
我国上市公司信用风险评估研究——基于Logit模型的分析
2011-01-23 12:15朱新蓉
中南财经政法大学学报 2011年3期
胡 胜 朱新蓉
(1.九江学院会计学院江西九江332005;2.中南财经政法大学新华金融保险学院,湖北武汉430073)
信用风险度量与管理的探索过程大致可分为三个阶段:第一个阶段是1970年以前,主要分析工具有5C分析法、LAPP法、五级分类法,大多数金融机构基本上是依据银行专家的经验和主观分析来评估信用风险。第二个阶段是建立于基于财务指标的信用评分模型,主要有线性比率模型、Logit模型、Probity模型、判别分析模型等。第三个阶段是进入20世纪90年代以来,西方若干商业银行以风险价值为基础,开始运用数学工具、现代金融理论来定量研究信用风险,建立了以违约概率、预期损失率为核心指标的度量模型,如 Credit、Metrics、KMV模型、Credit Risk+,Po rtfolio View模型等[1](P35—46)。
我国商业银行内部的信用评级水平比较落后,信用风险度量管理体系非常不健全,对信用风险的分析仍处于传统的定性分析阶段,远不能有效满足商业银行对信用风险控制与管理的要求。国外的信用风险度量模型也有很多缺陷,如没有一个模型能够准确地度量每笔信用产品的违约率、违约下的损失等。本文拟对Logit模型在上市公司信用风险评估应用方面进行研究,以期对商业银行内部的信用评级风险有所借鉴。
一、文献综述
在国外的研究中,Logit模型最早由Martin用来预测公司的破产及违约概率。他选取5 700家样本和25个财务指标进行分析,建立了8个财务指标的Logit模型来分析公司的破产及违约概率。Ohlson也将Logit模型应用于信用风险分析[2],W ilson借用Logistic函数建立了Logit信用评分模型[3](P12—35)。
在国内研究中,建立的模型的准确率因选取样本数据的个数不同大致有两类,一类是准确率平均达到70%左右;一类是准确率高达90.0%以上。王春峰、万海晖选取129家样本建立Logit模型的第一类错误为33.33%,第二类错误为25.00%[4];方洪全、曾勇选取1 332个样本数据自己建立5参数指标Logit判别模型的第一类错误为46.56%,第二类错误为19.1%,对王春峰等所建立的6参数Logit模型验证时的第一类错误达38.55%,第二类错误为27.39%;李萌选取195家上市公司客户建模的第一类错误超过30%,第二类错误是9.1%[5];顾乾屏、孙晓昆通过2.5万样本建立一个两阶段非线性变量边界Logit模型的第一类错误高达21.52%,第二类错误达12.47%[6]。上面的研究文献中Logit模型犯第一类错误平均达到30%左右。
也有部分研究者的总体准确率高达90.0%。庞素琳选取63家上市公司建立Logit判别模型判别准确率达到99.06%[7];贺刚选取由2001~2004年深沪两市106家上市公司建立Logit模型总体正确预测率达到98.1%;李关政、彭建刚从经济周期和经济转型两个方面引入系统性风险因子分14个行业建立14个拟合Logit模型,总体准确率均在90%以上,其中有10个总体准确率为100%[8]。我国2010年沪深主板上市公司1 500家左右,故笔者分析其每个行业方程建模样本应当不会超过120个。这些研究如此高的准确率从建模的样本看应不符合Logit模型建立的样本要求,他们建模的样本有100个左右,Logit模型样本数量不宜少于200个,故90.0%以上准确率可靠性值得进一步分析。
二、模型构建以及实证研究
(一)Logit模型基本原理
Logit模型是解释变量为二分变量,即违约与非违约,采用极大似然估计的选代方法找到“系数”的“最可能”估计。设P表示贷款发生的概率,xi是能够影响贷款是否违约的解释变量,假设ε服从Logistic分布,其分布函数为:F(x)=1/(1+e-x),则有:

Logit回归模型则可表示为:Logit(P)=∂+β1x1+…+βkxk
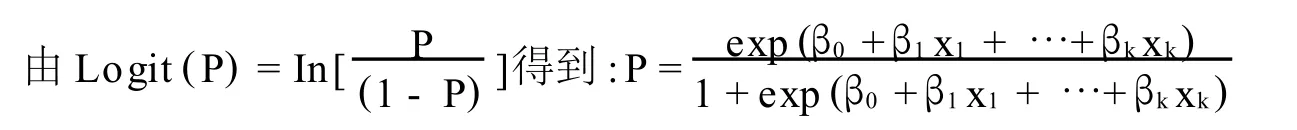
通过最大似然法可以得到参数列β0,β1…βk的估计值,将参数估计代入Logit模型中可以测出各贷款的违约概率:

Logit模型主要优点是可以无需像判别分析那样假设多元正态性并具有相同的协方差矩阵。但其在估计上也存在缺陷,如模型本质假设不合理,不具可加性;样本数量不宜少于200个,否则参数估计是有偏的;中间领域的判别敏感性较强,导致判别结果不稳定性等,需要运用时加以注意。在统计学中,误判分为两类,第一类错误(type Ierro r)称为“拒真”,在信用风险评估中,第一类错误是指将高信用风险企业误判为低信用风险企业的错误。第二类错误(type IIerror)称为“纳伪”,是指将低风险企业误判为高信用风险企业的错误。
(二)样本的选取
本文选取的数据来源是巨灵金融终端数据库。选取2007年沪深主板1 280家上市公司股票。样本的选取分为两类模式,即选取正常公司和非正常公司。正常公司由非ST公司构成,代表财务正常、低信用风险公司。非正常样本组成ST公司来构建,代表陷入财务困境、高信用风险公司。ST公司是我国从1998年4月22日起实行的表示出现财务状况或其他状况异常的上市公司。ST公司表示经营连续2年亏损,特别处理;*ST公司表示经营连续3年亏损,退市预警。数据样本分为两部分:训练样本集和测试样本集。训练样本集由874家正常公司和116家ST公司组成。测试样本集由250家正常公司和40家ST公司组成。
(三)指标的选择
本文在借鉴国有商业银行资信评比指标体系及国内外有关文献的有关指标,选取了28个财务指标。其选择依据主要从以下3个方面考虑:(1)数据有效性,选择那些能够对预测公司信用风险具有重要指示作用的财务比率。(2)数据全面性,即能够全面反映上市公司的经营状况与发展能力。(3)数据可获得性。具体指标见表1。

表1 财务指标表
(四)模型分析
对训练样本集采取向前逐步选择法,运用SPSS13.0软件得出如下的结果:

