
面向机器学习的数据库参数调优技术综述
2024-03-03 11:21姜璐璐高锦涛
计算机工程与应用 2024年3期
姜璐璐,高锦涛
1.宁夏大学 信息工程学院,银川 750021
2.宁夏大数据与人工智能省部共建协同创新中心,银川 750021
数据库管理系统(DBMS)经过半个多世纪的研究和发展,获得了快速的技术进步和优异的性能表现,这其中少不了DBA 凭借丰富的个人经验,对众多数据库系统的参数进行调优。数据库系统参数众多,并且参数值易变,参数之间还存在逻辑关系。随着数据库和应用程序的数量增加,依靠DBA 对数据库参数进行调优变得十分困难,因为DBA 可能只熟悉部分数据库参数的调优方式,并且调优过程是启发式的,不能保证全局最优。而找到全局最优参数配置是一个NP-hard 问题[1],因此需要探索其他解决方案。
机器学习是一门研究如何设计算法、利用数据使机器在特定任务上取得更优表现的学科,具有泛化能力和自我学习进化的能力,至今机器学习研究已经取得大量令人瞩目的成就:在图像分类任务上的识别准确率超过人类水平,能够生成人类无法轻易识别的逼真图像等。而数据库领域学术界和工业界共识的研究重点是将机器学习与数据库系统进行融合统一,自动化处理各种任务,这其中就包括基于机器学习的数据库参数调优。2019 年6 月,Oracle 推出云上自治数据库Autonomous Database;2020 年4 月,阿里云发布“自动驾驶”级数据库平台DAS;2021 年3 月,华为发布了融入AI 框架的openGauss2.0 版本。国内外IT 企业纷纷将机器学习融入到自身数据库系统的参数调优中[2]。
数据库调参技术是指通过调整数据库内部相关旋钮参数,从而提高系统性能的一种方式。对近些年数据库参数调优技术进行系统研究,基于时间维度,研究针对传统参数调优技术,从2017 年到2022 年之间的基于机器学习的参数调优方法,按照技术-问题-解决方案的思路,以树形结构有条理地给出具体的研究技术、存在的问题以及解决这些问题的方案,如图1,不仅能够使参数调优领域的研究者对近6 年的相关工作有一个整体的认识,而且能够提供将来的研究方向。从技术角度,将大方向划分为传统调参技术、基于BO(Bayesian optimization)模型的调参技术以及基于RL(reinforcement learning)的调参技术,而基于BO模型的调参系统与基于RL 的调参系统分别以OtterTune(GPR)与CDBTune 为基础,对其存在的问题进行总结,然后根据问题描述目前存在的解决方案,最后分析该解决的方案又存在的某些问题,给出研究展望。

图1 数据库参数调优研究思路Fig.1 Research ideas for database parameters tuning
本文按照图1的研究思路,从如下三个方面介绍数据库参数调优系统的演化路径。
第一类为传统参数调优技术。传统参数调优技术分为基于启发式算法的与基于辅助决策的参数调优技术,基于辅助决策的参数调优技术包括基于规则的与基于经验模型的参数调优技术。
第二类为基于BO模型的参数调优技术。早期被研究出基于BO 模型的系统之一为OtterTune(GPR)[3],它实现了自动化调优,当然它也存在着众多问题。比如在大数据集和高维特征向量表现不佳、没有对分布式数据库进行处理、调优时间长不能反应真实的工作负载或者调优复杂等等。针对上述问题,OtterTune(DNN)[4]、RelM[5]、OnlineTune[6]、CGPTuner[7]、ResTune[8]、Llama-Tune[9]等对上述问题提出了对应的解决方案。OtterTune(GPR)与CDBTune将调优思路集中在提高吞吐量和延迟上,而没有同时优化资源和SLA。基于此,ResTune将调参问题抽象成带限制的优化问题并且采用了带限制的EI 函数来解决上述问题。对于RelM 系统,它解决OtterTune(GPR)与CDBTune等调优系统没对分布式数据处理系统调优的问题,提出加快勘探需要一种基于改进的策略,该策略遵循基于序列模型的优化(SMBO),并且使用RelM 的分析模型来加速BO。由于OtterTune(GPR)与CDBTune 推荐的配置中有50%~70%比默认配置更差,且调优时间长,用户调优成本也较高,因此OnlineTune提出上下文特征化模型,能够有效降低计算复杂度和模型选择策略。CDBTune 系统使用DDPG 算法进行参数调优,该算法使用神经网络进行调优,模型复杂,需要多次迭代,因此LlamaTune 提出基于随机投影的自动降维技术并且用一种偏差抽样方法来处理特定旋钮的特殊值,以及旋钮值桶化。OtterTune(DNN)针对原有OtterTune系统中GPR高斯过程模型在较大数据集和高维特征向量上表现不佳等问题,将GPR 模型改为DNN 模型,也提出dropout 正则化技术,将高斯噪声添加到神经网络参数中。针对OtterTune考虑更多IT堆栈层,导致搜索空间的维度呈指数增长,提出基于上下文高斯过程的CGPBO。Tuneful[10]是对Spark 大数据分析引擎的性能进行优化,解决了之前未从成本效益上进行调优的问题。
第三类为基于RL 的参数调优基数。最早使用RL进行参数调优的系统为CDBTune[11],CDBTune基于深度学习框架,存在调优时间长、多次运行工作负载耗时、不能针对特定工作负载进行调优、神经网络复杂需要多次迭代时间较长等问题。Hunter[12]、QTune[13]、WATuning[14]等提出一系列解决措施。CDBTune采用DDPG算法,但DDPG没有考虑工作负载特性。WATuning系统在原有DDPG算法基础上增加注意力机制。QTune针对CDBTune系统多次运行负载耗时问题,提出DS-DDPG模型,并提供三种数据库调优粒度。Hunter采用混合结构解决冷启动问题,并利用遗传算法生成的样本预热DDPG算法。
参数调优系统常见术语的术语表,如表1所示。

表1 数据库参数调优常见术语Table 1 Glossary of common terms for database parameters tuning
为了帮助研究人员与开发者更好地把握当前参数调优系统的发展状况,按照使用的技术的不同将参数调优系统分为三个不同的方面,分别对这三个方面做进一步的综述:
(1)第1章概要介绍数据库传统参数调优技术的研究情况以及存在的问题与挑战;
(2)第2章概要介绍数据库基于BO 模型的参数调优技术的研究情况以及存在的问题与挑战;
(3)第3章概要介绍数据库基于RL 的参数调优技术的研究情况以及存在的问题与挑战;
(4)第4章概要介绍数据库参数调优技术的研究情况,并进一步探讨数据库研究的发展趋势。
1 传统参数调优技术
传统参数调优技术主要依靠DBA 的知识与经验,DBA 通过反复实验得到统计数据,以此决定配置方案。这种方式本身存在很多不确定性,完全基于启发式的方法大概率会造成局部最优甚至是更加劣化,在此过程中还需要DBA 掌握大量相关知识,并且在有限资源下,不可能会遍历所有的空间来找到最优解,需要进行数据库自动调优[15]。
1.1 辅助决策的参数调优技术
传统的参数调优技术除了DBA根据经验手动调参之外,还有一些可以辅助数据库管理员调参的工具。按照工具使用技术的不同可以分为两大类:基于规则的参数调优技术和基于经验模型的参数调优技术[16]。
(1)基于规则的参数调优技术
第一类是基于规则的参数调优技术,它是根据某一个数据库特定的需求设计出来的。系统根据用户需求,给出参数调整意见。最常见的基于规则的参数调优技术是MySQLTuner[17],通过收集数据库状态信息,根据确定的规则推荐给用户参数配置。这类调参技术虽然比手动调参不确定性小,但由于它是针对某一特定数据库需求进行设计,若面对不同数据库或用户需求,则需要重新设计规则,普适性较差。
(2)基于经验模型的参数调优技术
