
A Denoiser for Correlated Noise Channel Decoding:Gated-Neural Network
2024-03-11 06:28XiaoLiLingZhaoZhenDaiYonggangLei
China Communications 2024年2期
Xiao Li ,Ling Zhao,* ,Zhen Dai ,Yonggang Lei
1 School of Electronic and Information Engineering,Beihang University,Beijing 100191,China
2 Beijing Institute of Tracking and Telecommunications Technology,BITTT
Abstract: This letter proposes a sliced-gatedconvolutional neural network with belief propagation(SGCNN-BP) architecture for decoding long codes under correlated noise.The basic idea of SGCNNBP is using Neural Networks (NN) to transform the correlated noise into white noise,setting up the optimal condition for a standard BP decoder that takes the output from the NN.A gate-controlled neuron is used to regulate information flow and an optional operation-slicing is adopted to reduce parameters and lower training complexity.Simulation results show that SGCNN-BP has much better performance (with the largest gap being 5dB improvement)than a single BP decoder and achieves a nearly 1dB improvement compared to Fully Convolutional Networks(FCN).
Keywords: belief propagation;channel decoding;correlated noise;neural network
I.INTRODUCTION
Channel coding is important to improve the reliability of the communication system.For instance,lowdensity parity-check(LDPC)codes are proved to yield a performance close to the Shannon capacity under certain conditions[1].LDPC code in binary symmetric channel(BSC)exhibits outstanding performance.Especially in the case of additive white Gaussian noise(AWGN),BP decoding has excellent performance.However,many factors such as correlated noise may impair the communication performance in the SAGIN system[2]and Cognitive Radio(CR)[3]when filtering or oversampling,which will degrade BP decoding performance.The traditional method of solving correlated noise is to use a matrix to whiten the correlated noise,but the whitening matrix is too complicated when the code length is long or the correlated noise is too complex,and the same matrix cannot be applied to different correlated noises.At the same time,it is not always feasible to consider independent multiple-input multiple-output (MIMO) channels due to the physical limitations of antenna spacing and the lack of a environment with sufficient scatters in MIMO systems[4][5].
In recent years,researchers have tried to solve some communication problems including channel decoding using deep learning technologies[6][7].Liang and other researchers have proposed an iterative BP-CNN architecture for correlated channel decoding,which has better decoding performance than standard BP with lower complexity[8].
This paper is mainly inspired by [8] and [9].With the help of the excellent decoding ability of the BP decoding algorithm under Gaussian white noise,NN is used to transform correlated noise into white noise as much as possible.We propose a sliced-gatedconvolutional neural network with belief propagation(SGCNN-BP) architecture to improve decoding performance.A special neuron with gates is introduced to control the information flow to increase the NN ability to whiten correlated noise.Moreover sliced network is tried to decrease NN complexity with a little performance loss.The main contributions of this paper are as follows:
• We propose to combine the gate-controlled neuron with the convolutional NN.Numerical experiments are used to demonstrate the superior denoising performance of such a combination.
• As a new strategy for decoding long code,the input slicing operation is employed to reduce the dimension of the input layer,generating a lightweight NN with fewer parameters and greatly reducing the time for training and testing.
