
医学CT影像超分辨率深度学习方法综述
2024-03-03 11:21田苗苗支力佳张少敏晁代福
计算机工程与应用 2024年3期
田苗苗,支力佳,张少敏,晁代福
北方民族大学 计算机科学与工程学院,银川 750021
计算机断层扫描(computed tomography,CT)是临床诊断的重要辅助手段。CT影像的质量对病变诊断有非常重要的影响,高分辨率(high resolution,HR)CT 是肺结核[1]、特发性肺纤维化[2]和间质性肺炎[3]等疾病的关键诊断工具。并且HRCT 在鉴别肺结节良恶性方面优于常规胸部CT[4]。但由于成像设备的限制,难以获得高分辨率医学CT 影像,所以可以利用后处理技术获取HRCT。
超分辨率(super resolution,SR)的概念最早由Gerchberg[5]提出用于提高超出衍射极限的光学系统的分辨率。随着技术不断发展,超分辨率被定义为从相应的低分辨率(low resolution,LR)图像生成HR图像的方法。经典图像插值算法通过增加像素尺寸提高图像分辨率,简单且处理速度快,但是不能突破原有的信息量,而且由于不考虑结构信息,可能会产生伪影[6]。基于学习的SR 技术的基本思想是通过学习过程获得先验知识[7],该方法一般需要较少的LR图像就能得到效果很好的超分辨率图像,但是该算法不能随意改变放大因子。近年来,深度学习在图像处理的许多领域都取得了优秀的成果。深度学习用于SR问题的第一个模型SRCNN[8](super-resolution convolutional neural network)的出现,吸引了许多研究人员将神经网络的各种变体应用到图像超分辨率研究中。在医学图像超分辨率领域,Chaudhari等[9]使用SR方法从厚切片输入图像中生成膝盖磁共振图像的薄片。Dm等[10]提出使用渐进式生成对抗网络来提高磁共振图像质量。使用超分辨率辅助诊断已经成为近期的趋势,例如研究人员使用基于深度学习的SR 方法来协助诊断孤立性肌张力障碍等运动障碍[11]。由于医学成像的超分辨率技术之后通常是分割或诊断,因此增强感兴趣的结构并且保存敏感信息是非常具有挑战性的研究课题。此外,医学图像数据集相对较小且难以收集,尤其是临床高分辨率和低分辨率图像对。
一般地,图像超分辨率重建模型可以分为三个功能模块:输入模块、图像特征提取模块与特征图放大重建模块。随着深度学习技术的发展,不断有最新的网络结构和学习策略被引入到医学图像超分辨率领域。相关研究往往通过改进网络结构或者针对特定问题加入新的结构等手段提取更多深层高频信息,提高输出图像质量。基于对现有医学CT 影像超分辨率算法的研究,本文将从超分网络的三个功能模块入手,阐述基于深度学习的医学CT影像超分网络在结构和性能优化方面的创新与进展,通过提供结构上使用的SR 方法组件的细节来对比总结医学CT影像超分辨率最新进展。如图1所示为基于超分网络结构改进的分割方法。

图1 基于超分网络结构改进的分割方法Fig.1 Improved segmentation method based on super-resolution network structure
本文的其余部分组织如下:本文第1、2章分别介绍了超分辨率基本理论和常用图像质量评估准则。第3章重点论述了基于超分网络结构改进的相关研究工作,并给出相关方法的整体总结与比较。第4 章分析了超分辨率网络针对特定医学领域的应用。第5 章讨论了医学CT 影像超分辨率重建方向上存在的困难和挑战,并对未来的发展趋势进行了总结与展望。
1 超分辨率基本理论
图像超分辨率重建(SR)是计算机视觉领域中提高图像分辨率的重要方法之一,能够在不改变硬件设施的前提下,获得高分辨率图像。图像分辨率技术在医学成像、数字与场景识别、摄影以及目标跟踪等多个领域都有广泛应用。本章首先介绍SR 问题定义,然后依次介绍退化函数、网络框架分类以及损失函数,为后续章节中介绍网络结构改进提供理论基础。
1.1 超分辨率问题定义
超分辨率是从输入的LR 图像中重建相应的HR 图像。大多网络在训练和测试时使用的LR图像为退化函数输出,如公式(1)所示:
其中,t为退化函数,IHR为输入HR 图像,∂为退化函数的输入参数,通常是缩放因子、模糊类型和噪声。SR问题则是退化函数的逆过程,如公式(2)所示:
其中,f为SR 函数,是输入参数,为输入ILR对应的估计高分辨率图像。
最后,SR 要使损失函数最小,目标函数如公式(3)所示。为输出HR图像与真实HR图像之间的损失函数,ψ(ϕ)为正则化项。
1.2 退化函数
退化函数是指将图像从理想超分辨率转变为现实硬件设备生成的可能有瑕疵的图像,常用到的退化函数如图2所示。应用于医学CT领域的超分辨率大多为有监督算法,一般需要利用大量LR-HR图像对进行训练,其中LR 图像由HR 图像经退化函数得到,大多数文献会采用双三次插值下采样算法,但该方法在实际应用中效果不佳,因为现实世界的LR 图像的降质过程更加复杂且未知,由于扫描时间、身体运动或者剂量限制等因素,CT图像可能产生伪影,模糊等。

图2 退化函数Fig.2 Degenerate function
医学CT 超分辨率领域常用到的退化方式有四种:BI(bicubic-down)表示仅使用双三次下采样生成LR 图像;BD(blur-down)为HR 图像添加高斯模糊,然后进行下采样;BN(bicubic-down and noise)表示双三次插值下采样和高斯白噪声;DN(blur-down and noise)表示高斯模糊下采样并在图像中加入高斯白噪声。
很多网络采用双三次下采样结合模糊、噪声等手段处理HR 图像,但这并不是完美的解决方式,得到的LR图像与现实硬件设备生成的图像仍存在一定偏差,会影响网络最终的训练效果,本文在“3.1 节输入模块改进”中总结了一些网络针对此类问题的思路与方法。
1.3 超分辨率网络框架