第二类是基于经验模型的参数调优技术,该方法需要通过大量实验发现旋钮与数据库性能之间的关系,并将结果返回给数据库调参专家,调参专家通过可视化结果直观地分析数据库参数的值,选出符合用户需求的配置进行调优。但这种方法跟基于规则的参数调优技术类似,也是针对用户需求进行调优。当数据库用户需求发生改变时,该方法按照之前需求推荐的配置则不再适用。调优过程需要经过大量实验,当使用场景改变时,实验也需要重新进行,耗费大量资源。Wei 等人[18]提出的一种基于模糊规则的调优工具,主要包括三个阶段:首先从自动负载仓库(automatic workload repository,AWR)中提取参数调优相关数据,利用自动负载仓库获取负载、数据库状态、表现统计等信息;然后,系统通过在不同配置下重复执行负载,观察不同配置下系统调优结果,总结出调优相关“模糊规则”,这些模糊规则只针对特定用户需求,不具有普适性;最后,经过训练数据得到经验模型,根据用户需求进行参数配置推荐。
1.2 基于启发式算法的参数调优
基于启发式算法的参数调优技术通过给定提前设置好的规则进行搜索来找出需要进行调优的参数,Best-Config[19]系统使用启发式算法自动检测整个参数配置过程。BestConfig系统流程图[19]如图2所示。

图2 BestConfig调优流程Fig.2 BestConfig tuning process
在负载生成模块(workload generator)中,BestConfig 主要使用benchmark 工具。并且该模块直接与SUT(system under tune)交互。性能优化模块(performance optimizer)将抽样方法DDS(divide and diverge sampling)和优化算法RBS(recursive bound and search)结合起来作为一个完整的解决方案。这也是该调优系统主要的两个算法。具体流程为:首先将整个N维参数空间离散化,采用DDS抽样方法进行抽样,然后将每个参数的取值范围划分为k段,每一段随机取一个值,这样整个参数空间可以转化为kN个点组成的样本空间,并且为了保证抽样的多样性,要求每个参数值只能被取样一次,然后使用RBS优化算法进行优化,在每次抽样的空间中随机选取6 个样本进行测试,得到最好的点,再以最好的点为中心划分出下一个示例区域这样迭代,直到不能得到表现更好的点或者达到资源限制为止。
上述所描述的几种传统的基数调优方法主要体现了两种思路:第一种是专家根据经验给出对于特定场景下的调优规则;第二种探索参数空间进行抽样,在有限资源下找到表现最好的区域。但是上述两种思路,无论是专家依据经验给出的参数调优规则,还是依据抽样算法来进行参数调优,都不能很好地推荐提高系统性能的参数配置,即只能达到局部最优解。而且每次参数调优都是从头开始进行实验配置,不能利用之前的实验来进一步优化模型,这不仅会浪费大量的资源,也会因为一些条件的限制也往往得不到最优的结果。例如,Best-Config使用启发式方法从历史数据中搜索最佳配置,如果历史数据质量不高或者缺失,则会严重影响效果。
2 基于BO模型的参数调优技术
现有的基于BO 模型的参数调优系统基本采用BO模型来建模参数与数据库性能之间的关系。首先拟合概率代理模型,然后通过最大化采集函数选择下一个配置来评估。现阶段有众多学者提出基于BO 模型的系统。基于BO模型的部分调优系统对比如表2所示。

表2 基于BO模型的参数调优技术对比Table 2 Comparison of parameters tuning techniques based on BO
2.1 GPR-OtterTune
数据库中有成百上千的旋钮,不同的旋钮组合制约系统性能。企业会雇佣专门的数据库管理专家进行调优,但专家往往是根据先前知识与经验进行调优。并且,使用场景和工作负载会不断变化,导致企业在系统维护方面投入大量资源,从而导致总体系统管理成本不断增加。一些科学家在20世纪90年代初就提出实现自动数据库调优的想法,但并未引起广泛关注。
卡耐基梅隆大学数据库研究组开发GPROtterTune[20-22](在下文中简称为OtterTune),能够根据用户需求自动为数据库系统的旋钮找到合适的设置[20-21],且操作较为便捷。OtterTune系统是根据对之前数据库系统调参的知识来推荐新的参数配置,这个过程由系统自动获取。与OtterTune不同,iTuned不会使用从以前的调优会话收集的数据来训练其GP 模型。文章使用OtterTune 和iTuned 生成的配置对TPC-C 工作负载的OLTP DBMS 进行比较。对比分析得到OtterTune 在MySQL 的前30 min 和Postgres 的前45 min 内找到了这个更好的配置,而iTuned需要60~120 min才能生成为这些系统提供任何重大改进的配置。所以OtterTune充分利用之前数据可以节省大量调优时间。具体做法为:OtterTune 将之前调参时所用的数据记录到知识库,然后用这些数据去构建模型,进而根据用户需求推荐给新的数据库系统参数配置。OtterTune分为客户端和服务端。OtterTune 的客户端安装在目标数据库所在机器上,也就是用户需要调参的数据库所在的机器上,然后收集目标数据库的统计信息,并上传到服务端。服务端一般配置在云上,它收到客户端的数据,训练机器学习模型并推荐参数文件。在此过程中客户端接到推荐的参数配置文件后,配置到目标数据库上,测量其性能。以上步骤可以重复进行直到用户对OtterTune推荐的参数文件满意。当用户配置好OtterTune 时,它能自动地持续推荐参数文件并把所得结果上传到服务端可视化出来,而不需要数据库管理员的干预,这样能大大简化数据库管理员的工作。
首先在数据预处理阶段,使用因子分析(factor analysis,FA)的降维技术,将度量减少到更小的因子集合。然后将FA输出结果以散点图的形式输入到k-means聚类算法中,k-means 聚类算法将相邻的因素进行分组,从每组中选取一个具有代表性的指标,达到降维的目的。
利用上述方法将度量降维后,继续计算对目标函数影响最大的旋钮的排序列表。论文使用了Lasso[23]特征选择方法,其中旋钮数据作为输入X,输出的是结合已经修剪过的度量的目标数据。Lasso 在X和Y之间的回归过程中确定了重要的旋钮顺序。它从一个高惩罚设置开始,其中所有的权重都为零,因此在回归模型中没有选择任何特征。然后减少惩罚,重新计算回归,并跟踪每个步骤中将哪些特征添加回模型。旋钮在回归中首次出现的顺序决定了它们对目标指标的影响程度。得到旋钮顺序后,需要在调优会话的每次迭代结束时生成新的配置建议。第一步是确定OtterTune过去调优的工作负载中哪一个与当前工作负载最相似。它利用先前数据来引导新的配置。OtterTune 基于GPR 算法,采用高斯过程作为先验函数,计算测试点与所有训练点[24]之间距离。该算法利用核函数来预测测试点的值和不确定度。OtterTune系统流程图[20]如图3所示。

图3 OtterTune调优流程Fig.3 OtterTune tuning process
虽然OtterTune系统可以自动为DBMS找到合适的旋钮配置,但面对大数据集和高维特征向量可能表现不佳。并且大数据场景下无法进行并行处理,严重影响系统性能。
2.2 DNN-OtterTune
OtterTune 的高斯过程模型在大数据集和高维特征向量上表现不佳[5],为了改正这一点,文献[4]将GPR 模型改为DNN模型[25-26]。DNN依赖于对输入应用线性组合和非线性的深度学习算法。DNN模型的网络结构有两个隐含层,每层有64个神经元。所有各层均以ReLU作为激活函数完全连接。DNN-OtterTune 实现了一种称为dropout正则化的技术,以避免模型过拟合,并提高其泛化[27]。DNN 还在旋钮推荐步骤[28]期间将高斯噪声添加神经网络的参数中,以控制勘探与开发的数量。DNN-OtterTune 通过降低噪声的规模,在整个调优过程中提高了数据的利用率。
文章对比了GPR、DNN、DDPG 和DDPG++4 个算法,并给处理生成的优化配置在3 个VM 上的平均性能改进的数据。经过对比分析GPR 在4 个算法中总是快速收敛,但是GPR 很容易陷入局部极小值。DNN 的性能是整体最好的,而DDPG和DDPG++需要更多的迭代次数才能达到好的优化性能。
