
基于向量机学习算法的多模式分类器的研究及改进
2013-09-20 06:05柳长源毕晓君韦琦
电机与控制学报 2013年1期
柳长源, 毕晓君, 韦琦
(1.哈尔滨工程大学信息与通信工程学院,黑龙江哈尔滨 150001;2.哈尔滨理工大学电气与电子工程学院,黑龙江哈尔滨 150080)
0 引言
支持向量机(support vector machine,SVM)是上九十年代中期由Vapnik提出的一种基于统计学习理论的一种机器学习算法[1-2],该方法比神经网络具有更好的泛化能力,在小样本模式识别中也优于神经网络。相关向量机(relevance vector machine,RVM)是Tipping在2000年最早提出的一种基于贝叶斯估计理论的机器学习方法,适用于函数回归和模式分类问题[3]。该方法与SVM算法类似,但比后者解空间更稀疏,鲁棒性也更好[4]。这两种方法的共同目标是通过对样本数据进行机器学习和训练,找到一个最优的“超平面”方程作为分类面(实际就是求超平面方程的各阶次系数),把待识别样本数据分化在超平面两侧,从而实现两类别模式识别。
然而,在科学研究和工程技术中经常遇到需要将待识别模式分成多类别的情形。比如,在故障检测中通常不只是判断系统是否存在故障,还需要判断出存在哪一类故障[5-7];在人脸识别中要判断待识别的图像来自哪个人的面孔[8-9];在语音识别中要判断待识别的声音信号来自哪个人的声音[10-11]。为此有人提出用多个分类器组合的方式实现数据的多类别分类[12],其中最著名的有“一对一”法、“一对多”法和“二叉树”法3种。这3种方法中,目前应用最广泛的方法,也是分类正确率最高、鲁棒性和泛化能力最好的方法是“一对一”投票法,这种方法在训练样本较少时依然有效,但由于需要k(k-1)/2个RVM二分类器,该方法在类别数很多的情况下运算量很大。为此本文提出了一种可用于SVM或RVM机器学习算法的多类别模式识别方法该方法能够在保证分类精度的前提下,解决了“一对一”分类方法中运算量大、分类速度慢的问题,使其在实时性方面有了大幅度的提高。
1 基于向量机的二分类算法