根据上采样模块在模型中所处位置的不同,可以将超分网络框架分为如图3所示的四种框架。

图3 四种SR框架模型图Fig.3 Four SR framework model diagrams
1.3.1 预上采样框架(pre-upsampling SR)
预上采样SR框架[8]是指首先将LR图像上采样为所需的尺寸,再通过神经网络重建高质量的细节,例如SRCNN[12]模型。该框架的优势是学习难度低,并且可以将插值处理后的任意大小图像作为输入,效果与单尺度SR[13]模型相当。其缺点是经典的插值方法,例如双三次插值[14]、三次样条插值[15]等,会导致噪声放大、图像模糊,同时模型的计算在高维空间中进行,会显著增加计算复杂度,时间和空间成本也随之增加。
1.3.2 后上采样框架(post-upsampling SR)
后上采样[16]是指LR 图像先被传递到神经网络中,在较低维空间进行特征提取,上采样在最后一层使用可学习层来执行。该框架在低维空间进行计算,计算成本低,降低了模型复杂度,在SR中得到了广泛的应用。但是后上采样无法满足多尺度SR 的需要,并且当上采样因子较大时,学习难度增加。
1.3.3 渐进上采样框架(progressive-upsampling SR)
渐进上采样是指将整个模型分为几个阶段,每个阶段图像被上采样一次得到更高分辨率,逐步实现所需的缩放。该框架的优势是渐进式操作降低了学习难度,获得了更好的性能。缺点是仍然无法满足多尺度问题,并且多阶段模型设计的复杂性增加、训练难度增加。应用渐进上采样框架的模型有Lai 等[17]提出的LapSRN(Laplacian pyramid super-resolution network)和MSLapSRN(multi-scale Laplacian pyramid super-resolution network),Wang 等[18]提出的ProSR(progressive superresolution network)等。
1.3.4 迭代上采样框架(iterative up-and-down sampling SR)
迭代上采样将反向投影引入到SR中用来缩小LRHR之间的关系,迭代地进行上采样下采样操作,迭代使用反向投影精细化图像,通过计算重建误差来调整HR图像。PBPN[19](progressive back-projection network)利用这一概念进行连续的上采样和下采样,利用中间生成的HR 图像构建最终图像。SRFBN[20](super-resolution feedback network)将迭代上采样与密集连接层结合,能够更好地挖掘LR-HR 图像对之间的深层关系,从而提供更高质量的重建结果。反向投影机制刚刚被引入到该领域,具有很大的潜力,需要进一步探索。
1.4 损失函数
损失函数是网络模型的重要组成部分,一般用于测量网络重建误差并指导模型优化。本节主要研究医学CT超分辨率领域广泛使用的损失函数。
1.4.1 像素损失(pixel loss)
像素损失是用来度量两幅图像之间的像素级差异,主要包括L1损失(即平均绝对误差)和L2损失(即均方误差):
其中,h、w和c分别是图像通道的高度、宽度和数量。像素损失的目标是使生成的HR图像I在像素值上足够接近真实图像I,L1损失计算的是实际值与目标值之间绝对差值的总和,L2 损失计算的是实际值与目标值之间绝对差值的平方总和。与L1 损失相比,L2 损失可以对大的损失进行惩罚,但更能容忍小的误差,因此经常导致图像过于平滑,所以在近期的网络模型中使用L1损失更多。
在超分辨率领域,峰值信噪比是应用最广泛的评价指标之一,最小化像素损失可以使峰值信噪比最大化,因此像素损失也得到普遍应用。然而,由于像素损失没有考虑到图像的感知质量、纹理细节等,因此结果通常缺乏高频细节且纹理过于平滑。
1.4.2 感知损失(perceptual loss)
感知损失是使用预先训练的特征提取器的特定层来最小化特征空间中的均方误差,常用到的有VGG(visual geometry group)、ResNet(residual network)等,利用卷积层抽象高层特征,从更高维度感知图像,能够更准确地模拟人对图像的感受,基于VGG 的感知损失公式如下:
其中,Cj、Hj、Wj为特征图的通道数、长度和宽度,ϕ是预先训练的VGG模型,j表示ϕ的特定层特征图。
与像素损失不同的是,感知损失追求输出图像在视觉上与目标图像相似,而不是迫使图像精确匹配像素。感知损失可以获得更好的视觉效果,被广泛应用于超分辨率重建领域。
1.4.3 对抗损失(perceptual loss)
生成对抗网络(generative adversarial network,GAN)具有强大的学习能力,在各种视觉任务中应用广泛。GAN在训练过程中,交替执行两个步骤:固定生成器并训练鉴别器更好地进行识别;固定鉴别器并训练生成器得到与目标图像更接近的图像。基于交叉熵的对抗性损失公式如下:
其中,Lgan_ce_g和Lgan_ce_d分别表示生成器和鉴别器的对抗性损失,Is表示真实HR图像中随机采样的图像。
基于最小二乘误差的对抗性损失可以实现更稳定的训练过程和更高质量的结果[21],如下所示:
广泛的MOS测试表明,使用对抗性损失训练的SR模型与使用像素损失训练的模型相比产生了较低的PSNR,但是在感知质量方面有显著的提高[22]。为了得到更好的感知效果,许多模型采用多种损失函数,但组合型损失函数目前并无最优解,还需继续探索研究。本文在“3.4 节损失函数改进”中讨论了近期的医学CT 超分辨率重建模型使用的各种组合型损失函数。
2 图像质量评估准则(image quality assessment,IQA)
对SR模型性能进行评定,可以减少选择的盲目性,而且对创新SR模型和算法具有科学的指导意义。图像质量评估主要分为主观评估和客观评估,本章将介绍医学CT超分辨率模型中常用到的评价指标。
2.1 主观评价
