
Web文本挖掘在药商兴趣提取中的应用
2014-12-14 07:00孙士新
邵阳学院学报(自然科学版) 2014年3期
孙士新
(1.亳州职业技术学院信息工程系,安徽亳州236800;2.北京师范大学职业与成人教育研究所,北京100875)
中药材信息网站主要是围绕安徽亳州中药材交易市场所进行的,有中药材信息收集、市场行情分析、用户供求信息收集、中药材经营技术在线学习等功能,收录了中药材交易价格、中药材供求信息、中药材交易记录、中药材解析、中药材产地介绍等信息,网站信息浏览者主要是药商、药农、中药材相关客户.根据对网站注册信息统计数据显示,以药商身份注册的网站用户占总用户的67%,以药商身份注册的用户个体日均访问量为3.57人次.药商作为网站的VIP用户主要群体,以药商为单位挖掘药商的药材兴趣领域,把中药材信息配对推送给相应的药商对网站运营至关重要.本文所涉及药商兴趣提取,是基于网站注册信息、网站日志、市场交易数据库等存在的文本信息的挖掘而进行的.
1 药商兴趣提取
1.1 药商兴趣及兴趣提取
1.1.1 药商兴趣
药商,即中药材经营者,是从事中药材买卖的人,包括中药材供应者、中药材采购者和与中药材供求工作相关的从业者.药商兴趣,是药商对中药材感兴趣的种类、感兴趣的中药材属性.药商对中药材感兴趣的种类包括野生类、家种类、家野兼有类、矿石及其他加工类、动物及其制品类、草类、花类、叶类等;感兴趣的中药材属性包括今日价格、热点追踪、产地信息、历史价格、涨落排行、产地供应、产地分布、市场动态、品种分析、市场分析等.
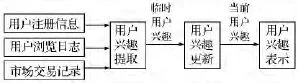
图1 药商兴趣提取模型Fig.1 The druggist's interests extraction model
1.1.2 药商信息提取
药商信息提取是通过Web数据挖掘技术对网站中药商信息进行抽取、分析、建模、表示的过程,如图1所示,药商兴趣提取模型包括用户兴趣提取、用户兴趣更新、用户兴趣表示三个部分.用户兴趣提取是根据用户注册信息中用户兴趣选取、用户介绍;网站日志中用户浏览网页记录、市场交易记录数据库中用户在买卖数据中出现的情况等信息而进行的.用户兴趣更新,是把用户提取环节所形成的临时用户兴趣与原用户兴趣进行匹配整理,重新形成当前用户兴趣.用户兴趣表示是把当前用户兴趣表示成系统容易识别和量化的过程,如{{草类,3},{家种类,5},{市场动态,7},…,…}.
1.2 Web文本挖掘关键技术
1.2.1 Web 文本挖掘
Web文本是网站信息中以文本形式存放部分,具有非结构性、半结构性、自述性、动态可变性、异构数据库环境等特点[1].文本挖掘又称为文本数据挖掘,文本知识发现,是指以发现知识为目的,从大规模文本库中抽取隐含的、未知的、潜在有价值的模式的过程[2].按照 Oren Etzioni的定义:Web文本挖掘是使用数据挖掘技术,自动地从Web文档、服务中发现并提取信息和知识的技术[3].文本挖掘的主要处理过程是对大量文档集合的内容进行预处理、特征提取、结构分析、文本摘要、文本分类、文本聚类、管理分析等[4].
