
基于规则的复句关系词的自动标识
2015-04-25 09:57贾遂民雷利利胡明生
中文信息学报 2015年1期
贾遂民,雷利利,胡明生
(1.郑州师范学院 信息科学与技术学院,河南 郑州 450044;2. 河南财经税务高等专科学校 综合实验实训中心,河南 郑州 451464)
基于规则的复句关系词的自动标识
贾遂民1,雷利利2,胡明生1
(1.郑州师范学院 信息科学与技术学院,河南 郑州 450044;2. 河南财经税务高等专科学校 综合实验实训中心,河南 郑州 451464)
关系词的自动标识是中文信息处理领域的基础性研究课题,该文利用规则实现其自动标识。首先通过语料的分析总结出关系词在使用过程中的12种特征,以这些特征建立规则的约束条件;然后提出包含匹配算法实现复句准关系词序列与规则索引词的匹配,以此获取目标规则,并根据目标规则约束条件与关系词所在语境的匹配结果得到匹配规则;最后利用匹配规则的结论实现关系词的自动标识。实验结果表明,该方法对关系词标识的正确率达到70.9%。
关系词;规则;复句;自动标识
1 引言
随着中文信息处理的不断发展,人们迫切地需要计算机能够对真实文本进行自动处理,以实现对文本浅层甚至深层的分析。关系词作为汉语复句的重要组成单位,它是连接小句和复句的主要成分,其研究结果不仅影响到复句类别的标识以及层次的划分,也影响到复句和篇章语意的理解,进而影响到机器翻译等众多领域的发展进程。但是由于汉语语言的隐晦性、灵活性以及复杂性等特点,复句的分句之间常存在包孕、并列、扩展和交叉等情况,这大大增加了关系词识别的难度。基于规则的研究是自然语言处理的研究方法之一,而基于规则的关系词自动标识是以实际语料为依据,以分析归纳为手段,找出相应的关系规则并建立规则库,根据规则对输入的复句关系词进行标识,因此是一种比较行之有效的方法。
胡金柱等人[1-2]曾基于规则对关系词的标识进行初步的探讨,并结合词性标记和关系词搭配理论,提出“正向选择算法”来标识关系词。本文是在以上研究的基础上,根据语料库建立规则,利用规则的结论来标识准关系词。
2 关系词规则的建立
2.1 关系词特征的建立
关系词的使用比较灵活多变,这就加大了规则的制定难度,因此需要将关系词的特征加以总结分类,以全面清晰的制定各种类型的规则。CCCS语料库[3]为汉语复句语料库(the Corpus of Chinese Compound Sentences,简称CCCS),它是华中师范大学语言与语言教育研究中心开发的,收录了近百万条汉语复句,是目前比较完善的一个语料库,因此是本文研究复句的主要语料库。根据对语料库内复句的分析归类得到12种关系词特征,具体如表1所示[4]。
表1中12种关系词特征是根据关系词在复句中的使用情况来制定的。本文中规则制定的难点在于约束条件,即准关系词在什么条件下能被标识为关系词或者不被标识为关系词。复句的结构是复杂的,改变关系词能影响其语义,判断准关系词是否为真正的关系词必须考察各种语言环境,就这导致约束条件的类型千变万化。将规则形式化时,会得到约束条件的逻辑表达式,其中涉及大量的自定义函数,对每种关系词特征再次细化,得到每种关系词特征的约束条件。表1的关系词特征共对应46个约束条件,以字面约束的6个约束条件为例,如表2所示[4]。
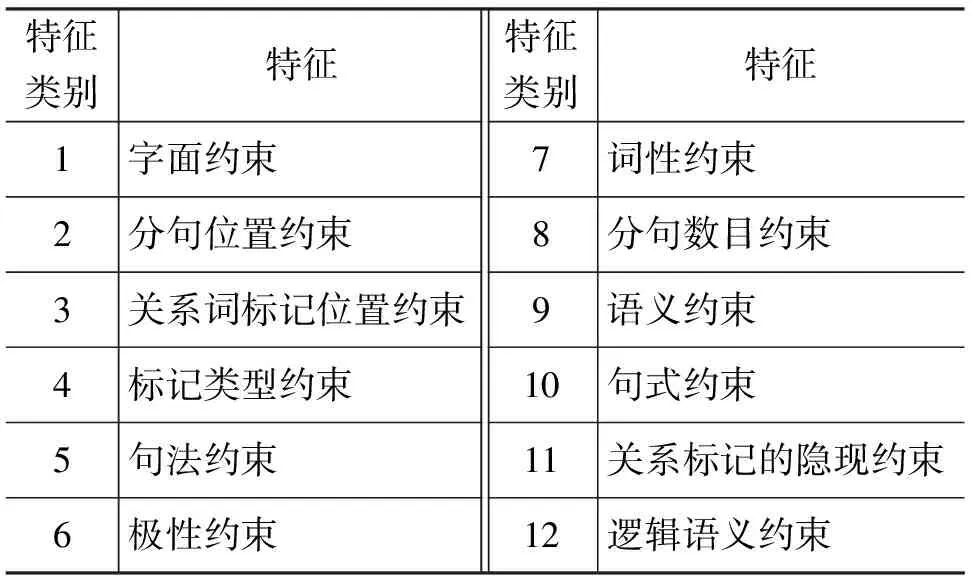
表1 关系词特征

表2 字面约束的6种约束条件
形式化描述规则能使其具有可运行化的性质,使得计算机能够解析规则。根据关系词特征与约束条件制定关系词的规则,规则组合成为规则库。目前规则库内有1 421条规则,挑选其中的两条如表3 所示。

表3 规则库内的规则