主观评价就是从人的主观感知来评价图像的质量,力求能够真实地反映人的视觉感知。根据是否有真实HR 图像作为标准参考图像,可以将其分为相对主观评价指标和绝对主观评价指标。相对评估经典方法有平均意见得分(mean opinion score,MOS)[23]、绝对评估常用到的是平均意见排名(mean opinion rank,MOR)[24]。表1所示为两种主观评价指标的评价尺度。

表1 主观评价指标的评价准则Table 1 Evaluation criterion of subjective evaluation indexs
虽然主观评价能够根据人眼的感知,直观并较精确地评价图片质量,但是费时费力,不能动态地调整参数,还会受到观看距离、显示设备、观测者的视觉能力、情绪等各种因素的影响。因此,能够自动精确地评价图像质量的数学模型是有必要的。
2.2 客观评价
客观评价是使用某种特定的数学模型给出参考图像和评估图像之间的差异量化值,具有自动化及不受主观因素影响的优点。使客观评估算法与人的主观质量判断相一致,是图像质量评估研究的重点。
(1)峰值信噪比(peak signal-to-noise ratio,PSNR)
峰值信噪比借助均方误差(mean squared error,MSE)来计算图像重建情况,MSE用于检测重建后的图像和真实图像的相似度。一般PSNR 的范围在20 到40之间,其值越大代表重建图像与参考图像越接近。
其中,y为真实图像,x为模型重建图像,N为图像的像素个数,L为图像的最大像素值,一般为255。
PSNR计算速度快,使用方便,是目前图像处理领域应用最广泛的评估指标之一。但其局限性也非常明显,PSNR 是基于逐像素点的,即图像中的每个像素点对图像质量结果输出的权重是相同的,这不合理;同时,人的视觉系统对于亮度信息的敏感度是强于色度信息的,以上因素导致PSNR给出的结果不够接近人眼的直观感觉。
(2)结构相似性(structural similarity index,SSIM)
结构相似性[25]通过比较参考图像内的对比度、亮度和结构细节来衡量图像之间的结构相似度,用图像均值作为亮度的估计、标准差作为对比度的估计、协方差作为结构相似程度的度量。SSIM的范围为0到1,当两张图像完全一样时,SSIM的值等于1。
其中,μx是x的平均值,μy是y的平均值,是x的方差,是y的方差,σxy是x和y的协方差,C1和C2是用来维持稳定的常数,l是像素值动态范围。
SSIM 基于人类对图像中结构信息的感知,改进了PSNR的缺点。但是当图像出现位移、缩放、旋转等非结构性失真时,SSIM 无法有效运作。当参考图像是方差或亮度较低的医学图像时,SSIM是不稳定的,可能会出现不一致的结果[26]。
(3)信息保真度准则(information fidelity criterion,IFC)与视觉信息保真度(visual information fidelity,VIF)
基于信息论中信息熵基础,互信息被广泛用于评价图像质量。IFC[27]和VIF[28]都是通过计算待评图像与参考图像之间的互信息来衡量待评图像的质量优劣的。这两种方法扩展了图像与人眼之间的联系,但是对于图像的结构信息没有反应。
(4)其他评价指标
均方根误差(root mean square error,RMSE)衡量的是预测值与真实值之间的偏差,并且对数据中的异常值较为敏感。距离得分(frechet inception distance score,FID)是计算真实图像和生成图像的特征向量之间距离的一种度量,从原始图像的计算机视觉特征的统计方面的相似度来衡量两组图像的相似度。如果FID 值越小,则相似程度越高,最好情况即是FID=0,两个图像相同。
3 医学CT影像超分辨率网络
本章将从面向网络结构的改进出发,系统介绍近期基于深度学习的医学CT影像超分辨率网络的相关研究工作,详细阐述每个功能模块的改进目的及其实现方法,将常规结构与改进结构进行对比总结,通过提供结构上使用的SR 方法组件的细节来对比总结医学CT 影像超分辨率最新进展。如图4 所示,根据LR 图像生成SR 图像的过程,按照输入模块改进、特征提取模块改进、放大重建模块改进、损失函数改进以及其他结构改进依次展开。

图4 超分网络模块改进Fig.4 Improvement of super resolution network module
3.1 输入模块改进
超分辨率网络一般需要利用大量LR-HR图像对进行训练,大多数文献采用双三次插值将高分辨率图像处理为低分辨率图像,但这种数据集处理方法在实际应用中效果不佳,因为现实世界的LR 图像的降质过程更加复杂且未知。本节将从对输入的LR图像进行处理和添加额外信息这两个方面介绍对输入模块的改进。
3.1.1 处理LR图像
获得清晰结果的一种广泛使用的方法是使用固定的标准偏差添加高斯模糊。与其他方法不同,为了避免过拟合到一个固定的标准偏差,Georgescu 等[29]使用随机标准差的高斯模糊平滑输入,获得更清晰的图像。
小波变换是指利用高频子带和低频子带中的全局结构信息高效地表示纹理。在SR 中使用小波变换,利用插值后的LR 小波子带生成HR 子带的残差,而反小波变换则对HR 图像进行重构。Amaranageswarao 等[30]利用小波变换捕捉LR图像的不同方向高频内容。小波变换在每个分解层产生对应不同频率分量的四个子带,分别是近似子带和不同边缘方向子带(水平、垂直和对角线),捕获图像在不同方向上的结构信息,可以有效利用图像的结构信息来推断缺失的细节。一级小波分解的滤波器组运算框图如图5所示。
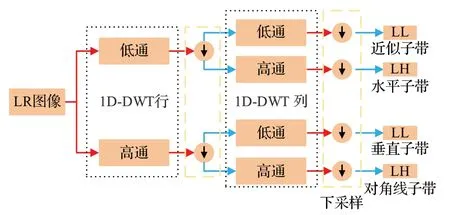
图5 一级小波分解的滤波器组运算框图Fig.5 Block diagram of filter bank analysis for level-1 2D-DWT decomposition