对于二分类问题,设训练样本集合为(xn,tn)(n=1,2,…,N,x∈Rd,t∈{0,1}是类别标号),向量机的分类函数定义[13]为
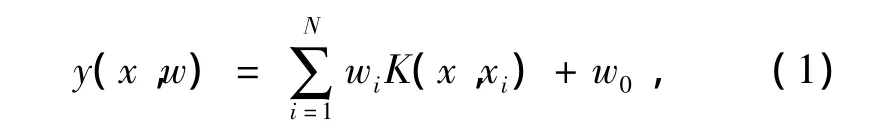
式中:K(x,xi)是核函数;wi是模型的权值。SVM和RVM分类方法都是通过一组训练样本求得权值wi。经过多次迭代更新,大多数训练样本相应的wi为零,不为零的wi所对应的训练样本称为支持向量(support vector,SV)或相关向量(relevance vector,RV)。相应的基函数因此可以“修剪”,实现稀疏性。由相关向量确定的分类函数是一个高维“超平面”,求得超平面方程,该平面把待测样本划分成两个区域,从而实现二类别模式识别问题。
2 “一对一”多模式分类器
“一对一”方法可利用二分类的机器学习算法实现多类模式识别[14]。此多分类算法每次只考虑两类样本,即对各模式类中每两类样本都设计一个二分类向量机模型,这样区分k个类别共需要设计k(k-1)/2个二分类器。当需要对一个新测试样本进行分类时,首先要利用训练样本对所有k(k-1)个二分类向量机模型进行训练,每一个二分类模型训练后立即对测试样本进行判别,对它所隶属的类别进行投票。若待测试样本属于第i个类别,则第i类将获得最多的票数,最终将票数最多的类判断为此测试样本的类别。
设分类函数fij(x)用来判别i,j两类样本,若fij(x)<0,则判x属于第i类,记i类得一票,否则判x属于第j类,记j类得一票,最后在决策时,比较哪一类得到的票多,则将测试样本划归为该类。该算法的基本结构如图1所示。
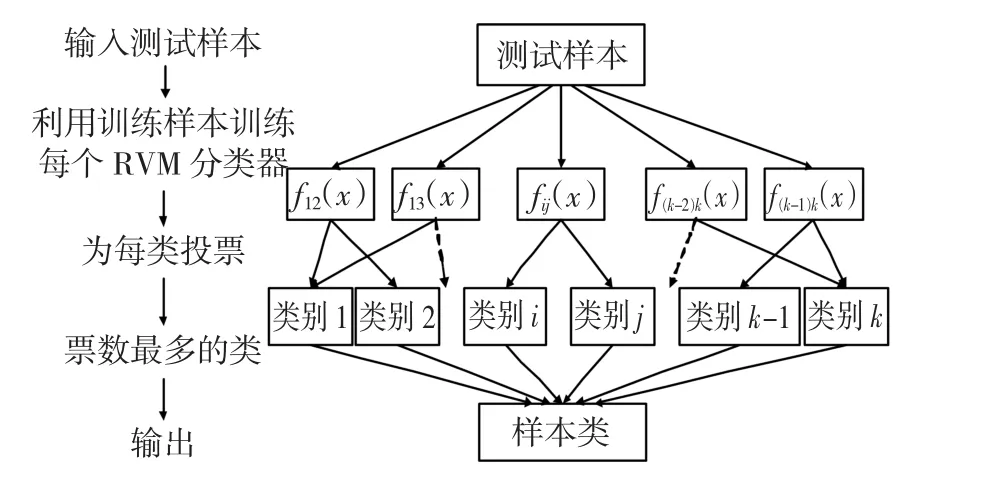
图1 基于RVM的“一对一”算法Fig.1 “one against one”algorithm based on RVM
因为每个类别都参与了k-1次比较,从理论上讲,如果每次判别结果都正确没有误差,那么待测试样本所在的模式类应该得到k-1票。其他类别在与正确类比较时得不到票数,但与其它不相关的类别比较时,得票被分散在各类中,任意两不相关类得票概率相同,每类平均得票数应该在(k-2)/2左右,当k比较大的时候,即使有一小部分二分类器输出错误结果,也能使正确类别得到最多的投票数,所以这种方法的分类精度高,鲁棒性也很好。唯一的缺点是二分类器个数比较多,运算速度比较慢。