1.2.2 Web 文本挖掘流程
如图2所示基于Web文本挖掘的药商兴趣提取流程分为网站文本采集、文本处理、文本特征分析、文本特征提取、文本分类、文本聚类、挖掘结果处理等七个阶段[5].文本采集是从海量文本源中根据需要采集相关文本信息的过程,文本采集的信息一般为一些非结构化、不完整性信息.文本预处理是把文本采集中所得到的非结构、不完整信息进行信息完整性、可用性处理,把非结构化、半结构化信息处理成可用的、计算机方便处理的结构化信息的过程.预处理包括数据过滤、用户身份识别、用户会话识别三个主要过程:数据过滤阶段需要移除和过滤掉冗余及不相关的数据,预测填充数据中丢失的值;用户身份识别通过Cookies、扩展日志、合并站点拓朴结构进行日志推断等方法进行;用户会话识别方法分为基于时间和上下文启发式方法[6].文本特征表示是在预处理阶段,将文本表示成计算机容易存储的格式,文本的表示方法大多数是从信息检索领域借鉴过来的[7].文本特征提取,是在文本表示的基础上从文本库中提取权值较高的词条作为文档的特征项,以达到对特征项进行降维的目的[1].文本分类按照一定的标准建立若干文本类别,在目标文档集里为所有文档确立所属相应类别,并按照文档类别对文档进行文档归类的过程.文本聚类是把一组个体按照相似性归成若干类别,即“物以类聚”,它的目的是使得属于同一类别的个体之间的聚类尽可能地小,而不同类别上的个体间的距离尽可能地大[8].挖掘结果处理是对以上各步骤对文档集进行的挖掘结果进行合理性、可用性分析,并对不同方案所挖掘的结果进行比较、评价、选择.
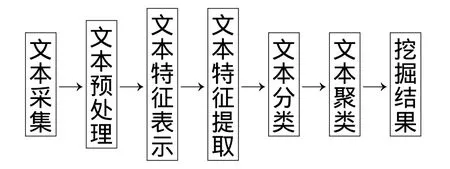
图2 Web文本挖掘流程图Fig.2 Web text mining process chart
1.2.3 文本特征提取中几个构造函数
(1)信息增益.信息增益是依照文本的特征项在文本中出现频次而推断该特征项所包含的信息量,是用来衡量文本信息的一个属性值标准.把文本特征用t表示,类别用c表示,目标文本类集用Ci表示,第i类出现的概率用表示为P(Ci),t出现与否的条件Ci下出现概率表示为则表示为P(Ci|t)和 P(Ci|).信息增益表示为:
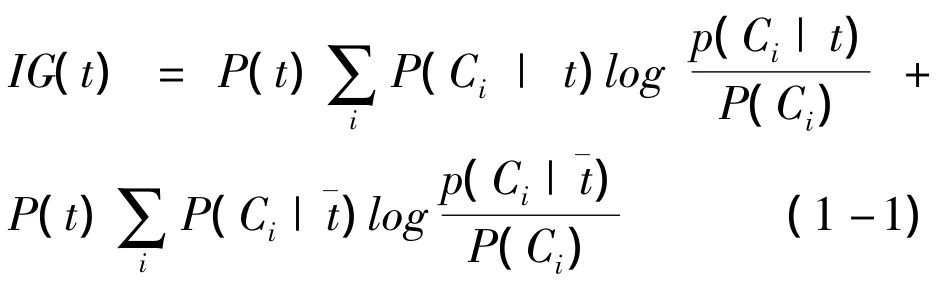
(2)互信息.表示变量之间的相互关联度,即表示两个变量的相关性,一个文本特征t相对于类别c的互信息表示为:
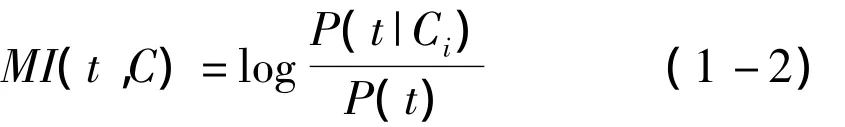
(3)表示两个变量之间的相关性,还可以用χ2统计,依然表示的是某个词与某个类之间的关系,用P(t|C)表示文本中包含词语t和属于类c的概率,用P(t|ˉC)表示文本包含t和不属于C的概率,对于C,t的χ2估计表示为:
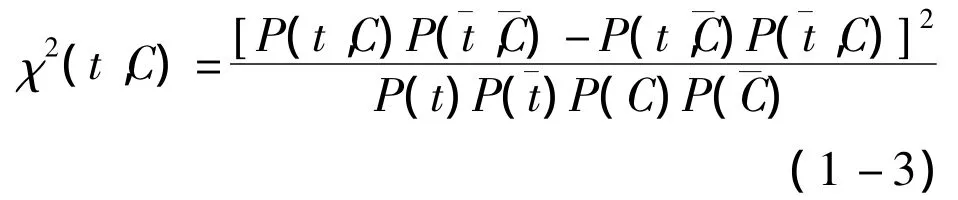
1.2.4 相似度[9]
向量内积公式为:

三种相似度比较公式中,向量内积是按照两文本之间词的相同个数量来判断相似度,忽略文本中词语之间的关联关系,判断效果不明显;向量夹角余弦与量相似度与Jaccard相似度判断效果基本一致,可以讲结果归入[0,1]范围内,判断效果明显.
