
Web藏文文本资源挖掘与利用研究
2015-04-25 08:24刘汇丹诺明花马龙龙贺也平
中文信息学报 2015年1期
刘汇丹,诺明花,马龙龙,吴 健,贺也平
(1. 中国科学院 软件研究所,北京 100190;2. 中国科学院大学,北京 100049)
Web藏文文本资源挖掘与利用研究
刘汇丹1,2,诺明花1,2,马龙龙1,吴 健1,贺也平1
(1. 中国科学院 软件研究所,北京 100190;2. 中国科学院大学,北京 100049)
该文结合链接分析技术和藏文编码识别技术,使用网络爬虫实现对互联网上藏文文本资源的挖掘,分析了Web藏文文本资源的分布情况。统计数据显示,国内藏文网站50%以上在青海省;约87%的藏文网页集中分布在31个大型网站中;人们正在逐步弃用旧有藏文编码,使用Unicode编码来制作网页。利用HTML标记、栏目归属、标点符号等自然标注信息对这些文本进行抽取,可以构建篇章语料和文本分类语料,可以抽取互联网藏文词库,进行词频统计和训练藏文语言模型,结合双语词典和搜索引擎技术抽取双语平行语料。这些语料可用于藏文分词、命名实体识别、信息检索、统计机器翻译等研究领域。
Web; 语料;文本挖掘;信息抽取;藏文信息处理;中文信息处理
1 引言
互联网海量的网页为藏文语料库建设提供了大量文本资源,为了对从互联网提取藏文语料提供依据,本文考察互联网上Web藏文文本资源的分布情况,并分析其潜在的利用价值。
本文接下来的部分首先介绍相关领域研究现状,其次介绍结合链接分析技术和藏文编码识别技术、使用网络爬虫实现对互联网上Web文本资源的挖掘的方法,然后介绍我们对现有Web藏文文本资源的分布情况的考察分析结果,之后对现有Web藏文文本在藏文自然语言处理研究中的潜在利用价值进行分析,最后对全文进行总结。
2 研究现状
由于诸多客观因素的制约,导致了藏文语料库匮乏的现状,仅有的语料资源规模也很小,国内曾报道的藏文分词语料库大多只有千余句[1-4],最多的也只有万余句[5-6]。
目前藏文语料的来源主要是政府文件、电子版书籍、报刊和部分源于互联网上的文本,而在语料库的建设和处理上大多依赖于人工方式[7-9]。这种原始语料库的获取方式大大限制了藏文语料库尤其是汉藏双语语料库的建设效率,不但制约了语料库的规模,更难以达到时效性的要求。中国科学院软件研究所从2009年7月份开始从相关单位搜集整理汉藏双语对照文本,历时近3年,获得的汉藏双语对齐语料却仅有约36万句对,与期望值相去甚远,由此,藏文语料库建设的难度和成本可见一斑。
与此同时,相关人员开始将目光转向互联网,研究从藏文网页获取文本资源的方法[10-13]。然而,这些研究局限于对一定范围内的藏文网页信息获取。目前,互联网网上有哪些藏文文本资源,它们存在的形式和分布状况是怎样的,可以用在藏文信息处理研究的哪些方面,等等,还未见有相关的报道。本文将通过对互联网藏文文本资源的考察,回答这些问题。
3 研究方法
在我们的研究工作中,我们首先开发了一套“互联网藏文文本资源挖掘系统”,采用链接分析的方法,利用网络爬虫根据预先指定的种子URL集合从互联网上采集网页,对网页进行编码检测,根据检测结果判断页面内是否包含藏文文本,将包含藏文文本的网页统一存放,并按照预先设定的方式组织管理。然后,由人工对采集到的藏文网页进行统一分析,考察其分布情况。我们的“互联网藏文文本资源挖掘系统”的前端界面如图1所示。
图1 互联网藏文文本资源挖掘系统前端界面
系统中主要用到了链接分析和藏文编码检测技术,下面针对这两方面的技术阐述我们的方法。
3.1 基于链接分析的藏文网页抓取
首先,我们定义如下符号:
•L(p): 页面p中的所有超级链接指向的页面集合;
•L(p,n): 与页面p有n重链接关系的页面集合,其中L(p, 0)= {p},L(p, 1)=L(p)。根据定义有:L(p,n)=L(L(p,n-1));
•L(S): 集合S中的所有页面p中的所有超级链接指向的页面集合。根据定义有:L(S)=∪L(p),其中p∈S;
•L(S,n): 与集合S中任意页面p有N重链接关系的页面集合,其中L(S, 0)=S,L(S, 1)=L(S)。根据定义有:L(S,n)=L(L(S,n-1)),同时L(S,n)= ∪L(p,n);
•HasTibetan(p): 页面p中包含藏文文本;
•Host(p): 页面p所在网站域名;
