相比,可以看出前者的变量间具有更高的线性相关度,二者的变化几乎呈现线性关系。而常规特征中的一些特征与电梯的负荷并不具备十分强烈的相关关系,其实质上输入对电梯辨识无效的特征。综合对比图5与图6,可以发现使用皮尔逊系数筛选出的特征具备更好的相关性。
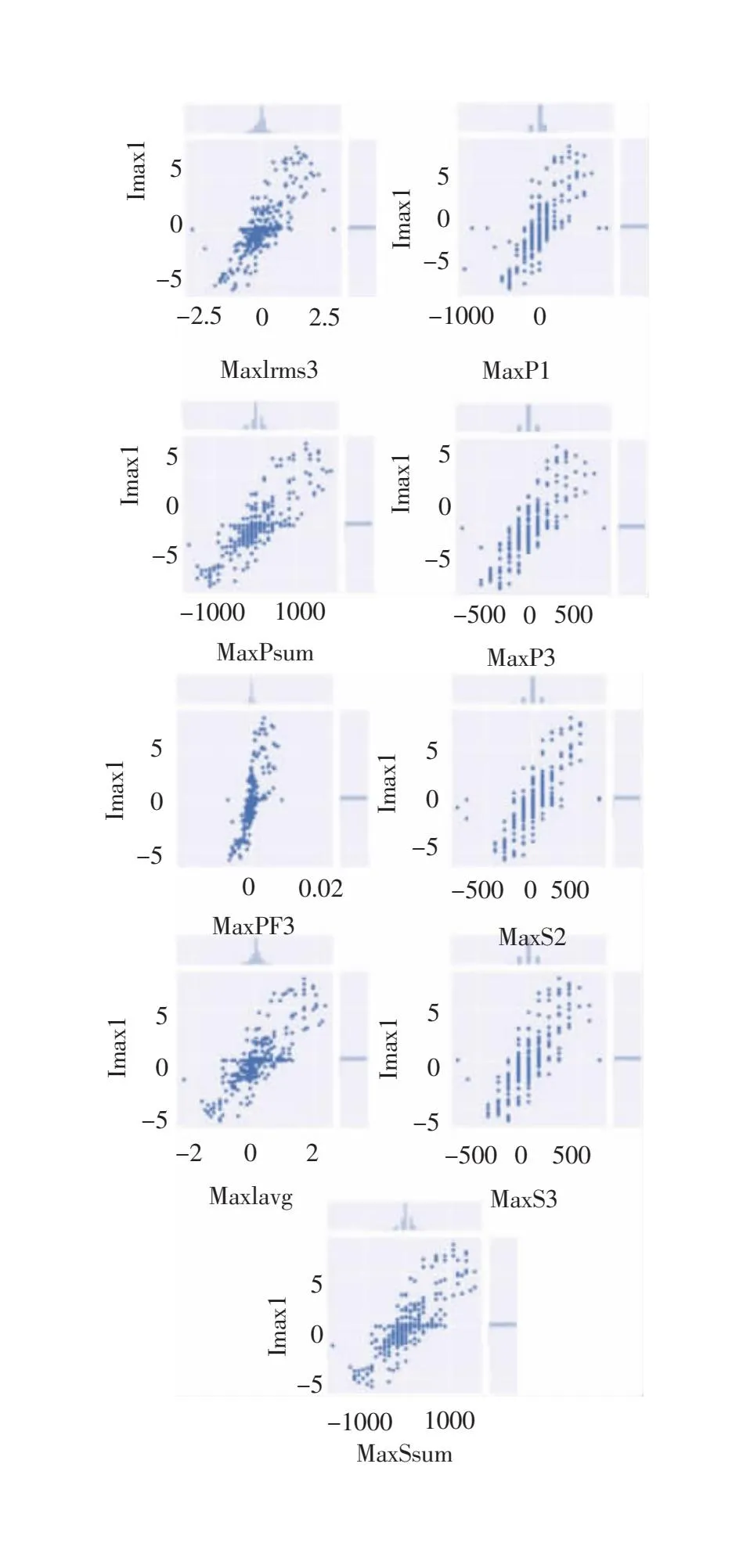
图6 皮尔逊系数法筛选出的特征与电梯电流的联合分布图
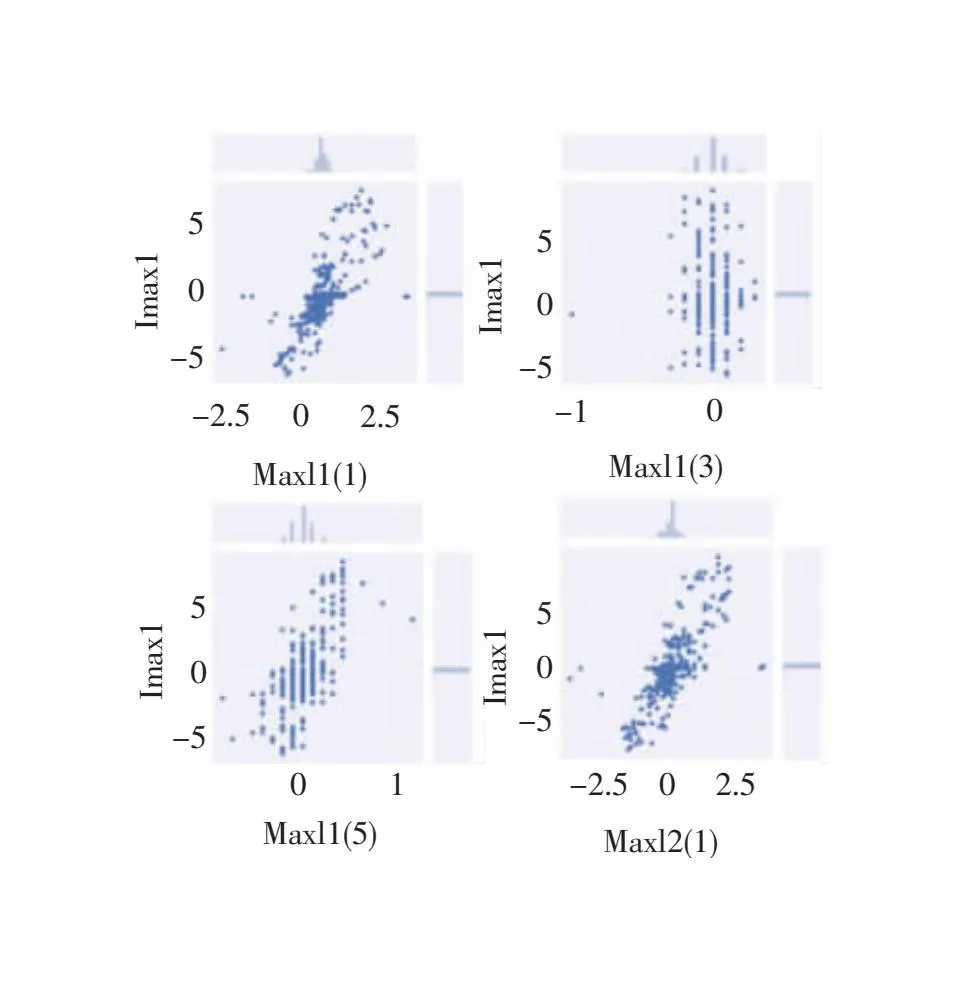
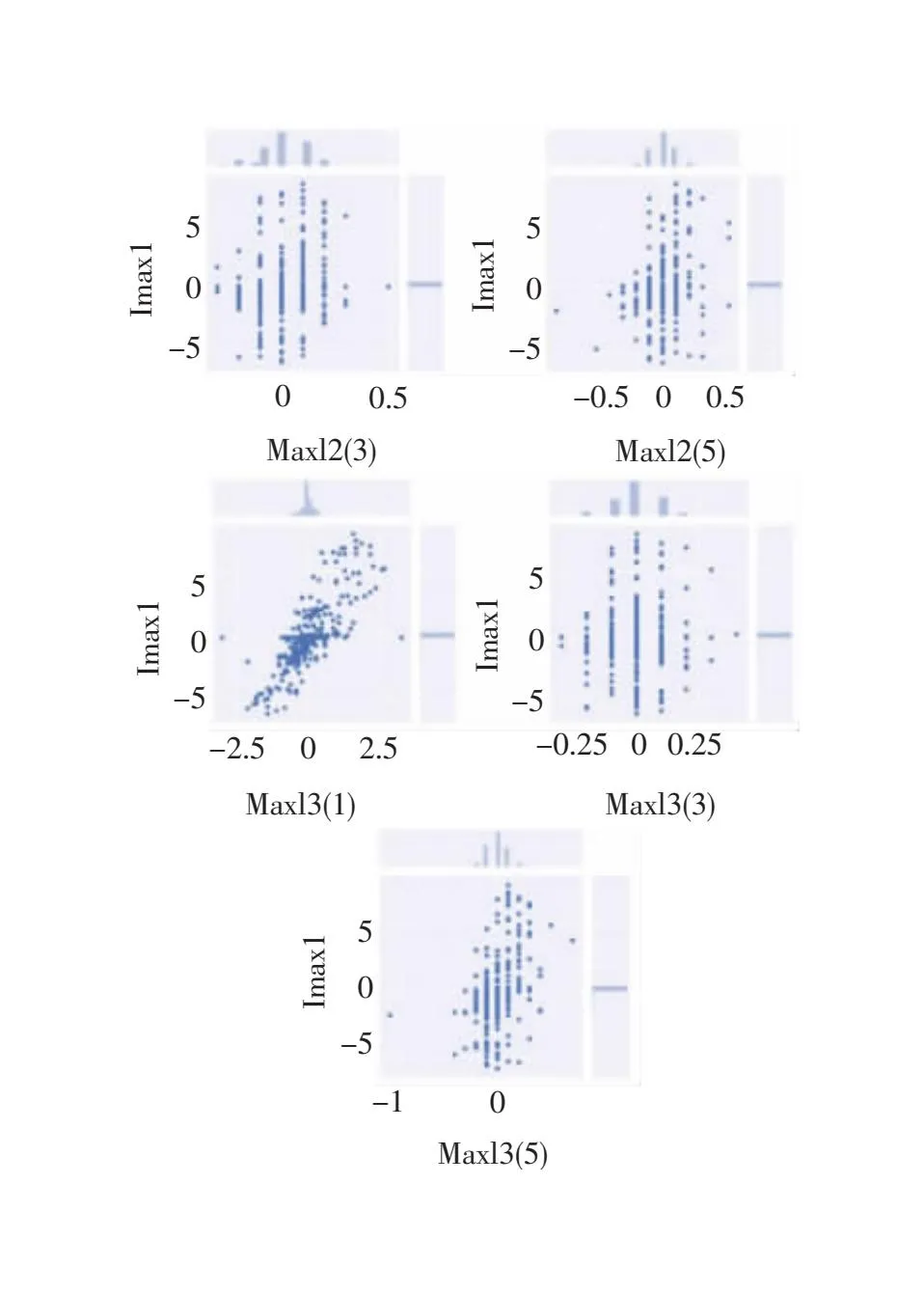
图7 常规电流特征与电梯电流的联合分布图
在辨识算法上,对比了KNN、SVM、决策树、Resnet以及预训练的Resnet共五种模型,运行状态辨识的准确率结果见图8,F1-score的结果见图9。

图8 0.59%数据量训练的准确率结果
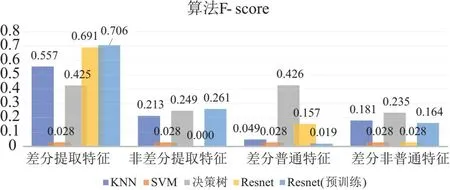