II.SYSTEM DESIGN
2.1 General
The system model consisting of a transmitter and a receiver is shown in Figure 1.At the transmitter,message bitsmof lengthKare encoded to a codewordxof lengthN.The codewordxis then mapped to a symbol vectorsthrough BPSK modulation.Passing through the correlated channel,the received symbolycan be denoted as
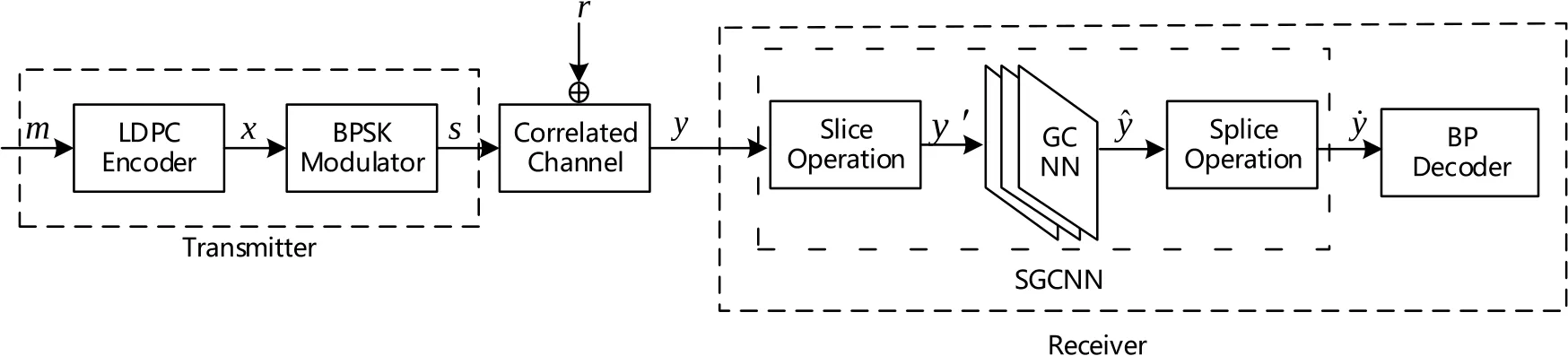
Figure 1.System model:The generated codewords go through a denoising system composed of slicing process and Gatednet-CNN,and finally enters the BP decoder.
whererdenotes the true channel noise.
After that,we slice the codewordsyasy′,feed them to the neural network and obtain the output ˆy.After training,these codewords ˆyare recombined as ˙y.In the end,˙yis fed into the BP decoder.In other words,SGCNN tries to transform the correlated noise via training.The details of SGCNN and slice operation will be introduced in the next section.For performance evaluation,we calculate the bit error rate(BER)according to the decoding results.
2.2 Network Structure
2.2.1 System Model The CNN has reached the limit of its ability to handle noise,and to continue to improve performance on this basis must change its structure.Also,in the subsequent slicing operation,the correlation between noise and codewords will be destroyed.At this time,if the traditional CNN is continued to be used,the decoding accuracy rate will drop significantly.In our model,the normal convolutional neuron is replaced with a gated one.Such special neurons with control gates are simplified from long short-term memory(LSTM)cells to regulate the data flow and parameter passing in channel decoding problems[10].
2.2.2 Neuron with Control Gates
The following is a brief introduction to this gated neuron for CNN which is shown in Figure 2 The input gate isi,the output gate iso,and thecis the cell.The input vector isv,the input weights areWi,Wc,Wo,while the biases arebi,bc,bo.

Figure 2.Structure of a gate-controlled neuron.
The operations of the gated neuron can be denoted as:
The symbol⊙is point-wise multiplication of two vectors.Theσgandσhare non-linear activation functions:
In the structure proposed in this paper,a GCNN layer consists of three CNN layers with the same structure except for the activation function,corresponding to the input gate of the gated neuron,the output gate and the neuron cellc,after training the data of these three CNN layers are multiplied to obtain the output of a GCNN layer.
2.2.3 Silced Convolution Neural Network
As the length of codeword N grows,the direct NN decoder become much more complex with huge trainable parameters.Inspired by their partitioned NN polar decoding structure in [11],we partition the input layer into smaller pieces in order to produce a lighter network for training.Because we are more concerned with the noise,the structure of the codewords itself is less important in this paper.
For example as shown in Figure 3,theN-length input is partitioned into 2 pieces,then eachN/2-length input is connected,the batch size will be doubled.Because the input dimension is reduced,the corresponding neural network with smaller parameters can be used.Then we feed the low-dimensional codewords into the neural network,after training these codewords are restructured to have the same dimensions as the original input and fed into the BP decoder.

Figure 3.Slicing operation of cutting input into two pieces:(1)Slice the input y of dimension(batch size=B,codeword length=N)along codeword length(2)Splice the sliced input along the batch size as y′(3)Feed y′ to the neural network with fewer parameters.
