
基于多模态共享网络的自监督语音-人脸跨模态关联学习方法
2024-04-01 07:30李俊屿卜凡亮谭林周禹辰毛璟仪
科学技术与工程 2024年7期
李俊屿, 卜凡亮*, 谭林, 周禹辰, 毛璟仪
(1.中国人民公安大学信息网络安全学院, 北京 100038; 2.公安部第一研究所, 北京 100048)
随着信息技术的飞速发展和人类对全方位感知的需求不断增加,多模态数据处理[1-5]已经成为了人工智能和计算机视觉领域的研究热点。在多模态数据的广泛应用领域中,音频和图像作为人类最常用的两种信号传输模式,承载着丰富的信息。图像可以直观地传达其中包含的颜色、形状和纹理等信息,而音频则包含了丰富的音调、音色和振幅等特征,能够间接地反映人的性别、年龄和情绪状态。语音和人脸作为广泛应用的两种模态,吸引了越来越多的学者来探索两者之间的潜在关联。认知科学的研究证明,语音和人脸的神经认知通路具有相似的结构[6],这使得人类能够将个体的语音和与之对应的人脸相联系起来[7]。此外,生物学和统计学的研究也发现个体的年龄、性别、种族以及面部骨骼结构等特征在语音和人脸中都能够得到反映[8]。因此,基于语音和人脸的跨模态交互关联具有一定的可行性。
语音-人脸跨模态关联学习作为新兴的研究领域,主要通过人工智能和计算机视觉的相关技术,挖掘语音与人脸模态间的潜在联系,实现跨模态验证、匹配和检索等关联学习任务。通过对语音与人脸之间的语义关联进行深入探索,为语音生成人脸[9-10]、深度伪造视频检测[11]、说话人跟踪[12]等领域的研究提供了有力支持,在公共安全领域更是具有广泛的应用前景。例如,在电信诈骗、绑架勒索和经济纠纷等涉及语音证据的案件中,警方可以通过采集到的语音数据与人脸数据库进行匹配,有助于预防和打击犯罪活动,避免进一步的人身安全和财产损失。在公共场所或事故灾难现场,搜寻人员可以利用收集到的语音或人脸图像,通过现场监控或录像进行检索,以寻找失踪人口。在身份验证、门禁控制和智能家居领域,用户还可以通过语音与人脸的匹配来获得受限区域的访问权限,提高系统的整体安全性。语音-人脸跨模态关联方法在公共安全领域的应用也存在一定限制,录音设备在不同场所下使用的局限性对语音数据的收集产生了一定的影响。
近年来,人们在语音-人脸跨模态关联学习上的研究可以分为基于分类的方法和基于度量学习的方法。基于分类的方法是把语音-人脸跨模态关联学习看作一个分类任务来处理。Nagrani等[13]是最早对语音与人脸进行跨模态生物特征匹配的研究者,提出了一种多分支卷积神经网络结构,可以分别读取语音频谱图和人脸图像,并对两者进行强制匹配,该模型在数据集上的表现超过了人类。Wen等[14]提出了一个不相交映射网络(disjoint mapping network, DIMNet),该模型从性别、种族、ID等公共变量中获取监督信号来学习语音和人脸的共同嵌入,通过多个不同的公共变量提供的多种标签信息来评估最终嵌入的匹配性能。基于度量学习的方法旨在通过学习一个度量损失函数,使得在公共特征空间中相似的语音与人脸特征向量距离更近,不相似的语音与人脸特征向量距离更远。Nagrani等[12]提出了一种基于Curriculum的无监督策略来构造困难负样本,该模型学习到的表征不再局限于强制匹配,而是引入了跨模态验证和检索任务,通过对比损失来约束语音与人脸特征向量的距离。Kim等[15]利用三元组损失来学习语音和人脸的特征嵌入,论证了该模型所学习到的特征向量包含了个体的性别、年龄、种族、是否是大鼻子、是否是双下巴等特征。Horiguchi等[16]采用双流网络的架构来提取语音和人脸的特征向量,通过N-pair损失对两个模态特征的距离度量进行优化。Nawaz等[17]提出了一个单流网络(single stream network, SSNet)和一种新的损失函数中心损失来学习弥合两种模态间的距离。Wang等[18]提出了一种双向五元组约束,可以更好地学习语音与人脸的联合嵌入,拉近属于同一身份的语音和人脸特征。
近期,随着数据集规模的不断扩大,标注大量数据所需的人力和时间成本急剧增加,这给有监督的跨模态关联学习方法带来了巨大的挑战。因此,研究无监督的跨模态关联学习方法具有重要意义。Chen等[19]提出了一种无监督学习模型(self-lifting, SL),结合聚类和度量学习来探索无监督的语音与人脸之间的特征关联。Zhu等[20]提出了一种跨模态原型对比学习模型(cross-modal prototype contrastive learning, CMPC),采用对比学习的方法实现了无监督的语音与人脸模态的关联学习,并利用噪声对比估计损失(info noise contrastive loss, InfoNCE loss)实现了跨模态验证、匹配和检索的关联学习任务。朱明航等[21]提出了一种基于双向伪标签的自监督学习方法,将一种模态下生成的伪标签作为唯一的监督信号去监督另一种模态的特征学习,实现了双向伪标签关联,促进了语音与人脸的跨模态相关性学习。
上述工作并未有效地解决不同模态特征之间的异构性,对语音和人脸高层语义一致特征的挖掘还不够充分。此外,大多数方法仍依赖于标记数据进行训练,这导致了时间和人力成本耗费大,实际应用价值低。
为了解决上述工作存在的问题,提出一种基于多模态共享网络的自监督语音-人脸关联学习方法。其主要工作如下:首先,通过多模态共享网络的共享全连接层、非线性激活函数以及残差连接,模型能够更好地挖掘到语音与人脸之间的关联性,使得它们在公共空间中的嵌入特征更具有语义一致性。然后,引入自监督学习,为度量学习提供监督信息,降低无标签数据的标注成本,提高模型的泛化能力。最后,将多相似性损失函数和均方误差损失函数相结合,对特征向量进行距离度量,从而实现在四种语音-人脸跨模态关联学习任务上的全面评估和测试。这种方法可以增加多模态数据在特征空间中的关联性,为实现更好的语音-人脸跨模态关联学习提供有力支持。
1 自监督语音-人脸跨模态关联学习方法
本文所提出的自监督语音-人脸跨模态关联学习方法的总体框架如图1所示,其中包含两个主要的网络模块,即多模态共享模块和自监督学习模块。首先,模型采用双流网络的架构,包括语音流和人脸图像流两个权重独立的编码器。接着,提取到的语音和人脸嵌入向量通过多模态共享模块,在公共特征空间中增强了不同模态之间的语义关联。然后,自监督学习模块将特征向量聚类成簇得到伪标签。最后,利用生成的伪标签作为监督信息,指导了对特征向量进行度量学习的过程,提高了模型的表征学习能力。