索引词(indexWord)为触发该规则的关系词序列,主要是与复句的准关系词序列进行匹配;优先级别(priority)是针对矛盾规则而制定的,值越低优先级别越高,若为空,则表示规则之间不存在矛盾;约束类型(constraintType)即为关系词特征(表1);约束条件(constraints)为准关系词所在复句必须满足的条件,与关系词特征相对应;结论(result)为标识结果。例如,约束条件“D(不但,反而)>4”属于关系词特征2,即分句位置约束,表示“不但”与“反而”所在分句的句间跨度大于4,规则的结论R(不但)=true,表示准关系词“不但”标识为关系词。从表3可以看出一个规则的约束条件通常有多个,复句中的准关系词只有满足所有的约束条件,才能利用该规则的结论来标识准关系词。
2.2 连用关系词分类
连用关系词[5-6]是指两个或者两个以上的关系词在复句中位置相邻。如例1所示。
例1 不管是北风呼啸的严冬,还是闷热难熬的盛夏,他都和科技人员一道,在知识的海洋里拼命吸吮,在科学的道路上奋力探索。(《长江日报》1982年10月21日)
“不管”与“是”都是准关系词,它们在复句中位置相邻,所以将“不管是”称作连用关系词或者连用词。
根据对语料库内连用关系词复句的总结,发现一些两标记连用的关系词存在一个特性,即这两个准关系词有且只有一个能够标识为关系词。这样的两标记连用的关系词共有21对: 甚至于是、如果说也、如果因此、如果只不过、尽管随后、因为随后、即使因此、于是只好、所以只好、但因此、却因此、既一方面、也首先、并随后、而是却、另一方面可是、加之随后、是因此、而最后、而随后、但随后,其中前11对可以直接判定结果,后面的10对需要借助其他条件来判定。
关系标记连用分为两类: 矛盾类与限制类。矛盾类: 两标记连用的准关系词A和B若同时充当关系词,会导致所引领的成分在表述时存在逻辑上的矛盾。判定A、B其中一个是伪关系词,一个为关系词。矛盾类针对两标识连用的关系词,可以直接标识其是否为关系词,上述的21对即为矛盾类;限制类: 两标记连用的准关系词A与B需要一定的限制条件,即一定的语境,根据关系词特征来限制A、B所在复句必须满足的条件来判定它们是否为关系词。
3 复句关系词与规则的匹配及标识
3.1 规则的匹配流程
复句关系词的标识过程大致可以分为三种: 输入、处理和输出。处理过程是其中最核心也最重要的流程,其过程如图1所示。
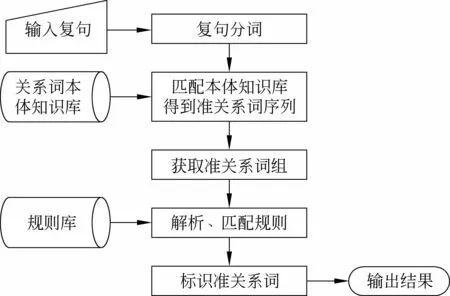
图1 规则匹配流程图
对复句进行分词之后需要对分词结果进行预处理,利用关系词本体知识库[7]以初步标识出准关系词,进而利用关系词的匹配关系,得到关系词组。根据复句的准关系词组与规则索引词的匹配结果获取目标规则。其中的难点为图1中的“解析、匹配规则”,这个过程包含两个难点: ①复句内准关系词序列与规则库中索引词的匹配;②规则约束条件的解析。
3.2 准关系词与规则库的匹配
将复句内准关系词序列看作模式串,规则库的索引词看做文本串,复句内准关系词序列与规则库内索引词的匹配必须满足包含匹配,包含匹配定义如下:
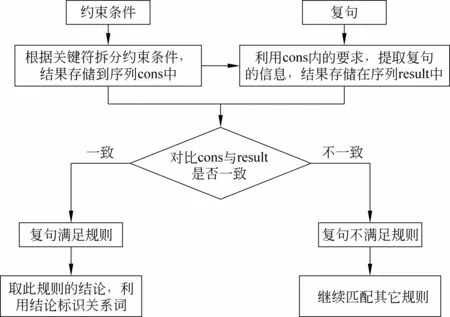
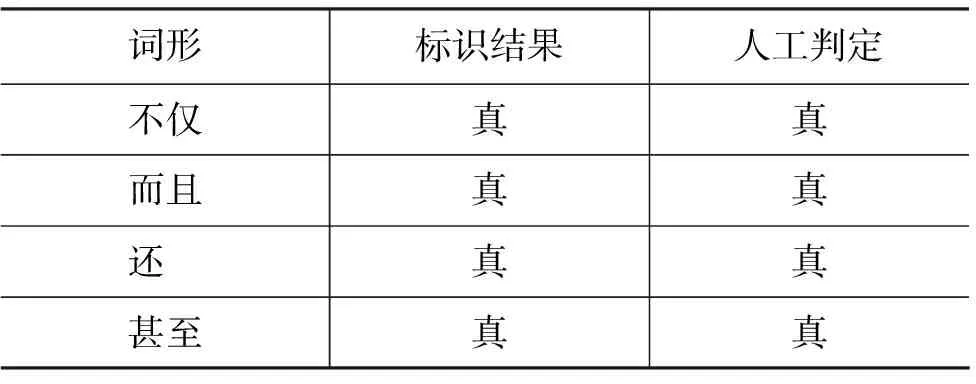
定义1 包含匹配: 对于文本串S={S1,S2,...,Sm}、模式串T={T1,T2,...,Tn}(n≤m),如果文本串S存在子串S′={Si,Sj,...,Sk}(1≤i 由包含匹配的定义可以看出,包含匹配不要求子串在文本串中位置相邻,子串元素与模式串元素只需保持前后顺序一致即可。 有限自动机M=(Q,Σ,δ,q0,F)[8]接受的语言是定义在Σ上被M接受的所有符号串的集合,形式化表示为公式(1)。 以文本串S={g r a p p e }与模式串T={g r a p e }为例,有限自动机的匹配过程如图2所示。 由上图可以看出文本串与模式串匹配,利用有限自动机能够实现包含匹配,但是却不能找到所有匹配子串,但是复句可能有许多重复的准关系词,匹配的目的是要找到文本串内所有符合包含匹配的子串,以根据子串去匹配规则。这里提出新的算法,具体如下。 