DNN-OtterTune 虽然能够解决OtterTune 高斯过程模型在较大数据集和高维特征向量上表现不佳的问题,但DNN神经网络过于复杂,不利于扩展。
2.3 RelM分布式系统
近些年,由于数据规模和业务访问负载越来越大,集中式数据库逐渐出现性能瓶颈,需要分布式数据库系统进行支撑。Kunjir等人[5]研究在现代分布式数据处理系统中自动调整内存分配问题,提出RelM算法,大大降低基于BO[29]和DDPG[30]等算法探索最优参数配置的开销。RelM系统能够在现代分布式数据处理系统上运行的应用程序上自动调整内存分配,流程图如图4所示。

图4 RelM调优流程Fig.4 RelM tuning process
首先应用程序配置文件交由统计数据生成器处理,生成一组统计信息。然后枚举器模块通过初始化器和仲裁器运行每个容器大小配置。给定容器大小和应用程序配置文件中的统计信息,初始化器模块独立优化每个池的内存池,设置初始值。仲裁器仲裁初始化器分配给各个池的内存,以确保可靠性和低GC开销,并计算生成配置的效用分数。最后,选择器根据其效用得分对每个探测容器配置的最佳设置进行排序,并返回最佳设置作为最终建议。
RelM 不是直接对高级调优目标(如延迟)进行建模,而是针对内存配置对系统资源利用效率和执行可靠性的影响进行建模,因此能够使用极少量(1~2次)的文件配置快速调整内存管理选项。RelM 核心是一组模型,用于估计应用程序中各种竞争内存池的需求。使用这些模型,保证了一个安全的、高资源利用效率的配置。RelM能够理解基于内存的数据分析系统中的内存管理中多个级别算法之间的交互,并使用它们构建分析解决方案,以自动调整内存管理旋钮。RelM 提出引导贝叶斯优化(GBO)[31],GBO 为被测应用程序提供一个配置和一组配置统计信息。该模型输出一组导出的度量,除了用于优化的原始配置选项之外,还使用简单的分析模型导出额外的度量,目的是从更昂贵的区域中分离出配置空间最合适的区域。与SBO[31]相比,GBO不需要专家通过在调整时观察系统性能来设计参数模型,而是使用白盒模型简化此过程,并且从可靠性、效率等相关的应用程序配置文件导出度量后插入到BO模型中,进而适应于各种类型的工作负载。为了加快最优配置的探索效率,RelM 提出一种基于序列型优化方法:SMBO改进的策略[32],能够在拟合代理模型和使用它推荐下一个探针之间进行迭代。
RelM 是分布式框架,解决了大数据场景下普通调优系统调优性能的问题。但是泛化能力有限,不能较好地适应新的工作负载。
2.4 OnlineTune
OtterTune利用BO模型,通过平衡探索和开发来推荐参数配置;CDBTune采用强化学习,通过试错来学习调优策略。它们可以找到接近最优的配置,但存在50%~70%的调优结果比默认配置更差[6]。在配置过程中,配置的总内存(例如缓冲池、插入缓冲区、排序缓冲区等)大于机器的物理容量,调优甚至会导致两次系统挂起。这种不好的建议会给在线数据库带来巨大的风险。
考虑到数据库负载动态变化以及安全性,Zhang 等人[6]提出了OnlineTune,能够适应动态负载,并且保证每次调优采样的安全性。OnlineTune 将在线调优问题定义为具有安全约束的上下文bandit 问题,进而提取工作负载和底层数据的特征,形成上下文特征化模型。OnlineTune采用上下文贝叶斯优化技术来优化数据库,以适应不断变化的环境。针对云环境中海量数据对OnlineTune可扩展性的影响,提出了一种有效降低计算复杂度的聚类和模型选择策略。该方法对观测值进行聚类,每个聚类中的观测值个数可以限制在一个常数P之下。OnlineTune 基于聚类拟合多个上下文GP,并学习用于模型选择的决策边界。首先基于上下文特征,执行DBSCAN聚类算法[33],为每个特征获得聚类标签li。对于每个聚类,OnlineTune使用其观察结果拟合上下文GP模型。为了选择模型,使用SVM来学习非线性决策边界,除了提高可扩展性之外,这种聚类从GP模型的训练集中排除了一些观察,防止了“负迁移”[34]。OnlineTune结合黑盒和白盒知识来评估配置的安全性,黑盒就是用上下文GP 预测安全性,由于是对每个子集建立的GP,模型比全局GP更精准。白盒来源于领域知识、DBA 经验,或者一些启发式规则。OnlineTune 使用MysqlTuner[17]实现白盒助手。但白盒有时并不会根据反馈进行进化,导致局部最优的陷阱。当白盒拒绝配置而黑盒推荐配置时,采用放松策略,为每个规则定一个冲突计数器,如果冲突达到阈值,将忽略规则并推荐有争议的配置,大的阈值增加了白盒规则的可信度。文章通过子空间自适应提出安全的勘探策略,在很大程度上降低了应用有害配置的风险。OnlineTune 系统流程图如图5所示。
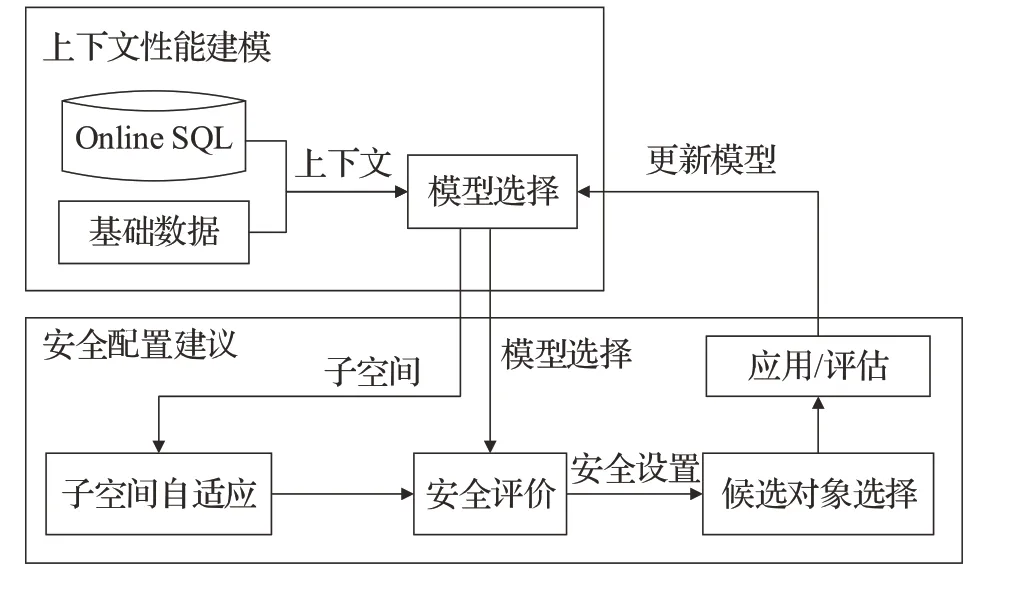
图5 OnlineTune调优流程Fig.5 OnlineTune tuning process
OnlineTune首先通过上下文特征捕获动态因素(如工作负载及其基础数据),获得上下文。然后从具有相似上下文的聚类中选择适合的上下文GP模型。对于新拟合的模型,以最优估计配置为中心初始化子空间。否则,会根据调优历史对子空间进行调整,其次对适应子空间进行离散化,构建候选集。OnlineTune基于模型的下界估计来评估候选对象的安全性,形成一个安全集。它还会用白盒来排除不安全的配置。如果启发式白盒从安全集合中排除了最优配置,OnlineTune通过最大化获取函数或探索子空间的安全边界,从安全集合中选择一个配置。最后,将配置应用于在线数据库并评估其性能。文章还从基准测试和现实应用中对动态工作负载进行评估。结果表明,与目前的最先进的方法相比,OnlineTune 在减少了91.0%~99.5%不安全推荐的同时,提高了14.4%~165.3%的累积改进。
OnlineTune 解决了OtterTune 系统调优时间长,不能反应真实负载的缺点,并且具备在线调优以及保证在线调优安全性的能力。在线调优可以实时根据工作负载的变化来进行调优,更好地适应数据库动态性的特征,但调优时间较长。如果将在线调优与离线调优相结合,利用离线过程可以使系统在目标DBMS的副本上探索更多配置,重用历史工作负载,用其来收集用于在线调优的观察结果,可以大大减少调优时间。
2.5 CGPTuner
OtterTune 利用过去的经验并收集新的信息来调优DBMS配置加速新工作负载下的搜索过程。然而,要做到这一点,需要收集大量历史数据,并且所有实验都应该包含所有可用参数。Cereda等人[7]提到由于搜索空间的维度呈指数增长,收集知识库的复杂性也会增加,它会变得越来越复杂。因此,提出CGPTuner 系统[7],它不需要任何初始的知识收集,并且能够在30 次迭代之后提出性能良好的配置。
CGPTuner 是一种基于CGPBO[35]的自动配置调优器,CGPBO 是贝叶斯优化框架的上下文扩展。贝叶斯优化已经成功地应用于性能自动调优问题[11,31,36-38]。CGPTuner 在考虑多层IT 堆栈和当前工作负载的同时,成功地调优了IT系统的配置,更重要的是,它不依赖于历史知识库。首先,在IT堆栈中,DBMS处于整个IT栈的最顶端,下面的JVM(Java virtual machine,Java 虚拟机)、操作系统的配置调优也都会影响DBMS 的性能。其次,DBMS 的性能还跟它所处的工作负载有关,即系统需要是实时、在线地自动调优。再次,目前软件版本更新得比较快,版本更新会修改其可用的参数,那么从先前的知识库中重用信息就让调优的问题变得更加复杂,因此要求系统不再利用先前的知识库。
基于上下文的高斯过程优化是指某些工作负载下的优化是相关的,比如工作负载w下得到的数据,可能为另一工作负载提供一些有用的信息。CGPTuner所提模型的优化目标就是在给定工作负载w下,找到一个配置向量x,将其应用在IT 栈上面来优化系统的性能指标y。调优器能够利用先前所有迭代的x、w和y,但不需要其他额外的知识。
