
基于图形识别的压裂工况智能标注方法研究
2024-04-06 12:49张德君魏伟张闻晨何小东朱智华郑光慧刘明艳杨航
电脑知识与技术 2024年3期
张德君 魏伟 张闻晨 何小东 朱智华 郑光慧 刘明艳 杨航
关键词:压裂;深度学习;数据降噪;音频特征提取;工程监控
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2024)03-0036-03
1 基础理论
1.1 曲线图形的降噪处理
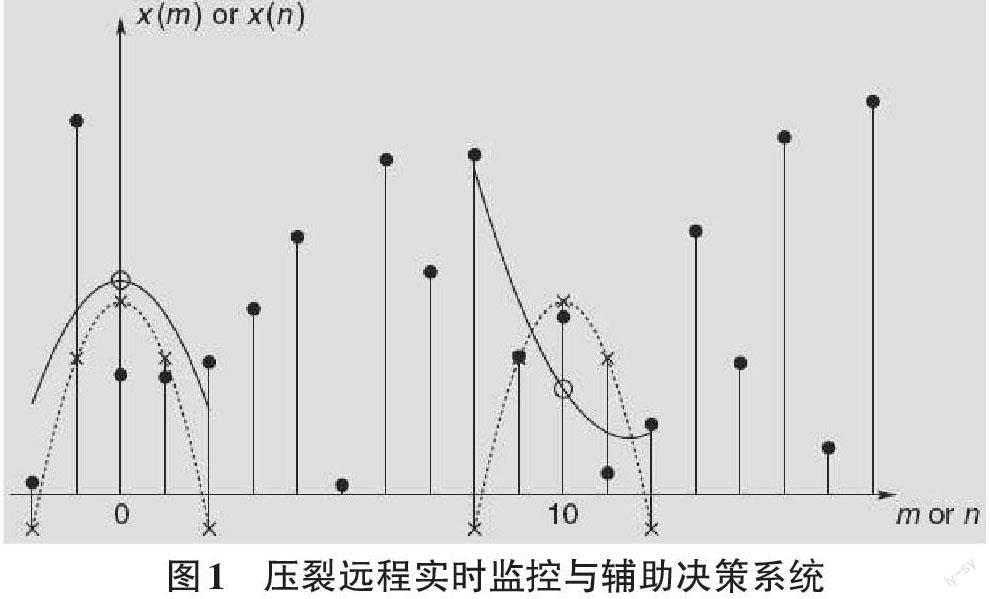
知识在处理压裂参数数据曲线时,有时会遇到一些异常的数据,这些数据无价值且会影响正常算法,因此需要进行降噪处理。Savitzky-Golay滤波器最初由Savitzky和Golay于1964年提出[1]。其广泛地运用于数据流平滑除噪,是一种在时域内基于局域多项式最小,二乘法拟合的滤波方法。这种滤波器最大的特点在于滤除噪声的同时可以确保信号的形状、宽度不变,它对信号的操作是在时域内对window_length内的数据进行多项式拟合。而从频域上看,这种拟合实际就是通过低频数据而滤掉了高频数据[2]。这种滤波其实是一种移动窗口的加权平均算法,但是其加权系数不是简单的常数窗口,而是通过在滑动窗口内对给定高阶多项式的最小二乘拟合得出。信号的最小二乘平滑的基本思想可以通过图1来说明。
1.2 曲线图形相似度判断
在实际施工过程中,因为有各种各样的因素会影响现场施工情况,使得参数曲线并不一定和压裂设计一致。所以在判断压裂施工工况时,只从一些参数指标去判断,往往无法达到预期效果。因此,本文引入图形识别的方法,根据真实施工曲线和设计施工曲线的相似情况判断。如果曲线整体趋势是偏向标准模型,就认定是当前工况。
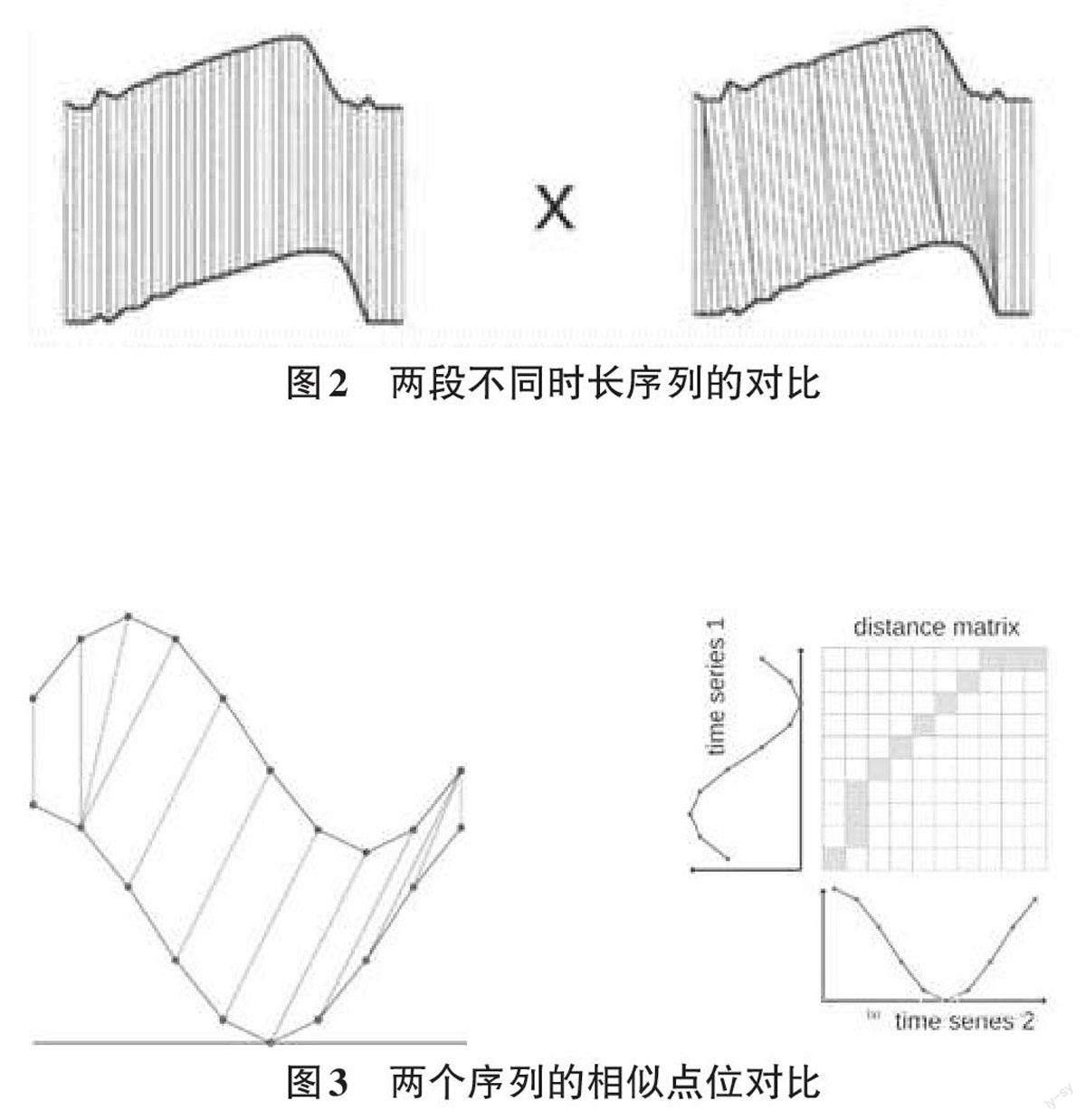
DTW (Dynamic time warping) 算法是可以度量两个独立时间序列的相似度的一种方法,曾被广泛应用在单词音频的匹配上,该方法主要用来解决在两段序列时长不同的情况下进行相似度的判断[3]。
图2中,左侧时长相等,可以逐一进行欧式距离的计算.右侧则时长不等,经过DTW之后得到的结果,可以看出来两个序列并不一一对应。