3 改进后的新分类器设计
为解决“一对一”分类器运算量大的问题,对其算法结构进行了改进,提出了一种新的基于向量机算法的多类别分类器。原分类方法比较次数与类别数的关系按k(k-1)增长,而新分类方法比较次数近似与类别数k呈线性增加。类别越多,新方法优势越明显。当k比较大的时候,即使有一小部分RVM分类器输出错误结果,也能使正确类别得到最多的投票数,所以这种方法不仅运算量小,分类精度可保证,鲁棒性也很好。
图2以5个类别的模式识别为例,给出了所提出的多类别分类器的结构原理图。
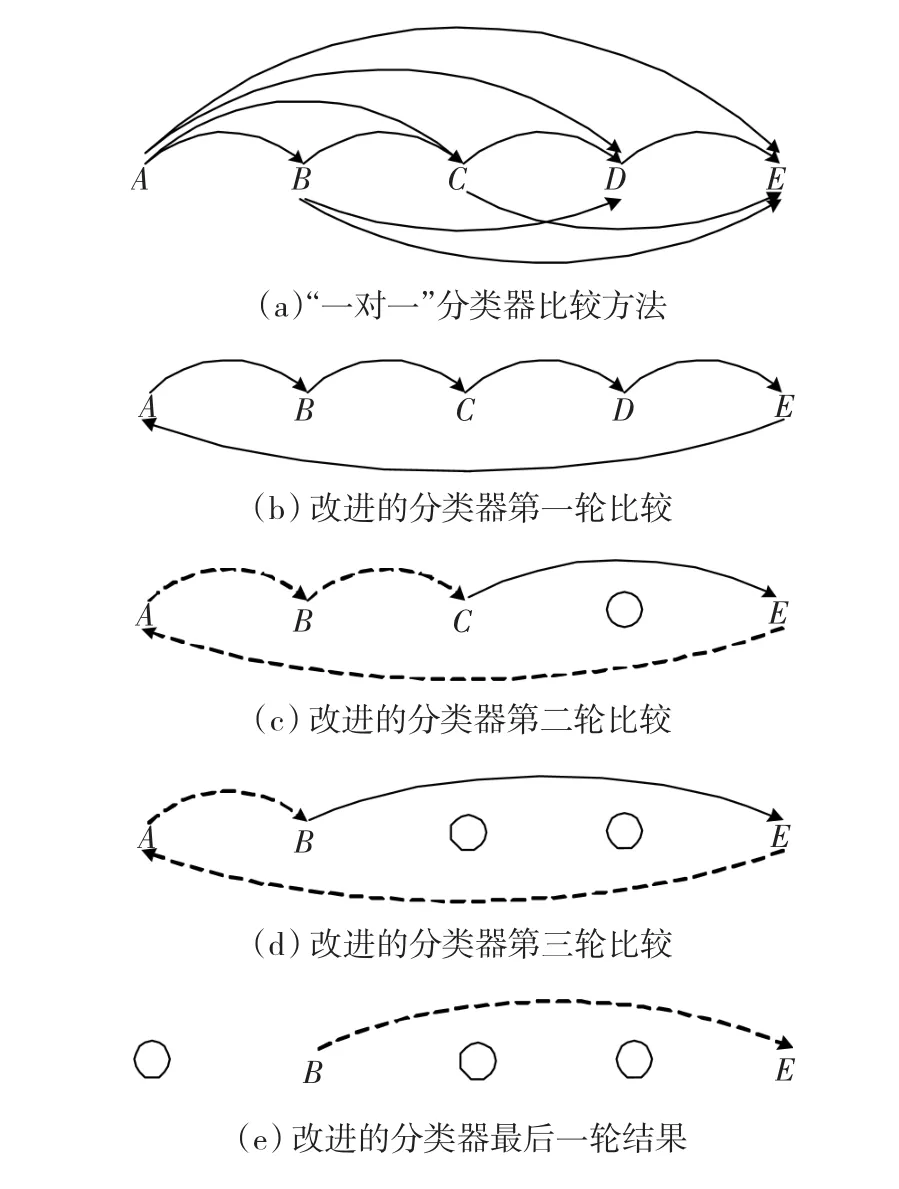
图2 改进的5类别分类器结构原理Fig.2 The schematic of improved 5 kinds classifier
图2(a)是传统的“一对一”循环方式,每两个类别都需要一个向量机分类器,训练识别次数为k(k-1)/2。为了减少运算量,提出的方法采取“最低票淘汰”的方式,每一轮不是把所有每一对类别都两两比较,而是各类单循环相邻比较,去掉每轮中得票最低的模式类别,然后进行下轮比较。
图2(b)是改进算法的第一轮比较,设D为得票最少的模式类,这样第二轮比较只需要对CE两类进行单独训练识别,其余类别数据沿用上一轮结果,如图2(c)。各类两轮票数相加后,假设C为本轮后得票最少的模式类,图2(d)是去掉C后的下一轮分类,只需要对BE两类别再判别,其它类别票数也是沿用原来结果。假设本轮累计统计票数后A又被淘汰,如图2(e)所示,此时无需再进行新的比较,只需要留下之前BE分类中得票高的模式类,即是模式识别结果。这样例子中的5类识别只需要7次二分类判别(当然考虑到每轮淘汰的不确定性,也可能为8次),而“一对一”法需要(5×4)/2=10次。当类别数k更多时,二者差异更加明显。如k=40时,“一对一”法需要(40×39)/2=780个分类器,而新方法在实验中得到的平均数据是53.4个,运算量比前者减少了一个数量级。
4 仿真实验与结果分析
