
基于SSA-GRU大功率多状态PEMFC寿命预测
2024-04-01 07:30张宸铭张达
科学技术与工程 2024年7期
张宸铭, 张达
(青岛科技大学自动化与电子工程学院, 青岛 266061)
近些年来,随着全球温度上升,环境保护日益受到重视,清洁能源成为各国大力开拓的新赛道。氢燃料电池在电能获取以及处理回收的过程中不会产生污染环境的风险,作为清洁能源,伴随诸多的政策支持,氢燃料电池迎来了巨大的发展空间[1]。由于是通过氢气与氧气在质子交换膜催化作用下进行化学反应产生电能的发电装置,所以也称为质子交换膜燃料电池[2](proton exchange membrane fuel cell, PEMFC)。剩余使用寿命(remaining useful life, RUL)的研究是当下PEMFC领域的热点[3],在实际使用中PEMFC存在寿命短、易故障等缺点,因此RUL的研究十分重要,通过RUL准确预测从而保证电池长期处于稳定运行的状态,并在需要更换时能够及时发出通知,以确保工作机能够持续高效运行,使电池安全工作的同时进一步延长使用寿命。
基于数据驱动的方法在对锂电池的寿命预测已有广泛运用[4-5]。目前广大学者对于PEMFC寿命预测主要分为两大类,分别为基于模型的方法和基于数据驱动的方法。基于模型的方法是根据电池材料性能,内部结构和负载情况等因素建立电池衰减模型从而预测,但PEMFC内部结构复杂,想要对整个电池进行物理建模仿真需解决诸多困难,当前基于模型的预测方法大多是将其中一个或是几个对PEMFC寿命影响比较大的器件建模来预测整个电池的寿命[6];因此基于数据的方法被广大学者运用,此方法不依赖于电池的内部模型,着重研究电池各项历史数据的变化情况,分析其隐性联系,建立关系来预测,例如文献[7]运用关联向量机(relevance vector machine, RVM),文献[8]运用自适应神经模糊推理系统(adaptive-network-based fuzzy inference system, ANFIS),文献[9]运用求和小波极限学习机(summation wavelet-extreme learning machine, SWELM),文献[10-11]利用长短时记忆循环神经网络(long short term memory, LSTM)等都是基于数据驱动的预测方法。
现对采集到的数据利用绝对中位差(median absolute deviation, MAD)去除异常值,并使用Savitzky-Golay(SG)滤波器进行平滑处理,减小预测结果的误差;使用麻雀搜索算法(sparrow search algorithm, SSA)对门控循环单元预测算法(gated recurrent unit,GRU)的参数进行优化处理,提高预测准确性;对不同功率点的数据分类预测,获取更早的寿命预测截止时间,确保电堆始终处于稳定运行的状态。
1 实验数据采集
1.1 实验工况设计
以110 kW车用PEMFC电堆为研究对象,开展多工况耐久试验并预测其RUL。在实际氢燃料电池汽车运行过程中,电堆输出功率会随着动力需求不同而改变,并不维持一个输出功率点。在不同额定功率点下工作,其输出电压值会有明显差别,因此无法使用传统方法简单对电压进行时序分析来预测PEMFC的RUL。本文便在不同功率工作下,对电压输出值进行分析预测,分别推算出此功率工作状态下PEMFC使用寿命的截止点。
本次耐久试验的工况运行遵循国标GB/T 38914—2020,PEMFC部分负载功率和对应电流的对应关系如图1所示,2 h为一个工况循环。耐久实验运行时长超过600 h,但在热机过程中或停机时间过长再次启动时便会发生电池反应温度没有达到标准温度的情况。PEMFC运行温度对其工作效率有着显著影响,当温度过低时,氢气经过质子交换膜后无法与空气中氧气充分反应,导致PEMFC欧姆阻抗增大,电堆整体性能变差[12],单片PEMFC电压方程为