如图3,要得到序列1与序列2的相似度,可以看出,两个序列有经过平移的迹象,直接用一一匹配的方法显然不合理。要得到图3的对应效果,就需要用DTW方法。
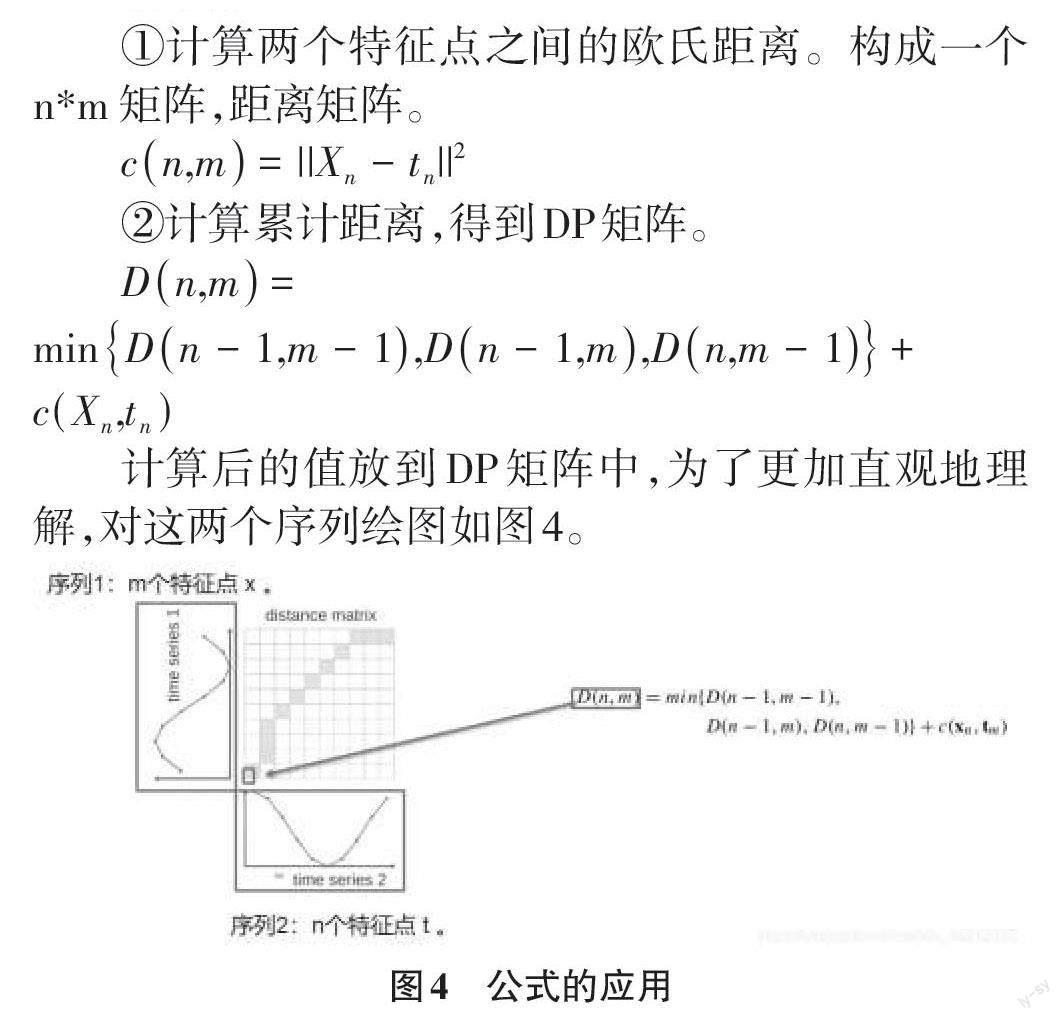
计算后的值放到DP矩阵中,为了更加直观地理解,对这两个序列绘图如图4。
2 案例与分析
2.1 模拟平台搭建
为方便进行数据分析并将分析结果直观展示,本文搭建了分析平台。具体使用的技术选型如下,前端采用VUE架构,并使用VUEX、vue-rounter等VUE技术框架,自底向上增量开发的设计,让数据响应时间更短。后端采用时下最流行的Spring cloud框架,无缝衔接新疆油田云平台。不仅如此,在数据处理方面,对静态数据和动态数据分类型处理,分别利用click?house 数据库对时序数据支持的能力和Oracle数据库稳定性分别储存动态传输数据和静态结果數据,为智能算法赋能。同时在数据读取时,将数据进行预处理,将参数异常项过滤掉,减少运算压力,增加算法准确度。建设相关的系统架构如图5。
平台模拟了桥塞,暂堵和连续油管三种不同的工艺施工情况,针对不同的施工工艺分别整理了两口不同的施工井,确保训练素材的普适性。
2.2 模拟平台搭建
自行建立数据发送程序,将秒点数据从Excel表格中发送到数据库中,再从数据库中提取数据。
预处理数据时采用了Savitzky-Golay 滤波器,对数据进行滤波处理,减少异常数据入库。
在对数据库设计时,设计数据库模型来存储用户、数据集、训练任务和模型等相关信息。使用JPA(Java Persistence API) 或其他ORM(对象关系映射)工具来简化数据库操作。结合压裂数据的数据特性,我们选择Oracle和Tdengine数据库,充分利用Oracle数据库和Tdengine数据库的技术特点,提高训练平台的稳定性和速度性。
规范API接口,设计和实现RESTful API接口,用于管理数据集、创建和管理训练任务、获取训练进度和结果等,可以使用Spring MVC来构建API接口。
神经网络训练逻辑,根据压裂工程方面特性选择的神经网络类型和训练算法,实现相应的训练逻辑。
结果展示和模型部署,设计和实现结果展示页面,以展示训练任务的进度和结果。在训练完成后,提供模型保存和部署的功能,同时也使用Web技术,跨平台实现不同操作系统的界面展示,让用户直观看到训练成果,同时也可让用户可以使用训练得到的模型进行预测和推断。