4.1 多维目标函数不同类别数量的数据分类识别仿真实验
所有实验在硬件配置为Intel Centrino Duo,CPU:T7250、2G内存、2.70GHZ主频的计算机上进行,程序采用Matlab R2008a编写。
采用SVM算法,改变不同的类别数k值,每个k值经过50次这样的仿真实验,分类时间取每次程序运行平均值,并统计出分类正确的百分比。比较传统的“一对一”分类器和改进后的分类器得出的实验数据如表1所示。
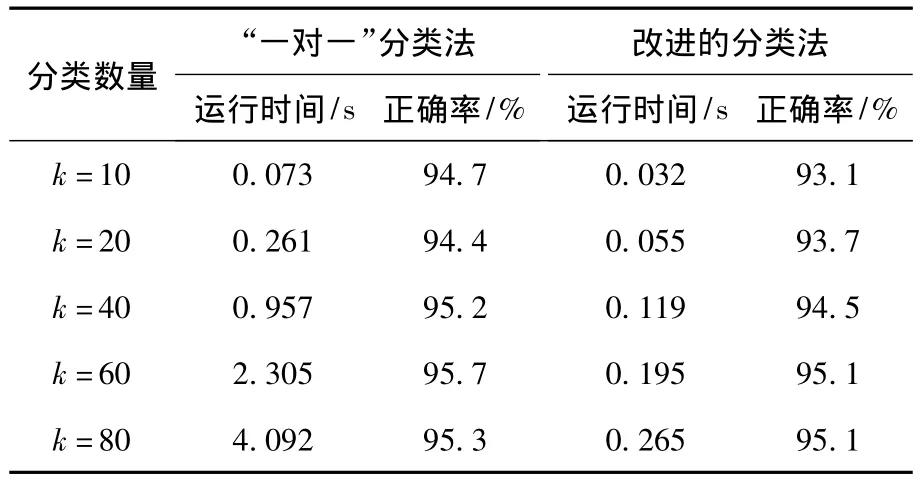
表1 基于SVM算法的分类器实验数据Table 1 The experimental data of classifier based onSVM algorithm
上述实验条件不变,改用RVM算法,再对比做不同k值得仿真实验,得到的数据如表2所示。
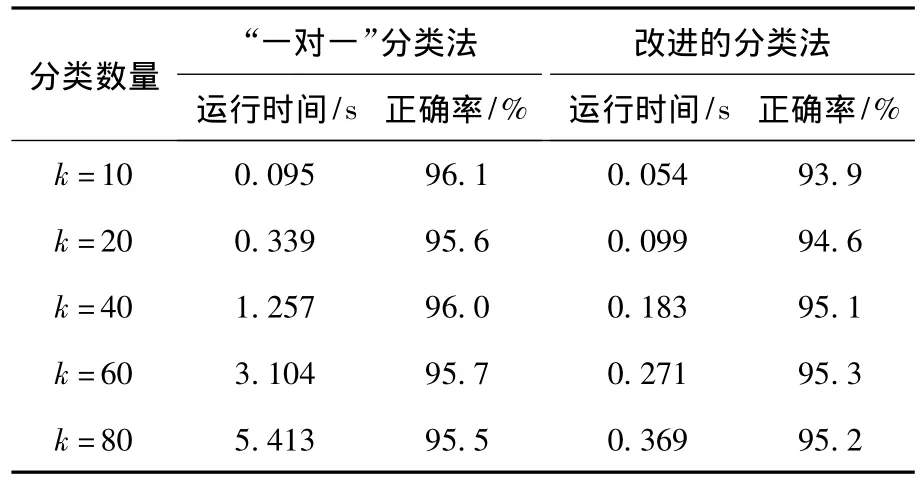
表2 基于RVM算法的分类器实验数据Table 2 The experimental data of classifier based on RVM algorithm
为了更清楚比较分类器改进前后的模式分类效果,把程序运行平均时间和识别正确率分别用图3和图4表示。

图3 分类器改进前后程序运行时间比较Fig.3 The comparison of program running time pre and post improving classifier
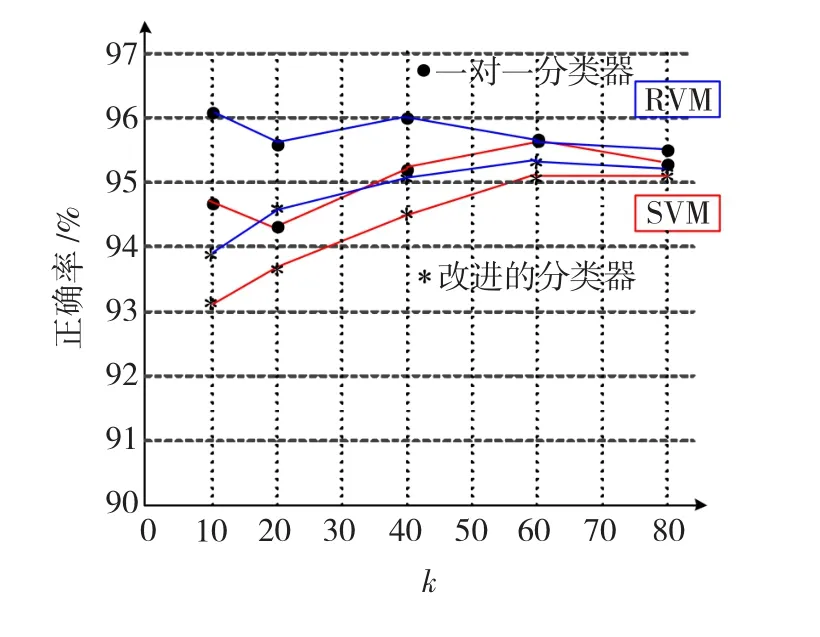
图4 分类器改进前后分类正确率比较Fig.4 The comparison of accuracy pre and post improving classifier
从图3可以直观看出,无论采用SVM还是RVM算法,改进算法的程序运行时间都有显著缩短,而且类别数越多,这种效率的提升越明显。改进后的运行时间与类别数近似线性增加,增加速率比改进前大大提高。
从图4中的数据不难发现,改进算法的分类正确率虽略低于原始算法,但两者的差别不大。当k>20时,改进后的新方法与“一对一”分类正确率相差不超过1%,当类别数足够多时,二者识别正确率几乎相同。