2 基于Web文本挖掘的药商兴趣提取流程
如图3所示,基于Web文本挖掘的药商兴趣提取流程分为网站文本采集、文本处理、文本特征分析、文本特征提取、文本分类、文本聚类、挖掘结果处理等七个阶段.
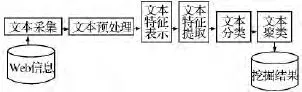
图3 基于Web文本挖掘的药商兴趣提取流程Fig.3 The druggist's interest extraction process based on the Web text mining
2.1 文本采集
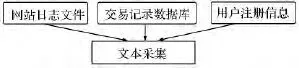
图4 网站访问日志Fig.4 Network access log
用户兴趣主要从网站日志文件、市场交易记录数据库、用户注册信息中提取,如图2-2所示.
①网站日志文件是网站在运营过程中所产生的记录性文件,其内容包括访问者IP地址、访问者ID、访问时间、离开时间、访问次数、被访问页面地址等.对日志文件的采集主要是读取访问者IP地址、访问者ID、停留时间、被访问页面主题、被访问页面内容等,其中文本采集的主要内容为访问页面主题、搜索关键词、访问页面内容文本.对注册用户主要以用户ID来确定访问者身份,对非注册用户主要通过访问者IP地址来认定用户身份.
②交易记录数据库记录着买方ID、买方ID、药材名称、药材产地、交易价格、交易数量、交易时间等信息.对交易记录数据库词条的采集主要包括买方ID、买方ID、药材名称、药材产地等,其中文本采集的主要对象为药材名称和药材产地.
③用户注册信息包括用户ID、用户名、性别、所在地、电话、E-mail、感兴趣中药材品种、感兴趣药材信息、个人说明等.对注册信息的数据采集包括用户ID、用户所在地、用户兴趣药材种类、用户兴趣药材信息、个人说明等,其中文本采集主要内容为用户所在地、用户兴趣药材种类名称、用户兴趣药材信息文本、个人说明文本.
2.2 文本预处理
文本处理面对想对象是网页主题、网页内容、中药材名称、中药材介绍、中药材分析等非结构化信息,在对文本进行标示和提取前应进行词汇分析,把对象中的文本转换为词,中文文本的分词可以采用基于统计的分词方法和基于词库的分词方法,也可以两者结合.
(1)基于统计的分词方法.是对词的判断,在一个预处理文本中,统计相邻的两个或两个以上的字,在同一文本处理单元中出现的次数,出现次数达到一定阀值,系统则认定为该字串为词,则进行该词的提取.一次进行,对文本单元中各达到阀值的字串进行提取,形成该文本单元的量化词条.如,在产地信息白芍页面中提取词条为:{{上货量,1},{增多,3},{理想,1}{价格,4},{保持,3},{交易价,5},{黑白芍,6}},若设置阀值为3,则该页面的词条为{增多,价格,保持,交易价,黑白芍}.
(2)基于词库的分词方法.首先应建立词库,对给定的文本单元,从第一个字开始把文本单元中的每一个字与词库中词的字进行比较,当连续的两个或两个以上的字与词库中的某词所有字相同时,则认为该连续字串与某次匹配,进行该词的提取,依次重复进行.本系统的词库以中药材名称、中药材价格属性、中药材介绍属性、中药材分析属性等进行分类,如中药材价格属性词库为{元,斤,上涨,下调,…,持平}.
