
借助汉语以义索词的英语用法检索*
2014-09-03 10:54北京外国语大学熊文新
语料库语言学 2014年2期
关键词:语境
北京外国语大学 熊文新
借助汉语以义索词的英语用法检索*
北京外国语大学 熊文新
有了一定的表达意图却找不到合适的英语表述方式,是中国学生经常面临的问题。借助句对齐的英汉平行语料库,能够从汉语出发检索出与之对应的英语实例。然而当前基于语言形式的语料库检索,其检索结果必须与用户输入的特定检索项匹配。为尽可能全面准确地获取地道的英语表述,本文借鉴信息检索的查询扩展策略,利用同义词词林等语义资源,介绍一种基于汉语同义表述的意义检索,在检索过程同时利用浅层语法分析,使检索精度得以保证。
检索、词汇语义、浅层语法分析、双语语料库、翻译句对
1.引言
在掌握组词造句规则之后,借助汉英词典,人们可以造出一些形式上合乎语法的英语句子;但离本族语者的地道表述还是要差上一大截。从不犯语法错误,到与英美人一样准确自然,是每个英语学习者的目标。
作为一种不可或缺的基础性语言资源(参见冯志伟 2001),语料库在语言本体、语言对比与翻译以及外语教育等领域产出丰硕成果(参见Sinclair 1991;Baker 1993;Hunston 2002;Grangeret al.2002)。高照明(2004)借助英汉-汉英平行语料库,实现了一个中国英语学习者能够以汉语发问检索相应的英语表述的查询系统。譬如想找英语如何表述“用坚强的意志和力量战胜(阻碍)”这一意思,最直接的办法是,先用汉语将其编码为“克服困难”;把这四个汉字作为检索项(search term),到句对齐的双语平行语料库中,找出跟这个词形完全匹配的中文句子;再输出与这些中文句子对应的英文句子。从理论上讲,借助构建良好的双语平行语料库,能够从某一种语言出发,检索出与之有对应关系的另一种语言表述。
然而自然语言的意义和形式并非一一对应,英汉两种语言之间的译法也不一致。从汉语出发检索英语的用法,有可能发生漏检(一些英语表述在语料库中译成了其他汉语形式)和误检(语料库的单纯字面匹配)的现象。本文试图帮助中国学生找到尽可能全、尽可能准的英语表述,拟解决的问题如下:
(1)选用何种类型的平行语料库?
(2)采用何种方法减少由于语言意义和形式及英汉语翻译不对应所造成的漏检?
(3)使用何种手段防止语料检索形式检索的误检?
2.句对齐加工的英汉平行语料库
帮助中国英语学习者找到合适的英语表述,涉及其母语(汉语)和目标语言(英语)两种语言。Zanettin(1998)将多语言语料库细分为平行(parallel)和可比(comparable)两类语料库。前一类语料库能看出翻译的方向性,目标语言的译文受到源语言的影响。后者的语料文本没有孰先孰后的依赖关系,存储的都是各种语言的原生文本,没有翻译腔;语言使用更地道、自然。理论上,可比语料库应是寻找合适外语表述的理想材料,但对此类语料库的对齐加工技术还很不成熟,作为语言工程项目实施还有难度,因此目前使用较多的还是双语平行语料库。有关平行语料库的创建及利用已经涌现了很多成功范例。在现有技术和资源下,选择英译汉的平行语料,更有利于中国英语学习者提取英美本族语者真实自然的表述。
当前双语平行语料库最常见的对齐单位是句子。比它大的单位,像句群段落,由于复现率不高,重复利用的可能性不大;比它小的单位,像短语或语块等,虽然复现率、对应的准确性都不错,但对语料加工标注的要求也较高,不太容易实现。语料库建设本质上是个语言工程项目。句子有显性的句末标点符号,又能表达相对完整的意义,并且重复性也比较高,因此当前绝大部分双语平行语料库都以句子为单位实施对齐(参见王克非、熊文新 2009)。