文章用两个指标来衡量在线与离线两种方式下的调优器的性能,分别是在线调优的累计奖励calculative reward(CR)和离线调优的迭代最佳值iterative best(IB)。若CR的值为0,则表示与默认配置性能相同,若CR 的值为负数,则表示所找的配置不如默认的配置。IB值记录了当前迭代下记录的最高的标准性能改进,它反映了调优器快速探索并且找到良好配置的能力。文章结果表明:从IB 值的变化可以得到CGP 相较于另外两种在线调优算法,能更快找到良好的配置,并且找到的配置质量高于另外两种算法;从CR 值的变化情况可以看到,OpenTuner 和BestConfig 的累计奖励值在持续地负向增加,也就是说这两种算法找的配置始终比默认的设置更差,而CGPTuner在第三天开始CR值开始正向增加,并且在第六天累计奖励的值开始为正值并不断增加;在另一种工作负载模式上的结果类似。
除了从优化的角度比较了各种算法外,还从吞吐量和内存消耗的角度来比较了三种算法,结果表明CGP在大多数工作负载上都能获得更好的结果。
CGPTuner 解决了OtterTune 随着搜索空间维度呈指数增长,收集大量历史数据复杂性增加的问题。CGPTuner 不依赖于历史知识库,并且经过多次迭代后提出较优配置。但CGPTuner在每次迭代后收集数据集变得越来越复杂,并且每次都进行单一的评估会造成时间复杂度过大,所以研究如何进行可重复评估是非常重要的。
2.6 ResTune
现有数据库调优方法[11,13,38-39]主要集中在提高吞吐量和延迟率,而没有同时优化资源使用和SLA(service level agreement)。iTune[38]和OtterTune[40]使用高斯进程调优旋钮,只实现高吞吐量。CDBTune[11]和QTune[13]使用强化学习方法训练策略模型来推荐好的旋钮,但是这需要很长时间来学习模型[6]。另一方面在重复地使用工作负载以迭代地学习模型过程中,即使最先进的系统[11,40]也需要成百上千次的迭代才能找到理想配置,所以系统应该尽量缩短调优时间。
ResTune系统调参的目标是同时考虑优化资源使用率和性能,由于TPS(transactions per second)会被客户端的request rate所限而达不到峰值性能[8]。因此,需要找出资源利用率最小的数据库配置参数,并且满足SLA。此外,优化DBMS系统,例如降低高资源利用率,可以用于在线性能故障排除。高利用率可能会严重影响系统可用性。通过将预算减少到数十次迭代来加速调优过程,ResTune 利用从调优其他任务中收集的历史数据,并将经验转移到调优新任务中。
文章在多个场景下对比了ResTune 和其他SOTA(state-of-the-art)系统的性能与速度。首先,在单任务场景下,文章选定CPU 利用率作为优化目标,验证了ResTune 解决带SLA 限制的优化问题的效果。测试了Sysbench、Twitter、TPC-C 和两个真实的工作负载:Hotel Booking 和Sales,实验得出,ResTune 方法在所有负载上都可以得到最佳效果与最佳效率。
文章还测试了不同机器硬件之间的迁移效果,得出:元学习算法使得整个ResTune 的调参过程能在30~50步左右完成,而非迁移场景通常需要几百个迭代步。
除测试CPU资源外,还测试了内存资源、IO资源的参数调优效果,得出:对于IO 资源优化调参任务,Res-Tune 降低了84%~90%IOPS,对于内存资源优化调参任务,ResTune将内存利用从22.5 GB下降至16.34 GB。
ResTune 将该问题定义为具有约束的优化问题,其中约束常量可以设置为默认配置参数下的TPS 和延迟值。ResTune 将优化资源使用和满足SLA 转换为约束贝叶斯优化问题。与传统的贝叶斯优化算法相比,这里使用了受限EI 函数,将受限信息添加到常用的EI 效用函数(acquisition function)中。另一方面,为了更好地利用现有数据,ResTune 设计了一个结合静态权重和动态权重的高斯加权模型。通过集成历史的高斯过程模型,得到目标工作负载代理函数的加权平均值。
ResTune 调参任务的具体流程如下:当一个调参任务开始后,系统首先对目标数据库进行拷贝,并收集一段时间内的目标工作负载到用户环境用于未来的回放。在每一轮迭代中,目标任务首先进入元数据处理模块(meta-data processing)模块,该模块在调参任务初始启动时,元数据处理模块分析目标任务的工作负载,使用TF-IDF方法统计SQL保留字作为目标任务的特征向量(meta-feature)。在每轮迭代中,元数据处理模块以历史观察数据为输入,经过归一化处理后,对资源(CPU、memory、IO 等)利用率、TPS、Latency 拟合高斯模型,作为目标任务的基模型。最终得到meta-feature 与base model作为knowledge extraction模块的输入。
知识提取(knowledge extraction)模块负责计算当前任务与历史任务base model 集成时的静态与动态权重,并对base model 进行加权求和得到meta model,在该模块中为了提取与利用历史知识,ResTune 提出采用高斯模型加权求和的集成方式,即元模型M的关键参数u由基模型加权计算得到。在计算基模型权重时采用静态与动态两种方式。在初始化时,权重的计算采取静态方式,以特征向量作为输入,通过预训练的随机森林,得到资源利用率的概率分布向量,最终以概率分布向量之间的距离作为任务相似性,决定静态权重。当数据量充足后,ResTune使用动态权重学习策略,比较基学习器的预测与目标任务的真实观察结果之间的相似程度。使用动态分配策略,权重会随着对目标工作负载的观察次数的增加而更新。通过这两种策略,最终得到元学习器,作为经验丰富的代理模型。
在旋钮推荐(knobs recommendation)模块,根据meta learner推荐一组参数配置。采集函数使用了带限制的EI 函数(constrained EI,CEI),其根据限制情况重写了EI 的效用函数,当参数不满足SLA 限制时效设置为0,且当前最佳参数定义为满足SLA 限制的最佳参数。CEI 采集函数能够更好地引导探索满足限制的最优区域。
目标工作负载重放(target workload replay)模块对推荐参数进行验证,并将结果写入目标任务的历史观察数据。目标工作负载回放模块首先推荐参数应用在备份数据库上,并触发工作负载的回放,经过一段时间的运行验证后,验证结果(包括资源利用率、TPS、latency)与推荐参数将一起写入目标任务的观察历史。
以上训练过程重复若干迭代步,当达到最大训练步或提升效果收敛终止。目标任务训练结束后,ResTune会把当前任务的meta-feature与观察数据收集到数据存储库(data repository)作为历史数据。
ResTune 开辟了数据库调优的新方向,它改变了传统调优策略单纯以延迟率与吞吐量为指标,而是提出了在优化延迟率与吞吐量的同时,通过提升资源利用率来提高系统调优性能。但目前ResTune 调参功能对用户来说是一种离线操作,且相对繁琐。
在线动态调参技术能够缓解离线操作的问题,但具有更高的要求。首先,参数调优效果要求稳步提升,不能让系统运行时出现性能猛烈的下降,不能影响线上实时的服务;其次,为了保证线上稳定性和调节过程快速收敛,在线动态调参需要针对不同的工作负载自动选择关键的相关参数进行调节;最后,目前的工作假设用户负载变化不频繁,一旦用户负载变化就需要重新进行调参。为了提高用户体验,还要结合工作负载的检测支持自适应的调参服务。
2.7 LlamaTune
基于ML的调优方法分两种:在选定基准上执行预先训练并传递(或微调)给新客户工作负载的知识(例如,OtterTune[3]和CDBTune[11]),以及通过使用优化器迭代选择配置[7,13,38],并与它们一起运行工作负载来直接调优新客户工作负载。这些配置优化器中使用的算法需要利用之前收集到的知识。Kanellis 等人[9]想要令人在不使用任何先验知识的情况下,且不需要将旋钮进行排序,通过合成旋钮的方法找到重要旋钮进行调优,因此提出LlamaTune。LlamaTune调优流程如下:首先,优化程序使用当前的知识库,得到能够用提高性能的配置,运行DBMS 实例。控制器调用向DBMS 馈送查询的工作负荷,工作负荷通常运行若干,一旦工作负荷执行完成,控制器收集性能数据和其他相关度量,并将它们转发到知识库,然后用观察结果更新知识库。Llama-Tune系统流程图如图6所示。