2.3 Loss Function
As mentioned before,the purpose of using SGCNN is to white the correlated noise.The residual noise on ˆycan be denoted as
We adopt the Jarque-Bera test as a part of this loss function to evaluate if ˆrfollow normal distribution[12].The new loss function is defined as
where
The first term in(9)is the well-known mean-squareerror(MSE)loss and the second term is adopted from the Jarque-Bera test whose value is smaller when the samples are closer to a Gaussian distribution,λis a scaling factor that balances these two objectives.
III.SIMULATION RESULTS
For performance evaluation,we use a systematic(576,432)LDPC code at the transmitter and the parity check matrix is from[13].As for the correlated channel,we adopt a widely used standard model as following[5]:
Wherewis white Gaussian noise andηis the correlation coefficient with |η|≤1,the larger theη,the stronger the noise correlation.For traditional CNN,{4;9,3,3,5;64,32,16,1}represents the number of layers,filter sizes and the feature maps.Since a SGCNN layer is composed of three CNN layers with the same structure,these parameters mean the number of SGCNN layers,the filter sizes and feature maps of these CNN layers that make up the SGCNN.Other basic SGCNN-BP settings are given in Table 1.Because noise is unpredictable in practical applications,we only train the network with the SNR of{-3,-2.5,-2,-1.5,-1,-0.5,0}and then test the network performance with different values of SNR.
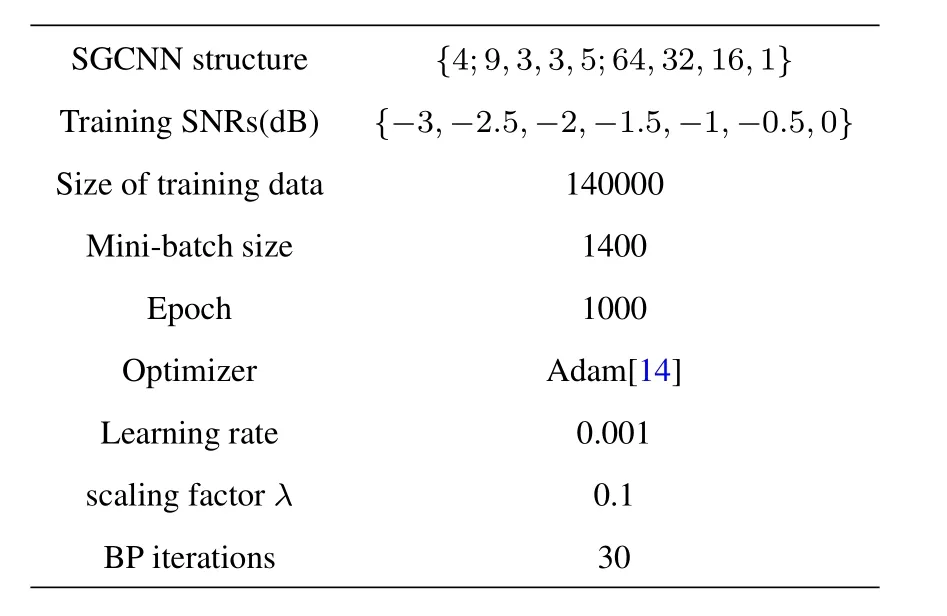
Table 1.Basic SGCNN-BP settings.
It should be mentioned that the log-likelihood ratios(LLRs)in SGCNN-BP can be calculated by the simple form as:
whereσ2is the power of the Gaussian channel noise.This is because that the noise on the prediction of SGCNN is expected to follow a Gaussian distribution benefitting from the normality test in loss function.With a small enough Jarque-Bera test value,it can be accepted that predicted residual noise ˆrfollows a Gaussian distribution statistically in our simulations.
We test the SGCNN-BP decoder in two correlated channels: moderate correlation (η=0.5) and strong correlation(η=0.8).Standard BP,iterative BP-CNN,and iterative BP-FCN are used to compare the performance with SGCNN-BP.