图1 循环工况功率、电流时序图Fig.1 Cycle working condition power and current timing diagram
V=E-Vohm-Vact-Vtrans
(1)
式(1)中:E为开路电压;Vohm为欧姆损失;Vact为极化损失;Vtrans为浓度差损失。
整个电堆由多片单电池组合而成,当单片电压过低并持续时间过长会对电堆造成不可逆的损害[13],因此通过单体最低电压与平均单体电压的差值能够判断电堆是否在安全健康的工作状态下运行。
1.2 健康因子选取
平均单体电压与常用的衰退指标,整堆输出电压相比较,两者极化曲线极为相似,由此推断单电池电压、温度曲线能够扩展至整个电堆[14]。且整堆输出电压的测量精度没有达到单电池测量的毫伏级,所以本实验将平均单体电压作为预测RUL的衰退指标。在耐久实验的同时每隔150 h进行了极化测试,电堆极化关系如图2所示。
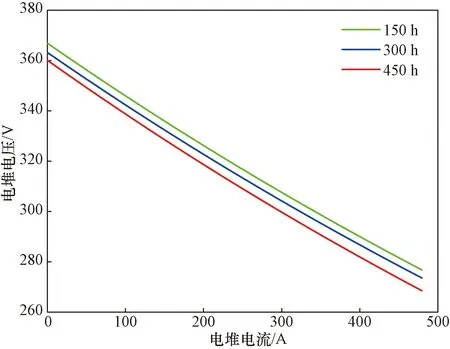
图2 电堆极化曲线Fig.2 Stack polarization curve
实验中电堆内部各项传感器采样频率为2 Hz,为便于初步观测,对导出数据每间隔240位采样,即每个采样数据间隔2 h。并对上述提到工作水温没有到达额定温度、单体最低电压与平均单体电压的差值过大的数据点进行剔除,以确保分析的数据属于电堆稳定运行的工作状态,采样得到指定功率下持续运行的工作时长与平均单体电压关系如图3所示。

图3 各负载功率下持续运行的平均单体电压时序图Fig.3 Time series diagram of average unit voltage for continuous operation under various load powers
电池的衰退可以分为可逆与不可逆,停机时自我修复形成的尖峰与水淹、膜干等故障造成的低谷反映了实际工作情形,在即时处理后便可恢复正常工作电压。单电池巡检的主流测量方法为两片一检,本次实验也是如此,下文与图3中平均单体电压都为两片单电池的电压值。
2 数据处理及预测网络
2.1 MAD异常值剔除
在统计学中,绝对中位差(median absolute deviation, MAD)是对单变量数据样本偏差的鲁棒性测试,用来描述样本在定量数据中可变的标准,公式为
MAD=median|xi-median(xi)|
(2)
式(2)中:xi为样本中各数据。
确定窗口大小获取数据集,即在给定的数据集中,计算出中位数,再把原始数据减去原始数据取绝对值得到新的数组,在此数组中取中位数得到MAD。将样本中各数据与中位数比较,差值超过了MAD的一定倍数将被剔除,并用前一位数据值代替,异常值剔除后的电压衰退趋势如图4所示。

图4 MAD异常值剔除后电压衰退趋势图Fig.4 Voltage decline trend diagram after MAD outlier elimination
2.2 Savitzky-Golay滤波
SG滤波器是由一种在时域内基于窗口中数据,利用k-1次多项式最小二乘法的拟合滤波方法,其特点是在滤除噪声的同时确保信号的形状与宽度不会变化,窗口宽度为2m+1,计算公式为
y=a0+a1x+a2x2+…+ak-1xk-1+b
(3)
式(3)中:x为待拟合的数据;y为拟合后输出数据;a为待求解参数;b为误差量。
矩阵表示形式为
Y(2m+1)×1=X(2m+1)×kAk×1+B(2m+1)×1
(4)
A的最小二乘解为
(5)
Y的滤波结果为
(6)
式中:X、Y、A、B分别为x、y、a、b的向量形式,下标为矩阵大小。经过SG滤波后的电压衰退趋势如图5所示。