图6 LlamaTune调优过程Fig.6 LlamaTune tuning process
LlamaTune 利用随机低维投影方法[41],配置空间从所有维度(D)到更低维度子空间(d)的投影,也就是对于用户提供D维输入配置空间XD,使用某个d维空间设计一个近似Xd,其中d≪D,它可能包含至少一个点p′∈Xd,可以产生接近最优的p*∈的性能XD。也就是构建Xd、XD两个空间之间的映射,即每个p∈XD都可以通过投影映射到某个点p′∈Xd。换句话说,如果低维空间大于目标函数的有效维度,则可以仅通过调整较小空间来实现接近最优的性能,然后使用优化器调整更小的子空间。该空间作为输入给出到BO[7,37-38,41]优化器。
对于上述描述,提出了合成搜索空间(synthetic search spaces)的方法,在之前系统中,一个旋钮往往对应一个维度,这样使每个维度都有一定实际意义。然而维度的意义对于优化器来说不是重要的方面,因此提出了合成搜索空间方法,也就是人工合成维度,将多个维度合并成一个维度,合成旋钮的一个值可以决定多个旋钮值,虽然人工合成旋钮本身没有意义,但是可以实现降低维度,同时避免了识别重要旋钮的需要。为了处理特殊值具有不同行为的旋钮,LlamaTune系统还对特殊旋钮的值进行处理,将数值过大的离散型旋钮进行桶化处理,对于含有特殊值的旋钮用偏置采样的方法处理。
在实验中,文章使用了6 个具有不同特征的OLTP工作负载,并将LlamaTune 与普通的SMAC 进行对比。首先,LlamaTune 达到基线SMAC 最佳配置平均快了5.62倍。其次,与普通SMAC相比,LlamaTune可以提高所有工作负载的平均最终吞吐量(100次迭代后),平均提高7.13%。TPC-C和SEATS这两个复杂的OLTP工作负载都显示出6%~7%的增长。最后,文章还观察到LlamaTune 在YCSB-A、TPC-C 和Twitter 这3 个工作负载上都优于基准SMAC。
LlamaTune 系统改变了之前调优系统的框架,没有将旋钮进行排序,而是用一种随机低维投影的方法将多个旋钮合成为一个旋钮,解决了通过排序方法选择旋钮准确性低的问题。但LlamaTune系统未能在Linux系统上进行调优,扩展性较差。
2.8 Tuneful
Fekry等人[10]对实际配置调优及其在数据分析框架中的部署进行了分析,提出调优成本摊销模型,并论证了该模型在调优经常性工作负载时的优势,根据不同工作负载集提供全面的增量调优解决方案。该模型是通过Gini评分作为指标进行旋钮渐进式选择,逐步缩小配置空间。与OtterTune 类似,同样采用工作负载映射框架来跨任务传递知识,提出Tuneful 模型。在重要参数调优操作上,采用执行敏感性分析(SA)[42]。每一轮SA中,都会删除一些低影响参数,以便在下一轮获得高影响参数的更好信息。首先使用随机森林回归(RFR)构建一个元模型来预测给定配置的执行成本,与单一学习模型[43]相比,提高了预测精度。Tuneful 利用高斯过程(GP),GP 能够使Tuneful 快速对不同配置下的执行成本进行建模。在相似度分析上Tuneful采用了一种相似感知的调优方法,以进一步适应对高效配置调优的需求。
Tuneful的设计是为了避免昂贵的离线阶段进行重要参数的识别或调优,将计算所有内容作为增量优化的一部分。文章通过在两个不同的服务提供商提供amazon web services(AWS)[44]和谷歌cloud(GCP)[45]两种云环境进行大量的实验来说明它的适用性。并利用所获得的经验教训定义了一个实用的自动化优化框架。该系统主要由3个组件组成,分别是性能分析配置器(significance analyzer)、成本分析器(cost modeler)和相似度分析器(similarity analyzer),由该系统的管理者(tuneful manager)控制。具体流程为:首先在搜索阶段的开始,性能分析配置器选择能快速探索某一特定工作负载的影响参数的配置,成本建模器就可以接管并构建一个低维模型。然后,在调优新工作负载时,相似度分析器通过重用现有信息进一步降低了探索成本。当工作负载提交执行时,Tuneful建议使用由性能分析配置器生成的探索性配置,或者使用由成本建模器生成的调优配置,再或者根据由相似度分析器生成的工作负载相似性从现有模型开始调优。执行之后,性能和成本指标被反馈到Tuneful,然后它们被用来更新下一个配置的选项。随着时间的推移,相似度分析器能够匹配越来越多的工作负载,这大大提高了调优速度。最后文章进行了实验分析,证明了当数据分析工作负载在动态环境中执行时,增量配置调优是正确的方法。
文章对比了Opentuner、Gunther、Random Search 与Tuneful 不同调优算法查找最优配置的搜索时间,结果表明Tuneful在4个基准测试上用时都是最短的。
Tuneful虽然解决了之前未从成本效益上进行调优的问题,但Tuneful不适合特定的云场景。
2.9 应用场景分析
OtterTune(GPR)适合低维数据集自动调优,它使用GPR 框架,会利用之前知识库中的工作负载,在之后的调优过程中,工作负载相似则可直接使用。OtterTune对每个支持DBMS 版本总结了一份“旋钮”黑名单,包括了对调优无关紧要的部分(比如保存数据文件的路径),或者那些会产生严重或隐性后果(比如丢数据)的部分,确保调优能够提高系统性能。
OtterTune(DNN)是OtterTune 的改进版本,解决了OtterTune只能在低维或者少量的数据集上进行调优的问题,适合大数据集和高维数据自动调优。
RelM 适用于分布式数据库数据处理系统,它可以自动调整内存分配问题。降低基于BO[29]和DDPG[30]等算法探索最优参数配置的开销。
OnlineTune使用的在线调优,能够适应变化较快的工作负载,可以在不断变化的云环境中安全地调整在线数据库。OnlineTune适用于对安全性要求较高、工作负载变化较快的云环境中使用。
CGPTuner 适用于没有任何历史知识的数据库,它解决了之前OtterTune系统需要收集历史知识的问题。
ResTune 优化资源的使用与性能,找出资源利用率最小的配置参数,并且能够让它满足相关协议。在资源较为紧缺的情况下,可以考虑使用此种方法。
LlamaTune 没有像其他系统一样使用旋钮重要度排序的方法,而是创新将众多旋钮进行合成,形成一个新的旋钮,这样避免了排序选出最重要的几个旋钮造成准确率下降的问题。LlamaTune旋钮选择准确率较高。
Tuneful 对分析引擎进行调优,适用于工作负载变化较快的Spark 大数据分析引擎的性能优化,能够在最小时间内达到最优性能。该方法考虑了环境的动态特征,对不同的工作负载,采用了不同的ML技术,提供全面的增量调优解决方案,并且在实践中能够以成本效益方式调优工作负载。
3 基于RL的参数调优技术
传统机器学习具有较强的泛化能力,使得这类调参系统在不同数据库环境下都有较好表现。此外,它能够有效利用在历史任务中学到的经验,应用在未来调参工作中。但是,这类方法主要采用一种管道式架构,上一阶段获得的最优解并不能保证是下一阶段的最优解,而且不同阶段使用的模型未必可以很好地配合。其次,它需要大量高质量的样本用于训练模型,而这些样本是很难拿到的。比如,数据库表现受磁盘容量、CPU状态、负载等很多因素的影响,很难去大量复现相似的场景。此外,仅仅使用高斯回归等模型很难优化数据库调参这种有高维连续空间的问题。
针对上述传统机器学习调参技术的缺点,引入强化学习(RL)。RL提供了一种框架,使智能体(agent)能够在特定场景(environment)中采取行动,并按离散时间在与环境的交互中学习。与传统监督学习不同,强化学习不需要大量的标注数据。相反,通过不断试错和对智能体惩罚和奖励,反复优化行为选择的策略,以最大化目标函数。通过探索和开发机制,强化学习可以在探索未知空间和开发现有知识之间做出权衡。表3 给出基于RL的参数调优方法对比。