The first is SGCNN,CNN,and FCN without slicing,the parameter numbers used in our simulations are listed in the first three items of Table 2.Due to the implementation of gate-controlled neurons,the number of parameters of SGCNN triples that of CNN with the same structure.

Table 2.List of parameter numbers.
Results in Figure 4 show that the performance of SGCNN is the best.Under strongly correlated noise,SGCNN-BP achieves nearly 5dB improvement compared to the traditional BP decoder atBER=10-5and in comparison to iterative BP-FCN,SGCNN-BP improves the performance at 1dB.

Figure 4.Performance comparison on different methods and correlations: (a) η=0.5,moderate correlation. (b) η=0.8,strong correlation.
Next we partition the input codeword into 2 and 8 slices.Due to the reduction of the input dimension,the neural network will also change,the structure of the specific network is also given in Table 2.We record the relevant times of SGCNN based on an Nvidia GTX1080 Ti GPU in Table 3.We only record the time that the data passes through the SGCNN.We can see that both the training time and inference time of the neural network that changes with the input slice will be greatly reduced.The decoding results in Figure 5 show that after slicing,the denoising ability of the neural network decreases because the dimension of the input is reduced.This reduction in performance is acceptable given the dramatic reduction in the amount of parameters and correlation time,and it is believed that this method of reducing training parameters and complexity can be used in the decoding of longer code.

Table 3.List of training and inference time for (576,432)LDPC.

Figure 5.Performance comparison on different slices:(a)η=0.5,moderate correlation.(b)η=0.8,strong correlation.
In the case of cutting 8 slices,traditional neural networks cannot effectively extract noise features due to the too small input dimension,since the decoding result of GCNN is still much better than the other two networks and the BP algorithm for direct decoding.
