
基于FPGA 的ICN 名字解析缓存加速系统
2024-04-02 03:42李雪彤
现代电子技术 2024年7期
李雪彤,陈 晓,宋 磊
(1.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 100190;2.中国科学院大学,北京 100049)
0 引 言
随着Web 服务的普及以及连接到互联网上的设备数量不断增加,互联网用户的需求从主机之间的通信演进为主机到网络的信息重复访问。信息中心网络(Information-Centric Networking, ICN)实现了从传统主机为中心的网络到信息为中心的网络架构的转变[1]。名字解析系统在寻址-路由分离的ICN 架构中,负责建立、维护信息标识与信息的实际物理地址之间的映射关系,是ICN 网络获取信息内容的关键[2]。因此,名字解析服务的查询延时等性能指标极大影响了用户体验。
当前的名字解析系统大多从路由方法和系统节点负载均衡方法的角度降低解析时延,文献[3]讨论了提供分布式本地的名字解析系统,保证用户可以就近获得服务,降低解析时延。但现有的名字解析系统受限于传统软件网络协议栈的固有性能瓶颈,无法满足高性能的需求。现场可编程门阵列(Field Programmable Gate Array,FPGA)因其低功耗、高性能以及可编程的特点广泛应用于高性能服务器设备中,将软件实现的功能卸载到FPGA 中,实现对网络功能的加速。例如,文献[4]基于FPGA对DNS权威服务器的功能进行卸载加速;文献[5]利用FPGA 的并行计算能力对国产数据库加速;文献[6]基于FPGA 实现了一种大容量、高性能的路由查找算法;文献[7]在FPGA上使用哈希算法实现了高性能键值存储。
为降低名字解析系统的负载,减少名字解析服务的查询时延,本文提出一种基于FPGA 的ICN 名字解析缓存加速系统,在网络节点上存储标识到网络地址的映射关系,处理需要获取网络地址的转发数据包,减少数据包对名字解析系统的请求访问。同时,采用尽力解析的方式与主机CPU 协同工作,实现对名字解析服务的透明加速。
1 ICN 网络的名字解析服务
根据内容寻址和转发的方式,ICN 架构主要可以分为直接基于名字路由的转发方式和寻址-路由分离的转发方式两类。在寻址-路由分离的ICN 架构中[8-10],内容标识符通常采用扁平化的命名方式,标识符和定位符被分别定义到两个不同的命名空间。用户首先在网络中获得与标识符相对应的定位符,然后根据定位符对数据进行路由。名字解析服务就是根据标识符在网络中获得相对应的定位符。软件定义网络(Software-Defined Networking, SDN)将网络设备的数据平面和控制平面分离,控制平面负责逻辑决策,通过下发流表项的方式告知数据平面如何进行操作,实现灵活性。