表3 基于RL参数调优方法对比Table 3 Comparison of tuning methods based on RL parameters
3.1 CDBTune
由于不同的数据库实例和查询负载的不同,这使得数据库管理员(DBA)的工作变得非常困难。现有的自动DBMS配置调优解决方案有几个局限性。首先,它们采用流水线学习模型,不能以端到端的方式优化整体性能。其次,它们依赖于难以获得的大规模高质量训练样本。再次,现有的方法不能为大量的旋钮推荐合理的配置在如此高维连续空间中的旋钮。在云环境下,现有的方法很难适应硬件配置和工作负载的变化,适应性差。针对上述问题,Zhang 等人[11,46]基于DRL 提出端到端的数据库管理系统配置自动调整系统CDBTune,该系统能够在复杂云环境中对旋钮设置进行重新调整。CDBTune使用深度强化学习(RL),利用深度确定性策略梯度法(deep deterministic policy gradient,DDPG)在高维连续空间中寻找最优配置。基于试错思想,以有限样本学习旋钮设置,完成初始训练,减少了采集大量高质量样本的必要性。并且采用RL 中的奖赏-反馈机制代替传统的回归,实现端到端学习,加快了收敛速度提高了在线调优的效率。CDBTune 系统优先体验回放,以加速模型的收敛,并探索如何减少耗时的重启时间,从而在实际使用中为用户提供更好的体验。
CDBTune 系统是最早采用上述的深度确定性策略梯度算法的。该算法是在连续动作空间环境中搜索最优策略的一种深度强化学习算法。DDPG由3个组件组成:actor、critic 和replay memory。actor 根据给定的状态选择一个动作(例如,对一个旋钮使用什么值)。critic根据状态对选定的动作(即旋钮值)进行评估,并且提供反馈来指导actor。actor 的输入是DBMS 的度量,输出推荐的旋钮值。critic将之前的度量和推荐的旋钮作为输入,输出一个Q值,DDPG神经网络的Q值计算的是对未来所有预期奖励的叠加。replay memory存储按预测误差降序排列的训练数据。对于每个旋钮k,DDPG构造一个元组。在接收到一个新的数据时,CDBTune首先通过比较当前、历史和初始目标值来计算奖励。训练时从memory中获取一个小批量排名靠前的tuple,并通过反向传播更新actor 和critic 的权重。最后,CDBTune 将当前度量m输入actor 以获得下一旋钮k_next的推荐。
上述CDBTune调优的工作过程主要分为离线训练和在线调优两个步骤。离线训练就是用一些标准的负载生成器对数据库进行压测,边收集训练数据,边训练一个初步的配置推荐模型。当用户或者DBA有数据库性能优化需求时,可以通过相应的交互接口提出在线调参优化请求,此时云端的控制器通过给智能优化系统发出在线调参请求,并根据用户真实负载对之前建立好的初步模型进行微调,然后将模型微调后推荐出的相应的参数配置在数据库中进行设置。反复执行上述过程,直到待调参的数据库性能满足用户或系统管理员的需求即停止调参,如图7所示。

图7 CDBTune调优流程Fig.7 CDBTune tuning process
在多种不同负载和不同类型的数据库下进行的大量实验证明,CDBTune 性能优化结果明显优于目前已有数据库调优工具和DBA 专家。即使在云环境下,用户数据库内存、磁盘大小发生变化或负载发生变化(类型不变)的情况下,实验证明CDBTune依然保持了较好的适应能力。文章将CDBTune 与BestConfig、DBA 和OtterTune 进行对比,发现CDBTune 比其他三者的吞吐量更高,延迟率更低。
CDBTune 是使用RL 进行调优的先驱,改正了基于BO 算法推荐配置有一定误差,以及需要大量高质量经验数据进行模型训练的缺点。CDBTune 使用DDPG 算法,该系统能够在复杂云环境中对旋钮设置进行重新调整,并且利用DRL 对系统旋钮进行调优的工作具有开创性,但在结构设计上还需要进一步改进。
首先,CDBTune直接使用DRL与系统交互,没有利用当前的工作负载特性,其次,CDBTune 只为3 种工作负载(只读、只写和读写)提供粗粒度调优,无法为特定查询工作负载提供细粒度调优。
3.2 Hunter
CDBTune 需要较长的调优时间才能通过自我学习达到较高的性能。对此,CDB团队提出了Hunter[12]能够在保证调优效果的前提下极大地缩减调优耗时。
Hunter 是一个用于CDB 的在线调优服务。首先,Controller 与目标DBMS、调优系统和用户交互。它由Actor 和CDB 组成,其中Actor 被设计用于从DBMS 收集运行时信息,克隆CDB 上的用户实例,并管理克隆CDB上的并行执行。而在经典架构中,例如CDBTune,Controller只与单个CDB实例进行交互。而Hunter中的Controller 管理一个Actor 集合,每个Actor 管理一个从用户实例克隆的CDBS 集合。改进的混合调优系统Hunter,主要包含样本生成、搜索空间优化、深度推荐3个阶段。
在样本生成阶段,由于基于学习的调优方法在训练初期都有着调优效果差、收敛速度慢等问题(冷启动问题)。这些方法面临冷启动问题主要是因为样本数量少质量差,网络难以快速学到正确的探索方向,或者搜索空间大,网络结构复杂,学习速度缓慢。为了缓解上述问题,Hunter采用收敛速度更快的启发式方法(如:遗传算法(GA))进行初期的调优,以此快速获得高质量的样本。启发式方法虽有着较快的收敛速度,但是却容易收敛到局部最优,导致最终调优效果不佳。而基于学习的方法却在较长的调优时间后可以得到较高的性能,但是却需要较长的训练时间,速度较慢。Hunter将两种方法结合,既加快了调优速度,也确保了参数质量,获得高质量样本。样本生成阶段是根据目标工作负载和用户需求,通过GA和规则生成样本。规则是由用户或DBA定义的限制,包括哪些旋钮是固定的,以及其他旋钮允许调整的范围。在不同规则下,预训练的模型很难推荐令人满意的配置。
在搜索空间优化阶段,文章利用样本生成阶段可以获得较多高质量的样本,但是却没有将其效果充分发挥。Hunter 利用PCA 进行状态空间降维,随机森林(random forests)进行参数重要性排序。PCA是一种常用的机器学习的降维方法,可将高维数据降为低维数据的同时保留大部分信息。系统采用累计方差贡献率来衡量信息的保留度,一般来说,当累计方差贡献率大于90%时即可认为信息得到了完全的保留。Hunter 选择贡献率最大的两个成分,并以此作为x、y轴描点,以其对应的数据库性能作为点的颜色(颜色越深性能越低),由此低性能的点可以被两个成分较为明显地区分开来。随机森林可以被用来计算特征的重要性,以数据库参数为输入,对应的数据库性能为输出训练随机森林模型,然后计算各个数据库参数的重要性,并进行排序。采用不同数量的Top 参数进行参数调优可以看到数据库最优性能的变化,在一定数量的样本保证下,TPC-C负载调整20 个参数即可达到较高的性能。总的来说,搜索空间优化阶段是将样本工厂生成的样本作为输入,对指标和搜索空间进行压缩和降维。
深度推荐阶段利用之前阶段的信息进行维度优化和强化学习预训练,保证调优效果的同时显著减少调优时间。具体来说,在深度推荐阶段采用深度强化学习(DRL)来进行参数推荐。首先,搜索空间优化的结果会对DRL的网络进行优化,减少其输入输出的维度,简化网络结构。其次,样本生成阶段的样本将加入DRL 的经验池中,由DRL进行一定程度的预训练。最后,DRL将基于改进后的探索策略进行参数配置推荐。DRL 的基本结构与CDBTune 类似,为了充分利用高质量的历史数据,文章修改了其探索策略。为了进一步对调优过程进行加速,Hunter充分利用CDB的克隆技术,采用多台数据库实例实现并行化,令整个调优时间更进一步地减少。
文章将CDBTune 与BestConfig、GA(遗传算法)和OtterTune 进行对比,结果显示了每种方法在MySQL 上测试TPCC 获得的最佳吞吐量和最佳延迟曲线。结果表明Hunter能够在更短的时间内获得55%~65%的最佳性能。特别是使20个克隆的CDB,Hunter-20能够在2.5小时内实现最佳性能,这减少了94%~95%的推荐时间。