To ensure the fairness of the experiment and to be able to see the superiority of GCNN more clearly,we use deeper FCN for comparison,so that GCNN and FCN maintain similar parameters under the same number of slices.We denote the deepened FCN network as FCN(deeper)and the parameters after slicing are given in Table 4.From the experimental results shown in Figure 6,we can see that even with the same parameters,the performance of FCN after slicing does not outperform GCNN.This proves that GCNN is notjust a simple superposition of parameter quantities.In the case of rapidly reducing the input codeword dimension and network structure,this structure can still have a strong noise reduction ability.So it can be considered that the GCNN structure is better than the FCN or CNN itself.

Table 4.List of parameter numbers.
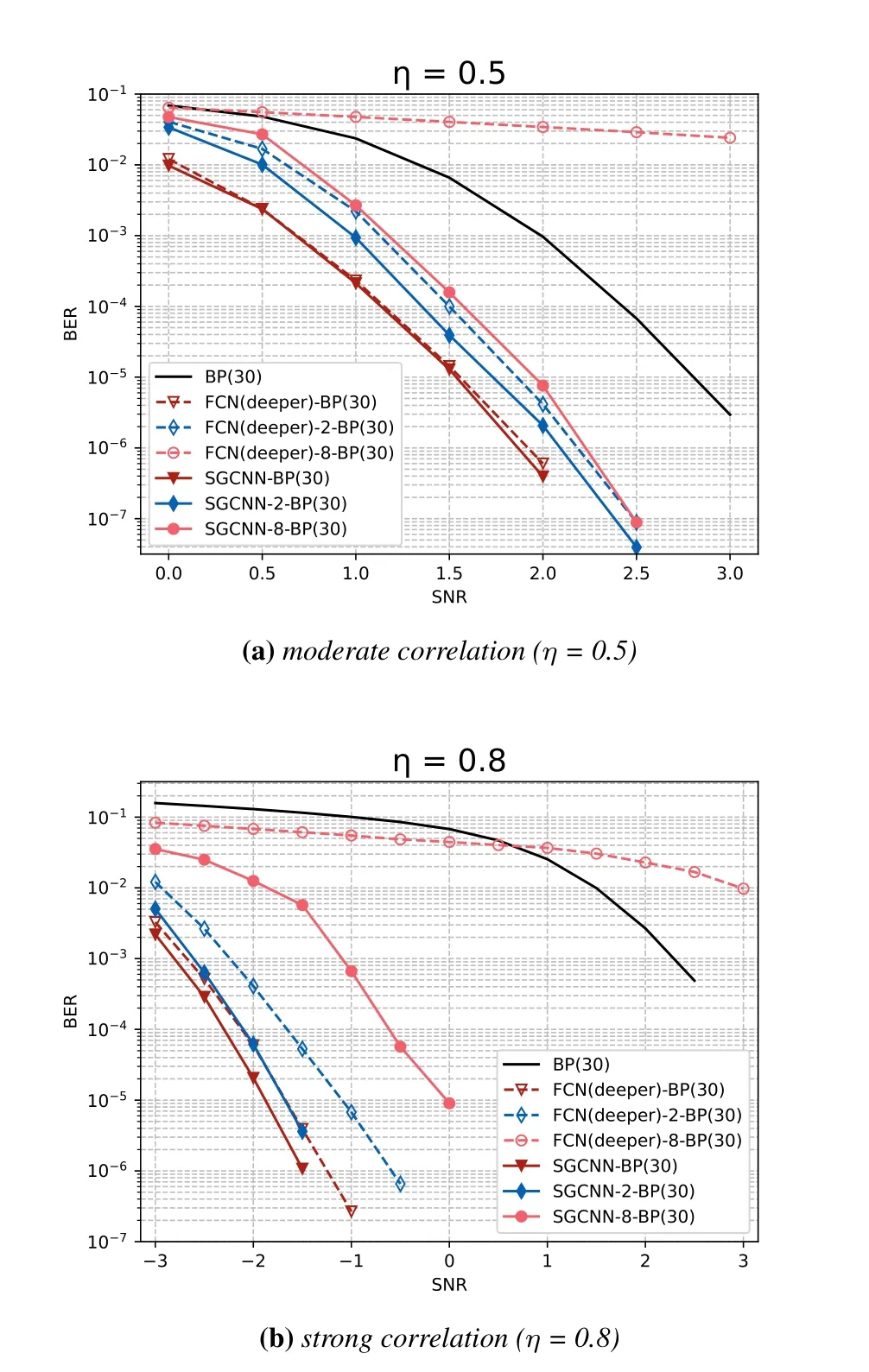
Figure 6.Comparison of two networks under the same training parameters: (a)η=0.5,moderate correlation. (b)η=0.8,strong correlation.
IV.CONCLUSION
We propose a neural network based decoding architecture,SGCNN-BP for decoding under correlated noise.In this architecture,gate-controlled CNN is mainly used to handle colored noise so that it can be sliced into pieces to reduce the complexity.The simulation results show that the proposed SGCNN-BP decoder performs better than the standard BP decoder a gap as large as 5dB and has about 0.5dB improvement compared to iterative BP-FCN.Furthermore,slicing can decrease more than half of trainable parameters with 1dB performance loss.We expect this architecture can be adopted to solve longer code decoding problems in the future.
ACKNOWLEDGEMENT
This work was supported by Beijing Natural Science Foundation(L202003).

- China Communications的其它文章
- Resilient Satellite Communication Networks Towards Highly Dynamic and Highly Reliable Transmission
- Mega-Constellations Based TT&C Resource Sharing: Keep Reliable Aeronautical Communication in an Emergency
- High-Precision Doppler Frequency Estimation Based Positioning Using OTFS Modulations by Red and Blue Frequency Shift Discriminator
- Blockchain-Based MCS Detection Framework of Abnormal Spectrum Usage for Satellite Spectrum Sharing Scenario
- Energy-Efficient Traffic Offloading for RSMA-Based Hybrid Satellite Terrestrial Networks with Deep Reinforcement Learning
- For Mega-Constellations: Edge Computing and Safety Management Based on Blockchain Technology