2.3 模型训练
CNN由纽约大学的Yann LeCun于1998年提出。CNN本质上是一个多层感知机,其成功的原因在于它所采用的局部连接和共享权值的方式。
由于各种施工工艺决定了施工参数的走向,而且工艺类型数量较少,只需稍加训练模型,就能提高工艺的识别准确度,进而标注出对应的施工阶段。收集带有工况标签的数据集。压裂施工数据集应包含施工数据和对应的标签,确保数据集的标签与施工数据对应。对压裂施工数据进行预处理。这可能包括压裂施工数据的采样率调整、时域和频域的特征提取、值域数据增强、干扰信号去除等,预处理有助于提高模型的训练效果和鲁棒性。根据前期选定好的模型方向进行训练,确定输入数据的维度和特征。对于图像数据,通常是二维的图像矩阵,对于压裂施工数据,可以使用短时傅里叶变换(STFT) 将压裂施工数据图像转换为时频图,引入卷积操作来提取图像或音频数据的局部特征[4]。通过设置不同的卷积核数量和大小,可以捕捉到不同层次的特征,可以使用多个卷积层进行层级特征提取。在卷积层之后,引入非线性激活函数,如ReLU(Recti?fied Linear Unit) ,用于增加模型的非线性表达能力。通过池化操作(如最大池化或平均池化)减少特征图的维度,同时保留重要的特征。池化操作有助于减少模型的参数数量和计算复杂度。引入批归一化操作可以提高模型的稳定性和训练速度。该层用于对每个批次的数据进行标准化处理,有助于加速模型的收敛和改善模型的泛化性能。通过全连接层将卷积层的输出映射到最终的输出类别,全连接层通常包括多个神经元,可以进行特征的组合和分类。
使用CNN模型提取压裂数据的特征表示。将音频数据输入CNN模型中,获取卷积层输出的特征图。对于压裂施工数据,可以使用短时傅里叶变换(Short-Time Fourier Transform,STFT) 等技术将压裂施工转换为时频表示,作为输入特征使用带有标签的压裂施工数据集对CNN模型进行训练,将提取的音频特征和对应的标签输入模型中,计算预测结果,并通过反向传播算法更新模型的权重[5]。使用验证集评估训练好的模型的性能。计算模型对音频样本的预测准确率、分类精度或其他指标,可以使用混淆矩阵、准确率、召回率等评估模型在不同类别上的表现。