在SDN 与ICN 相结合的网络架构中,网络数据包为了获取一个唯一标识对应的实际物理地址信息,数据面将网络数据包上送至控制面,控制面将网络数据包转换成解析请求,并通过解析系统交互接口与名字解析系统交互获取实际物理地址信息,返回到数据面;数据面根据返回的地址信息对报文中的地址字段进行处理,形成新报文,并通过基于地址的转发机制进行转发。如上所述,网络数据包请求名字解析服务的处理流程长,造成网络延迟和性能下降。
本文利用FPGA 技术在网络节点的数据面上维护大规模的标识到网络地址的映射关系。该方法允许网络数据包直接在数据面查询对应的物理地址信息,从而显著减少了数据包与网络控制面的交互次数。同时,FPGA 具备并行化和低功耗的特点,能够快速响应需要获取实际物理地址的网络数据包。
2 系统整体架构
系统整体架构包括网络设备的控制面和数据面以及名字解析系统,如图1 所示。其中,数据面的功能利用FPGA 网卡实现,网卡通过PCI-E 接口挂载在服务器主板上,与CPU 通过总线通信。同时,使用万兆光纤接口与网络通信,用于收发网络数据包。

图1 系统整体架构
名字解析缓存加速器在FPGA 网卡上实现,主要的工作流程为:
1)解析接收到的网络数据包,判断是否需要查询网络地址,若需要,则提取查询的标识ID;
2)根据网络数据包中提取的标识信息,在映射表中查找对应的表项;
3)如果查找到相应的表项,修改网络数据包的目的地址字段并发送,否则,将该数据包上送至控制面,与名字解析系统交互获取实际的物理地址。
除此之外,若名字解析缓存加速器处于满载状态,难以及时处理新的请求,该系统架构将超出处理能力的网络数据包上送至控制面处理。网络数据包的处理流程如图2 所示。
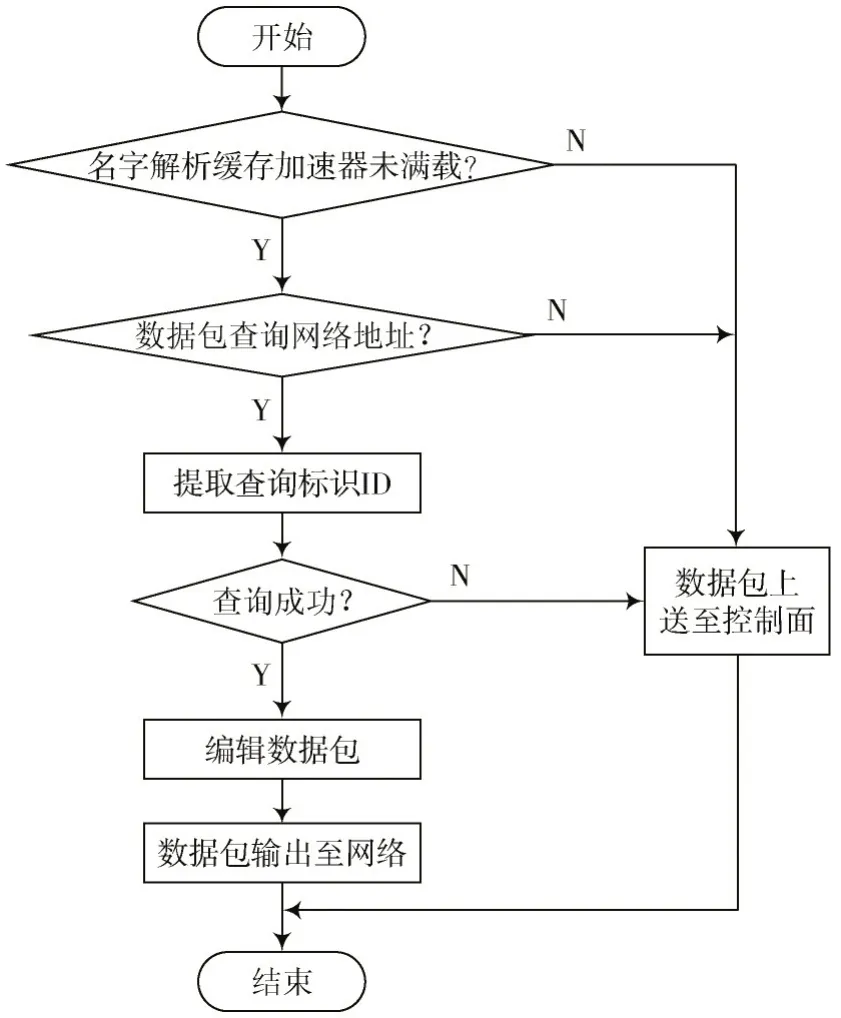
图2 网络数据包的处理流程
本文设计的架构通过在FPGA 网卡上实现名字解析缓存加速器,采用尽力解析的方式与主机CPU 协同工作,确保对请求数据包的响应,实现对名字解析服务的透明加速。当网络数据包被上送至控制面时,除返回对应的地址信息外,还返回表项信息,保证名字解析缓存加速器的存储表项更新;另外,名字解析缓存加速器独立于FPGA 网卡的其他功能,仅需实现名字解析应用处理的功能,功能更新不需要修改其他系统组件,部署简便。
3 名字解析缓存加速器设计
图3 是本文设计的基于FPGA 的名字解析缓存加速器整体结构,该加速器的设计是在开源Corundum[11]网卡工程的基础上进行的,其优势在于无需卸载网卡的所有功能,只需要专注于所加速的服务。