图1 语音-人脸跨模态关联学习方法的总体框架Fig.1 Overall framework of the proposed voice-face cross-modal association learning method
1.1 基本定义

1.2 多模态共享模块
采用双流网络的架构,用独立的两条语音流和人脸图像流网络提取各自模态特有的特征,以充分学习语音与人脸特征之间的异构性。然而,现有的语音-人脸关联学习方法往往通过在双流网络的顶端引入权重共享的单一全连接层来构建公共特征空间,该全连接层限制了不同模态特征的公共表示能力,无法充分地挖掘语音和人脸特征之间的语义一致性。
为此,设计了一个多模态共享模块来增强语音与人脸数据在跨模态公共特征空间上的语义关联。本文所提出的方法是受残差网络(ResNet)[22]的启发,ResNet是一种深度神经网络架构,通过引入残差连接,将输入直接加到输出上,解决了训练过程中的梯度消失和表达能力受限的问题。多模态共享模块的网络结构由一个改进的残差块和一层共享全连接组成。改进的残差块包含三个权重共享的全连接层,每个全连接层之后加入批归一化层和ELU激活函数,最后通过跳跃连接将残差块的输出与输入进行元素级相加。该网络充分考虑了残差块在提取稀有特征方面的关键作用,通过保留原始特征并建立非线性相关性,能够在特征提取过程中更好地关联两种模态的信息,实现更强的特征表示能力。
在深度学习中,模型的输入和矩阵的运算都是线性的,然而实际情况中输入数据和输出数据的关系通常是非线性的。为了更好地适应和拟合这种非线性关系,对于具有多个隐藏层的神经网络,使用非线性激活函数来提高神经网络的性能,充分利用其多层非线性变换的能力,使其能够更好地挖掘和表示复杂的非线性数据关系。
在设计多模态共享模块时,对ResNet原残差块的激活函数进行了优化改进,用ELU激活函数替换了其中的ReLU激活函数。ELU激活函数具备更好地处理和表示负数输入的能力,对噪声和异常值具有一定的鲁棒性,有助于残差块更好地学习和拟合复杂的数据。
ReLU激活函数的表达式为
(1)
ReLU激活函数的导数为
(2)
式中:x为输入特征。由式(1)、式(2)可得出,当输入特征为正值和0时,输出等于输入,梯度为1,不存在梯度消失问题;当输入特征为负值时,输出和梯度都为0,ReLU硬饱和。
ELU激活函数的表达式为
(3)
ELU激活函数的导数为
(4)
式中:x为输入特征;α为超参数,取值通常为1。由式(3)、式(4)可得出,当输入特征为正值时,输出等于输入,梯度为1,不存在梯度消失问题;当输入特征为0时,ELU函数的输出也为0,并且梯度为1。与ReLU函数不同的是,ELU在输入为0时的梯度不为0,这是ELU相比于ReLU函数的一个优势;当输入特征为负值时,ELU函数的输出为指数增长的负值,无限趋近于-α,梯度为ex,接近于0但不为0,不存在硬饱和问题。