改进的CNN模型采用五层网络结构,选取Relu 为激活函数,添加dropout层,利用交叉熵来定义损失,在经过多次调整参数后,选定学习率为0.000 1,drop?out率为0.15时效果较好。训练次数为2 000次时的loss值变化如图6所示,在经过约300次的训练loss值已经降低到很小。
2.4 模标注结果
使用模型训练的算法去判断施工阶段,已经可以非常准确地判断施工类型,即使在非常大的数据干扰下也依然可以准确判断。以JLHW2001井17-8压裂段为例,施工阶段的6个类型均能准确判断,并识别出对应的标注名称,如图7所示。
在压裂施工数据同CNN进行结合时,使用了多种结合方式、多种特征的提取方式,最终认为使用和音频数据识别的信号特征提取方式一致,使用了短时傅里叶变换技术,音频信号和压裂施工数据有着一些相似的地方,从而完成对CNN模型的训练,达到实现压裂施工数据的工况识别。
3 结束语
智能算法处理数据是大数据背景下必不可少的工具,使用CNN模型训练后的深度学习算法在处理模糊不清的数据时更加精准。大数据提供了更多样化、更全面的数据资源。传统研究可能只能依赖有限的数据样本,而大数据能够涵盖更广泛的领域、更多的观测和测量结果,使研究人员能够获得更全面的数据,从而更好地理解和解释现象。通过大数据处理技术,可以处理大规模数据集,并应用更复杂的算法和模型进行分析。这有助于发现更深入的模式、趋势和关联关系,从而提高研究的准确性和可靠性,帮助研究人員发现新的洞见。通过分析大规模数据集,可以发现意想不到的关联、非线性关系和新颖的模式,从而推动研究的前沿。传统的研究方法可能需要花费大量时间和资源来处理有限的数据集,而大数据技术可以更快地处理大规模数据,并实时或几乎实时地提供分析结果,从而加快研究进展。总之,批量的数据在智能算法的帮助下变得更加清晰透明,也为研究员提供了帮助,从而提高工作效率和生产效率。
【通联编辑:代影】
猜你喜欢
科技创新与应用(2017年6期)2017-03-23
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
中小企业管理与科技·中旬刊(2016年7期)2016-07-08
中国高新技术企业(2015年14期)2015-04-29
中华建设科技(2014年4期)2014-07-18
