
数据挖掘技术在计算机档案管理中的应用分析
2024-04-06 13:05李阿芳张言上张颖吕佳慧周琦
电脑知识与技术 2024年3期
李阿芳 张言上 张 颖 吕佳慧 周琦
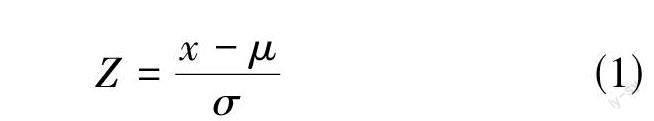

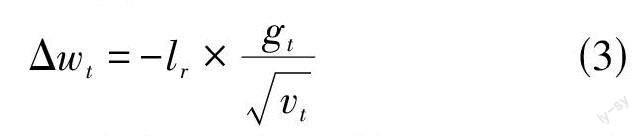
关键词:数据挖掘;档案管理;大数据
中图分类号:G270 文献标识码:A
文章编号:1009-3044(2024)03-0072-03
0 引言
计算机档案管理是指通过计算机技术和软件工具对档案进行收集、整理、存储、检索和维护的过程[1]。
随着数字化转型的推进,档案管理逐渐从传统的纸质档案转向电子档案,这为数据挖掘技术的应用提供了良好的基础。数据挖掘技术可以从大量的电子档案中自动发现和提取有价值的信息,为档案管理提供更高效和准确的支持。基于档案数据的量大、复杂度高、利用率低等现存问题,本文详细阐述了数据挖掘技术在计算机档案管理中的具体应用,包括数据源采集、数据预处理、构建挖掘模型、数据可视化等。希望通过本文的研究和分析,能够为档案管理人员提供一些参考和启示,进一步推动数据挖掘技术在计算机档案管理中的应用和发展。
1 数据挖掘技术在计算机档案管理中的应用方向
1.1 档案收集
档案收集是档案管理的重要环节,它涉及获取、整理和登记各种类型的档案资源,以便后续的分类、保管和传输。数据挖掘技术可以帮助档案管理人员从各种电子文档、图片、视频等非结构化数据中抽取有价值的信息[2]。通过对大量档案数据进行文本挖掘、图像分析等处理,自动化地识别出关键词、主题、关联性等信息,避免了人工逐一查找和筛选的烦琐过程,提高档案收集的效率,从而构建起一个全面而准确的档案资源库。
1.2 档案分类
档案分类是对已收集到的档案资源进行归类整理的过程,旨在提高档案的检索效率和管理精度。而数据挖掘技术可以通过分析已有档案中的内容特征、关键词等信息,自动发现其中的潜在关联和规律。通过运用聚类分析、关联规则挖掘等方法,可以将具有相似性质或相关特征的档案资源自动归类到相应的分类中,减轻了人工分类的工作量和主观性。此外,数据挖掘技术还能够辅助档案管理人员进行档案的主题分析和关键词提取。通过对档案数据进行文本挖掘和语义分析,可以自动提取出其中的主题、关键词和摘要等信息,提高档案的检索效率和利用价值。
1.3 档案保管
在档案保管方面,数据挖掘技术可以帮助档案管理人员更好地管理和维护档案资源,其主要表现为以下三个方面:其一,通过分析档案资源的特征和属性,可以建立备份策略和冗余存储机制,监测和预测档案资源的使用情况和变化趋势,防止档案资源的丢失和损坏[3];其二,数据挖掘技术可以辅助档案管理人员进行档案完整性检查和错误修复,例如文件丢失、损坏、存储空间不足等,通过数据校验和异常检测,保障档案的完整性和可信度;其三,数据挖掘技术还可以应用于档案资源的访问控制和安全管理。通过对用户行为和权限的分析,可以建立有效的权限管理机制,保护档案资源免受未授权访问和滥用。
2 数据挖掘技术在计算机档案管理中的具体应用
2.1 数据源采集
数据源采集是数据挖掘技术中的首要步骤,主要是收集和获取原始数据。在计算机档案管理中,数据源可以包括电子文档、数据库、电子邮件、网页等各种形式。通过数据源采集,可以将这些分散的数据集成在一起,为后续的数据挖掘提供统一的数据基础[4]。
首先,需要明确计算机档案管理中所需挖掘的数据类型、格式、结构,以及使用的用途和分析目的。根据数据需求,选择适当的数据源,包括电子文档、日志文件、数据库记录等。对于电子文档数据源,使用正则表达式匹配和提取文档中的特定信息,如电话号码、邮箱、日期、整数或浮点数等。如果文档中存在自然语言文本,可以应用自然语言处理技术来进一步处理。将文本进行分词,将长的文本划分为单词或短语,然后对分词结果进行词性标注,以确定每个词的语法角色。接着,进行实体识别,识别出文档中的人名、地名、组织机构名等特定实体。在提取特定信息的过程中,借助Python的正则表达式模块re,或者使用自然语言处理库NLTK或Spacy来处理文档。对于日志文件数据源,使用ELK Stack或Splunk日志分析工具,对日志文件进行解析和分析。对于数据库记录数据源,使用SQL查询语言来抽取数据。根据具体的查询需求,编写SQL语句从MySQL数据库中读取所需的档案数据,从而高效地获取并准备好需要挖掘的数据,为后续的数据挖掘工作打下良好的基础。