图5 经SG滤波电压衰退趋势图Fig.5 SG filtered voltage decay trend chart
2.3 GRU神经网络
GRU是基于循环神经网络的一种,与常见的LSTM相比,减少至只有更新门与重置门,促使整个算法运行结构更为简洁且性能增强,适用于大规模数据集的预测,GRU内部结构如图6所示。
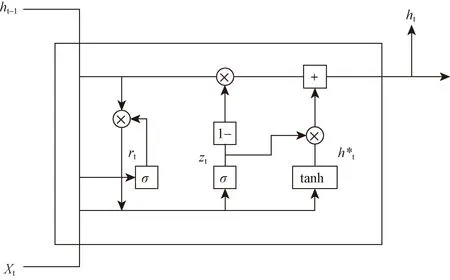
xt为当前输入,ht-1上一个节点传递的隐状态,ht为传递至下一节点的隐状态,为隐藏的当前状态,zt为更新门,rt为重置门,σ为Sigmoid函数,×表示矩阵相乘,+表示矩阵相加,tanh为激活函数图6 GRU内部结构Fig.6 Internal structure of GRU
GRU工作原理如下。
(1)更新门:决定上个隐藏状态有多少信息需要被保留,且有多少新内容被加入,表达式为
zt=σ(Wzxt+Uzht-1)
(7)
(2)重置门:决定上个隐藏状态有多少信息需要被遗忘,表达式为
rt=σ(Wrxt+Urht-1)
(8)
(3)确定当前记忆内容,表达式为
(9)
(4)确定隐藏层需要更新的内容,表达式为
(10)
式中:W、U为权值矩阵;z为更新门;r为重置门;x为输入;h为隐藏层状态;t为时刻;σ为Sigmoid函数;⊙为Hadamard积。
2.4 麻雀搜索算法
为了使预测结果更为准确,采用麻雀搜索算法优化GRU中学习率与正则化系数这两个参数,使适应函数即训练集和测试集的输出均方误差(mean squared error, MSE)最小,公式为
(11)
fitness=MSE(A)+MSE(B)
(12)
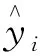
SSA是受麻雀的觅食和反猎捕启发提出的一种优化算法,具有多样性和全局搜索能力,并能自适应调整参数的优点。根据储备能量分为生产者与乞讨者,生产者要找到食物丰富的地方带领乞讨者前往,也要根据危险警报引领乞讨者前往安全地带,其中生产者和乞讨者身份可以相互转换,但总比例不变。建立数学模型为
(13)
式(13)中:n为麻雀个数;d为需要优化的变量数。适应度值越大,发现食物能力越强,其公式为
(14)
生成者更新位置表达式为
(15)
式(15)中:t为当前迭代次数;i为第i个麻雀,j=1,2,…,d;Xi,j为1×d的矩阵;Nmax为最大迭代次数;a为随机数;R为警报值;ST为安全阈值;Q为满足正态分布的随机数;L为元素全为1的1×d矩阵。
乞讨者更新位置表达式为
(16)
式(16)中:Xp为1×d的矩阵表示生产者占据的最优位置;xworst为1×d的矩阵表示当前最差位置;A为1×d的矩阵且元素只有1和-1。
将GRU中隐含层层数、神经元个数、初始学习率、正则化系数设置为需优化的超参数组合,将其通过SSA优化获取最优输出。目标函数为均方误差,即当训练输出数据与输入数据的均方误差最小时,将得到最优超参数组合,将其设置为GRU测试部分的参数,输出得到预测的平均单体电压。经过调试,效果最优时其中部分参数设置如表1所示,SSA-GRU模型流程如图7所示。

表1 SSA-GRU模型部分参数Table 1 Partial parameters of SSA-GRU model

图7 SSA-GRU模型流程图Fig.7 SSA-GRU model flowchart
在不同功率下工作的数据以及训练集,需要不同的超参数设置,而SSA-GRU预测模型的运用能够有效解决这一问题。
3 实验数据分析
3.1 评价指标选取
PEMFC平均寿命达到上千小时,且平均单体电压在短时间内也不会有明显变化,为进一步简化数据,将采样间隔为两分钟的数据每隔10位再次进行筛选得到在当前设定功率下稳定工作每隔1/3 h的平均单体电压。分别将不同输出功率下的输出电压数据前50%、60%、70%、80%作为训练集观测其训练结果与真实输出的误差值来判断模型的可靠性。使用4个不同比例的数据作为训练集,可证明对各时间段输出电压进行有效预测。本实验选取均方根误差(root mean square error, RMSE),平均绝对误差(mean absolute error, MAE)以及平均相对误差(mean absolute percentage error, MAPE)作为评价指标,其公式为
(17)
(18)
(19)
3.2 多工况分析
SSA-GRU预测模型的输入为实测平均单体电压,经算法叠加,输出为预测的时序平均单体电压。在设定负载功率为30、50、70、90、110 kW工况下运行,其输出图像如图8所示,各评价指标的值如表2所示。