我们选取部分众所周知的藏文网站URL作为种子集合,通过链接分析技术,抓取从种子URL网页经过不大于N重链接关系可以到达的网页,将其中的藏文网页保存,并添加到藏文网页集合P,然后将这些网页所在网站的主机域名URL添加到种子集合中,如此循环。算法如下:
算法1: 藏文网页抓取算法 输入: 迭代次数T,链接深度N输出: 藏文网页集合P算法描述:P←S0;fort=0toT
forn=1toN
if(n==1)
forpsinSt
L(St,1) ←∪L(ps)
endfor
else
L(St,n) ←L(L(St,n-1) )
endif
forpinL(St,n)
ifHasTibetan(p)
St+1←St+Host(p);
P←P+p;
endif
endfor
endforendforreturnP;
在于第t次迭代中,对于种子集合St中的每个页面ps,抓取页面并分析页面获得其中所有超级链接指向的页面即L(ps),对所有的L(ps)求并集,得到L(St,1),对于L(St,1)中的每个页面,判断其是否藏文,若是则将其添加到藏文网页集合P中,并将其对应的网站URL添加到种子站点;然后分析L(St,1)中的每个页面,获取其中所有超级链接指向的页面即L(St,2)=L(L(St,1)),对L(p,2)中的每个页面做同样处理,直至达到链接深度N,并处理完L(p,N)中的所有页面。因处理过程中改变了种子集合,所以需要进行下一次迭代处理。理论上讲,如果链接深度N足够大,该算法能够抓取互联网上所有的藏文网页,迭代处理过程将在种子集合包含所有藏文网站之后停止。而实际上,随着时间的变化,已处理过的藏文网站也会被更新,作为一个完善的持续服务的系统(例如,搜索引擎),应该将迭代一直进行下去。
3.2 基于编码识别的藏文网页判断
在我们的研究中,采用藏文编码识别的方法判断一个网页是否包含藏文文本。由于基于ISO 10646(等同Unicode)国际标准实现藏文支持需要实现藏文字符的垂直动态组合,导致不少藏文软件采用预组合的方式自定义一套藏文编码字符集,而各个软件之间又互不兼容,导致了藏文编码“万马奔腾”的局面。文献[14]中按编码所属体系介绍了26种藏文编码,提出了一种综合使用藏文的音节点间距规律为特征、以藏文高频音节为特征进行藏文编码识别的方法。事实上,由于各种藏文软件在具体应用领域的差异,并不是所有的编码都被用于制作藏文网站(网页),例如,方正编码和华光编码主要用于出版印刷行业,而Tibetan Machine编码对应有用于Web的Tibetan Machine Web编码。综合各方面因素,我们判断,可能用于网页的藏文编码主要包括: Unicode编码(UTF-8或UTF-16)、同元编码、班智达编码、TCRC编码、Tibetan Machine Web编码、LTibetan编码,除此之外,藏文拉丁转写方案也可以视为一种藏文编码。
对于待识别编码的网页文本,进行编码识别的顺序依次为: 班智达编码、同元编码、Unicode编码UTF-8、Unicode编码UTF-16、TCRC、Tibetan Machine Web、LTibetan、拉丁转写。其中,对同元编码和Unicode编码的识别以音节点间距规律为特征,对其它编码的识别以高频音节的出现次数为特征。在判断为不是某种编码时,进行后续编码的识别。具体的方法与文献[13]本质上相同,不再赘述。
经过对编码识别结果的统计,在已抓取的13万网页中,编码识别正确率为99.93%。同时,编码识别方法能够将只包含极短藏文文本的网页召回,例如,http://zw.qh.gov.cn/zwqhgov/index.html 和http://www.tibetebook.com/help/HimalayaKeymap.htm两个页面中的中分别只包含不超过30个藏文音节,说明编码识别的召回率是可以接受的。
3.3 人工分析
由于编码识别不能保证完全正确,如果非藏文网站URL进入到种子集合中,将会影响系统的效率。对所有新发现的藏文网站,在进行人工确认以后,我们的系统才将其加入到种子集合。其他的分析工作主要包含对采集到的藏文文本资源考察以及对其分布情况的统计分析。
4 Web藏文文本资源分布情况
我们的系统从2011年1月12日开始运行,中间经过若干次的系统改进和完善,至2012年4月13日止,收录藏文网站URL共计165个。我们采用如下的规则作认同处理。