图2 多模态共享模块的网络结构图Fig.2 Structure of multi-modal shared module
(5)


(6)
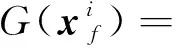
(7)
最后,将残差块的输出向量经全连接层映射到嵌入空间,得到最终的128维输出可分别表示为
(8)
(9)
式中:wi为全连接层的权重;bi为对应的偏置;γ为激活函数ELU;输入与输出向量的维度均为256。
1.3 自监督学习模块
自监督学习是一种特殊的无监督学习方法,它通过设计预测任务来生成伪标签,并将这些伪标签作为监督信号来训练模型。现有的大多数语音-人脸跨模态关联学习方法[13-18]都是采用有监督的方式,难以有效地建立语音与人脸在潜在语义上的关联。本文在自监督学习框架SL的基础上进行改进,能够从语音和人脸数据中学习到有意义的特征表示,实现跨模态的自监督学习,从而充分挖掘语音与人脸之间的结构和语义关联。
特征向量级联是将两个或多个特征向量按照一定顺序拼接在一起形成一个更长的向量,有助于模型捕捉到更多的语义信息。当其中一种模态数据的质量较低时,例如,语音数据有环境噪声干扰或图像数据有极端光照条件照射等情况,可以利用另一种模态的数据来获取补充信息,从而提高聚类算法对复杂场景和低质量数据的鲁棒性和精度。如图3所示,将语音和人脸的高层语义特征向量进行级联,将生成的视频特征向量ei作为自监督学习模块的输入。公式为

图3 特征向量级联图Fig.3 Feature vector concatenation diagram

(10)
式(10)中:⊕为向量的级联。
给定一组输入数据E={e1,e2,…,eN},其中ei表示第i个样本,N表示样本数量。通过K均值聚类算法(K-means)[23]将这些样本点划分为k个簇,迭代优化直至聚类中心不再发生变化或达到预定的迭代次数,实现聚簇内的样本点相似度最大,聚簇间的样本点相似度最小。
如图4所示,首先,随机初始化k个聚类中心向量Μ={μ1,μ2,…,μk},计算每个样本点ei与每个聚类中心点μj之间的距离;其次,将ei划分到距离最近的聚类中心点μj所属的聚类Cj中,并更新聚类中心点的向量μj,将其设为聚类Cj中所有样本点的均值;最后,迭代直至收敛,得到每个样本点所属的聚类伪标签Y={y1,y2,…,yk},其中yi为第i个簇中视频特征向量的伪标签。

图4 自监督学习框图Fig.4 Block diagram of self-supervised learning
欧式距离计算公式为
(11)
K-means聚类的目标函数的公式为
(12)
中心向量矩阵的计算公式为
(13)
式(13)中:|Cj|为聚类Cj中样本点的数量。
1.4 度量学习
度量学习是表征学习的一种方法,旨在学习一个合适的相似度度量,以在特征空间中衡量样本对的距离。度量学习需要标签作为引导来定义样本之间的相似性,对于无标签数据,可以将自监督学习生成的伪标签作为监督信号进行训练,学习伪标签的语义关系,从而提高模型的表征学习能力。本文中采用多相似性损失函数[24]衡量语音和人脸特征向量之间的相似度。