搜集到尽可能多的多语对照电子文本,还只是建立了一个生语料库。生语料的利用价值有限。针对没有分词的汉语文本,就只能做字层面的字频统计等。想要更充分地利用语料,就有必要对其进行各种不同类型的深加工。假如对语料文本的外部属性充分予以标注,像语体、体裁、题材、作者、翻译方向以及创作时间等信息,就能根据特定属性,抽取相关文本研究,使研究者能多层面、多角度地考察翻译文本受哪些外在因素的影响。如果对语料进行过词类赋码、句法分析以及语义标注等处理,就有可能深入挖掘翻译文本的语言属性,开展对比语言学的研究。尽管对语料的深加工能有效提高双语语料库的利用价值,同时也应看到受语言技术条件制约,处理精度尚难以保障,对语料精加工的后期校对依然需要投入大量时间和人力。
简而言之,现阶段能够对中国学生寻找合适英语表述有帮助的语言资源,应该是做过加工标注的、并已实施句对齐的英汉平行语料库。
3.检索项的同义扩展及对应词表引入
人工语言,像世界语及各种程序设计语言,其语法、语义及词汇都具有确定性。但自然语言形式和意义之间却没有整齐划一的关系。Barzilay & McKeown(2001)发现针对同一个意思可以有不同的说法,如替换词语、变化句式。Dale & Reiter(2000)指出有了表达意图,想找一个恰当的语言形式表述,这是语言产出或生成问题。
3.1 从意义到形式的检索
要表达某一特定意义,英语和汉语都可能有不同的说法,例如图1中的一组汉语表述ChineseExp和一组英语表述EnglishExp。这反映语言意义和形式之间的不一致性。英汉翻译也不具有一一对应性,例如ChineseExp2对应于两种英语EnglishExp2和EnglishExp3两种说法;而EnglishExp2在翻译成汉语时,也另有ChineseExp2和ChineseExp3两种译法。正是这种语言意义和形式的不一致,以及不同自然语言互译的不确定性,使得自然语言和翻译显得更加丰富多彩;而人们也总能根据不同的语境或场合选取合适的表述方式。
在汉译英的过程中,从源语言的汉语语句出发,比如选取ChineseExp1和ChineseExpn中的任何一个用例,以该语言形式作为检索项,执行传统的语料库检索,找出与其对应的英语表述。但另一些与之同义但不同形的汉语表述对应的英语表述将会被遗漏。譬如以ChineseExp1作检索项,在平行语料库中只能找到EnglishExp1;像EnglishExp2~EnglishExpn就检索不到,因为它们与ChineseExp1在句对齐的语料库中没有关联,可是它们也是表达该义的地道英语。这就引发一个问题:其实英汉平行语料库中还有大量可供参考的、地道准确的英语用法,由于学习者只挑选了部分汉语检索项,而无法检索出来。
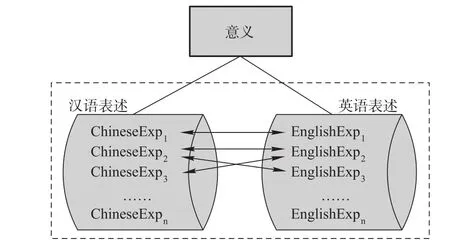
图1.意义和形式以及不同语言的翻译之间的不对应关系
语料库检索本质上是语言形式的匹配,而信息检索更关注信息主题和内容的对应。如果把用户输入的检索项理解成信息检索中需要在目标文本找到的概念,而不拘泥于语料库检索的语言形式,即不把检索项的词形作为唯一查询条件,借助现有词汇语义资源库,如《同义词词林》,将表述相同或相似意义的不同词语都引入作为检索项,防止因检索用语不同造成的目标语用法遗漏。
3.2 词汇语义知识库的应用
梅家驹等(1983)编写的《同义词词林》是我国首部现代汉语类义词典。编写初衷是为写作或翻译者提供一个从词义查词的工具书。哈尔滨工业大学开发了机用的《同义词词林(扩展版)》。新词林扩展后收录77,343条词语,按照树型结构组织词语,采用五级编码方式。同义词共享同一个编码标识,如“克服”标注为:Jd09B01=。各部分编码含义如表1所示。

表1.同义词词林扩展版的词语编码示例
表中共有8个编码位,其中第8个编码位上的标识符取值有三个{=, #,@},分别表示“同义”“相关”和“孤立词”。本例中的“=”表示当前词语“克服”的前7位标识,有其他词语共享,即在《同义词词林》中能找到与词语“克服”相关的其他同义词。