3.1.2 添加额外信息
Gu等[31]提出的MedSRGAN(medical images superresolution using generative adversarial networks),引入了一个均值为零、单位变化的随机高斯噪声作为额外的扰动通道,使网络的特征映射具有一定随机性,帮助网络在同质区域更能自适应地生成更可行的模式。Kudo等[32]将包含身体部位信息的切片条件和参数尺度退化的虚拟薄图像输入鉴别器,使其可以对不同的身体部位进行调节。EDLF-CGAN[33](edge detection loss functionconditional generative adversarial networks)采用亮度和对比度作为输入辅助条件,以解决纹理不合理的问题,提高图像精度。
本小节介绍的方法均为基于退化模型的方法,虽然有助于模型获得更清晰的图像,但是真实的退化模型难以模拟,使用合成数据不能准确评估超分辨率模型在实际医学应用中的性能。但是基于退化模型的方法并不是没有意义的,Ji[34]等通过从真实世界的图像对学习一组基本模糊核和相应的像素权重,开发了一个有效的退化框架,并赢得了NTIRE 2020真实世界图像超分辨率挑战[24]。基于退化模型的超分辨率的卓越性能表明,这种方法是解决真实世界SR的可行方案。
3.2 特征提取模块改进
为了针对性地解决不同的问题,常常会采用多种网络结构相结合的方式。特征提取模块的改进一种是基于现有的残差结构、密集连接以及注意力机制等进行改进或组合来达到更好的效果;另一种则是针对特定任务在模块加入新的网络设计如群卷积、信息蒸馏等。
3.2.1 基本块变体
特征提取模块由大量特征提取基本块组成,最常使用的基本块有残差块、密集连接块以及嵌套残差的密集连接块,其中残差块在特征提取中具有较好的性能,所以许多超分辨率模型都会采用残差块作为网络的一个基本单元。针对特征提取模块中的残差块及残差结构进行改进是医学图像超分辨率领域被广泛采取的改进方法。
本小节主要针对特征利用不足的问题,对特征提取基本块结构进行梳理总结,讨论每个基本块的创新与优势。根据常见基本块结构可将其分为五个小类进行阐述,分别是:残差块改进、嵌套残差的密集连接块改进、残差结构与注意力机制结合、残差结构与上投影下投影块结合以及U-Net架构。
残差结构有助于解决梯度消失和梯度爆炸问题,增强网络学习能力,在训练更深网络的同时保证良好的信息。针对残差块进行改进的网络有:You 等[35]在GANCIRCLE(GAN constrained by the identical,residual,and cycle learning ensemble)中将残差块的ReLU 替换为LeakyReLU进行非线性处理,以改善评价指标,并结合跳跃连接提取局部和全局的图像特征。基于此模型,Jiang等[36]将16个相同的残差块采用跳跃连接迭代的学习上一层的输出,并应用并行1×1卷积运算来降低每个隐藏层输出的维数,使网络训练更加流畅。Jiang等[37]将SRGAN(super-resolution generative adversarial networks)残差块的普通卷积替换为空洞卷积,并去除了BN(batch normalization)层。在SR 任务中,BN 层会产生伪影,限制泛化能力。这样既能充分利用图像信息,又能最大限度地保留超分辨率后图像的语义信息。
密集连接使特征和梯度的传递更加有效,能够有效缩减模型大小,减轻梯度消失现象。针对嵌套残差的密集连接块改进的模型有:WCRDGCNN[30](wavelet based novel cross connected residual-in-dense grouped convolutional neural network)中使用交叉连接密集分组卷积块作为基本模块,该模块包含14个交叉连接的分组卷积,上下分支层之间交叉连接,有助于学习不同的特征集,避免更深层次网络中的特征冗余。Zhang 等[38]提出新的轻量化多重密集残差块结构,与RDN[39](residual dense network)不同的是,该结构在残差块外采用密集连接,尽可能地保持了重建图像的全局信息,该结构不仅实现了CT 影像特征复用,保证了最大程度的信息传输,而且减少了仅使用DenseNet或ResNet的冗余。
注意力机制[40]通过不断调整权重,帮助网络关注局部信息,权重越高表示对重要信息越关注。多尺度学习是在不同尺度上使用相同的特征提取过程,来处理单一网络下的多尺度SR问题。信息蒸馏结构采用通道分裂操作逐步提取特征,将特征分为两部分,一部分被保留,另一部分进行进一步的蒸馏操作,然后将两个特征融合以获得更多的信息,使模型可以在深度网络中学习图像特征,并提取特征信息。Zhao 等[41]提出的IDMAN(information distillation and multi-scale attention network)模型为了充分利用图像的特征信息,将信息蒸馏与深度残差网络相结合,并且该模型使用如图6所示的多分支多尺度注意块(multi-scale attention block,MAB),与传统的通道注意模块图6(a)相比,MAB 的多分支结构图6(b)具有3×3和5×5分支,由于两个分支的特征融合,可以更好地捕获信息。通过这些改进,该模型有效地解决了特征利用不足、注意源单一的问题,提高了学习能力和表达能力,能够重构出更高质量的医学CT 图像。Gu 等[31]基于RCAN[42](residual channel attention network)提出改进的残差全图注意网络(residual whole map attention network,RWMAN),用于从不同的通道提取有用信息,同时更加关注有意义的区域。
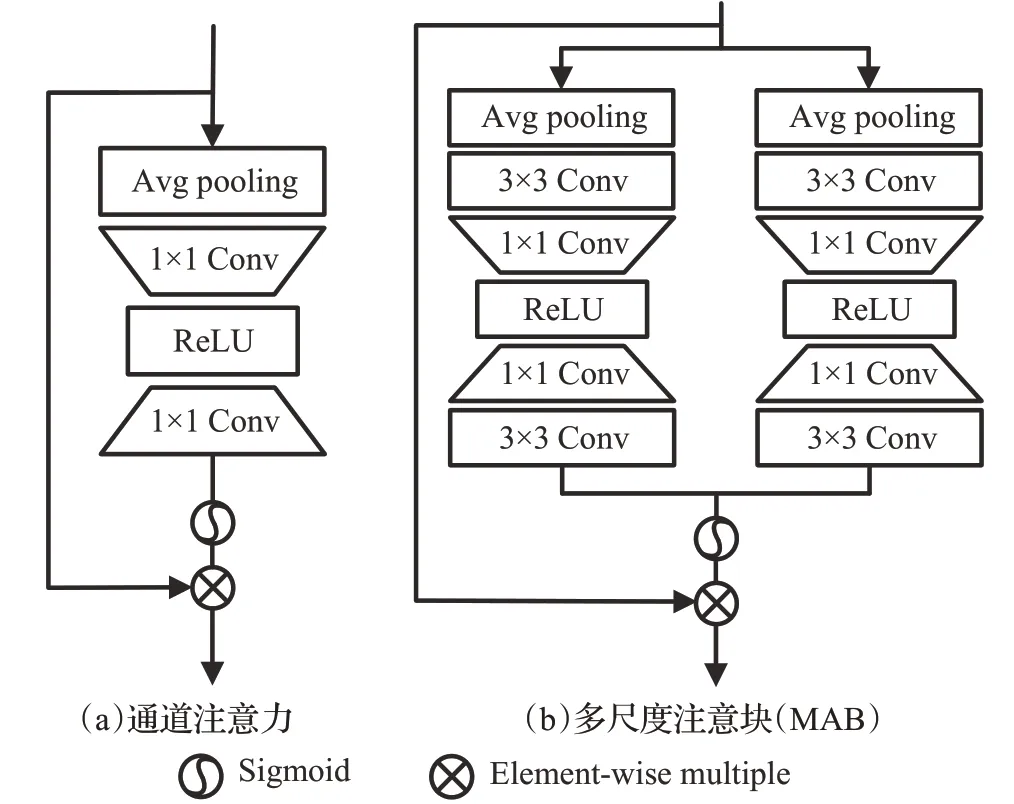
