
多模态视频语篇的分析模式研究
2013-12-21 09:19王正
东北师大学报(哲学社会科学版) 2013年1期
王 正
(绥化学院 外国语学院,黑龙江 绥化152000)
随着科学技术的高速发展,视频语篇(video text)已经成为人们交流和传递信息的最重要手段之一,语言学界也已经开始关注对视频语篇的研究。由于视频语篇的复杂性和特殊性,以及现有语言学理论的局限性,使得对于视频语篇的分析目前还存在很多困难。
一、现有的视频语篇分析模式和不足
目前国内外对视频语篇的分析模式主要有以下3类,这3类不同的分析模式对视频语篇有着不同的定性描述。
第1类是以Baldry和Thibault,Vanluween,O'Halloran等为代表的社会符号学派对于视频语篇的分析模式,其主要理论基础是Halliday创立的系统功能语言学。这种分析模式的操作方法是将视频语篇转录成为图片和文字,然后以功能语言学的语域、衔接等相关理论以及Cress &Vanluween的视觉语法为基础进行分析[1][2]。在社会符号学派的分析模式下,视频语篇的本质看作是图片的连续体(包含音频),当连续的图片伴随音频以一定的频率播放(例如48帧/秒),就形成了连续的动态的视频语篇。
第2类针对视频语篇的分析模式,是Norris在Scollon的介入性语篇理论(Mediated Discourse Theory)的基础上建立的多模态分析框架[3]。Norris的分析模式关注的是人们在现实世界中交流时的交互行为(human interaction)[4],并非针对视频语篇,但是她的分析资料是通过视频录像捕捉到的,所以可以把Norris的分析模式也看作是针对视频语篇的研究。在这种分析模式下,视频语篇的本质被看作是社会交互行为(social interaction),对社会交互行为的分析等同于对视频语篇的分析。
第3类视频语篇的分析模式是我国学者顾曰国所建立的分析模式,其主要理论基础也包括Scollon的介入性语篇理论,还有其本人对现场即席话语(situated discourse)的研究[5],以及 Argyle et al.对社会情境(social situation)的研究[6]。顾曰国提出从内容层和媒介层两方面来分析多模态语篇,从社会语境入手,将多模态语篇(视频语篇)分为社会心理层和个人行为层,前者从上至下包括社会情境、活动类型和任务/插曲;后者包括谈话、行为和言外行为的韵律单位[7]。此种分析模式把视频语等同于社会情境,认为对视频语篇的分析等同于对社会情境的分析。
以上三种分析模式,对视频语篇的定性描述和分析各有其侧重点和不足之处。社会符号学分析模式把视频语篇的本质被看作是图片的连续体,只关注对视频语篇表现形式的分析,而忽略了本质和内容;在Norris的分析模式下,视频语篇的本质被看作是社会交互行为,对社会交互行为的分析等同于对视频语篇的分析,此种模式局限于内容是人的活动的视频语篇;顾曰国的分析模式把视频语等同于社会情境,忽略了社会情境在转换成视频语篇过程中发生的变化,也就是社会情境的重新语境化过程。
二、对视频语篇重新进行定性描述
任何进入摄像机镜头范围内的客观世界中存在的一切,从人的活动到自然风景,再到微观世界中的分子、原子等,都可能会被镜头记录下来,形成一个包含音频的视频文件,播放出来就是一个视频语篇。视频语篇还可以是形象化的主观世界的内容,例如人工制作的动画片等。由于视频语篇的复杂性和特殊性,对其进行系统的定性描述是进行分析的第一步。
一个视频语篇的物质载体首先是一个存储在电脑硬盘或其他媒体中的一个数字化的视频文件,当这个数字化的文件通过电脑、电视机或手机等媒介播放出来后就形成了包含音频的动态视频,视频的直观表现形式是连续播放的图片,通过图片的内容我们可以确定其中的参与者的具体行为,而不同的参与者及其具体行为和场景就构成了一个具体的社会情境,这个具体的社会情境可以看作是视频语篇的本质,作为视频语篇本质的社会情境通常会经过重新语境化的过程。所以描述一个视频语篇应该从不同的层次上进行。我们从层次划分的角度对视频语篇作了以下的定性描述:视频语篇包括本质、内容、形式和载体四个层次;视频语篇的本质是重新语境化的社会情境,内容是社会行为,形式是连续播放的图片,载体是数字化文件(见图1)。视频语篇的每一层次之间的关系是体现关系(realization)。社会情境由社会行为体现,也就是社会情境的性质取决于其中的社会行为形式;社会行为需要通过其表现形式确定,也就是要通过连续的图片中的内容所体现;而视频图像中的内容最终取决于硬盘等媒介中储存的数字化视频文件所记录的内容。如果要充分的描述一个视频语篇,就要由本质到载体逐层进行分析和描述。
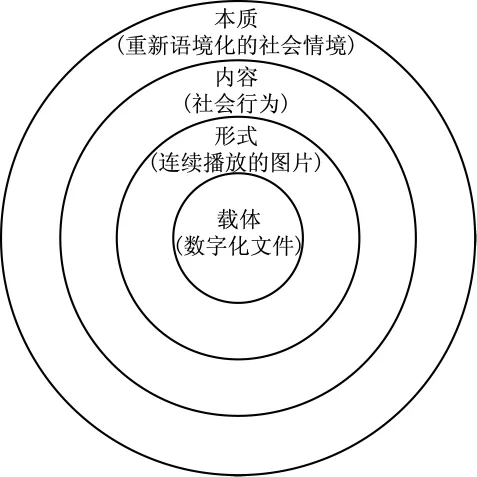
图1 视频语篇的层次模型