硬件系统设计成流水线的处理模式,主要包括包解析模块、匹配查询模块、包封装模块以及输出引擎模块等部分。其中,匹配查询模块主要由五部分构成:键提取模块、仲裁模块、哈希计算模块、命令处理模块以及动作执行模块。为了最大程度地在网络节点的数据面上处理需要获取网络地址的转发数据包,减少数据包与控制面的交互,降低网络时延,对名字解析缓存加速器的存储规模提出了特定要求。该系统设计将标识与网络地址的键值对存储在DDR3 内存中,以实现高效且大规模的解析操作。
网卡接收到以太网数据帧后进行跨时钟域转换,完成后将完整数据包传输到包解析模块进行分类处理。包解析模块在名字解析缓存加速器处于未满载状态时,对输入数据包进行判断,如果是非查询的其他报文则直接送往CPU 处理;如果是查询网络地址的数据包则对报文进行解析,提取相关信息(标识ID、目的地址的偏移OFFSET 等)送至匹配查询模块。包解析模块在名字解析缓存加速器处于满载状态时,直接将所有数据包上送至CPU 处理。这样处理的优势在于确保对请求数据包的响应,实现透明加速。
匹配查询模块提取字段信息中的标识ID 作为匹配查询的键,计算哈希值并根据哈希值索引表项,并返回查询结果到包封装模块。包封装模块负责对数据包进行编辑修改。输出引擎模块则将查询成功的数据包转发至网络,查询失败的数据包上送至控制面匹配查询。
3.1 包解析模块设计
首先判断当前名字解析缓存加速系统是否处于满载状态。在非满载状态下,包解析模块对到达系统的数据包按照协议格式逐层进行解析,获取关键字段;若处于满载状态,直接将数据包上送至CPU 处理。该模块主要实现网络数据包的协议解析处理,提取标识ID,计算目的IP 地址偏移,过滤无关报文。其中,名字解析缓存加速系统是否处于满载状态根据数据FIFO 当前的占用情况和名字解析缓存加速系统的处理能力综合设定。
鉴于FPGA 硬件结构的特殊性,该模块的设计采用流水线的处理方式,时序如图4 所示。在数据包间隙设置为1 个时钟周期时,可以进行正常解析处理,说明在200 MHz 时钟处理频率、数据位宽为128 bit 的情况下,可完全满足线速解析处理的要求。

图4 包解析模块线速处理时序图
3.2 匹配查询模块设计
本文利用哈希表来实现标识ID 的匹配查询,为实现大规模的标识ID 到网络地址的映射,哈希表采用DDR3进行存储。其中,标识ID 作为匹配查询的关键字,为160 bit;网络地址作为与之对应的值,为128 bit。由于2的整数次幂非常适合在DDR中进行哈希表的快速寻址与表项读写操作。考虑到这一点,本文设计key-value对的大小为512 bit。为了缓解哈希冲突,哈希表的单个地址采用多槽位(slot)结构,能够存储4个key-value对,如图5所示。在该配置下,8 GB的DDR3内存能够支持3 200万条表项存储。