2.2 数据预处理
在计算机档案管理中,数据预处理是数据挖掘过程中的关键环节,主要包括数据清洗、数据集成、数据转换和数据规约。数据预处理的主要目的是提高数据的质量,减少噪声和异常值的影响,使得数据更加适合进行数据挖掘[5]。当进行数据预处理时,按照以下具体步骤来进行。
第一步,使用Python的pandas库进行数据清洗,包括去除重复数据、处理缺失值、处理异常值和噪声数据等,用于去除数据中的噪声和错误。如果原始数据来自多个不同的数据源,使用PowerDesigner工具进行数据字段映射的设计和定义,使用ETL(抽取、转化、加载)技术,从不同的数据源中抽取数据,并进行必要的转换操作。在数据合并后,为了去除冗余数据,使用OpenRefine技术进行数据去重操作。
第二步,在数据挖掘过程中,执行相应的数据转换操作,包括数值化(将非数值型数据转换为数值型数据)、数据规范化(将数据压缩到较小的区间,如0到1.0) 、数据离散化(将连续型数据转换为离散型数据)等。同时,使用Z-score标准化方法,将不同尺度和单位的数据转换为统一的标准形式,计算公式,如式(1)
其中,X是原始数据,μ 是数据的均值,σ 是数据的标准差。通过Z-score標准化,将数据转换为以0为均值,1为标准差的标准化形式,便于不同单位或量级的指标进行比较和加权,以消除不同变量之间的量纲影响。
第三步,通过比对数据源中的某些唯一标识符或者共同字段,找到相互匹配的记录。在数据匹配的基础上,通过添加新的字段、更新现有字段或者增加新的记录,将相互匹配的数据记录进行合并,形成一个更完整的数据集。当数据源之间存在关联关系时,基于共同的字段,通过数据连接来将它们关联起来。为了消除冗余和保证一致性,删除重复的数据记录,保留最新或最完整的数据,对不一致的字段进行统一取值或修正,并将日期字段的格式统一为特定的标准格式。使用MySQL数据库管理系统来构建数据仓库,存储结构化数据、半结构化数据和非结构化数据,并支持数据的查询和分析。
第四步,通过选择部分重要特征或使用聚类等方法,将原始数据简化为更小的数据集,减少计算复杂度和提高挖掘效率。对于高维数据,可以选择维度规约方法(如PCA、LDA等)对数据进行降维处理。降维过程中,需要确定保留主成分或判别特征的个数。通过累计方差贡献率、交叉验证等方法来确定合适的主成分或判别特征数量。对于大规模数据集,可以选择数量规约方法(如抽样等)。通过简单随机抽样、分层抽样、聚类抽样等方式,减少数据样本的数量。为避免信息丢失,在实际应用中需要根据具体问题和数据特点权衡数据规约的程度。
2.3 构建挖掘模型
在计算机档案管理中,构建挖掘模型是数据挖掘技术的核心步骤,主要是通过选择合适的挖掘算法对预处理后的数据进行挖掘和分析,从而发现数据中的有价值信息。通过构建挖掘模型,可以从大量的数据中提取出有用的信息和规律,为计算机档案管理提供决策支持和业务指导。
根据计算机档案管理需求,选择和提取合适的特征,包括文本内容(分类、关键词提取和语义分析等)、作者信息(姓名、单位、职务等)、创建时间(创建日期、修改日期等)、文件类型(文件扩展名、文件大小、文件格式等)。通过对这些特征进行分析和提取,为挖掘模型提供有效的输入。选择决策树、关联规则、聚类分析等数据挖掘模型,设计合适的网络结构、层数和参数设置,确定輸入层、隐藏层和输出层的节点数目。输入层的节点数应与特征数量相等,输出层的节点数应与目标变量的类别数或维度相等。根据问题的复杂性增加一个或多个隐藏层。每个隐藏层的节点数可以根据经验公式进行设置,如式(2) 所示:
其中,nh表示隐藏层的节点数,l表示隐藏层数,ni表示输入层的节点数。使用网格搜索、随机搜索等方法,调节模型的超参数,提高模型性能和泛化能力。选择Adam优化器作为初始选择,自适应地调整每个参数的学习率,从而在训练过程中加速收敛。Adam 优化器的计算公式,如式(3) 所示:
其中,Δwt是权重参数的更新值,lr是学习率,gt 是当前时间的梯度,gt 是当前时间的平方梯度。在模型训练过程中,使用贝叶斯优化技术,通过更少的迭代找到良好的超参数配置,例如学习率、批次大小、正则化系数等。在迭代过程中,根据概率模型选择最佳参数组合,使用这个最佳参数组合更新模型。重复迭代过程,直到达到预定的迭代次数或者收敛,从而优化模型的性能。之后,使用交叉验证法,将数据集划分为多个训练集和验证集的子集,进行多次训练和验证。K折交叉验证的公式,如式(4) 所示:
将训练好的模型部署到实际的档案管理系统中,使其能够接收输入数据并生成相应的输出。在部署过程中,需要确保模型的接口与档案管理系统的接口匹配,以及模型能够顺利地与其他系统组件进行交互,实现自动分类、归档、检索等功能[6]。在模型应用过程中,需要持续监控模型的指标,包括模型的准确率、召回率、F1值等性能指标,以及模型的运行时间、资源消耗等效率指标,确保其能够稳定、有效地工作。通过Crystal Reports工具自动生成档案管理的报告,包括档案统计、趋势分析、异常报警等,以便管理员及时了解档案管理的状况。为了确保模型的稳定运行,使用Ansible配置管理工具、Nagios监控工具,实现模型运行状态的自动监控、模型参数的自动备份、运行故障的自动处理,并利用Docker 容器化技术,以及VMware、KVM等虚拟化技术,实现应用程序和服务的快速部署、扩展和管理,以适应档案管理的变化需求,从而实现档案管理的智能化、高效化和准确性。
2.4 数据可视化
数据可视化是数据挖掘技术的重要环节之一,它可以将挖掘结果以图形化的方式展示出来,让人们能够更直观地理解和分析数据。在计算机档案管理中,数据可视化可以用于展示档案的分布情况、分类结果、关联规则等。通过数据可视化,可以帮助档案管理人员更好地理解档案的特点和规律。
根据数据的类型和分析目标,选择合适的可视化图表,包括柱状图、折线图、饼图、散点图、热力图、箱线图等。例如,使用柱状图展示不同类别的档案数量,使用折线图展示档案的变动趋势等。用编程语言(如Python、R) 和相应的数据可视化库(如D3.js、ECharts) ,实现档案数据的可视化。例如,使用Python 的Matplotlib库绘制统计图表,使用D3.js库创建交互式可视化图表等,为档案数据可视化添加交互功能,如数据筛选、缩放、联动等,从而使档案数据更加生动、易于理解。合理布局可视化图表的各个元素,如坐标轴、网格线、图例、标签等,以提高图表的可读性和美观性。参考颜色映射、颜色梯度等技术,使用合适的颜色和样式来表示数据,例如根据数据的值选择不同的颜色,以强调数据的差异;使用渐变色来表示数据的大小,使图表更具立体感,以便于区分不同的数据点和类别。
在计算机档案管理中,通过合理运用各种可视化图表、元素布局、颜色样式以及交互功能,可以帮助档案管理人员更深入地了解档案数据的特点和规律,从而提高档案管理的效率和准确性。
3 结束语
综上所述,随着信息技术的快速发展,数据挖掘技术已经成为计算机档案管理中的重要工具。通过数据挖掘技术,通过数据挖掘技术,可以实现对档案数据的自动化分类、关键词提取、相似性分析、趋势预测等功能,从而提高档案的检索速度和准确性,为档案管理提供更高效、准确和全面的支持。然而,档案管理人员也需要注意数据挖掘技术的挑战和限制,合理应用和解释数据挖掘结果。相信随着技术的进一步发展和应用,数据挖掘技术将在计算机档案管理中发挥更加重要的作用,为档案管理提供更高效、准确和全面的支持。
【通联编辑:闻翔军】
猜你喜欢
大众投资指南(2021年35期)2021-02-16
经济技术协作信息(2018年22期)2019-01-19
消费导刊(2017年24期)2018-01-31
电力与能源(2017年6期)2017-05-14
科技视界(2016年20期)2016-09-29
信息通信技术(2015年6期)2015-12-26
中国卫生(2014年11期)2014-11-12
电子设计工程(2014年18期)2014-02-27
办公室业务(2014年10期)2014-02-27