Hunter 解决了CDBTune 调优时间长的问题,能够在保证调优效果的前提下极大地缩减调优耗时,但Hunter难以快速判断性能是否达到“最优”。
3.3 WATuning
Ge 等人[14]提到传统的参数调优是由DBA 进行的,但DBA 可以调整的旋钮数量是有限的,很难在全局范围内找到更好的旋钮。DBA通常擅长调优他们熟悉的系统类型,并且由于系统可以构建在不同的环境中(如本地或云、CPU、RAM、磁盘),DBA 需要长时间调优不同环境下的系统,严重影响调优效率。工作负载通常以dy-namal方式连续变化。因此,不断变化的工作负载也要求DBA 始终动态地调整旋钮以获得高性能。在3.1节提到的CDBTune,是最早使用强化学习来处理调优问题的系统,但它存在很多问题,首先,CDBTune 不能很好地适应工作负载的变化,只提供粗粒度的调优。CDBTune 只对3 种工作负载进行分类(只读、只写和读写)。其次,CDBTune 重新修复旋钮需要重新启动系统,影响系统的稳定性。再次,CDBTune 的核心算法DDPG没有利使用工作负载特性。
针对上述问题,文章提出了一个基于注意力深度强化学习的调优系统WATuning,该系统能够适应工作负载特性的变化,高效、有效地优化系统性能,也能够服务于数据库以及其他系统。首先,文章设计了WATuning的核心算法ATT-Tune来完成系统的调谐任务。ATT-Tune是在深度确定性策略梯度(DDPG)[30,47]的基础上设计的。CDBTune[11]的弱点之一是其核心算法(DDPG)没有使用工作负载特性。所以在核心算法ATT-Tune 中,文章考虑了不同的工作负载对系统内部状态的影响。并利用深度神经网络构建注意力机制模块,生成状态权重矩阵,使系统在不同工作负载下的内部状态根据重要性得到不同的权重值。文章使用并改进了CDBTune中应用的奖励函数,增加了一个公差因子和一个公差间隔,以保证推荐的旋钮值在实际环境中的可用性。其次,文章将注意力机制模块和DDPG看作一个整体一起训练,大大降低了神经网络训练的难度。最后,针对实际应用场景,设计了一种动态的自微调方案,使WATuning更符合实际工作负载,从而实现对旋钮的重新调整,使系统更加使用实际工作负载。
WATuning系统调优流程如下:在训练阶段,首先使用性能测试模块生成工作负载,并将工作负载应用到系统模块。然后将工作负载和内部状态传递给控制器,控制器将分类完成的工作负载和内部状态传递给自动调谐模块。性能测试模块对系统模块进行监控,获取系统的吞吐量和延迟率作为外部度量,并将外部度量传递给自动调谐模块。自动调谐模块采集上述步骤传递的参数并进行训练,并向系统推荐旋钮配置。重复上述步骤,直到自动调谐模块的内部核心算法收敛。
在推荐阶段,系统模块将实际工作负载和状态传递给自动调优模块,然后自动调谐模块向系统模块推荐高性能旋钮配置。
文章最后对该系统进行实验,结果表明,WATuning的吞吐量和延迟率要比现有的最优调谐方法CDBTune的吞吐量和延迟率分别提高52.6%和13%。
WATuning 改正了CDBTune 不能很好地适应工作负载的变化、没有利用对系统参数推荐的工作负载特性等缺点,考虑了不同工作负载对系统内部状态的影响。WATuning 利用深度神经网络构建注意力机制模块,生成状态权重矩阵,使系统在不同工作负载下的内部状态根据重要性得到不同的权重值。
3.4 QTune
CDBTune 使用深度强化学习(DRL)通过试错策略来调优数据库。然而,CDBTune 需要在数据库中多次运行SQL查询工作负载以获得适当的配置,这十分耗费时间。并且CDBTune 只提供粗粒度的调优(即针对只读工作负载、读写工作负载、只写工作负载的调优),但不能提供细粒度的调优(即针对特定查询工作负载的调优)。其次它直接使用现有的DRL模型,该模型假设环境只能受到重新配置操作的影响,不能利用查询信息。
基于CDBTune 上述不足之处,Li 等人[13]提出了一种基于深度强化学习查询感知的自动调参系统QTune,从3个方面解决CDBTune中遗留的问题。首先,为了提高参数配置对不同负载的适应能力,QTune在查询计划级别对负载特征(如读写比例、使用的关系表、执行代价等)进行编码,对执行开销做预估计。其次,为了进一步提高调参表现,QTune采用了一种面向调参问题的深度强化学习算法(double-state deep deterministic policy gradient,DS-DDPG),不仅基于Actor-Critic 算法,提高训练效率,而且在强化学习的状态特征中综合负载、数据库状态指标、当前参数值等特征,提高调参策略的准确度和适应能力。再次,为了更好地满足不同用户对数据库性能的需求(如低延迟、高吞吐量等),先对所有用户负载根据参数偏好进行聚类,然后对相同类中的查询做批量调参和执行,从而平衡吞吐量和延迟两方面的需求。
对于上述QTune 提出了一种深度确定性策略梯度(DS-DDPG)模型使用Actor-Critic 网络。DS-DDPG 模型可以根据数据库状态和查询信息学习Actor-Critic 策略,自动解决调优问题。此外,QTune 吸收了SQL 查询的丰富特性,并为SQL 语句提供了系统的三个调优粒度。第一个是查询级调优,它为每个SQL查询找到一个很好的配置。这种方法不能并行运行SQL查询,可以实现低延迟,但吞吐量较低。第二个是工作负载级调优,它为查询工作负载找到很好的配置但无法为每个SQL查询找到好的配置。这种方法能够实现低吐量但延迟高。第三种是集群级调优,它将查询集群到几个组中,并为每个组中的查询找到一个良好的数据库配置。这种方法实现高吞吐量和低延迟,因为它可以为一组查询找到良好的配置,并在每个组中并行运行查询。因此,QTune 可以根据给定的需求在延迟和吞吐量之间进行权衡,并同时提供粗粒度调优和细粒度调优。文章还提出了一种基于深度学习的查询聚类方法,根据查询匹配配置的相似性对查询进行分类。
QTune系统具体调优流程如下:首先客户机与Controller交互以提出调优请求。Query2Vector将每个查询定义为一个向量。它首先分析SQL查询,从数据库引擎中提取查询计划和每个查询的估计成本,并使用这些信息生成一个向量。基于特征向量,Tuner 推荐适当的旋钮,然后数据库根据新的旋钮值执行这些查询。调谐器使用深强化模型DS-DDPG 来调整模型,并推荐连续旋钮值作为新的配置。Tuner还需要使用训练数据来训练模型,这些数据存储在training data 存储库中。对于查询级调优,Query2Vector 为给定查询生成一个特征向量。调谐器采用这个矢量作为输入,并建议连续的旋钮值,系统根据推荐的旋钮值执行查询。对于工作负载级调优,Query2Vector为工作负载中的每个查询生成一个特征向量,并将它们合并成一个统一的向量。调谐器采用这个统一的矢量作为输入,并建议旋钮值。对于集群级调优,Query2Vector首先为每个查询生成一个特征向量,Tuner 学习每个查询的配置模式,但这个过程代价较高。为了提高性能,文章提出了一种深度学习模型Vector2Pattern,它学习旋钮的离散值。然后Pattern2Cluster根据离散配置模式对这些查询进行聚类,得到查询组。对于每个查询组,Tuner推荐适当的配置,然后数据库依据新的旋钮值在组中执行这些查询。
文章最后将QTune的性能与数据库默认设置、Best-Config、OtterTune、DBA以及CDBTune进行对比。QTune在所有情况下都实现了最佳性能。比如:与CDBTune相比,QTune的吞吐量提高了151.10%,延迟减少了60.18%,训练时间减少了66.15%。