图2 包含匹配 Step1: 根据复句分词结果与本体知识库的匹配,得到复句的准关系词序列S={S1,S2,...,Sm},以及要匹配规则的索引词T={T1,T2,...,Tn}; Step2: 根据T中的每个准关系词,在S中找到与其相同的索引词,并利用二维数组A存储S的下标号,数组的行列数为T内准关系词的个数,设为n。数组第j列的元素A[][j](0≤j SA[i][j]=Tj+1(0≤i 具体存储方法为: 找到S中与T1相同的准关系词集合,依次将集合的下标号存储到数组A的第0列;找到S中与T2相同的准关系词集合,依次将集合的下标号存储到数组的第1列,以此类推直到第n-1列。如果T中有个标记Tj与S的任意一个元素都不相同,则S不包含匹配T,结束;否则转至Step3; Step3: 根据数组构造所有满足条件的子串,数组A以列为单位,每一列选择任意一个元素i(i≠0),按列号从小到大组合为一个有序集合I={A[][0],A[][1],…,A[][n-1]}⟺{I1,I2,...In},集合I若满足条件Ij 3.3 规则约束条件的解析 由于约束条件为文本形式,这就增加了约束条件解析的难度。这里使用拆分策略,提取约束条件的关键信息来解析。具体过程如流程图3所示。 图3 单个规则约束条件的解析过程 上图中的关键符为一些特殊分隔符号,如逗号、括号等,通过拆分规则的单个约束条件就可略除约束条件内的无用信息,以得到关键信息。例如,约束条件“D(不但,反而)>4”,通过拆分之后得到“D、不但、反而、>、4”这5个关键信息,并将它们加入到cons线性表中,利用“D”这个关键信息,分析复句内的准关系词“不但”与“反而”所在分句的跨距,通过准关系词所在语境来获取匹配规则。如果复句的准关系词满足规则的所有约束条件,就可以取此规则的结论,利用规则的结论来标识准关系词。 为了验证本方法的正确性与可行性,特利用实例来详细说明基于规则的关系词的标识策略,如例2 所示。 例2 据生理医学研究,运动不足不仅对儿童智力和生长发育有妨害,而且还会给健康状况带来不良后果,甚至影响成年后的健康。(《长江日报》1998年04月28日) 根据输入的复句例2,规则解析器的执行流程如下: 第一步: 利用中科院的分词系统得到复句的分词结果为“据/p生理/n医学/n研究/vn,/w运动/n不足/an不仅/c对/p儿童/n智力/n和/c生长/v发育/v有/v妨害/v,/w而且/c还/d会/v给/p健康/a状况/n带/v来/v不良/a后果/n,/w甚至/c影响/vn成年/n后/f的/u健康/an。/w”,计算起始字符与终止字符时加入了分隔符与词性,文献[7]给出了词性的标注约定。根据分词结果与本体知识库的匹配得到例2的准关系词,如表4所示。 表4 例(2)的准关系词 根据对规则库内准关系词的匹配以及约束条件的解析,得到基于规则的解析结果,如表5所示。 表5 例2准关系词的标识结果 由表5可知基于规则的标识结果与人工判定一致,即判定准关系词都为关系词。为了进一步验证本方法的可行性,本文选取CCCS语料库[3]中117条复句作为测试用例,这些测试实例共包含365个准关系词,利用规则去标识关系词的正确率为70.9%,表面上看测试实例所得的正确率并不高,其主要原因有两点: 一是规则库还不完善,有大约18.7%的关系词并没有找到匹配的规则;第二点则是因为规则是由人工制定,存在一定的主观性,因此需要进一步检测、修正并扩充规则库。 本文是在以往研究的基础上,根据规则索引词的匹配需求,提出包含匹配方法以获取匹配子串,然后对规则约束条件提出解析方案,通过实例证明研究方法的可行性。但同时也应看到,由于规则库的不完善造成标识准关系词的正确率还不是很高,而规则的制定是一项长期且工作量很大的工程, 难以一步到位,同时由于规则是由人工制定,不可避免的带有一定的主观性,因此研究规则的自动挖掘技术,完成规则的自动生成将是一项有意义的研究课题。 由于关系词的自动识别是一项极具挑战性的工作,仅用一两种方法在短时间内很难使自动识别率达到很高的水平,今后还需要探索更有效的方法来进一步地提高识别的正确率,从而使得所做的研究可以更有效地应用于实际。 [1] 胡金柱,沈威,杜超华.基于规则的复句中的关系词标注探讨[J].福建电脑,2009,4:398-401. [2] 胡金柱,舒江波,姚双,等.面向中文信息处理的复句关系词提取算法研究[J].计算机工程与科学,2009,31(10):90-93. [3] 舒江波.面向中文信息处理的复句关系词自动标识研究[D].武汉:华中师范大学博士学位论文,2011. [4] 陈江曼.复句关系词自动标识系统中规则库及其维护方法研究[D].武汉:华中师范大学硕士学位论文,2012. [5] 胡金柱,雷利利,杨进才,等.多重复句关系标记搭配的求解模型研究[J].计算机工程与科学,2011,33(11):177-182. [6] 胡金柱,陈江曼,杨进才,等.基于规则的连用关系标记的自动标识研究[J].计算机科学,2012,39(7):190-194. [7] 雷利利.复句关系词自动标识系统中规则解析器的研究[D].武汉:华中师范大学硕士论文,2012. [8] Peter Linz著,孙家骕等译.形式语言与自动机导论[M].北京:机械工业出版社,2004. [9] 胡金柱,俞小娟,李琼,等.基于规则库和聚类分析的复句短语字段的自动识别研究[J].华中师范大学学报(自然科学版),2008,42(2):190-194. [10] 张金,王军海,耿标.基于规则解析的柔性编码系统[J].计算机系统应用,2006,3:17-20. [11] Schubert Foo, Hui Li. Chinese word segmentation and its effect on information retrieval [J]. Information Processing and Management, 2004, 40(1):161-191. [12] George A Miller. WordNet: A Lexical Database for English[C]//Proceedings of Communications of the ACM. 1995, 38:39-41. [13] Lafferty J, McCallum A, Pereira F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the 18th ICML-01, 2001:282-289. [14] Zhang Kunli, Zhang Wencong, Zan Hongying, et al. Studies on automatic recognition of several common Chinese adverbs’ usages based on BP neural networks[C]//Proceedings of the 10th Chinese Lexical Semantics Workshop. 烟台:鲁东大学出版社,2009: 31-37. [15] Lovasz L, Plummer M D. Matching theory [M]. Amsterdam: Elsevier Science, 2009. [16] 刘盈盈,罗森林,冯扬,等. BFS-CTC汉语句义结构标注语料库[J].中文信息学报,2013,27(1):72-80. [17] 张坤丽,赵丹,昝红英,等. 常用现代汉语副词用法自动识别研究[J].