
基于双语词典的远距离语对无监督神经机器翻译方法
2024-04-02 03:42黄孟钦
现代电子技术 2024年7期
黄孟钦
(昆明理工大学信息工程与自动化学院,云南昆明 650500)
0 引 言
2013 年,Nal Kalchbrenner 和Phil Blunsom 提出了端到端编码器-解码器结构[1],这一创新将神经机器翻译引入了主流研究领域。近年来,基于深度学习的方法逐渐在机器翻译领域占据主导地位。这些方法在许多语言对之间的翻译任务上表现出色,有些情况下甚至超越了人类翻译的质量。
然而,基于神经网络的翻译模型高度依赖于可用平行数据的数量和语言之间的相关性。在一些拥有丰富平行语料的语言对,尤其是同一语系的语言对上,神经机器翻译已经展现出了卓越性能[2]。但在实际应用中,存在很多语言对之间缺乏足够平行语料的情况,有些语言甚至没有可用的平行数据,导致神经机器翻译的性能下降。
为了减少神经机器翻译模型对平行数据的依赖,文献[3]提出了无监督神经机器翻译(Unsupervised Neural Machine Translation, UNMT)方法。这种方法仅利用两种语言的单语语料库进行翻译,而不使用平行语料,从而摆脱了对大量平行数据的需求。在某些语言对上,无监督神经机器翻译已经取得了出色的效果,甚至能够媲美有监督神经机器翻译。然而,在一些远距离语言对,例如中-英语言对,其翻译效果仍然不够理想。这主要是因为远距离语言对之间的对齐信息较为稀缺,语言之间的相似性较低。因此,针对远距离语言对的无监督神经机器翻译面临着一个难题,即如何让源语言和目标语言在潜在空间中实现有效的对齐。
为提供更多对齐信息,研究者们开始尝试引入外部知识来辅助模型学习两种语言之间的对齐关系。文献[4]探索了使用词典辅助无监督神经机器翻译的方法,将翻译过程分解为两个阶段:首先,利用源语言到目标语言的双语词典,将源语句中的部分词替换为词典中对应的目标词,生成粗略的中间译文;然后,将生成的中间译文输入神经机器翻译模型,以获得流畅的目标语言译文。这种方法旨在为翻译模型提供更多对齐信息,从而改善远距离语言对的翻译效果。
1 相关工作
1.1 无监督神经机器翻译
神经机器翻译在取得卓越性能时的一个前提条件是拥有大量的平行语料,这些语料用于训练模型以学习源语言和目标语言之间的映射关系。然而,在应用中确实存在很多语言对之间缺乏足够平行语料的情况,比如德语和俄罗斯语之间的翻译。构建平行语料库需要昂贵的成本,而缺乏平行语料会显著降低神经机器翻译模型的性能[5]。
为了减少神经机器翻译模型对平行数据的依赖,研究人员开始尝试不使用平行语料,而是仅使用两种语言的单语语料库来训练模型,被称为无监督神经机器翻译[3]。这种方法有助于克服对平行数据的严重依赖,从而能够在缺乏平行语料的情况下进行翻译。然而,需要注意的是,无监督神经机器翻译仍然面临一些挑战,尤其是在远距离语言对的情况下,语言之间的对齐信息非常有限,导致翻译质量受到影响。
1.2 双语词典归纳
双语词典归纳(Bilingual Lexicon Induction, BLI)[6]用于在缺乏两种语言之间平行语料的情况下,利用各自语言的单语语料生成对齐的双语词嵌入,并通过这些嵌入来归纳出双语词典。双语词典归纳的核心思想在于学习一个映射函数,该函数能够将两种语言中的词嵌入映射到一个共同的向量空间中,以便于进行后续的对齐操作。虽然没有直接的平行语料,但通过将单语语料中的词嵌入映射到共享的空间中,可以在一定程度上实现不同语言之间词汇的对应关系。
通过双语词典归纳,可以在缺乏平行数据的情况下,利用单语语料中的信息构建一些基本的语言关联,从而实现单词级别的翻译任务。这对于处理缺乏大量平行语料的语言对或语种之间的翻译任务非常有帮助。
1.3 预训练语言模型
在早期,一些方法开始尝试利用预训练模型的表征向量来初始化神经机器翻译(Neural Machine Translation, NMT)模型的表征向量。这一策略显著提升了模型的训练效果,特别是对于训练数据稀缺的语言对而言。这表明预训练模型的表征向量可能在NMT模型训练中发挥了一定作用,因为它们包含丰富的语义信息。