2.3 文本特征表示
文本特征表示可以用布尔逻辑模型、概率模型、向量空间模型等,本系统采用向量空间模型(VSM)法,具体步骤为:
(1)将文本看做一组词条的集合,表示为(T1,T2,T3,…,Tn);
(2)依据词条在文档中的出现频次为集合中的每一词条Ti赋予一个权值Wi,集合T的权值集合W可以表示为(W1,W2,W3,…,Wn);
(3)该文本集合则映射为一个由词条和权值组成的向量空间组合,每一个待挖掘文档都可以表示为(T1,W1,T2,W2,T3,W3,…,Tn,Wn)的词条特征矢量形式.
2.4 文本特征提取
文本的特征提取是对文本中出现词条Ti及其权值Wi的选取,特征提取的单位是特征项,特征提取分为一般特征项和专业特征项.在药商兴趣信息提取中,一般特征项是某些出现频次高的名词,如{价格,销售,上升,…,回落,产地};专有特征项主要为药材名称、销售日期、数量数字、产地等,如{甘草,当归,白芍,柴胡,…,2014-4-2,2014-4-5,…,50,98,,…,湖北利川市,贵州施秉县,…}.文本特征项提取可以采用信息增益、互信息、χ2统计等构造函数:
(1)信息增益.是用来衡量中药材信息的一个属性值标准.一种中药材信息的信息增益值可以用公式(1-1)表示.
(2)互信息.在本系统中,t表示药材信息属性,c则表示药材类别;t表示药材信息种类,c则表示药材信息大类.则一个文本特征t相对于类别c的互信息可以用公式(1-2)计算.
(3)χ2统计.用 t表示词语,如中药材名称、价格、产地等信息;c可以表示中药材大类、中药材类别、中药材属性类别等.t的χ2估计表示为公式(1-3).
2.5 文本分类
方便用户浏览文档和简化文档查找,文本分类阶段是按照既定分类模型,在文档集合范围内为各文档确立一个类别,文本分类分为建立分类模型和根据分类模型进行分类两个阶段:
2.5.1 建立分类模型
(1)设类别集合为C,集合中各层次为并列式,则有:
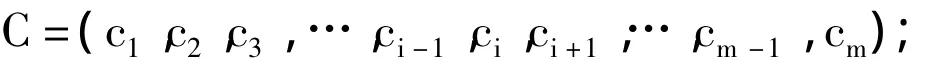
(2)设训练文档集合为S,则有:
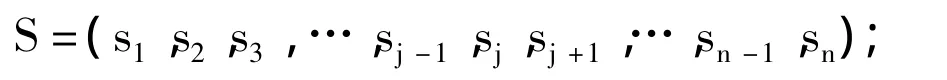
(3)在S中提取各个文档的特征矢量V(sj),然后确定代表C中各个类别的特征矢量V(ci).
2.5.2 根据分类模型进行分类:
(1)设测试文档集为D,则有D=(d1,d2,d3,…,di-1,dk,dk+1,…,dk-1,dt),对 D中任何一个待分文档dk计算V(dk)与V(ci)之间的相似度,用两特征矢量之间的夹角余弦,表示为:
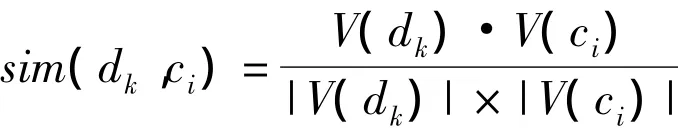

2.6 文本聚类
在该阶段是把一组文本对象按照相似性归纳成相关类别,可以用K-紧邻参照聚类法、基于概念的文本聚类、层次聚类法、平面划分法、简单贝叶斯聚类法等,本系统考虑到药材种类与各属性、药材类别与各种类、用户与属性等之间关系,采用层次聚类法,具体过程为:
对象文档为 T,T 表示为{d1,d2,d3,…,di-1,di,di+1,…,dn}.
(1)把给定文档集合T中的每一个文档di作为一个由一个单一成员的簇,即ci={di},这些单个成员的簇构成T的一个聚类,表示为:C={c1,c2,c3,…,ci-1,ci,ci+1,…,cn};
(2)逐次计算C中每对簇ci和cj之间的相似度:sim(ci,cj);
(4)重复步骤①②③,直到C中仅剩下一个簇时结束.