表2 参数估计和最终模型的统计量
根据上表分析,可以建立如下模型:
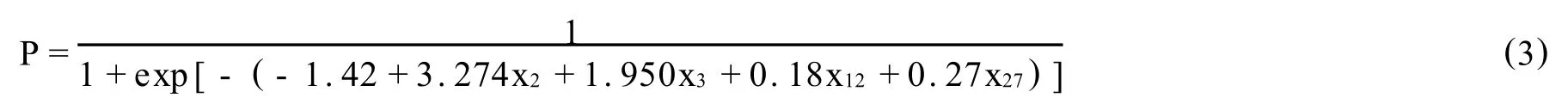
本模型结果表明,一个公司是否违约与公司基本面情况、现金流量分析、发展能力有重大联系。其选中的指标是扣除经常性损失后的每股收益(x2)、每股净资产(x3)、现金债务总额(x12)、总资产同比增长率(x27),这些指标都通过参数检验,模型整体检验都比较显著有效。将模型(3)对测试样本数据进行分析得到如下结果:
从表3分析中可以看出,对正常公司是识别准确率为98.4%,即犯第二类错误仅为1.6%。该模型犯第一类错误较高,达到30%。将“ST公司”判为“正常公司”比例较高。笔者进一步细查40个“ST公司”中判断为正常公司的具体公司如下表:
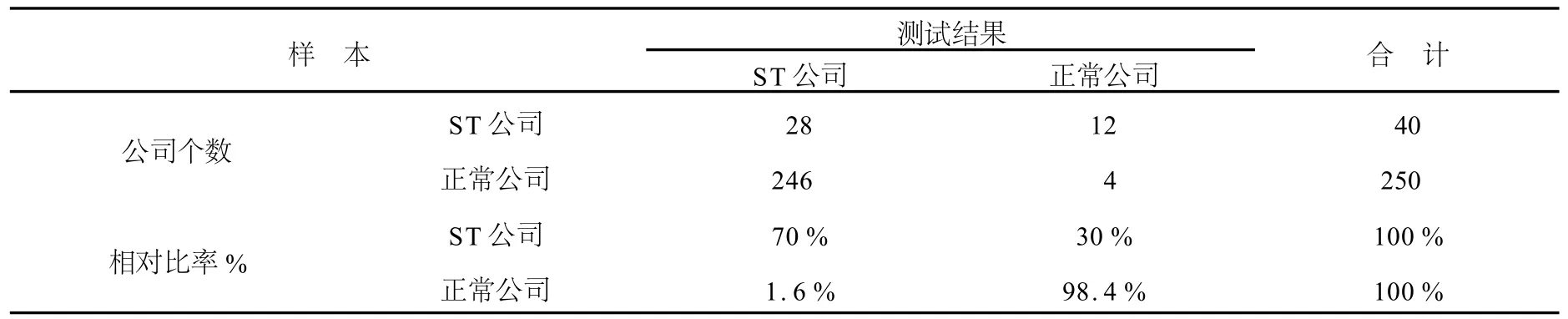
表3 Logit模型对预测样本的判别结果

表4 Logit将ST股票判为非ST股票结果
上表分析中可以看出,该模型将“ST公司”误判“正常公司”共有12个,其中还有5个是有退市风险的*ST公司,同时将5个处于严重财务困境的公司(即很高信用风险企业)误断低信用风险企业。
三、简要结论和启示
本文基于我国上市公司数据建立的Logit模型,研究发现,基于该模型商业银行对上市公司信用风险评估时犯第一类错误达到30%。对于银行来说,第一类错误即将高信用风险企业误判为低信用风险企业是可怕的,有时对银行是致命的。结合上述符合合理建模样本的相关文献研究犯第一类错误平均达到30%左右,可以得出我国商业银行在实际运用Logit模型对有业务来往的上市公司企业乃至非上市企业进行信用风险要十分谨慎使用,或只参考使用,要结合新巴塞尔协议,综合运用元判别线性模型、Logit模型、KMV模型,积极推进IRB基础数据库和管理信息系统(M IS)建设等各方面工作,建立内部信用评级,对企业信用风险进行合理评估。
[1]李志辉.现代信用风险量化度量和管理研究[M].北京:中国金融出版社,2001.
[2]Ohlson,J.S.Financial Ratios and the Probabilitistic Prediction of Bankruptcy[J].Journal of Accounting Research,1980(1):109 —131.
[3]乔埃尔.贝西斯.许世清,等,译.商业银行风险管理——现代理论与方法[M].深圳:海天出版社,2001.
[4]王春峰,万海晖.商业银行信用风险评估及其实证研究[J].管理科学学报,1998,(1):68—72.
[5]李萌.Logit模型在商业银行信用风险评估中的应用研究[J].管理科学,2005,(4):34—36.
[6]顾乾屏,孙晓昆.信用风险的两阶段非线性变量边界Logit模型实证研究[J].系统管理学报,2008,(12):680—685.
[7]庞素琳.Logistic回归模型在信用风险分析中的应用[J].数学的实践与认识,2006,(9):129—137.
[8]李关政,彭建刚.经济周期、经济转型与企业信用风险评估——基于系统性风险的Logistic模型改进[J].经济经纬 ,2010,(2):88—90.
猜你喜欢
化工管理(2022年13期)2022-12-02
中国信用(2022年4期)2022-09-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
大众投资指南(2020年10期)2020-07-24
中国交通信息化(2018年5期)2018-08-21
消费导刊(2017年20期)2018-01-03
当代经济(2016年26期)2016-06-15
当代经济(2015年4期)2015-04-16