其中,跨语言模型(Crosslingual Language Model,XLM)预训练是第一个尝试将预训练应用于跨语言方向的方法。这种方法在多语言文本数据上进行预训练,使得模型能够同时学习两种语言的语法和文本特征。这种跨语言预训练方法有助于模型在不同语言之间进行知识迁移,从而提高跨语言任务的性能。当前,研究者们在跨语言预训练语言模型领域进行了大量尝试,主要的跨语言模型包括BERT[7]、XLM[8]、XLM-R[9]、MASS[10]、mBART[11]等。这些跨语言预训练模型的出现丰富了多语言NLP 研究领域,为不同语言之间的自然语言处理任务提供了强大的工具和基础。
虽然两者造型差不多,但光路完全不同。从D500的光学取景器看到的是反光板反射到对焦屏上的光线,而X-H1的电子取景器看到的是传感器接收到画面。当然,D500也可以切换到实时取景模式,但切换时反光板需要抬起,这意味着光学取景器失效(必须使用机背屏幕取景),而且D500引以为傲的相位对焦传感器也同样会失去用途,转而使用原始的反差侦测对焦。相比之下,无反结构的X-H1不会面临这个问题,无论使用取景器还是屏幕,相机的对焦方式都不会发生变化。
1.4 XLM
尽管BERT[7]在自然语言处理领域取得了显著的成就,但是不同语言之间的BERT 模型并不具有相互通用性,即它们学习到的知识不会被共享。因此,Facebook对BERT 进行了改进,提出了XLM[8],以便于在多种语言之间进行训练,从而使模型能够获得更多的跨语言信息。XLM 的方法主要分为两种:基于平行语料的有监督方法和没有平行语料的无监督方法。
因果语言模型(Causal Language Modeling, CLM)和遮蔽语言模型(Masked Language Modeling, MLM)使用单语语料进行训练,而翻译语言模型(Translation Language Model, TLM)是MLM 的扩展,不同之处在于它使用平行语料进行训练。在TLM 任务中,将MLM 的输入单语语料替换成双语平行语料,然后模型试图预测源语言和目标语言之间的对应关系,这使得模型能够借助平行语言的信息来提升翻译质量。翻译语言模型结构如图1所示。
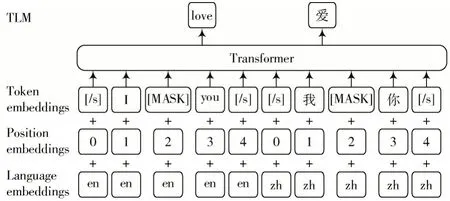
图1 翻译语言模型结构
2 方 法
2.1 双语词典的获取
在本研究中,采用文献[12]提出的方法,借助无监督的单词嵌入映射技术,从仅使用源语言和目标语言的单语语料库中提取双语词典。具体而言,首先使用Word2Vec[13]将源语言和目标语言的单词表示成分布式向量,即各自的单词嵌入。接下来,使用文献[12]的无监督单词嵌入映射方法,利用自学习或对抗性训练来学习一个映射函数f(X) =WX,将源语言和目标语言的单语词嵌入映射到一个共享的嵌入空间中,然后利用CSLS[14]计算词向量之间的相似性。最后,选择在共享空间中相似性最高的词嵌入,以提取本文中要使用的双语词典。
2.2 Dict-TLM
TLM 任务是一种有监督的任务,其目标是训练能够进行翻译的语言模型。通常情况下,这种任务需要大量的双语平行语料进行训练,但很多语言之间缺乏足够的平行语料,这导致训练比较困难。本文提出了一种改进的方法,采用词典融合的策略代替传统的平行语料进行模型训练。
这种方法的基本思想是利用单语语料和双语词典训练语言模型。具体来说,模型首先接受源语言的句子作为输入;然后,不同于TLM 的平行语料输入,模型还接受把源语言句子用双语词典处理后的数据作为输入,在此输入中,模型会将源语言句子中在双语词典出现的单词替换为相应的目标语言翻译词,这一步可以看作是一种跨语言信息融合的过程。
接下来,模型会对源语言句子和目标语言翻译句子的部分单词进行随机遮蔽。具体地,约80%的词会被用[MASK]进行遮蔽,约10%的词会被随机的标记替换,而余下的约10%将保持原样。这个步骤有助于模型学习到源语言和目标语言之间的对应关系,同时也鼓励了模型对上下文的理解和单词预测能力的提升。
需要强调的是,本文使用的双语词典是通过无监督的方式获得的,这意味着不需要依赖于任何平行语料。通过使用被替换过的源语言句子进行训练,模型可以从两个方面获得信息:首先,模型通过源语言的上下文单词来预测被遮蔽的词;其次,模型通过被替换的目标语言单词进行学习。这样,语言模型不仅能够学习源语言的信息,还能够学习两种语言之间的对应关系。这些额外的跨语言信息在后续的翻译任务中将提供有力的支持,使得模型能够更好地进行翻译工作。这一方法为解决缺乏平行语料的语言翻译任务提供了一种有效的替代方案。