图6 传统通道注意模块和多尺度注意块Fig.6 Traditional channel attention module and multi-scale attention block
Haris 等[43]提出的上投影块和下投影块是通过迭代纠错反馈机制减少重构误差,残差结构与上投影下投影块结合的算法有:Qiu等[44]提出的MWSR(multi-window back-projection residual networks)使用多窗口上投影下投影残差模块提取图像特征,之后将几个具有全局特征的相同连续残差模块进行合并,输入到重构模块中。MWUD结合三个窗口同时提取同一特征图的关键信息,可以有效利用浅层网络中各层的特征图,提高高频信息检测的概率。Song 等[19]设计了残差注意模块(residual attention,RA)和上投影下投影残差模块(up-projection and down-projection residual,UD),如图7的K所示。UD采用三次上采样和三次残差连接下采样的方法,以最小的重构误差提取浅层特征。RA 模块由残差注意块组成,可以从LR 图像中提取更多的深层高频信息。在对LR 图像特征进行多次上采样的过程中,通过反投影和深度特征提取提高了SR重建的性能。U-Net[45]架构通过跳跃连接将高、低层次特征映射拼接,从而保留不同分辨率下的像素细节信息,使用U-Net架构的算法有:EDLF-CGAN[33]模型和Kudo等[32]提出的算法。渐进式U-Net残差网络PURN[46](progressive U-Net residual network)设计了双U-Net 模块,该模块执行三次上采样和三次下采样,可以有效提取LR图像特征,更好地学习HR和LR图像之间的依赖关系。同时该模型在双U-Net模块中引入局部跳跃连接结构,在重构层中引入全局长跳跃连接结构,进一步丰富了重构HR图像信息的流程。

图7 特征提取模块结构对比Fig.7 Comparison of feature extraction module structures
以上是对特征提取基本块的分类总结,主要是为了解决特征利用不足问题,有效提取浅层深层的特征,充分利用图像信息。残差结构在SR特征提取中有普遍应用,使用最新的网络结构和学习策略与残差结构相结合提取特征是被广泛采取的改进方法,如图7所示为按照五个小类对特征提取模块结构进行分类对比。
3.2.2 针对特定任务加入不同结构
本小节将介绍特征提取模块中针对特定任务做出的创新与改进,主要分析特征增强和轻量化网络这两个方面的改进。
在医学影像中,小的解剖标志和病理细节对准确的疾病分析至关重要,一般可以通过加入SE(squeeze-andexcitation)模块[40]或者注意力模块进行激励,来增强目标特征、抑制无关特征。
SE 块是通过显式的模拟通道之间的相互依赖关系,自适应地重新校准通道特征响应。Bing等[47]改进了原始的SE 块[40],如图8 所示。改进SE 块激活函数中的残差同时利用三层网络的输入输出,只需对权重进行微调,缓解训练过程中的困难,并且有效改善了尺度小于1的多次乘法导致的特征弱化问题。

图8 改进SE块Fig.8 Improved SE block
IDMAN[41]模型使用多分支多尺度注意块(MAB),MAB采用3×3和5×5两个分支的特征融合,可以更好地捕获信息,有效地解决注意源单一的问题。RWMAN[31]基于注意力机制,使用了1×1卷积和Sigmoid激活函数,有助于模型自适应地放大或降低每个像素的效果。Yu等[48]使用的TAB(through-plane attention block)利用体积数据的空间位置关系,达到了较好的性能。Kudo等[32]在鉴别器中增加了自注意力层,加速了对抗性训练的收敛。
轻量化网络(lightweight network,LN)[49]指的是通过设计紧凑的结构或者使用轻量化策略来减少网络参数量,提升网络速度,并保持或提升原有网络性能的一种高效网络,是对性能和效率的一种权衡。
VolumeNet[50]使用轻量级Queue 模块,主要由可分离的二维跨通道卷积构成。分解的3D卷积最初通过1×1×1 卷积将通道从S减少到R,然后来自三个轴的1D卷积对所有通道的特征进行卷积,最后一层使用1×1卷积将通道从R增加到T。Queue 模块通过减少参数数量来加快处理速度,并通过深化网络提高精度。
Zhang 等[38]使用的轻量化多重密集残差块结构,减少残差单元数量,建立密集连接,最大限度保证信息传输。Jiang等[37]和Qiu等[44]使用了空洞卷积,可以在没有池化层(池化层会造成信息丢失)和等量参数的情况下提供更大的接受域,使每次卷积输出包含更大范围的信息,充分利用图像信息,最大限度地保留超分辨率后的图像语义信息。VolumeNet[50]和WCRDGCNN[30]都使用了群卷积来减少训练参数,解决内存不足的问题。
3.3 特征图放大重建模块改进
特征图放大重建模块负责对特征图进行上采样并还原为超分辨率图像,由上采样和特征图重建组成。
3.3.1 上采样方式
不同上采样方式对网络模型性能有很大影响,上采样方式可以分为基于线性插值的上采样和基于深度学习的上采样。下述为医学CT超分辨率重建领域常用的上采样方法。表2为这些上采样方法的优缺点对比。

表2 常用上采样方法对比Table 2 Comparison of commonly used upsampling methods
线性插值方法在超分领域应用广泛,其中最常用的就是双三次插值方法[14]。双三次插值是利用待采样点周围16个点的灰度值作三次插值,不仅考虑到4个直接相邻点的灰度影响,而且考虑到各邻点间灰度值变化率的影响。与其他插值方法相比,双三次插值可以得到更平滑的边缘,效果更佳,但也导致了运算量急剧增加。基于插值的上采样只能通过图像本身内容提高图像的分辨率,并没有带来更多信息,并且有噪声放大、计算复杂度增加以及结果模糊等副作用。
