
一种改进轻量化神经网络的齿轮箱故障诊断方法
2024-04-01 07:30杨青松郝如江范亚飞邓飞跃杨文哲
科学技术与工程 2024年7期
杨青松, 郝如江*, 范亚飞, 邓飞跃, 杨文哲
(1.石家庄铁道大学机械工程学院, 石家庄 050043; 2.石家庄铁道大学省部共建交通工程结构力学行为与系统安全国家重点实验室, 石家庄 050043)
齿轮箱是机械设备中常见而关键的部件之一,有着传递动力、改变速度和调整方向等功能。齿轮箱的工作环境复杂、恶劣,其零部件常常在高速、重载下持续工作,极易发生各种故障[1]。因此,齿轮箱故障诊断成为研究热点问题。多年来国内外学者针对机械设备故障诊断问题提出了功率谱分析、傅里叶变换、包络谱分析、幅值谱分析等特征提取的方法,以及逻辑回归、决策树、K最邻近分类算法等故障分类方法。但由于这些方法过度依赖先验知识,以及特征提取和分类分开执行、难以协同,因此限制了其推广及应用。
随着深度学习的发展,越来越多的学者将其应用于机械设备故障诊断中,其方法包括卷积神经网络、循环神经网络、反向传播(back propagation, BP)神经网络等。孙晔等[2]提出一种基于深度残差网络-极限学习机和迁移学习的风力发电机齿轮箱故障诊断方法,进行了轴承到轴承、轴承到齿轮以及混合故障的小样本迁移故障诊断,该方法的平均准确率可达98.79%;陈科等[3]提出了一种多深度学习模型决策融合的齿轮箱故障诊断分类方法,利用该方法对齿轮进行故障诊断比单个网络模型诊断正确率有所提高,为齿轮故障智能诊断分类提供了新途径;王辉等[4]提出了一种基于深度宽卷积Q网络的行星齿轮箱故障智能诊断方法,该方法能够在多个工况下均可有效、准确地实现行星齿轮箱的智能诊断,诊断准确率均超过99%。在追求更高故障识别率的同时,深度神经网络模型的层数越来越多,参数量越来越大,大而复杂的模型对计算机硬件配置提出了非常高的要求,难以应用在实际设备中。
因此,轻量而高效的神经网络具有很高的研究价值。孙国栋等[5]设计了一种混合深度可分离卷积神经网络用于旋转机械故障诊断,与传统网络相比参数量大大减少;邓飞跃等[6]基于ShuffleNet单元和模块化思想,构建了一种新型轻量化ShuffleNet网络模型,在运算时间、模型参数量和复杂度等方面均有明显提升,对于计算机硬件配置的依赖更小。越来越多的轻量化神经网络应用在故障诊断中,现提出一种基于Shuffle-ECA单元设计方法,采用模块化思想构建Shuffle-ECANet网络模型,并通过实验分析,验证该网络模型可有效用于齿轮箱故障诊断,及良好的现实应用价值。
1 基础理论
1.1 深度可分离卷积
深度可分离卷积由深度卷积(depthwise convolution, DWConv)和逐点卷积(pointwise convolution, PWConv)两部分组成,如图1所示。

图1 深度可分离卷积Fig.1 Depthwise separable convolution
标准卷积将每个卷积核与所有输入通道分别进行卷积运算,深度卷积针对每个输入通道采用不同的卷积核,即通道和卷积核一一对应,逐点卷积为卷积核大小为1×1的卷积,其目的是实现不同通道特征的融合以及通道方向上的升维或降维。逐点卷积将深度卷积输出的特征进行合并,促进通道之间信息的融合,增强了网络表达能力。
标准卷积计算量为
Q1=DK×DK×M×N×DF×DF
(1)
深度可分离卷积计算量为
Q2=DK×DK×M×DF×DF+M×N×DF×DF
(2)
深度可分离卷积与标准卷积计算量比值为

(3)
式中:M为输入通道数;N为输出通道数;DK×DK为卷积核大小;DF×DF为特征图大小。
1.2 分组卷积与通道混洗
分组卷积(group convolution, GConv)对输入特征与卷积核进行了分组,卷积核只与同组的输入特征进行卷积操作,不同组之间没有信息交流,最终输出的特征仅由一部分输入通道的特征计算得出,这种操作阻碍了信息的流通,进而降低了特征的表达能力。因此,将输入特征矩阵进行一个组卷积得到对应特征矩阵之后进一步划分,再将划分好的每一个对应组放在一起,就得到一个经过通道混洗(channel shuffle, CS)之后的特征矩阵,这样就实现了特征图之间的通道信息融合[8],如图2所示。