表2 各工况不同训练集预测结果评价指标对比Table 2 Comparison of evaluation indicators for prediction results of different training sets under different operating conditions

图8 各工况不同训练集预测输出对比Fig.8 Comparison of prediction outputs for different training sets under different operating conditions
其中在70 kW功率点以80%作为训练集的预测准确度最高;在30 kW功率点以60%作为训练集预测准确度最差。由表2各评价指标的数值得出,SSA-GRU预测模型对短期预测都有较高的精度,相较于使用60%与70%数据集的预测结果,使用50%数据集的长期预测总体准确度更高。60%数据集的预测结果在各评价指标的对比中,误差较大的个数最多,因此之后本模型使用时尽量避免以60%数据集的预测,以确保预测的准确性。
3.3 算法对比
GRU因为减去了神经网络中一个门的运算步骤,相较于LSTM运行时间更加短,同时也不可避免地导致预测精度略有下降,而SSA-GRU模型通过优化算法,提高了准确性,对于单体平均电压都有更好的预测效果。为进一步证实预测的准确性,使用上文中判断出预测效果相对较差的训练集分类,即将每个功率点总数据的60%作为训练集,利用时间卷积网络(temporal convolutional network, TCN), 卷积神经网络(convolutional neural network, CNN)和LSTM 3个预测算法进行比较,测试集输出结果如图9所示,并将MAPE作为输出结果的预测评价指标,其对比数据如表3所示,与其他算法对比可知SSA-GRU预测结果MAPE降低最少为30 kW,差值为0.103 7%,降低最多为110 kW功率点,差值为0.947 5%。

表3 各负载输出功率下以60%为训练集的不同算法预测MAPETable 3 Predicting MAPE using different algorithms with 60% training set under different load output power

图9 各负载输出功率下以60%为训练集的不同算法测试集输出结果Fig.9 Output results of different algorithm test sets with 60% training set under each load output power
根据美国能源部要求,运行过程中性能衰退至10%即为PEMFC寿命截止点,由于本实验电堆在之前有进行过其他实验,判断运行电压为初始最高电压的95%为寿命截止点。寿命截止的电压点在图9中已标出,RUL的预测误差计算公式为
(20)
各算法在各个功率点RUL的预测误差值如表4所示,SSA-GRU在各功率点的预测误差都小于CNN,TCN以及LSTM算法的预测结果。

表4 不同算法各功率点RUL预测误差值Table 4 RUL prediction error values for different power points using different algorithms
4 结论
从110 kW PEMFC电堆耐久试验数据可以看出,在给定电流越大即设置的输出功率越大,电堆输出电压会有所降低,但在相同输出功率下,输出电压会随着循环工况的不断进行,持续降低,也会因为停机休息再启动时略有回升。从分析的数据中得出以下结论,当训练集的量越大时,预测结果的各项评价指标更优,对于短期的预测结果最为准确。但PEMFC工作时,如遭遇停机、膜干、水淹等情况使电压发生突变,而突变的电压值作为训练集输入,会导致预测输出的结果精度降低。以60%的数据作为训练集利用SSA-GRU进行预测,各功率状态下预测剩余使用寿命的预测误差都在9%以内,并与其他预测算法对比后,得出SSA-GRU预测模型在各功率状态下都能输出更为精确的预测结果这一结论。证明此算法模型能有效解决大功率PEMFC在复杂工况下对RUL的预测,且此方法具有普适性,在不同工作状态下稳定运行的RUL类时序处理上都可以运用。在行车过程中进行寿命预测,是下一步待实现的目标。
猜你喜欢
今日农业(2022年14期)2022-09-15
军事文摘(2022年14期)2022-08-26
科学大众(2021年21期)2022-01-18
小学科学(学生版)(2021年12期)2021-12-31
中国军转民(2017年7期)2017-12-19
大连工业大学学报(2015年4期)2015-12-11
电源技术(2015年5期)2015-08-22
电源技术(2015年7期)2015-08-22
中国卫生(2014年10期)2014-11-12
电源技术(2014年5期)2014-07-07