(14)
式(14)中:‖zi‖和‖zj‖分别为向量zi和zj的L2范数。
首先,如果{zi,zj}是负样本对,则条件为

(15)
如果{zi,zj}是正样本对,则条件为

(16)
其次,将通过以上方式挖掘到的正样本集和负样本集分别表示为Pi和Ni。
最后,利用多相似性损失函数来实现度量学习的过程。公式为

(17)
式(17)中:α、β、λ为超参数。通过梯度下降法对式(17)进行优化。
1.5 模型训练
模型的总体迭代策略是通过自监督学习模块生成伪标签引导度量学习,度量学习再使用伪标签计算损失函数,通过反向传播计算梯度并更新模型参数,以使模型逐步优化,学习到的语音和人脸的特征表示能够更好地满足度量学习的目标。
本文提出方法的整体损失函数形式为
L=LMS+ηLmse
(18)
式(18)中:Lmse为均方误差损失函数(MSE Loss),用于计算语音与人脸嵌入向量之间的差异。权重系数η设置为0.5。
MSE Loss的公式为
(19)
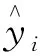
将每批次训练的样本数设置为256,并选择Adam[25]方法作为优化模型。训练学习率设置为10-3,迭代次数设置为250。设置为0.1,α设置为2,β设置为50,λ设置为1,K-means算法中簇数k设置为1 000。
2 实验结果与分析
本文在Voxceleb1[26]数据集上验证自监督语音-人脸跨模态关联学习方法的有效性,具体实验详情如下。
2.1 数据集
Voxceleb1是一个来源于YouTube的大规模视听人类语音视频数据集,其中包含1 251位名人,他们有不同的年龄、职业和口音。VGGFace[27]是一个大规模的人脸识别数据集,其中包含2 622位名人。在实验中,选择了这两个数据集的交集,同时为了保证实验评测的有效性,将交集数据集中的1 225个身份进行划分,生成了不含身份信息重叠的训练集、验证集和测试集,身份个数分别为924,112、189。
2.2 实验设置
本文的实验平台与环境配置如表1所示。语音编码器采用在VoxCeleb2[28]数据集上预训练的ECAPA-TDNN[29]模型;人脸编码器采用在VGGFace2[30]数据集上预训练的Inception-v1[31]模型。最终输出256维的语音和人脸特征向量。

表1 实验平台与环境Table 1 Experimental platform and environment
2.3 评价指标
为了验证本文方法的有效性,实验从以下4种语音-人脸跨模态关联学习任务上进行评估。
(1)跨模态验证。跨模态验证是指给定一组语音片段和人脸图像,判断样本对是否属于同一身份。评价标准采用受试者工作特征曲线(receiver operating characteristic, ROC)下面积(area under curve, AUC)值为量化指标,ROC曲线是以假阳率为横轴,以真阳率为纵轴的曲线,故AUC值越高表示模型在验证任务上的性能越好。
(2)1∶2匹配。跨模态1∶2匹配包括语音-人脸(voice-face, V-F)和人脸-语音(face-voice, F-V)两种情景。V-F情景下的1∶2匹配是指给定一段语音和两张人脸图像,判断这段语音和其中的哪一张人脸图像属于同一身份。F-V情景下的1∶2匹配反之,是指给定一张人脸图像和两段语音,判断这张人脸图像和其中的哪一段语音属于同一身份。评价标准均采用准确性(accuracy,ACC)值为量化指标,ACC值表示正确匹配的样本数与总样本数之比,故其值越高表示模型在匹配任务上的性能越好。
(3)1∶N匹配。跨模态1∶N匹配是在1∶2匹配的基础上进行扩展,将待选样本的总数增加到N,从N个样本中判断与待匹配样本属于同一身份的唯一正例。同样的,1∶N匹配也包括V-F和F-V两种情景,评价标准均采用准确性ACC值为量化指标。
4)跨模态检索跨模态检索是指给定一种模态的一个样本,从另一种模态的样本库中检索与之属于同一身份的正例,并根据样本对之间的相似度进行排序。评价标准采用平均准确率均值(mean average precision, mAP)为量化指标,mAP综合考虑了准确率和排名质量,数值越高表示模型在检索任务上的性能越好。
2.4 消融实验与对比实验
2.4.1 消融实验
为了明确两个主要的网络模块和两个距离度量损失函数对最终实验评估的影响,利用Voxceleb1数据集在原实验环境和参数下进行消融实验,以语音-人脸跨模态验证的实验结果为参考进行分析。
自监督语音-人脸跨模态关联学习网络模型主要由多模态共享模块、自监督学习模块和度量学习模块组成,其中度量学习用到了多相似性损失函数和均方误差损失函数。由于度量学习中多相似性损失函数是必要的,因此保留该函数,然后分别删除两个模块和均方误差损失函数进行消融实验,实验结果如表2所示。