QTune 解决了CDBTune 多次运行负载耗时的问题、不能针对特定查询工作负载调优以及只提供粗粒度的调优的问题,对DRL 模型进行了改进。首先,QTune吸收了SQL 查询的丰富特性,并为SQL 语句提供了系统的3个调优粒度(查询级、工作负载级和集群级)。其次,模型利用查询特征(工作负载)预测系统内部状态的变化值ΔS。但是,系统需要收集真实环境中产生的大量的ΔS来训练一个神经网络,这是一个耗时的过程。此外,DRL模型中系统的当前内部状态依赖于以前的状态。如果对ΔS的预测稍有偏差,则累积的迭代的结果也会出现极大的误差。因此,对训练模型的精度要求也极为严格。
3.5 应用场景分析
CDBTune 使用端到端的方式优化,并且能够在复杂的云环境中对旋钮设置进行调整。Hunter 是CDBTune 的延伸版本,在保证调优效果的同时缩短CDBTune 调优的时间,并且不需要依赖于高质量的训练样本,可以为高维连续空间中大量旋钮推荐合理配置,更适合高维连续空间内进行调优。
WATuning 能够适应工作负载的变化的特征,修改后的旋钮值不需要进行重启系统。系统还可以根据工作负载的变化生成多个实例模型,从而可以针对不同类型的工作负载完成针对性的推荐服务,适合工作负载较多,变化复杂的场景。
QTune 提供了3 种级别的调优:第一种是查询级调优,它为每个SQL查询找到一个很好的配置。这种方法实现低延迟,但吞吐量也会低。第二种是工作负载级调优,它为查询工作负载找到一个很好的配置,可以实现高吞吐量但延迟也高。第三种是集群级调优,这种方法可以实现高吞吐量和低延迟。因此,QTune可以根据给定的需求在延迟和吞吐量之间进行权衡,同时提供粗粒度调优和细粒度调优。QTune 还提出了一种基于深度学习的查询聚类方法,根据查询匹配配置的相似性对查询进行分类。
4 数据库参数
4.1 服务器设置参数
(1)listen_addresses:指定PostgreSQL服务器监听的网络地址。
(2)port:指定PostgreSQL服务器监听的端口号。
(3)max_connections:限制并发连接的最大数量。
(4)max_locks_per_transaction:限制每个事务所能获取的最大锁数。
(5)deadlock_timeout:指定检测死锁的超时时间。
(6)vacuum_cost_delay 和vacuum_cost_page_hit:控制VACUUM操作的成本计算和延迟。
4.2 内存和性能参数
(1)shared_buffers:指定共享缓冲区的大小,用于存储经常访问的数据块。
(2)work_mem:指定每个查询操作使用的内存量。
(3)effective_cache_size:指定系统的有效缓存大小。
(4)data_directory:指定PostgreSQL数据目录的路径。
(5)temp_tablespaces:指定用于存储临时表的表空间。
(6)max_wal_size和min_wal_size:指定WAL(writeahead log)的最大和最小大小。
4.3 日志和错误报告参数
(1)log_destination:指定日志输出的目标,如文件、控制台或系统日志。
(2)logging_collector:启用日志收集器,将日志写入到指定的日志文件中。
(3)log_rotation_age 和log_rotation_size:控制日志文件的轮换方式。
4.4 安全和身份验证参数
(1)password_encryption:指定密码加密算法。
(2)ssl:启用或禁用SSL/TLS 加密。
(3)pg_hba.conf:配置客户端身份验证规则。
4.5 查询优化参数
(1)effective_io_concurrency:指定磁盘I/O 操作的并发数量。
(2)random_page_cost 和seq_page_cost:用于计算查询计划中不同类型访问的成本。
(3)max_parallel_workers 和max_parallel_workers_per_gather:指定并行查询执行的最大工作进程数。
(4)max_parallel_maintenance_workers:指定并行维护工作进程的最大数量。
(5)enable_seqscan和enable_indexscan:控制查询计划中顺序扫描和索引扫描的使用。
4.6 备份和恢复参数
(1)archive_mode 和archive_command:配置归档模式和归档命令。
(2)wal_level:指定写入WAL(write-ahead log)的详细程度。
(3)restore_command:配置恢复命令。
(4)max_wal_senders:指定可用于流复制的最大WAL 发送者数量。
(5)synchronous_commit:指定是否使用同步提交来确保事务持久性。
5 总结与展望
近年来,数据库参数调优与机器学习结合得到广泛关注,并取得一系列研究成果。本文首先阐述传统参数调优存在的问题,然后给出学习式调优方法,包括基于BO 模型的参数调优以及基于RL 的参数调优。机器学习与数据库参数调优的结合包括3种方式:第一种方式是针对基于DDPG框架的模型,如CDBTune[11]、Hunter[12]等,利用深度强化学习提高参数调优质量;第二种方式是基于高斯的模型,如OtterTune(GPR)[3]、ResTune[8]等;第三种方式是针对分布式环境,如RelM[5],SmartPS[48]等模型,以及使用新的参数服务器框架[49]来解决分布式机器学习问题,能够提升参数调优的效率[50-51]。最后,本文对数据库参数调优在如下方面做出展望。
5.1 基于因果推理的参数调优
当前学习式参数调优模型可解释性差,无法捕捉问题路径。建议结合因果推理模型进行解决。虽然现在机器学习、深度学习等方面的内容已经被广泛研究,且应用到日常生活中能够提高生活质量。上述的数据库调优系统,目前大多数的研究也与机器学习、强化学习相结合,但机器学习、深度学习模型也不是完美的。其一,很多机器学习、深度学习训练出来的内容缺乏适用性,也就是缺乏泛化的能力,需要不断的训练新方向的内容,才能够拥有更好的适用性。而因果推理恰恰弥补了这方面的不足,训练一个模型,能够根据经验、规律泛化到另一个模型之中。其二,机器学习普遍存在可解释性差的问题,可解释性差导致很多时候不知道如何优化一个模型。因果推理恰恰可以降低机器学习可解释性差的问题,所以将数据库学习与因果推理相结合也是一个趋势。
5.2 并行数据库参数调优
随着机器学习的使用越来越普遍,数据规模与业务访问的负载也越来越大,越来越多的公司企业无法依赖于单个数据库服务器来支撑起服务。且训练的数据量和模型的不断增长,单个服务器也很难进行训练数据,因此研究分布式数据处理很有必要。目前也有一些学者研究数据库分布式系统[5,47-48],例如,前文所介绍的REIM[5]研究的分布式系统方面的内容,实现自动内存分配。但有学者指出这些现有的研究大多数基于独立的服务器,或者搭载在主流的分布式机器学习系统上,并且许多现有的数据库系统利用并行性可以实现更高的性能[49-50]。在这个趋势下,研究分布式数据库的参数调优系统是很有必要的。
5.3 其他数据库类型性能优化
现代的数据库系统有很多种类型,如关系型数据库,非关系型数据库(NoSQL)以及时序数据库等。未来研究可以寻找通用的性能优化的方法。对于异构存储的场景,考虑利用更好的缓存管理与外部池技术,比如可以考虑GPU与NVM等介质加速查询优化的方法。
5.4 优化云数据库性能
随着企业逐渐将数据中心转移到云环境中,管理分布式数据和配置成为一个非常重要的问题。因此未来研究可以着手研究如何有效的管理分布在云上的数据库系统,优化数据传输的速度,降低复杂度提高可用性等。
5.5 利用数据库容器技术自动组织数据库资源
数据库有效利用资源也是目前很多人研究的重点,目前利用容器技术(如Docker)部署应用程序和数据库服务已经成为了一种普遍的做法。未来的研究将探索如何利用容器组织数据库资源,并使用自动化工具进行配置和调整,以提高性能、可移植性和灵活性,提高资源的利用率。
猜你喜欢
日用电器(2021年8期)2021-09-13
日用电器(2021年7期)2021-08-17
家庭影院技术(2019年8期)2019-08-27
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
大众摄影(2015年7期)2015-07-01