中文信息学报,2012,26(6):65-71. Rule Based Identification of Compound Sentences Relation Words JIA Suimin1, LEI Lili2, HU Mingsheng1 (1. College of Information Science & Technology, Zhengzhou Normal University, Zhengzhou, Henan 450044, China; 2. Comprehensive Experimental & Training Center, HeNan College of Finace & Taxation, Zhengzhou, Henan 451464, China) Automatic identifying the relation words of compound sentences is a fundamental issue in the field of Chinese information processing. This paper describe a rule based method for automatic identification of compound sentence relation words. To construct the rule, 12 featuresare summarized from the corpus. Then a match algorithm is described to obtaind the candidate relation word sequence. Finally the context of the relation words is employed to match with the rules. Experiment results show that this method achieves an accuracy of 70.9%. relation words; rule; compound sentences; auto-identifying 贾遂民(1968—),本科,副教授,主要研究领域为中文信息处理与应用数学。E⁃mail:jiasuimin@163.com雷利利(1986—),硕士,讲师,主要研究领域为中文信息处理与复杂网络。E⁃mail:leili_lei@163.com胡明生(1973—),博士,副教授,主要研究领域为复杂网络与人工智能。E⁃mail:hero_jack@163.com 1003-0077(2015)01-0044-05 2013-08-29 定稿日期: 2013-11-12 国家自然科学基金(U1204703);中央高校基本科研业务费资助(HUST: 2012QN087, 2012QN088);河南省重点科技攻关项目(122102310004);郑州市创新型科技人才队伍建设工程(10LJRC190) TP391 A
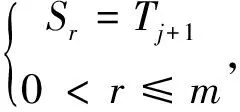
4 实验结果及分析

5 结束语
 猜你喜欢
电机与控制应用(2022年4期)2022-06-27成都理工大学学报·社会科学版(2022年1期)2022-05-26韩国语教学与研究(2021年2期)2021-11-24华北电力大学学报(社会科学版)(2021年2期)2021-07-21文化创新比较研究(2020年13期)2021-01-14天津外国语大学学报(2020年1期)2020-03-25北京航空航天大学学报(2016年6期)2016-11-16西安航空学院学报(2014年4期)2014-07-13外语教学理论与实践(2014年4期)2014-06-13
猜你喜欢
电机与控制应用(2022年4期)2022-06-27成都理工大学学报·社会科学版(2022年1期)2022-05-26韩国语教学与研究(2021年2期)2021-11-24华北电力大学学报(社会科学版)(2021年2期)2021-07-21文化创新比较研究(2020年13期)2021-01-14天津外国语大学学报(2020年1期)2020-03-25北京航空航天大学学报(2016年6期)2016-11-16西安航空学院学报(2014年4期)2014-07-13外语教学理论与实践(2014年4期)2014-06-13