基于语义词典的词语语义相似度的计算方法有很多(参见Budanitsky & Hirst 2006;Jiang & Conrah 1997;裘江南等2008)。大多数算法与语言资源的特定组织结构相关,比如有些语义词典针对每个词条给出定义项,通过比较这些释义短文本中的词语分布的相似性,推知被释词的词义相似度,像基于向量空间(VSM)的WordNet和Roget’s词语的比较。另有一类语义词典,如知网(HowNet),它采用人工构造的知识描述体系,结合基本义原、语法义原以及关系义原等基本描述单位,对每个词语表述的概念进行特别描写。刘群、李素建(2006)根据义原性质以及这种描述语言的语法,实现了词义的相似度计算。
《同义词词林》与上述词典的组织方式都不同。它只是一个词语集;按照一定层级对收录词语进行整理,即根据特定分类体系把词语安置在树形结构的某个位置。编码位自左往右可以看作分类层次。任意两个词语能够根据它们右向共有的编码位多寡,实施远近亲疏的归类。针对本例,如果采用最粗略的归类,选取左数第一位表示的大类,只需取其首位以字母J开始的所有词,都可以看成是与“克服”相关的一类词。这种处理显然词语颗粒度太大。如果采用最严苛的归类处理,将比较位一直顺移到编码位的第7位;即只有全部7位编码都相同的词语才能算作一类,那么能够算作同义词的词语数就少得多,也准确得多。在最粗(只看首位)和最细(看全7位)的分类方法中间存在一个过渡阶段,实际处理时根据不同项目的精度要求,可以通过调整编码位的比较序列来动态计算词语相似度。
许多汉语词汇语义库资源,像《同义词词林》及其扩展版、知网等,由于类义词典(thesaurus)的性质,能够从特定概念意义出发,找出一簇相关的汉语表述用语,部分解决前文所述的“意义和语言形式的不一致性”问题。
3.3 英汉对应词表的应用
有时在单语语境中不易解决的问题,若是眼界放得更开阔一些也就好办得多。词义消歧的主要工作是,确定某个多义词在特定语境中的具体词义。要完成这项任务,往往事先需要储备很多资源,比如对词义的描述以及大量标注好的语料。这相对来说较难满足,于是人们想到利用双语材料来辅助解决单语的词义消歧(参见Galeet al.1992)。
汉语同义词,既可以从《同义词词林》或知网等现有词汇资源提取,也可以借助各类英汉汉英双语词典的对译词获取。譬如综合现有电子词典的基础,可以构造一个较大的汉英对译词表。例如基于现有电子词典的词表,能够发现“克服”的英译词有{conquer, get over, hurdle, lick, overcome, ride, surmount, tide over},“度过”的英译词有{get through, live through, spend, tide over, weather through}。由于这两个词共有tide over的译法,在表述to help to get through (a period of difficulty, distress, etc)这个意义上,它们是同义词,如“克服困难/渡过难关”。
汉英对译词既可从词典释义用词中提取,也可以取自双语语料库的词语自动对齐。这些都是鲜活的语言事实。放宽对词义及同义词认定的严格语言学界定之后,依据是否包含有相同的对译词义项,能够构建更丰富的汉语同义表述用法集。基于对译词表的词语形式扩展,可以消解由于翻译选词不一致造成的地道英语表述的遗漏。
4.浅层语法分析
计算机生成词语索引行是语料库处理最重要的手段之一(参见Hunston 2002)。语料检索通行的做法是:先对语料文本通篇扫描或直接读取已做好的字词索引,定位包含检索项的特定位置,根据用户指定的跨距,提取指定跨距范围内的字符串,然后再按照特定的排列方式在屏幕上呈现该结果,同时以突出的颜色高亮显示用户输入的检索项。
4.1 语料库检索的准确性缺陷
在语料库检索中,如果某次查询有多个检索项,缺省状态下它们是逻辑“和(and)”关系。满足查询的结果必须在指定跨距中包含这些检索项。除非特别设计,检索项出现的先后位置不影响结果。Christ(1994)指出一些专门的检索系统能够在标注程度不一的语料库上,对词语、词码等颗粒度不同的语言单位,实现截词、模糊及近邻匹配等多种检索方式的查询处理。