Dict-TLM 模型的预训练结构如图2 所示。
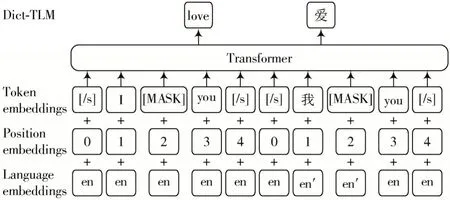
图2 Dict-TLM 模型结构
3 实 验
3.1 数据的获取
本文的实验中,采用了Facebook 于2018 年提出的完全无监督方法,即vecmap,从两种语言的单语数据中获得双语词典。该方法的独特之处在于词典的生成过程不涉及任何平行语料的使用,而是通过无监督的方式生成一个种子词典,作为后续词嵌入学习的初始知识。
在本文的实验中,使用WMT14中2007年和2008年新闻数据集中的英文以及中文单语数据集,每种语言都包含了500 万个句子。选择中国科学院自动化研究所在2015 年发布的CASIA-2015 数据集作为平行语料库,将平行语料中的目标语言语料替换为用双语词典处理后的源语言语料。对于后续的预训练任务,所有的数据都使用mosesdecoder 提供的tokenizer 进行正则化处理,中文语料使用斯坦福大学的NLP 工具进行分词处理。
3.2 实验环境设置
在本文的所有实验中,所采用的模型架构是Transformer[15],具体包括1 024 个隐藏单元、8 个注意力头、GELU 激活函数[16]、0.1 的丢失率以及学习位置嵌入。使用Adam 优化器[17],采用线性预热策略[15],学习率在训练过程中从10-4逐渐增加到5×10-4。
在预训练阶段,采用XLM 中的TLM 作为预训练语言模型。TLM 任务是遮蔽语言模型的改进版本,类似于BERT 的遮蔽语言模型任务。在TLM 训练过程中,随机遮蔽了源语言句子和目标语言句子中部分单词,其中80%的词用[MASK]进行遮蔽,10%的词用随机的token进行替换,最后10%的词保持不变。
3.3 实验结果及分析
本文采用BLEU[18]作为评价指标,来比较本文方法和其他方法的性能差异。这种评价方法认为翻译系统翻译出来的译文和人工翻译的译文越接近,那么翻译系统的翻译质量就越高。
本文进行了两个模型的训练。首先,以Lample 等人使用单语语料进行的机器翻译方法作为基准,对比了本文方法和UNMT 方法。表1 中总结了在英中和中英语言对上的基线方法和Dict-TLM 方法的性能表现。

表1 各个模型在不同的语言对上的BLEU 值
如表1 所示,实验结果表明,本文方法在中英语言对上的BLEU 分数相对于传统的无监督神经机器翻译提高了4%,而在英中语言对上的BLEU 分数也提高了4%。通过分析实验结果,可以得出结论:将源语言句子中在双语词典存在的单词替换为相应的目标语言翻译词,并以此作为源语言对应的平行语料进行模型训练,有助于模型更好地学习跨语言信息,从而实现源语言和目标语言之间更好的对齐,进而获得更出色的翻译效果。
4 结 论
本文介绍了一种创新方法,将源语言句子在双语词典中存在的单词替换为相应的目标语言翻译词,用以替代TLM 中的平行语料作为预训练模型的输入。这一方法的主要优势在于减少了模型对平行语料的依赖,给远距离语言对之间提供了更多的对齐信息,从而提高了对这些远距离语言对的翻译效果。研究结果显示,这一方法在无监督神经机器翻译中实现了显著的性能提升。
尽管取得了令人满意的进展,但在没有平行语料的情况下如何进一步提升无监督神经机器翻译的性能仍然是一个值得深入研究的问题。未来的研究方向包括如何在无监督情况下获得更高质量的双语词典,以及如何更有效地将这些词典与翻译模型融合,以更好地辅助模型实现更出色的翻译性能。
猜你喜欢
文苑(2019年24期)2020-01-06
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
疯狂英语(双语世界)(2017年3期)2018-01-19
文理导航(2017年25期)2017-09-07
疯狂英语(双语世界)(2017年1期)2017-07-01
速读·下旬(2016年7期)2016-07-20
考试周刊(2015年36期)2015-09-10
华南师范大学学报(社会科学版)(2013年1期)2013-12-02
疯狂英语·中学版(2013年7期)2013-08-01