3 应用实例
本文采用亳州药通网2014年3月份网站日志、供求信息数据库、用户注册信息作为挖掘对象,采用SQLServer 2005中的SQL Server Business Intelligence Development Studio工具进行挖掘.部分实例如下:
从中药材信息网所采集的原始数据如表1所示,包括用户IP地址、用户ID、用户访问时间、用户离开时间、访问方式、访问内容、访问页面标题等.

表1 中药材网站用户兴趣提取来源Tab.1 Traditional Chinese Medicinal Materials that the user's interest extraction source
如表2所示,为以用户08005为检索关键词所得到的用户访问网站记录,包括用户IP地址、访问网页内容、访问时间、网页名称等内容.

表2 某用户浏览网站记录Tab.2 Some user's browsing the website record
如表3,为文本分类阶段后,各文本提取的中药材名称,及所属中药材大类对应表部分,其中包括每种中药材所属大类.
表4为经过文本聚类后,用户与兴趣所属中药材大类、中药材属性对应列表.其中包括用户ID、中药材大类、中药材属性等信息.
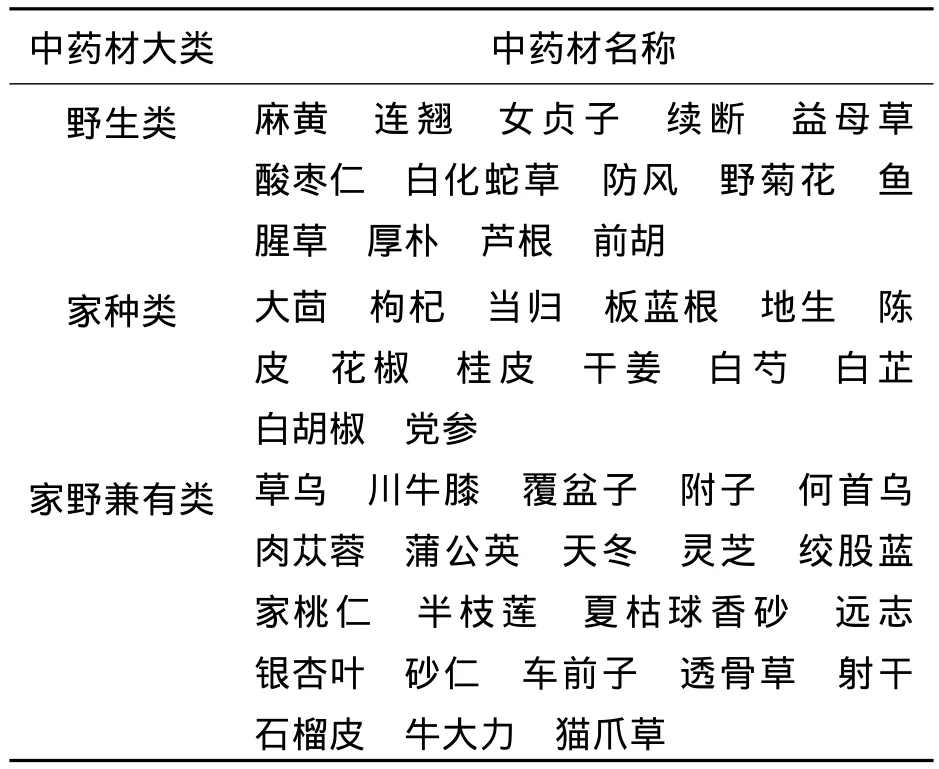
表3 中药材大类及中药材种类对应Tab.3 The broad category of the Traditional Chinese Medicinal Materials and the comparison of the Traditional Chinese Medicinal Materials category
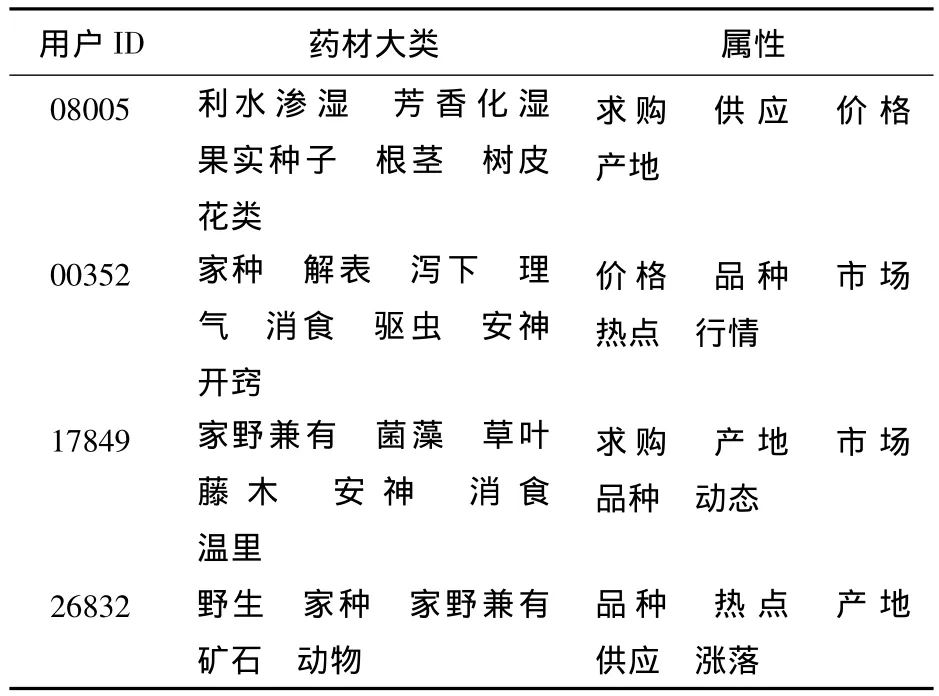
表4 用户兴趣中药材大类及属性Tab.4 The user's interest the broad category of the Traditional Chinese Medicinal Materials and the nature
4 结论