根据以上的层次模型,在现有的视频语篇的分析模式中,符号学派针对的是视频语篇表现形式层的分析,Norris的交互活动分析模型针对的是视频语篇的社会行为层,而对于视频语篇的载体的分析属于计算机科学领域的研究,下面着重探讨目前研究很少涉及的视频语篇的本质层的分析模式。
三、视频语篇的本质是重新语境化的社会情境
(一)社会情境(social situation)
社会情境这一概念在前面提到的第三类分析模式中已经涉及。在顾曰国建立的多模态语篇的分析框架下,社会情境这一概念只是指内容是有人参与的社会接触(social encounter)的视频语篇,而没有包括那些内容不包括人和人的行为或社会接触的视频语篇,例如内容是自然风景、动物等的视频语篇。
本文在使用社会情境这一概念对视频语篇进行定性描述时其内涵意义有所变化和扩大。
我们认为任何视频语篇都可以被看作是社会情境,包括那些内容不是人的行为或社会接触的视频语篇。因为任何视频语篇都是社会化了的内容。例如一个内容完全是自然风景的视频,其第一步的社会化过程就是摄像师的操作过程——摄像师调整镜头的角度、焦距,选择摄入到镜头范围中的内容。另外如果这段视频是一段电视节目,那么社会化的过程还可能包括在制作视频的过程中的导演、剪辑人员等其他参与节目制作的成员的工作。所以,任何视频语篇都是一个社会化的产物,我们可以把其内容的本质看作是社会情境。作为视频语篇本质的社会情境是被重新语境化了的社会情境。
(二)重新语境化(recontextualization)
视频语篇的社会化过程也就是社会情境的重新语境化的过程。
视频语篇的重新语境化过程发生在3个层面:(1)摄影师有选择的对视频内容进行录制;(2)视频制作者对视频语篇进行编辑,例如镜头的剪切、组合、特效处理以及加入背景音乐和画外音等;(3)不同的社会情境重新组合在一起共同形成一个新的整体的视频语篇。
一个视频语篇,可以是关于同一个社会情境的内容,也就是一个完整的社会接触,例如“我们约会吧”这一类的电视节目。但更多的情况是一个视频语篇包括多个社会情境,也就是多个社会接触。例如“焦点访谈”节目,包括主持人在演播室,记者在现场对当事人采访等多个社会接触,也就是多个社会情境。这些不同的社会情境重新组合,共同构成焦点访谈这一个视频语篇整体。所以社会情境在同一个视频语篇中重新组合也是社会情境的重新语境化的过程。
(三)作为系统的视频语篇的社会情境层
综合了Argyle et al.对社会情境的研究和顾曰国的分析模式,本文认为视频语篇的社会情境层是一个系统,包括6个变量:目标(Goals)、参与者 (Participants)、活 动 (Activities)、架 构(Schema)、地点(Place)和时间(Time)。一个视频语篇的社会情境层可以同时包含这六个变量,也可以只包含其中一个或几个变量。
视频语篇本质层对变量的选择,取决于视频语篇的内容层。不同内容的视频语篇其本质层所包含的变量也不同。内容不包括人的活动的视频语篇只包含地点和时间两个变量,例如一个自然风景的短片。而内容是有人参与的社会接触的视频语篇则包括更多的变量。如果内容是一个社会接触片段,例如偶然拍摄的突发事件的视频语篇,那么其社会情境层可能只包括活动、参与者、地点和时间四个变量,如果内容是一个完整的社会接触的视频语篇,除了包括活动、参与者、地点和时间以外,还包括目标和架构,也就是六个变量全部包括。
(四)以“我们约会吧”节目为例对视频语篇的社会情境层进行分析
下面我们以“我们约会吧”这个电视节目为例对视频语篇的社会情境层的六个变量进行初步分析。
1.目标
社会情境首先是以目标为导向的。作为社会情境的“我们约会吧”节目包括三个层次的目标。第一层次的目标是:要赢得高收视率,以提高湖南电视台的影响力。第二层次的目标是节目本身的目标:为男女嘉宾提供一个浪漫的舞台,帮他们找到理想的约会对象。第三层次的目标是节目参与者的目标:参与节目的男女嘉宾的目标是展示自己、找到理想的约会对象;观众的目标是亲身体验和观赏节目;主持人的目标是:控制节目现场,使节目按步骤顺利进行等。
2.参与者
参与者就是社会情境活动的主体。“我们约会吧”节目的参与者主要有四类:主持人、男女嘉宾、观众和节目的工作人员(摄像师、音响师、灯光师等)。为了实现社会情境的目标,每一类参与者都有不同的角色(role),参与者的行为受到角色的约束。例如:男女嘉宾要按照节目规则在台上选取自己的约会对象;观众在舞台下面观看节目录制,在适当的时候鼓掌欢呼;节目的工作人员进行现场节目录制等。
3.活动
活动是指社会情境中参与者的活动。“我们约会吧”节目的社会情境中有两类活动同时进行:第一类活动是主持人和男女嘉宾以及节目中的观众等的活动,这些是节目的直接参与者的活动;第二类是节目的工作人员所进行的活动,例如:摄像师拍摄节目,音响师为节目提供音响效果,灯光师进行照明等。两类活动同时进行但作用和地位不同,第一类活动是主体的,第二类活动是辅助的。
4.架构