检索能做到什么程度,取决于对语料库的加工程度。在没有任何加工的生语料上,只能进行字词一级的检索。如果想检索更复杂的语言现象,则需要先对语料库进行相应的标注。譬如想要检索某些特定的句法结构,就必须先对语料库进行句法剖析(parsing)。尽管语料库语言学家对搭配的典型定义包含了语法和语义上的限制,但在做索引行提取和关键词语境(key word in context,KWIC)时还存在如下缺陷:
(1)语言是有层次结构的。一些词语线性相邻,但分处不同层次的结构体。它们之间的关联有远近亲疏之分。例如有一个连续字符串AN1N2,一种可能组合是,先由N1N2结合成NP,再由A + NP组合成NP,譬如实例“男篮球队长”。单纯从形式上看,AN1直接相邻,如“男”和“篮球”线性相邻,但这两个词本身并没有直接联系,反倒是“男”与远距离的“队长”结合更紧密,因此不能单纯以为物理距离相近就意味着它们结合得更紧密。
(2)构造文本索引行时,通常确定搭配的跨距是-4/+4或-5/+5,即在被检索词前后4到5个词范围内出现的词语,都可当做搭配候选词。在获取大量实例的频次信息后,根据统计显著性来评估这些实例是否为有效搭配。然而自然语言远距离搭配的可能性是存在的。如检索VO搭配,V和O的中心语的跨距就有可能落在规定值之外。由于远距离搭配超出跨距所规定的范围,这类搭配现象就难以提取出来,在语料库检索中这部分也就被遗漏了。
要解决这些问题,需要对其实施进一步的语言学分析,而不是浅层次的字符匹配。
4.2 浅层语法分析
Lin(2003)介绍了加拿大艾伯塔大学林德康教授开发的英语依存语法分析器MINIPAR。以SUSANNE语料库作为测试数据,该系统对英语句子的依存关系识别达到88%的准确率和80%的召回率,响应速度也很快,基本上能够满足处理大规模文本的需要。
MINIPAR分析结果以元组(tuple)信息呈现。例如针对英语句子As he weakened, Moran became afraid of his daughters.(BNC-A6N)的句法分析,结果呈现如图2所示。关系节点以形式为label (word, root, pos, governor, rel, exinfo, exinfo )这样的元组描述。
浅层语法分析能够识别出词语之间的语法依存关系,而不管关联的词语处于句中什么位置,相隔有多远;只要输入查询词语及其相关的语法关系,就能按图索骥地将满足特定语法关系的词语检索出来。尽管MINIPAR的分析精度还难以满足机器翻译等语言知识关键应用的要求,但针对大规模语料库,通过频数等统计信息,能够过滤一些错误或垃圾信息。

图 2.MINIPAR的分析结果
要得到MINIPAR带来的好处,就需要预先对语料库进行标注和索引。好在MINIPAR的计算速度基本能满足大规模文本的处理所需。语料库索引过程通常也是脱机进行的。对于新增语料采用增量(incremental)索引的方式既能保证检索的相对准确,又不会过多增加系统的计算负荷,因此,引入浅层语法分析技术对语料文本进行标注并索引是可行的。
5.一个实验
以下以前文提到的查询“用坚强的意志和力量战胜(阻碍)”的英语表述为例,说明如何应用本文介绍方法来帮助中国英语学习者获得更多的英语表述实例(参见王克非、熊文新 2011)。
第一步搜集相关的英汉对照文本,实施文本清洁及对齐等处理,标识各类文本外部属性,如翻译方向、源自文本等信息,做成基于句对齐的双语语料。第二步对英语语料文本的每个句子,采用MINIPAR分析句中每个词语之间的依存关系,将分析结果中的词语(label)以及governor位置指代的相关词语和它们之间的语法关系(rel)编入索引,供检索系统调用。本步骤是双语语料库资源的准备阶段。由于涉及整理、分析和校对等环节,多是脱机完成。