端到端学习层被称为亚像素层[51],通过对卷积产生的多个通道进行重新洗牌[51]操作实现上采样,如图9所示。该方法具有广泛的感受野,提供了更多的上下文信息以帮助生成更多逼真的细节。然而,由于感受野的分布是不均匀的,并且块状区域共享相同的感受野,因此可能会导致不同块的边界附近出现一些伪影,并且独立预测块状区域中的相邻像素可能会导致输出不平滑。

图9 亚像素层Fig.9 Sub-pixel layer
反卷积也叫转置卷积(transpose convolution)[52],通过插入零值,进行卷积来提高图像分辨率。如图10 所示为比例因子为2,卷积核为3×3 的反卷积层。由于反卷积在保持与卷积兼容的连接模式的同时以端到端的方式放大了图像大小,因此它被广泛用作SR 模型的上采样层。然而,该层很容易在每个轴上引起“不均匀重叠”,并且两个轴上的相乘结果进一步创建了大小变化的棋盘状图案,损害了SR性能。

图10 反卷积层Fig.10 Deconvolution layer
元上采样[53]以任意上采样因子放大LR 图像,具体来说,对于HR图像上的每个目标位置,此模块将其投影到LR 特征图上的一个小块,根据密集层的投影偏移和缩放因子预测卷积权重并执行卷积。该方法能以任意因子连续放大单个模型,性能可以超过使用固定因子的模型,并且预测权重的执行时间比特征提取所需总时间少100 倍[53]。但是,该方法基于与图像内容无关的多个值来预测每个目标像素的卷积权重,因此当放大倍数较大时,预测结果可能不稳定且效率较低。MIASSR[54](medical image arbitrary-scale super-resolution)设计的meta-upscale 模块由两个全连接层和一个激活层组成。它根据输入的比例因子预测一组权重,利用矩阵乘法实现特征图放大。然后由放大后的特征图生成超分辨率图像,实现了医学图像的任意尺度超分辨率。
EDLF-CGAN[33]模型采用快速上卷积实现上采样操作,在使用5×5 卷积核的卷积操作中,有很大一部分操作是在0 的数据上操作的,很浪费时间,因此把原来的5×5卷积核分为四个不同的小尺寸卷积核,在得到相同效果的同时用时很少,大大降低了网络的棋盘效应。
3.3.2 重建结构改进
GAN-CIRCLE[35]模型的重建部分如图11所示,该模块使用网中网结构,两个重建分支A、B 合并为C,提高网络非线性能力,使其可以学到更复杂的映射关系。de Farias 等[55]提出的CT SR 病灶聚焦框架也使用了网中网结构来增加非线性并降低滤波器空间维数,以实现更快的计算。
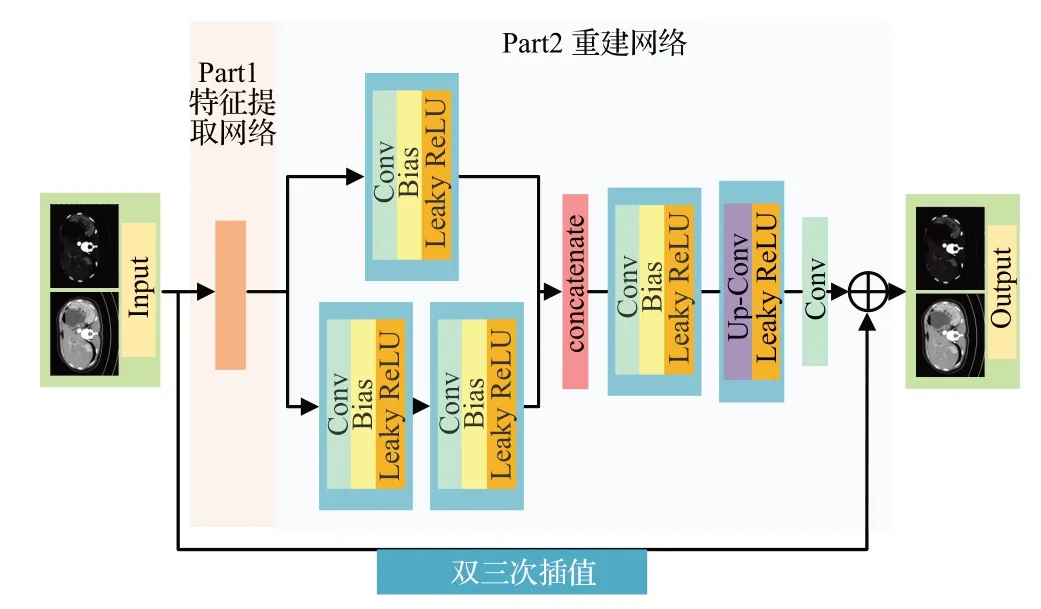
图11 GAN-CIRCLE特征重建结构Fig.11 GAN-CIRCLE feature reconstruction structure
3.4 损失函数改进
损失函数是网络模型的重要组成部分。相较于之前只使用一种损失函数的方法,多种损失函数的组合已表现出明显优势,能给图像带来更好的感知效果[56]。但组合型损失函数目前并无最优解,仍需继续探索。本节介绍医学CT超分辨率重建模型中设计的组合型损失函数及其优缺点。
Georgescu 等[29]在模型中除了计算最后一个卷积层之后的损失外,还在上采样层之后计算了与真实高分辨率图像的损失,中间损失迫使该网络产生更好的输出,更接近基本事实。
Jiang 等[37]在模型中使用平均结构相似度(mean structural similarity,MSSIM)损失代替均方误差(MSE)损失,得到新的感知损失函数,在视觉感知方面获得了更好的效果。MSSIM损失函数如下(N为训练批次大小):
Bing等[47]将L1损失、对抗损失(LRG)[57]、感知损失(LVGG)[58]和均方误差损失(LMSE)[8]组合成为一种新的融合损失,可以进一步加强对低层次特征的约束。新的融合损失如下(w1,wRG,wMSE为超参数,控制每个个体损失的权重):
MedSRGAN[31]训练中采用了内容损失、对抗性损失和对抗性特征损失的加权总和,形成多任务损失函数。MIASSR[54]整个模型采用端到端的综合损失函数进行训练,包括L1 损失、对抗性损失和基于VGG 的感知损失。Jiang 等[36]将对抗损失、循环一致性损失、一致性损失和联合稀疏变换损失结合起来形成新的损失函数,充分利用了没有标准HR 图像的大规模LR 训练样本,并以半监督的方式训练模型。
EDLF-CGAN[33]模型采用的边缘检测损失函数(EDLF)可以抑制不合理纹理信息的产生,定义如下:
其中,W和H分别代表LR图像的宽度和高度,r是下采样因子,表示满足条件y的原始HR图像为HR图像中(x,y)位置的像素值,表示满足条件y的生成图像,C为Canny边缘检测函数[59]。
3.5 其他结构改进
3.5.1 GAN模型鉴别器改进
对抗神经网络(generative adversarial nets,GAN)[60]包含生成器和鉴别器,其优化过程是一个“二元极小极大博弈”问题。大多基于卷积神经网络(convolutional neural network,CNN)的SR 网络都更关注图像质量指标而不是图像视觉感知质量,而SRGAN 在图像感知质量方面取得了巨大的提高。在超分辨率方面,采用对抗性学习只需将SR 模型视为生成器,并定义一个额外的鉴别器来判断输入图像是否为生成图像。GAN模型的生成器结构改进在上述章节中已经介绍,下面将介绍GAN模型鉴别器的改进。
MedSRGAN[31]模型使用图像对(LR,HR/SR)作为鉴别器的输入,如图12所示,鉴别器通过将从LR和HR路径中提取的特征映射进行拼接,学习HR/SR和LR图像的成对信息,并输出(LR,HR)对或(LR,SR)对作为真实数据的概率。