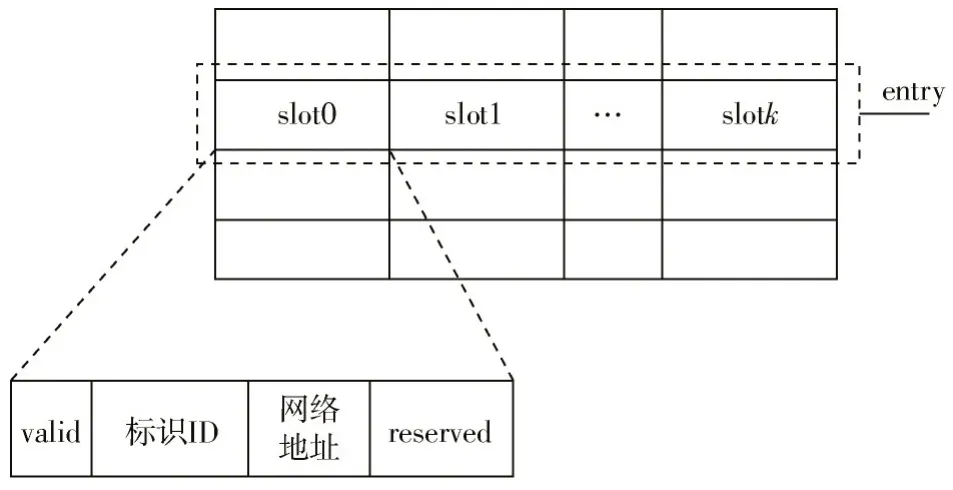
图5 哈希表表项结构
考虑到本系统中表项的更新信息(插入/删除)和查询请求的接口不同,设计仲裁模块。该模块的主要功能是将更新表项的插入/删除请求与来自前序键提取模块的查询请求进行合并。仲裁模块将表项的更新请求以及查询请求分别缓存在两个FIFO 队列中,当后续模块返回ready 信号有效,并且至少有一个FIFO 非空时,仲裁模块才会根据当前的有限状态机状态从两个FIFO 中提取相应的请求。在这个过程中,插入和删除请求具有高于查询请求的优先级。
哈希计算模块具备H3哈希计算功能,前序仲裁模块输入关键字key,该模块输出对应的地址值index。H3哈希函数[12]已经被证明可以有效地在散列表条目中均匀分配密钥,这种均匀分布本身显著降低了哈希冲突。其次,H3哈希函数仅需要简单的逐位AND 和XOR 运算,也非常适用于高吞吐量的硬件实现。该模块输出的哈希计算结果会经由寄存器配置有效的哈希值位宽范围,对哈希计算结果进行取低位操作以适配不同大小的内存外设。
命令处理模块完成对DDR3 的读写以及表项的对比处理,其硬件实现结构如图6 所示。在Xilinx 平台中通过MIG IP 核对DDR3 进行读写操作,在实际读写过程中使用AXI4 总线。由于MIG IP 核提供的时钟与用户时钟频率存在差异,因此在使用该总线时利用异步FIFO 处理跨时钟域问题。
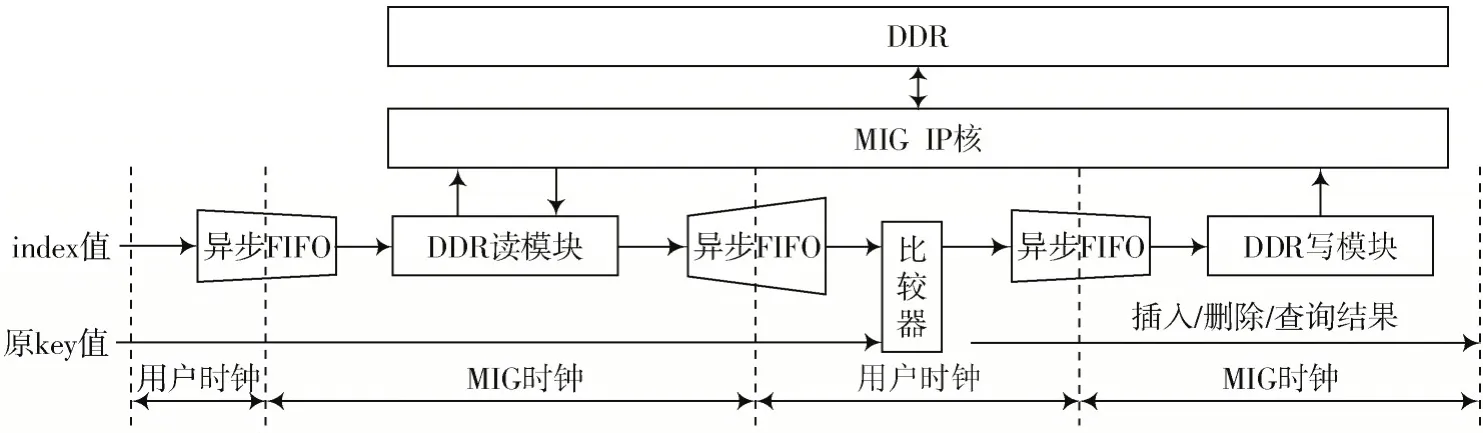
图6 命令处理模块的硬件实现结构
DDR 读模块通过与前置FIFO 与后置FIFO 的配合,实现DDR 读功能。前置FIFO 中存储着index 值,即读地址。当前置FIFO 非空时,DDR 读模块取出读地址并完成读任务;当后置FIFO 未满时,将读结果放入后置FIFO 中,随后继续探测前置FIFO 是否为空,以进行下一次读任务。DDR 读模块每次读内容的大小由表项大小决定。DDR 写模块通过与其前置FIFO 配合,实现DDR 写功能。其中,前置FIFO 存储待写入的完整表项内容。
比较器模块将待处理请求的原key 值与读取的表项结果进行比较,4 个槽位的对比是并行执行的,将存在以下情况:
1)查询请求。对于查询请求,该模块将请求中的关键值key 与读取表项中4 个槽位的关键值并行对比,如果找到匹配的关键值,则输出查询结果;如果没有匹配项,则返回查询失败的信息。