图2 分组卷积与通道混洗Fig.2 Group convolution and channel shuffling
1.3 Gelu激活函数
激活函数是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。
高斯误差线性单元(Gaussian error linear units, Gelu)[9]加入了随机正则的思想,综合了Dropout和Relu的特色,是一种高性能的神经网络激活函数,实验效果好于Relu函数,对比情况如图3所示。Gelu激活函数加入了高斯正态分布的累积函数,提升了模型对独立随机变量的拟合能力,其近似计算的数学公式为

图3 Gelu和Relu函数对比Fig.3 Comparison of Gelu and Relu functions


(4)
1.4 组归一化
组归一化(group normalization, GN)[10]是针对批归一化(batch normalization, BN)在batch size较小时错误率较高而提出的改进算法,其工作原理是将通道分成若干组,并在每组内计算均值和方差进行归一化,即对每组内的特征进行归一化。GN的归一化方式避开了batch size对模型的影响,算的是channel方向每个group的均值和方差,和batch size没关系,不受batch size大小的约束,而且在很大的batch size范围内其精度也很稳定。
1.5 ShuffleNet V2单元
ShuffleNet V2[11]网络主要由两种基本单元堆叠而成,如图4所示,ShuffleNet V2单元1中,输入的特征按照通道数一分为二,进入2个不同的分支,左边分支不做任何操作,右侧分支进行了1次3×3的深度卷积操作和2次1×1的卷积操作,然后与左侧通道级联在一起进行CS操作。单元2中,取消了通道分开的操作,左侧分支进行了1次3×3的深度卷积操作和1次1×1的卷积操作,右侧分支进行了1次3×3的深度卷积操作和2次1×1的卷积操作,然后与左侧通道级联在一起进行CS操作。在两个基本单元中,卷积操作之后均采用了批归一化来加快网络收敛,在1×1卷积之后还采用Relu激活函数增加模型的非线性特征。

图4 ShuffleNet V2基本单元Fig.4 ShuffleNet V2 basic unit
1.6 ECA
在神经网络中,注意力机制能够从大量的信息中筛选出重要的信息,在提高深度卷积神经网络性能方面具有巨大潜力。现有方法大多致力于开发更复杂的注意力模块以获得更好的性能,而增加了模型的复杂性。高效通道注意力(efficient channel attention, ECA)模块可以克服性能和复杂性之间的矛盾,该模块只增加了少量的参数,却能获得明显的性能增益[12],如图5所示。在ECA模型中首先输入维度是H×W×C的特征图,然后使用全局平均池化GAP,得到1×1×C的特征图,再通过1×1卷积,进行通道特征学习,最后将通道维度1×1×C的特征图和原始输入维度为H×W×C的特征图进行逐通道相乘,得到具有通道注意力的特征图。