图12 MedSRGAN鉴别器Fig.12 MedSRGAN discriminator
Kudo 等[32]在鉴别器网络的第四层中增加了自注意力层,加速了对抗性训练的收敛。De Farias等[55]提出的CT SR 病灶聚焦框架将空间金字塔池集成到GANCIRCLE[35]的鉴别器中,以处理不同的输入CT 影像大小,用于病灶的斑块聚焦训练,提高了肺部CT数据集中最重要放射学特征的鲁棒性。
3.5.2 Transformer结构
Transformer是一个完全基于注意的序列转导模型,用多头自注意取代了编码器-解码器架构中最常用的循环层。基于深度学习的超分辨率是提高分辨率可行的方法,其大多以在视觉任务方面表现出色的CNN 为核心,通过卷积操作提取局部特征,具有平移不变性,可以使用池化操作减少特征维度,防止过拟合。但是这类方法会受到卷积算子固有属性的限制,使用相同的卷积核来恢复不同的区域可能忽略内容相关性,卷积算子的局部处理原理使得算法难以有效地模拟远程依赖。与基于CNN 的算法相比,Transformer 可以对输入域的远程依赖进行建模,并对特征进行动态权值聚合,从而获得特定于输入的特征表示增强[61]。
医学成像任务的数据集具有标注样本少、图像非自然的特点。在数据集稀缺的情况下,CNN和Transformer的性能都较差,标准的解决方案是使用迁移学习,模型在较大数据集(如ImageNet)上预训练,然后在特定的数据集上进行微调,这类模型通常在最终性能和训练时间方面都优于那些在医学数据集上从头开始训练的CNN。在ImageNet 上预训练的Transformer,在数据有限的情况下表现出与CNN 相当的性能,当自监督的预训练之后是监督的微调时,Transformer 的表现比CNN 好[62]。这些发现表明,Transformer 在医学图像SR 领域有很好的前景。
Yu等[48]提出的基于自注意机制的Transformer体积超分辨率网络(Transformer volumetric super-resolution network,TVSRN)使用非对称编码器-解码器架构,为了更好地模拟可见区域和遮蔽区域之间的关系,解码器使用了比编码器更多的参数。并使用计算量较少的STL(swin Transformer layer)层[63]代替标准的Transformer层[64]作为基本组件,更适合于高分辨率图像,同时使用TAB 利用体积数据的空间位置关系,达到了较好的性能。TVSRN模型结构如图13所示。

图13 TVSRN网络结构Fig.13 TVSRN network structure
相关网络从维度、亮点、数据集和评价参数这几方面总结见表3。

表3 医学CT影像的超分辨率面向结构优化总结Table 3 Summary of medical CT images with super resolution oriented structure optimization
4 超分网络在医学CT领域的应用
临床实践中对医学图像质量有很高的要求,高质量高分辨率的图像能提高诊断决策正确性。基于深度学习的超分辨率重建算法在医学领域有巨大的应用价值,将特定领域的医学图像先验信息与深度网络结构、损失函数以及训练方式结合是有潜力的研究方向。本章介绍超分网络在特定医学CT领域的应用。
4.1 针对Covid-19的CT影像超分网络
新型冠状病毒肺炎(COVID-19)[70]在全球肆虐,肺部遭受病毒侵入后,常呈磨玻璃影,无明显白色肿物改变[71]。CT 扫描是检测COVID-19 肺炎和肺炎严重程度最有力、最有效的方法。Tan 等[72]提出基于SRGAN 和VGG16 的新型冠状病毒病辅助诊断算法,有效提高了新冠病毒图像分类精度,但模型存在较大参数量。MWSR[44]利用多窗口获得更丰富的高低频信息,与垂直深化网络结构相比,这种水平扩展网络结构可以更早地获得完整的COVID-19 CT 图像目标特征,但是,LR 特征空间与HR特征空间之间的特征映射关系有待优化。PBPN[19]使用残差注意模块和上投影下投影残差模块,能重构出包含更多细节和边缘的高质量高分辨率COVIDCT 影像。PURN[46]使用双U-Net 结构,从浅层加强特征监督,促进网络收敛,有效提高图像重建质量,但是该模型的任意尺度算法存在局限性。Nneji等[73]使用轻量级的孪生胶囊网络,以VGG16预训练网络为骨干,共享参数和权重,用于COVID-19筛查,收敛速度快,有很好的分类效果,可以创建更合理和真实的图像,但是模型训练和测试数据集数量有限。Baccarelli 等[74]提出孪生残差自编码器的架构,利用特征向量和自编码器恢复的SR 图像进行迁移学习,通过有限的可训练参数获得更高的精度。Zhou 等[75]提出一种基于快速超分辨率卷积和修正粒子群优化的SR 算法,通过使用突变机制保证粒子的全局搜索能力和种群的多样性。
重建的COVID-19 肺炎CT 图像比原始CT 图像更清晰,对比度更高,提高了AI 算法诊断COVID-19 的准确性,有效辅助COVID-19 的诊断和定量评估。目前,基于卷积神经网络的SR 模型由于网络结构较深,普遍存在高频信息丢失、模型规模过大等问题。基于渐进上采样的COVID-CT 超分辨率网络会增加重建误差。所以未来研究人员需要进一步优化网络结构,设计出更好的SR重建网络。
4.2 针对牙科CT影像的超分网络