表2 Voxceleb1数据集消融实验结果Table 2 Ablation experiment results of Voxceleb1 dataset
从表2中可以看出,当删除其中任何一个模块或者均方误差损失函数,与完整模型相比,跨模态验证AUC值均有一定程度的下降。当没有多模态共享模块时,AUC值下降了0.3%;没有自监督学习模块时,AUC值下降了0.1%;尤其是没有均方误差损失函数的情况下,AUC值下降了0.7%,下降比例最大。经过对实验结果的分析,多模态共享模块、自监督学习模块以及均方误差损失函数对最终结果都有一定的优化。
2.4.2 对比实验
1)跨模态验证
本文对测试集引入性别约束,按2个分组进行测试,分别是未分层组(U)和按性别分层组(G)。按性别分层组(G)指的是给定的一组语音片段和人脸图像性别相同。跨模态验证的结果对比如表3所示。

表3 跨模态验证任务上的AUC值Table 3 AUC values on cross-modal verification task
经过对实验结果的分析,本文方法在两个测试组上的量化指标均有提升。其中,“U”分组比Bi-Pcm-FST方法提升了1.9%,比CMPC方法提升了2.3%,“G”分组比Bi-Pcm-FST方法提升了3.8%,比CMPC方法提升了3.4%。实验结果明确表明,本文所提出的方法在跨模态验证任务上优于现有的几种方法。
2)1∶2匹配
1∶2匹配的结果对比如表4所示,包含“V-F”和“F-V”2种情景。

表4 跨模态1∶2匹配任务上的准确率Table 4 Accuracy(ACC) on cross-modal 1∶2 matching task
经过对实验结果的分析,本文方法在两个测试组上的量化指标均有一定的提升。其中,准确率最高的是“F-V”情景下的“U”分组,准确率达到了86.42%,比DIMNet-IG方法提升了2.39%,比CMPC方法提升了1.52%,比Bi-Pcm-FST方法提升了0.59%。实验结果明确表明,本文所提出的方法在跨模态1∶2匹配任务上优于现有的几种方法。
3)1∶N匹配
1∶N匹配的结果对比如图5所示,在实验中增加了随机情况下(Chance)的实验结果进行对比。

图5 跨模态1∶N匹配结果对比Fig.5 Comparison on cross-modal 1∶N matching task
经过对实验结果的分析,可以观察到随着样本库中样本总数的增加,两种模态样本之间的匹配难度也相应增加,匹配精度持续下降。实验结果明确表明,本文所提出的方法在不同的N值条件下仍然表现出优于现有其他方法的性能。
4)跨模态检索
如图6和表5所示,跨模态检索结果包含“V-F”和“F-V”2种场景。其中,图6是跨模态检索的可视化实验结果,已将语音片段和人脸图像属于同一身份的结果用绿色方框标注,不属于同一身份的结果用红色方框标注。

表5 跨模态检索任务上mAP的性能表现Table 5 Performance mAP on cross-modal retrieval task

图6 跨模态检索结果Fig.6 Cross-modal retrieval results
经过对实验结果的分析,本文所提出的方法的平均mAP为7.52,在现有方法的基础上提升了1.3%。 实验结果明确表明,基于本文模型所提取的特征表示在处理大规模数据检索任务时表现出更高的准确性。在跨模态检索任务中,由于样本库中的样本数量庞大、样本的复杂多样性以及语音和人脸之间的模态差异,使得任务的难度显著增加,因此现有方法在此任务上仍然面临巨大的挑战。
3 结论
本文提出了一种基于多模态共享网络的自监督语音-人脸关联学习方法。该方法学习到的特征向量可有效地应用于4种语音-人脸跨模态关联学习任务。首先,在双流网络的顶端设计了一个多模态共享模块,充分挖掘特征之间的非线性数据关系,增加了语音与人脸在公共特征空间上的语义关联。然后,引入自监督学习,利用生成的伪标签作为监督信号来指导度量学习的过程。实验结果表明,本文提出的方法在跨模态验证、匹配、检索任务上的表现均优于现有方法。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
少儿美术·书法版(2021年9期)2021-10-20
阅读(快乐英语高年级)(2019年5期)2019-09-10
当代陕西(2019年15期)2019-09-02
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
动漫星空(2018年9期)2018-10-26
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