架构是指为实现社会情境的目标社会活动所必须要遵循的程序和规则。以“我们约会吧”节目为例,主持人、男女嘉宾以及特邀嘉宾等参与者必须按照节目的规则,即架构展开活动。
如果要实现“我们约会吧”节目这个社会情境的目标,那么参与者必须按照节目的规则即架构展开活动。
5.地点
地点是视频语篇社会情境层的重要方面。地点是指社会情境中的社会活动发生的具体场景。地点对社会情境中的活动有着重要的促进和控制的作用[8]。“我们约会吧”节目这个视频语篇本质层的地点就是节目拍摄的演播厅。演播厅接近圆形,主体部分是舞台,高出其他部分约50厘米,两侧是观众席位,特邀嘉宾的席位在舞台右侧。演播厅这种结构设计对社会情境中的活动和个体行为起到重要的促进和控制作用。例如,摄影师、灯光师、音响师等的辅助活动通常只能发生在舞台之下,而男女嘉宾、主持人等的主体活动通常发生在舞台之上,男女嘉宾通常站在舞台上特定的位置进行交流,而且必须从指定的出入口登场和退场,观众的行为也只能局限于在观众席上鼓掌、欢呼等。通过以上的分析我们发现地点对社会情境中的活动、参与者的个体行为以及社会情境的目标的实现有着重要的促进和控制作用。
6.时间
时间是视频语篇社会情境层的重要因素。社会情境中的社会活动和参与者的个人行为等一定会受到时间的控制和制约。以“我们约会吧”为例,这个节目每期通常大约是70分钟,在“男选女”节目中,每一位男嘉宾登场后在舞台上的时间大约是15分钟,期间要播放两段大约每段时长1分半左右的有关男嘉宾的短片,被选男女嘉宾的互动要在剩下的12分钟内完成。所以,时间和地点一样,都会对社会情境中的活动、参与者的行为起到重要的控制和制约的作用。
结 语
本文对已有的视频语篇的分析模式进行了总结,然后在此基础上对视频语篇重新进行了定性描述,指出视频语篇包括本质、内容、形式、和载体四个层次,视频语篇的本质是重新语境化的社会情境,内容是社会行为,形式是连续播放的图片,载体是数字化文件。
另外本文还对目前研究很少涉及的视频语篇的本质层,即社会情境层,以电视节目“我们约会吧”为例进行了分析,目的是建立一种针对社会情境层的有效的分析模式。
[1]Baldry,Anthony P,Thibault,Paul.Multimodal Transcription and Text Analysis[M].London,Oakville:Equinox,2006:165-268.
[2]Kress G R,Van Leeuwen T.Reading Images [M].London:Routledge,1996/2006:45-214.
[3]Scollon R.Mediated Discourse as Social Interaction[M].London:Longman,1998:27-122.
[4]Norris S.Analyzing Multimodal Interaction:A Methodological Framework[M].London:Routledge,2004:48-127.
[5]顾曰国.Towards a model of situated discourse[A].In The Semantics and Pragmatics Interface[C].K.Turner (ed.),Oxford:Elsevier Science,1999:150-178.
[6]Argyle M,Furnham A,Graham J A.Social Situations[M].Cambridge:Cambridge University Press,1981:41-226.
[7]顾 曰 国.A multimodal text analysis-a corpus linguistic approach to situated discourse[J].Text & Talk,2006(2):127-167
[8] 顾 曰 国.An Institutional Anniversary Ceremony as Systemic Behavior in Chinese Context[A].顾曰国语言学海外自选集[C].北京:外语教学研究出版社,2010:233-241.
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
华人时刊(2022年21期)2022-02-15
天津外国语大学学报(2021年1期)2021-03-29
云南教育·中学教师(2019年10期)2019-08-13
摄影之友(影像视觉)(2019年3期)2019-03-30
现代营销(创富信息版)(2018年10期)2018-10-12
数学学习与研究(2016年19期)2016-11-22
工业设计(2016年4期)2016-05-04
华人时刊(2016年13期)2016-04-05
当代修辞学(2014年1期)2014-01-21