2)插入请求。在处理插入请求时,如果读取的表项中存在空槽位,或者虽然没有空槽位但存在与请求中关键值相同的项,则会通过DDR 写模块更新表项,并返回插入成功的信息;如果两种情况均不满足,则视为发生了碰撞,此时将丢弃待插入的表项,并返回插入失败的信息。
3)删除请求。在处理删除请求时,如果读取的表项不为空且关键值与请求中的相同,则通过DDR 写模块删除该表项,并返回删除成功的信息;如果读取的表项为空或关键值不一致,则返回删除失败的信息。
3.3 包封装模块设计
在常规设计中,数据包封装模块通过重构数据包包头的方式来构建响应数据包,这通常需要占用大量的设计资源。本文提出的数据包封装模块采用更为高效的方法,它根据数据包解析模块计算得出的目的IP 地址的偏移信息以及动作执行模块输出的查询结果,直接对原始请求包进行编辑修改。这种方法不仅减少了资源消耗,还提高了封装过程的效率。
4 系统测试与分析
为进一步验证本文设计的ICN 名字解析缓存加速系统在真实情况下的性能,故设计板级测试实验。设计的架构在Xilinx XC7K32-5TFFG900-2 的FPGA 板卡上实现;测试平台选用DellR730 商用服务器,该服务器配备两个6核Intel Xeon E5-2609 v3 1.9 GHz CPU以及8 GB DDR3 内存,操作系统为CentOS 7.9;测试设计的架构时,选用Spirent 公司的SPT N4U 作为网络测试仪,测试仪运行的软件采用Spirent TestCenter Application 4.82版本,设备间使用光纤互联。
4.1 性能分析
为了测试本文提出的基于FPGA 的ICN 名字解析缓存加速系统的吞吐量及延迟指标,实验使用思博伦测试仪生成数据包长度为128~1 500 B 的10 Gb/s 测试流量,经过FPGA处理后,测试流量被转发回思博伦测试仪。
图7 展示了系统的吞吐量指标,硬件实现的ICN 名字解析缓存加速系统能够以10 Gb/s 的线速处理256 B以上的解析请求数据包。此外,本文提出的加速系统架构采用尽力解析的方式,对于256 B 以下的请求包,将超出能力范围的数据包交由控制面处理。该架构在保持解析服务能力的同时,有效地加速了解析过程。
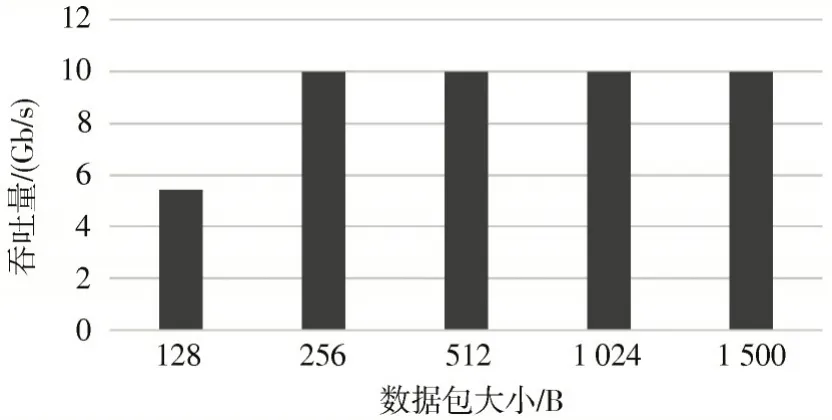
图7 名字解析缓存加速系统的吞吐量
如图8 所示为名字解析缓存加速系统对不同包长的数据包的转发率,该系统对256 B 小包的转发率达到4.5 Mpps,支持每秒四百万次请求,而软件实现的名字解析系统仅支持每秒十万次请求,性能大大提升。