牙科诊断中常常会用到锥束CT来确定牙齿的三维结构,但是部分体积效应、噪声和光束硬化[76]等会影响成像质量。Hatvani 等[77]分别利用亚像素网络和U-Net网络提高离体牙齿的二维锥束CT 切片的分辨率,相比基于重建的SR 方法可以更好地检测医学特征,但模型中使用的损失函数并不是度量感知指标的最佳选择。在牙科中心定期进行根管治疗,可以保存腐烂和感染的牙齿,其中根管长度、直径和曲率都是规划治疗的重要因素。Hatvani等[78]提出基于张量分解的三维单图像SR方法,使用较少的参数,具有计算优势,可以很容易地通过视觉检查重建结果并进行调整,但随着迭代次数的增加,差异变得不那么结构化,一些牙齿形状在随机噪声中丢失。Mohammad-Rahimi 等[79]将多个基于深度学习的SR模型应用于牙科全景X线片。SRCNN[8]可以提高放射图像的视觉质量,但应用在根尖周X线片上对牙周骨丢失的检测是无效的。SRGAN可以从下采样图像中恢复逼真的纹理,显著提高图像质量的MOS值,但客观指标不一定得到改善。
应用SR模型来提高低剂量和低分辨率的牙科锥束CT 扫描的质量是有希望的。与基于重建的SR 方法相比,基于深度学习的SR 方法在质量指标和基于图像分割的分析方面都显示出更好的结果。但该类模型计算复杂性高且依赖于训练集,在未来的工作中需要进一步提高网络效率。
4.3 针对肿瘤CT影像的超分网络
CT扫描是肿瘤诊断和治疗的重要辅助手段。结直肠癌(colorectal cancer,CC)是临床上最常见的恶性肿瘤之一,在全球恶性肿瘤发病率中排名第三,在恶性肿瘤死亡率中排名第四。Wang等[80]构建单轴超分辨率的特征增强残差密集网络模型用于非腹膜化结直肠癌诊断,取得了较好的效果,但是在该方法中样本量相对较少,没有大量样本的前瞻性实验。Liu 等[81]使用ResNet18 结合非局部注意机制实现膀胱肿瘤分级和分期双重目标,有效提高了诊断准确率。Xu 等[82]提出一种用于肺癌CT 图像重建的稀疏编码方法,该方法解决了自相似约束导致重建图像边缘过于平滑和模糊的问题。Zhu等[83]提出基于双注意机制的单幅图像SR,该模型通过混合的空间注意力和通道注意力保留了图像的高频细节信息,但模型推理速度慢,不能很好地应用于工程任务。
深度学习医学图像超分辨率重建方法可以为肿瘤的早期诊断提供有力的技术支持。CNN的深度结构大大提高了对原始图像的处理能力,与传统方法相比,CNN 可以自动生成高度抽象的图像特征,并且直接使用原始图像获得更准确的结果,提高了诊断效率。残差网络可以解决深度网络训练中的退化和梯度消失问题,因此通过建立相关学习模型,可以更高效、准确地捕捉相关特征,为临床医生选择治疗方案和指定随访策略提供依据。在未来的研究中要更加关注网络轻量化,在不降低性能的情况下最大限度地提高模型的运行效率。
5 总结与展望
5.1 总结
基于深度学习的医学CT 影像SR 重建对于医学图像分类、分割、融合以及特征提取等领域有重要意义。本文首先介绍了SR 基本理论和评价指标;然后重点介绍了超分网络模型在结构和性能优化方面的创新与进展,并提炼出其优化常用到的网络结构;最后讨论了医学CT 影像SR 重建存在的困难和挑战,并对未来的发展趋势进行了总结与展望。综上,基于深度学习的SR 技术在医学CT 领域仍有极大发展空间,仍有很多尚未完善的工作,需要更多的研究者开展富有创新性的工作。
5.2 展望
本文重点是基于深度学习的医学CT影像超分辨率重建,有许多其他领域的超分模型对医学CT 影像重建有参考价值。例如CT-SRCNN[84]采用级联训练,在逐步增加网络层数的同时提高神经网络精度,并且提出级联剪裁来减小网络规模。SAINT[85](spatially aware interpolation networks)用于提升肝脏、结肠等部位影像的层间分辨率,对于同样层间切片数少的LR CT影像有借鉴意义。LSRGAN[86](Laplacian pyramid generation adversarial networks)使用残差密集块结合拉普拉斯金字塔结构实现了高缩放因子(16×)下心脏影像SR重建,抑制了重建后常出现的伪影。
基于深度学习的超分辨率重建技术在医学图像领域中具有广泛的应用前景,并已经成为目前的研究热点,但其未来发展仍面临着许多问题和挑战。
(1)多因素降质图像的质量增强问题。在计算机辅助诊断系统(computer aided diagnosis,CADs)中,医学图像的退化通常表现为噪声和低分辨率模糊。虽然有DCNN[87](dynamic convolutional neural networks)和双通道联合学习框架模型[6]提出去噪和超分辨率重构,但这方面的研究仍然很少。现有的医学CT 影像SR 重建研究大多没有关注去噪任务和超分辨率任务之间的相互作用,这类方法在解决实际问题时,往往效果欠佳。因此,借助深度神经网络强大的学习能力,开展多种降质因素协同处理方法的研究,具有重要的理论意义和应用价值。
(2)基于无监督学习的超分辨率重建问题。从监督学习到无监督或半监督学习,成对数据的要求限制了监督算法的发展,而无监督或半监督学习只需要少量的匹配数据来训练网络,可节约获取大量数据集的时间,直接使用现实图像进行训练和测试,不依靠外部数据集,更能提高模型泛化能力。因此,无监督学习有极大发展空间。
(3)网络结构和学习策略。网络结构设计在本质上决定了模型的整体性能。例如“上采样方法”中所讨论的四种方法各有其优缺点,需要进一步研究适用于SR模型的、适用于任何比例因子的上采样方法。许多网络应用注意力机制、多尺度学习、网中网结构和信息蒸馏等网络结构提高输出图像质量。因此,创新网络结构,研究开发计算成本低且能提供最佳性能的网络架构是另一个有前途的研究方向。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
数学小灵通·3-4年级(2021年5期)2021-07-16
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
数学物理学报(2019年3期)2019-07-23
今日农业(2019年15期)2019-01-03
家庭影院技术(2018年9期)2018-11-02
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