Web文本的特征决定着文本的不确定性、歧义性和内涵丰富性,从网站注册信息、访问日志、交易记录数据库中自动提取文本,并对文本进行分析,以文本特征标志用户兴趣,实现了用户兴趣评价,排除了认为评价用户兴趣的主观性.本文借助文本挖掘流程,并改进文本挖掘流程,借助中药材信息网数据,实现了用户兴趣挖掘,为网站的个性化服务奠定了基础.
[1]邹腊梅,肖基毅,龚向坚.Web文本挖掘技术研究[J].情报杂志,2007,(2):53-55.
[2]谌志群,张国煊.文本挖掘与中文文本挖掘模型研究[J].情报科学,2007,25(7):1046-1051.
[3]Oren Etzioni.The world wide web:Quagmire or gold mine?[J].Communication of the ACM,1996,39(11):65-68.
[4]袁军鹏,朱东华,李毅,等.文本挖掘技术研究进展[J].计算机应用研究,2006,(2):1-4.
[5]马刚.基于语义的Web数据挖掘[M].大连:东北财经大学出版社,2014.
[6]蒋涛,张彬.一个集成Web语义和使用挖掘的个性化模型[J].长沙大学学报,2006,20(5):63-66.
[7]王兴起,王维才,谢宗晓,等.文本挖掘技术在信息安全风险评估系统中的应用研究[J].情报理论与实践,2013,36(4):107-110.
[8]王伟.基于语义挖掘的智能竞争情报系统研究[J].情报理论与实践,2008,31(5):773-776.
[9]刘恒文.基于网络语义挖掘的舆情监测预警研究[D].武汉:武汉理工大学,2010.
猜你喜欢
客联(2022年3期)2022-05-31
今日农业(2021年12期)2021-11-28
今日农业(2021年7期)2021-11-27
中国新闻周刊(2021年26期)2021-07-27
当代陕西(2020年15期)2021-01-07
今日农业(2020年13期)2020-08-24
信息安全研究(2016年4期)2016-12-01
中成药(2016年8期)2016-05-17
中国储运(2015年4期)2015-11-21