图5 ECA结构Fig.5 ECA structure
2 Shuffle-ECANet网络模型
2.1 ShuffleNet V2单元的改进
本文中对ShuffleNet V2单元进行了改进,如图6所示。改进的单元将BN换成了GN,GN解决了BN在batch size较小时错误率较高的问题,不受batch size大小的约束;将Relu换成了Gelu,Gelu解决了Relu在零点不可微的问题,加入了随机正则思想,提升了网络性能;其中改进单元1,在CS操作以后添加了ECA注意力机制,在保证网络轻量化的同时,进一步提升了网络性能。
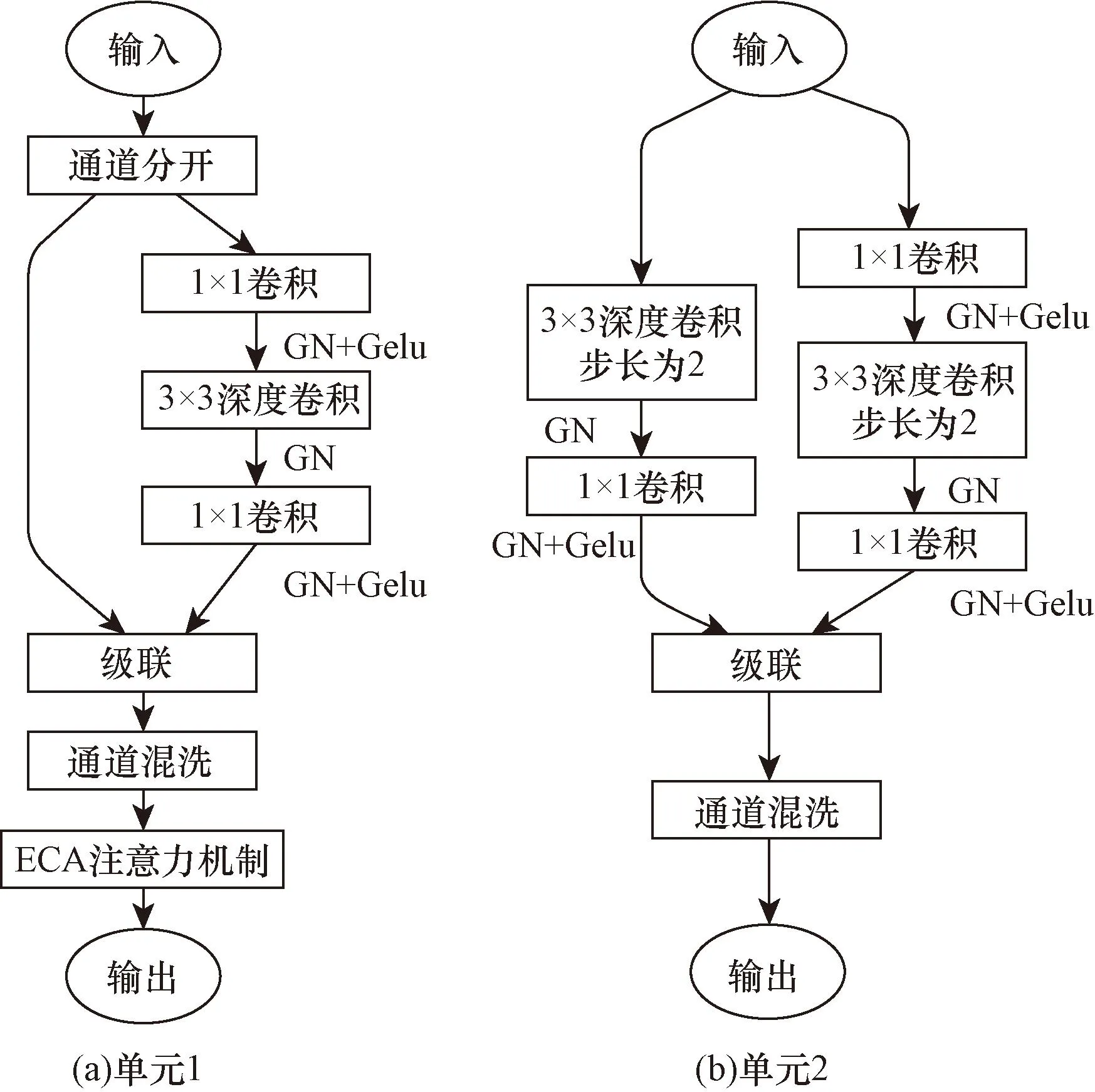
图6 改进ShuffleNet V2基本单元Fig.6 Improved ShuffleNet V2 basic unit
2.2 Shuffle-ECANet网络模型
本文提出的Shuffle-ECANet网络模型如图7所示,由于所分析数据是一维的,无法与本文提出的二维网络模型兼容,因此需要将一维数据转化为二维数据后再输入网络[13]。首先,网络首层采用一个通道为64,卷积核大小为3×3的卷积神经网络,接着进行最大池化操作,然后把改进单元1和改进单元2首尾相连堆叠3次,再对每个通道的输出特征进行全局平均池化,添加Dropout层减小过拟合的影响,最后,使用全连接层并进行Softmax分类输出,网络结构参数如表1所示。本网络参数量个数为30 001,与其他网络参数量对比如表2所示,可以看出本文所提模型参数远远小于其他神经网络,更加轻量化。

表1 网络结构参数Table 1 Network structure parameters

表2 不同网络参数量对比Table 2 Comparison of different network parameters
3 实验结果及分析
3.1 实验介绍
本次实验采用动力传动故障诊断综合实验台(drivetrain dynamics simulator, DDS)如图8所示,该实验台由驱动电机、齿轮箱、磁励制动器等组成。数据采集系统包括加速度传感器,采集仪以及驱动软件等,采样频率为12.8 kHz。