4.2 不同目标函数40组类别数据分类识别仿真实验
为了进一步验证改进方法的可推广性,选择几个有代表性的标准测试函数进行分类实验。函数的自变量及其对应的函数值为一个数据样本,在每个函数的定义范围内随机产生400个数据样本,按函数值的范围不同区分把这400个数据分成40个区间,每个区间内的10个样本形成一个数据类别。这样每个函数都可以产生40类数据样本,把每一类数据的前5个样本作为向量机学习算法的训练样本,后5个样本用来测试训练后向量机模型的分类识别正确率。
4个测试目标函数如下:
1)sqr(x):平方根函数,实验变量范围取0<x<10;2)lg(x):常用对数,实验变量范围取0<x<10;3)exp(x):以e为底的指数函数,实验变量范围取-5<x<5;4)th(x)双曲正切函数,实验变量范围取-1<x<1。
实验结果如表3所示。
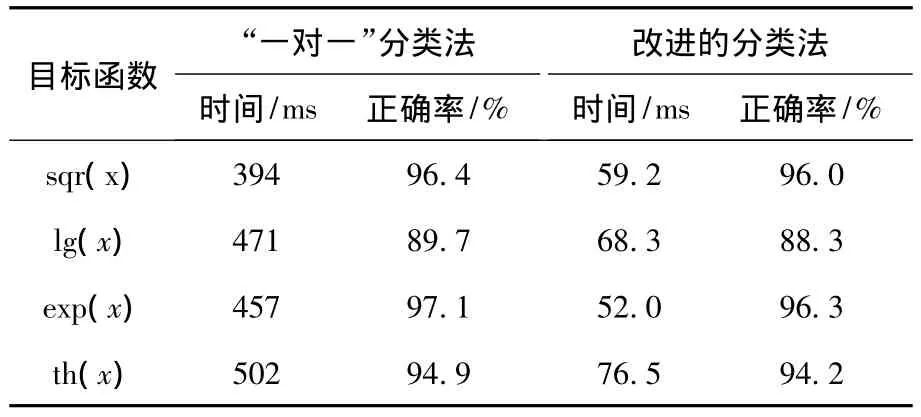
表3 用标准函数测试改进的分类器Table 3 Testing improved classifier using the standard function
从表中数据可以看到,针对不同的测试函数,算法改进前后识别率变化不大,程序运行时间均有显著提高。这表明改进后的方法对目标函数不敏感,鲁棒性很好。因此该方法具有可推广性,能满足不同应用中提高模式识别软件实时性的需要。
5 结语
本文提出了一种可用于SVM或RVM机器学习算法的多类别模式识别方法,该方法在现有的泛化性能、分类精度和鲁棒性最好的“一对一”投票法基础上进行了新的改进,并按照“最低票数轮次淘汰”的方式逐步逼近正确解。仿真实验表明,该方法在基本不降低分类精度的前提下,运算量有明显下降,特别是在类别较多的模式识别问题中,这种方法更是显著地节约了程序的运行时间,提高了多类识别的工作效率。在模式类别数很多的实际应用中,该方法可以大大提高分类识别效率,具有一定的应用价值。
[1]VAPNIK V.The Nature of Statistical Learning Theory[M].New York:Springer,1998.