在实时检索阶段,用户以两个汉语词“克服 困难”作为检索项送入检索系统,如图3所示。系统首先调用同义词词林,对检索项实施词语扩展,将与这两个汉语词意义相关的其他词语同样纳入扩展检索项。譬如针对词语“克服”,先获得其语义编码为Jd09B01,到同义词词林中提取与此标记相同的词语,如“克服”“战胜”“排除万难”“摆平”作为追加检索项。对词语“困难”,根据提取的语义编码,同样可以获得一簇意义相关的词,像“难关”“难点”等。根据英汉对应词表,得到与“克服困难“义的动词同义表达“度过”,将这两个检索项的原词及其扩展词排列组合,可以形成多个新的查询表达式,如“克服 难关”“战胜 困难”“渡过 难关”等。这些新生成的组合也是该特定意义的有效表述。

图3.启用扩展后的英语实例查询
诚然,在组合配对的过程中,也会有一些噪声,如取“克服”的扩展词“排除万难”与“困难”的扩展词“难点”构成的新查询式“排除万难 难点”,就构不成一个有语法关系的组合。由于在实际语料中不存在这种翻译实例,因而采用该查询式检索也得不到结果,自然就无需额外处理。另外一种解决办法是通过增加语法检查工序来排除明显不合法的表述。
Xiong(2010)根据双语“平行对应性”的原则,利用原有检索项和经词语语义扩展后的组合检索项以及它们之间的语法关系,到经过MINIPAR分析处理的语料库中提取相关的英语实例。譬如输入的原汉语检索项是“克服 困难”,希望知道在英语中如何表达“克服困难”这一意义,在提取出的双语对齐实例中,已确知汉语词语“困难”在匹配英语词语difficulty之后,到MINIPAR分析出的依存关系结果库中,找出与difficulty具有动宾关系的谓词成分,并将其作为可能的英语表示,并呈现出来供翻译者或学习者参考。在英译汉语料中出现汉语“克服 困难”及其等价语义表述的,与difficulty构成动宾搭配的谓词有contend with、fought、get out of、struggle with等形式。这些谓词都具有“克服”表示的意思,然而在双语词典中一般不会收录,因此借助常规查词典的手段是检索不到这些用法的。作为佐证的是,在汉译英语料中,中国英语学习者和翻译者的首选常常是中规中矩的overcome,在汉英词典中“克服”的第一个释义词往往就是它。
6.结语
传统的语料库检索大多是针对语言形式的检索,在检索之前事先就必须规划好检索项,因为检索结果必须与检索项匹配。如果检索项选得不好,就可能找不到符合要求的语言实例。本文提出基于表达的英语“找词”检索,由于不知道用什么样的英语表述,学习者只能借助已做好句对齐的英汉双语语料库,从对应的汉语字词出发迂回地找到相应的英语表述。然而由于自然语言形式和意义的矛盾、英汉两种语言之间翻译的多样性,当前的语料库检索系统只能得到与检索项对应的英语表述。显然还有更多同义的英语表述,由于对译的汉语与检索项不同,而没有被提取出来。此处本文借鉴信息检索的主题词概念扩展的方法,利用词汇语义资源和英汉对应语等信息,能够最大限度地实现检索结果的无遗漏。同时,针对传统语料检索的机械形式匹配,通过引入浅层语法分析技术,部分提高了检索的准确性。
语料库为缺乏语境的外语学习者提供了客观真实的自然语言事实材料。双语平行语料库能够实现由汉语到英语的检索,如果配以良好的检索功能,将能为中国英语学习者提供尽可能全、尽可能准的地道英语表述;若是结合语料库语言学的统计功能,无疑将对我国英语课堂教学的范例教学、学生自主学习等起到促进作用。遵循这一思路,利用对比语言学、语料库语言学及二语习得方法,已经有服务英语特异组合识别和教学的成果问世(熊文新等2013)。
Baker, M.1993.Corpus linguistics and translation studies: Implications and applications [A].In M.Baker, G.Francis & E.Tognini-Bonelli (eds.).Text and Technology: In Honour of John Sinclair[C].Amsterdam: John Benjamins.233-250.