图8 DDS试验台Fig.8 DDS test bench
本实验采用基于python语言的Tensorflow+Keras框架搭建虚拟环境。计算机配置为:英特尔酷睿i7-11800H处理器,英伟达GeForce RTX 3060显卡,16 GB内存。
3.2 实验结果
数据集共有各类故障数据8类,具体内容如表3所示。每个数据类别取1 000个样本,其中训练集占70%,测试集占30%。使用Adam优化算法,网络模型训练参数如下:学习率为0.001,批处理量为128,迭代次数为50。

表3 数据集Table 3 Datasets
网络模型训练和测试分类准确率和损失值如图9和图10所示,在迭代10次后准确率达到了99.6%,损失值趋于0,并且能够保持稳定。结果说明,本文所提网络模型可以准确识别齿轮箱的不同故障。采用T-SNE算法对模型的分类过程进行特征可视化,未训练及已训练的特征可视化如图11所示。从图11中可以看出原始数据集处于混乱状态,故障类别难以区分,经过本文所提网络分类后,故障类别清晰明了。将测试集数据输入模型进行分类,得到的混淆矩阵如图12所示,测试集的故障分类准确率达99%以上。

图9 分类准确率Fig.9 Classification accuracy

图10 分类损失值Fig.10 Classification loss value

图11 训练前后的特征可视化Fig.11 Feature visualization before and after training
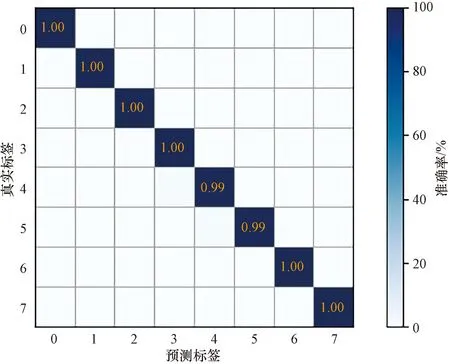
图12 混淆矩阵Fig.12 Confusion matrix
3.3 分析讨论
为验证模型在不同噪声工况下的表现,在原始信号的基础上添加了不同信噪比(signal noise ratio, SNR)的高斯白噪声,其中SNR分别为-2、-5、-8 dB。以下实验均在原信号以及添加了高斯白噪声的信号下进行。
本文所提网络模型对改进单元1、改进单元2首尾相连堆叠3次,为验证改进单元堆叠次数N的最佳选择,对N设置1、2、4进行对比实验验证。图13为不同堆叠次数模型在各信号下的准确率。

图13 不同堆叠次数模型准确率Fig.13 Accuracy of models with different stacking times
由图13可知,改进单元1和改进单元2堆叠1次和2次时,模型的准确率在4种信号下均不如堆叠3次高,堆叠4次的准确率也低于或接近堆叠3次,因此本网络模型中改进单元1和改进单元2堆叠3次为最佳选择。
为检验各个改进单元的性能,进行消融实验。在本文所提模型中其他条件不变,设置去除改进单元1的“模型1”,去除改进单元2的“模型2”,以及仅去除改进单元1中ECA模块的“模型3”进行实验,各模型准确率如图14所示。

图14 不同结构模型的准确率Fig.14 Accuracy of different structural models
由图14可知,改进单元1、改进单元2以及ECA模块均对网络模型有影响,其中改进单元1对网络模型影响最大。
综上所述,无论在原信号还是在添加了高斯白噪声的信号下,本文所提的网络模型诊断效果均好于其他对比模型,在SNR为-8 dB的环境中依然可以保持92.7%的诊断准确率,有良好的实用价值。
4 结论
基于轻量化神经网络ShuffleNet V2进行改进,结合ECA注意力机制,提出Shuffle-ECANet网络模型用于齿轮箱故障诊断,经过实验分析得到如下结论。
(1)本文所提网络模型诊断准确率高,在不同噪声工况下仍能保持较高的诊断准确率,证明了该方法的可行性,可有效用于齿轮箱的故障诊断。
(2)实验分析表明,本文所提网络模型诊断效果好于其他对比模型,具有一定的优势。
(3)与传统神经网络相比参数量小,更加轻量化,降低了对计算机硬件的要求,为神经网络走向实际工程提供了一条可行性途径。
在未来的研究中,会进一步优化和改进该网络模型以得到更高的准确率并满足不同的工作需求。
猜你喜欢
山东冶金(2022年3期)2022-07-19
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
制造技术与机床(2017年4期)2017-06-22
风能(2016年12期)2016-02-25
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
振动、测试与诊断(2014年5期)2014-03-01
振动、测试与诊断(2014年4期)2014-03-01