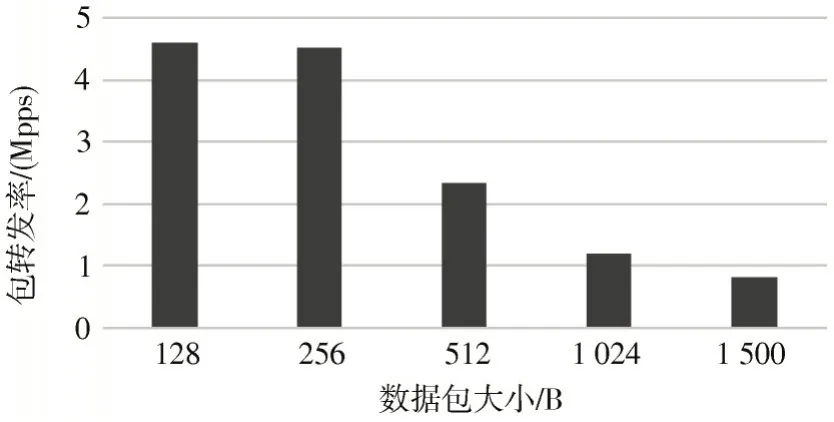
图8 名字解析缓存加速系统的数据包转发率
本文系统对解析请求包的处理时延如图9 所示,结果显示基于FPGA 的名字解析缓存加速器处理256 B请求包的时延仅为1.5 μs,远低于软件的处理时延。文献[13]中提出,利用传统套接字实现的键值存储系统的处理时延在41.40 μs,基于DPDK 实现的键值存储系统的处理时延在6.29 μs。数据表明,硬件实现的键值存储系统相较于传统软件实现的键值存储系统处理速度提高了27 倍,与使用DPDK 内核旁路进行优化的软件相比处理速度提高了4 倍。
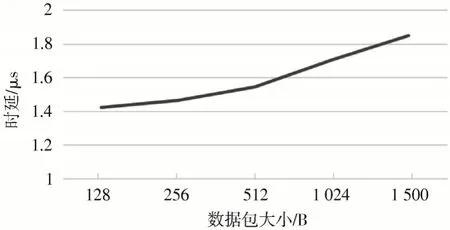
图9 名字解析缓存加速系统的处理时延
4.2 资源开销
本文工程基于Xilinx FPGA 的XC7K32-5TFFG900-2设计实现,运行频率为200 MHz,其资源消耗如表1 所示,包括查找表(LUT)、触发器(FF)和存储器资源(BRAM)。由于表项存储在片外DDR上,节省片上资源。
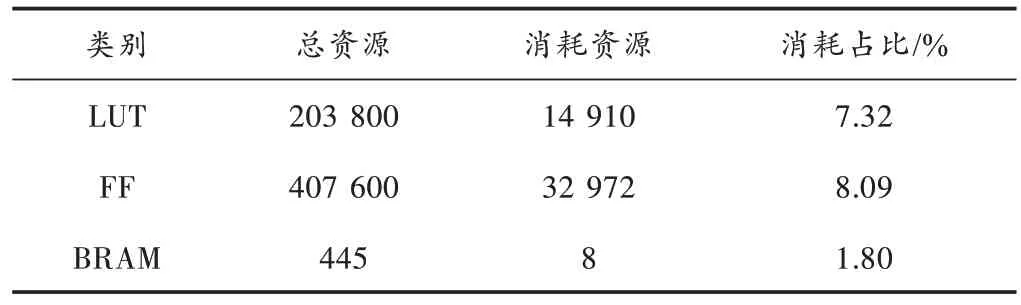
表1 FPGA 工程资源消耗情况
5 结 语
为解决ICN 网络中名字解析服务流程长以及名字解析系统负载高的问题,本文提出一种基于FPGA 的ICN 名字解析缓存加速系统。该架构在网络节点的数据面卸载名字解析功能,处理需要获取网络地址的转发数据包,有效缩短处理流程。同时,采用尽力解析的方式与主机CPU 协作,满载时将数据包上送至控制面处理,在不影响服务能力的前提下加速了整个过程。
系统测试验证显示:基于FPGA 实现的键值存储处理性能相较于传统软件以及基于DPDK 实现的键值存储处理性能均明显提升;其次,名字解析缓存加速器与网卡其他功能分离的形式极大简化了系统设计难度。
注:本文通讯作者为宋磊。
猜你喜欢
有色金属科学与工程(2023年4期)2023-02-08
通信技术(2022年5期)2022-06-11
科学与生活(2021年32期)2021-01-17
计算机工程与应用(2020年7期)2020-04-07
中南民族大学学报(自然科学版)(2017年3期)2017-10-18
电脑知识与技术(2016年12期)2016-06-14
无线互联科技(2016年5期)2016-05-16
工业设计(2016年8期)2016-04-16
计算机工程(2015年8期)2015-07-03
计算机工程(2014年6期)2014-02-28