图9 0.59%数据量训练的F1-score
算法辨识的目标是通过总入口处的变压器采集的数据,判断电梯是否处于运行状态。图9中,可以发现具有最高准确率的模型是经过了预训练的Resnet模型。除此以外,结果还表明:(1)预训练的Resnet模型在差分的特征输入条件下具有较强的学习能力;(2)使用皮尔逊相关系数提取特征对算法水平的提升具有强烈的正效应;(3)即使在小样本的条件下,通过合适的特征提取方法,也能使得机器学习算法正确的提取出关键的特征组合。这在图8中展现的算法的F1-score比较中更为明显。对结果的分析说明了结合特征筛选与深度神经网络的负荷状态辨识方法的有效性。
4 结束语
本文提出了一种基于皮尔逊相关系数的特征筛选方法与深度神经网络的复杂设备环境中多状态负荷状态辨识方法。该方法能够在仅提供少量训练样本的情况下,取得较高的电梯负荷运行状态辨识成功率。实验的结果表明了提出方法的有效性,并且指出:(1)对特征进行差分能够更有效的帮助机器学习算法对负荷状态的特征组合进行学习;(2)图像识别的预训练对负荷状态辨识存在积极的效果。在未来的研究中,可以进一步地引入更大范围的时间依赖关系,从而捕获负荷的时间尺度上的行为与状态的关系。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
初中生世界(2020年43期)2020-12-18
初中生世界·九年级(2020年11期)2020-12-02
电子制作(2019年11期)2019-07-04
教育教学论坛(2019年7期)2019-03-18
科学与财富(2018年16期)2018-08-10
北京航空航天大学学报(2018年1期)2018-04-20
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
核科学与工程(2015年2期)2015-09-26