Barzilay, R.& K.McKeown.2001.Extracting paraphrases from a parallel corpus [A].InProceedings of 39th Annual Meeting and 10th Conference of the European Chapter of Association for Computational Linguistics[C].Toulouse.50-57.
Budanitsky, A.& G.Hirst.2006.Evaluating WordNet-based measures of lexical semantic relatedness [J].Computational Linguistics32(1): 13-47.
Christ, O.1994.A modular and flexible architecture for an integrated corpus query system [A].In G.Kiefer & J.Pajzs (eds.).Papers in Computational Lexicography[C].Budapest.22-32.
Dale, R.& E.Reiter.2000.Building Natural Language Generation Systems[M].Cambridge: CUP.
Gale, W., K.Church & D.Yarowsky.1992.Using bilingual materials to develop word sense disambiguation methods [A].InProceedings of the 4th International Conference on Theoretical and Methodological Issues in Machine Translation[C].Montreal.101-112.
Granger, S., J.Hung, S.Petch-Tyson (eds.).2002.Computer Learner Corpora, Second Language Acquisition and Foreign Language Teaching[C].Amsterdam: John Benjamins.
Hunston, S.2002.Corpora in Applied Linguistics[M].Cambridge: CUP.
Jiang, J.& D.Conrah.1997.Semantic similarity based on corpus statistics and lexical taxonomy [A].InProceedings of International Conference on Research in Computational Linguistics[C].Taipei.19-33.
Lin, D.2003.Dependency-based evaluation of MINIPAR [A].In A.Abeille (ed.).Treebanks: Building and Using Parsed Corpora[C].Dordrecht: Kluwer Academic.317-329.
Sinclair, J.1991.Corpus, Concordance, Collocation[M].Oxford: OUP.
Xiong, W.2010.Detecting collocations from Chinese English learner’s perspective [A].InInternational Conference on Intelligent Computing and Cognitive Informatics[C].Kuala Lumpur.175-178.
Zanettin, F.1994.Bilingual comparable corpora and the training of translators [J].Meta43(4): 616-630.
冯志伟,2002,中国语料库研究的历史与现状 [J].Journal of Chinese Language and Computing12(1): 43-62.
高照明, 2004,语料与机助翻译 [A]。载王克非等,《对应语料库:研制与应用》[M]。北京:外语教学与研究出版社。
刘 群、李素建,2002,基于“知网”的词汇语义相似度计算 [J],《中文计算语言学》(2):59-76。
梅家驹、竺一鸣、高蕴琦、殷鸿翔,1983,《同义词词林》[M]。上海:上海辞书出版社。
裘江南、罗志成、王延章,2008,基于中文语义词典的语义相关度方法比较研究 [J],《情报理论与实践》(5):32-38。
王克非等,2004,《双语对应语料库:研制与应用》[M]。北京:外语教学与研究出版社。
王克非、熊文新,2009,用于翻译教学与研究的英汉对应语料库加工处理 [J],《外语电化教学》(6):3-9。
王克非、熊文新,2011,汉英对应语料库的检索及应用 [J],《外语电化教学》(6):31-36。
熊文新、梁茂成、赵秀花,2013,基于语料库及对应词表的英语特异组合发现方法 [J],《外语电化教学》(4):3-8。
通信地址:100089 北京外国语大学中国外语教育研究中心/北京外国语大学国家语言能力发展研究中心
* 本文系国家社科基金项目“服务信息检索的自然语言”(11BYY051)的阶段性成果之一,同时得到教育部“新世纪优秀人才支持计划”(NCET-11-0591)的支持。
猜你喜欢
艺术生活-福州大学厦门工艺美术学院学报(2022年1期)2022-08-31
北京第二外国语学院学报(2021年1期)2021-07-16
疯狂英语·爱英语(2020年9期)2020-01-07
疯狂英语·爱英语(2020年9期)2020-01-07
传媒评论(2017年8期)2017-11-08
中国老区建设(2016年4期)2017-01-15
教学与研究(2016年1期)2016-02-28
时代英语·高二(2015年1期)2015-03-16
中国记者(2014年2期)2014-03-01
心潮诗词评论(2014年5期)2014-02-28