[2]VAPNIC.统计学习理论的本质[M].张学工,译.北京:清华大学出版社,2000.
[3]TIPPING M E.Sparse Bayesian Learning and the relevance vector machine[J].Machine Learning Research,2001:211-244.
[4]IOANNIS Psorakis,DAMOULAS Theodoros,MARK A,et al.Multiclass relevance vector machines:sparsity and accuracy[C]//IEEE Transactions on neural networks,2010,21(10):1588-1598.
[5]陶新民,徐晶,杜宝祥,等.基于相空间RVM的轴承故障检测方法[J].振动与冲击,2007,25(12):1-7.
TAO Xinmin,XU Jing,DU Baoxiang,et al.Bearing fault detection based on RVM using phase space[J].Journal of Vibration and Shock,2007,25(12):1-7.
[6]马笑潇,黄席褪,柴毅.基于SVM的二叉树多类分类算法及其在故障诊断中的应用[J].控制与决策,2003,18(3):272-276.
MA Xiaoxiao,HUANG Xitui,CHAI Yi.2PTMC classification algorithm based on support vector machines and its application to fault diagnosis[J].Control and Decision,2003,18(3):272-276.
[7]卢迪,窦文娟.遗传优化支持向量机在失火故障诊断中的应用[J].哈尔滨理工大学学报,2012,17(1):36-38.
LU Di,DOU Wenjuan.Fault diagnosis of engine misfire based on genetic optimized support vector machine[J].Journal of Harbin University of Science and Technology,2012,17(1):36-38.
[8]谢赛琴,沈福明,邱雪娜.基于支持向量机的人脸识别方法[J].计算机工程,2009,35(16):186-188.
XIE Saiqin,SHEN Fuming,QIU Xuena.Face recognition method based on support vector machine[J].Computer Engineering,2009,35(16):186-188.
[9]聂会星,梁坤,徐枞巍.基于小波变换和支持向量机的人脸识别研究[J].合肥工业大学学报:自然科学版,2011,34(2):208-211.
NIE Huixing,LIANG Kun,XU Zongwei.Face recognition based on wavelet transform and support vector machine[J].Journal of Hefei University of Technology:Natural Science Edition,2011,34(2):208-211.
[10]杨成福,章毅.相关向量机及在说话人识别应用中的研究[J].电子科技大学学报,2010,39(2):311-315.
YANG Chengfu,ZHANG Yi.Study on speaker recognition using RVM[J].Journal of University of Electronic Science and Technology of China,2010,39(2):311-315.
[11]高争艳,张玉双,王慕坤.基于核K-均值聚类和支持向量机结合的说话人识别方法[J].哈尔滨理工大学学报,2008,13(5):40-42.
GAO Zhengyan,ZHANG Yushuang,WANG Mukun.Speaker recognition using kernel K-mean clustering and SVM[J].Journal of Harbin University of Science and Technology,2008,13(5):40-42.
[12]KREBEL U.Pairwise classification and support vector machines[C]//Advances in Kernel Methods:Support Vector Learning.Cambridge,MA:The MIT Press,1999:255-268.
[13]BOTTOU L,CORTES C,DENKER J S,et al.Comparison of classifier methods:a case study in handwriting digit recognition[C]//International Conference on Pattern Recognition.Newyork:IEEE Computer Society Press,1994:77-87.
[14]SCJWEMLER F.Hierarchical support vector machines for multiclass pattern recognition[C]//Fourth International conference on Knowledge-Based Intelligent Engineering Systems&Allied Technologies.Brighton,UK:IEEE Press,2000,2:561-565.
猜你喜欢
民族古籍研究(2018年1期)2018-05-21
中成药(2017年10期)2017-11-16
计算机应用(2017年4期)2017-06-27
智能系统学报(2017年5期)2017-01-22
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
新校长(2016年8期)2016-01-10
海军航空大学学报(2015年1期)2015-11-11
浙江大学学报(工学版)(2015年1期)2015-03-01
智能系统学报(2015年3期)2015-01-29