表1 包含1000以上网页的藏文网站信息表
• 同一域名的不同表达形式要认同,例如,http://gesar8.com 与http://www.gesar8.com 被认为是同一个网站;
• 不同子域名不认同,例如,http://blog.amdotibet.cn 与http://t.amdotibet.cn被认为是两个网站。
• 不同的域名不认同,例如,http://ti.gzznews.com 和http://www.kbcmw.com都是"康巴传媒网"的域名,但认为是两个网站。
认同之后,获得网站共计150个。表1中列出了采集网页数量在1 000以上的藏文网站的信息。
4.1 藏文网站地域分布情况
我们主要根据网站的主办单位、页面底部的电话区号、ICP备案地、域名及IP地址归属地来判断各个网站所属的区域,结果如图2和图3所示。个别网站因暂时不能访问,而已采集到的数据太少而不能判断,归属于“未知”类别。从表2中可以看出,国内网站共110个,占73.33%,国外网站共35个,占23.33%,另有5个网站未能确认。国内网站主要集中在北京、青海、西藏、四川、甘肃等地,其中青海省内的藏文网站的数量远远大于其他各地,占国内藏文网站的53.64%(图4),占本系统收录所有藏文网站的39.33%(表2)。国外藏文网站主要集中在美国和不丹。

图2 国内藏文网站地域分布图

图3 国外藏文网站地域分布图

图4 国内藏文网站地域分布比例图

表2 藏文网站地域分布情况
4.2 藏文网站页面数量分布情况

图5 页面数量图

图6 页面数量分布图

图7 页面数量累加比例图
如图5所示,藏文网站的网页数量呈典型的长尾分布,按页面数量降序排列之后,按指数数列设定阈值进行统计,达到阈值的网站数量与包含的网页数量呈对数线性分布(图6),页面数量在1 000以上的藏文网站共有31个,这些网站的网页数量占到了采集到的网页总数的86.68%(图7)。其中页面数量在 10 000 以上的藏文网站共有3个,各自包含的网页数量都在总数的9%以上,3个网站的累计比例达到32.21%。前7个网站中的页面数量接近网页总数的一半,达到49.98%。其中中国西藏新闻网有 18 000 多藏文网页,占比13.79%,而人民网藏文版和中国共产党新闻网藏文版都是由人民网主办,如果视为同一网站,则其网页占比达到14.11%,与中国西藏新闻网相当。而中国西藏网藏文版的旧版新版多种编码及多个域名(表1中未全部列出)合并计算,则其占比也达到10.16%。以上数据表明,藏文网络文本资源的分布非常集中。
4.3 Web藏文文本编码使用情况
如表3所示,目前Web页面中仍在使用的藏文编码有Unicode编码(含国家标准扩充集编码)、同元编码、班智达编码和藏文的拉丁转写,暂时未发现其它编码。其中Unicode编码的藏文网站和网页分别占比93.33%和82.48%,后者比例比前者低,是因为最近几年新出现的藏文网站都使用Unicode编码,但使用其它编码的网页达到了一定的规模,新的网站在短时间内难以超越;其次是同元编码,占6.00%和16.78%,后者比前者高,说明同元编码曾经被大量使用,网页数量积累到了一定规模,但新的网站更倾向于用Unicode编码。页面数量在 1 000 以上的31个藏文网站中(表1),3个是同元编码,其余28个都是Unicode编码。
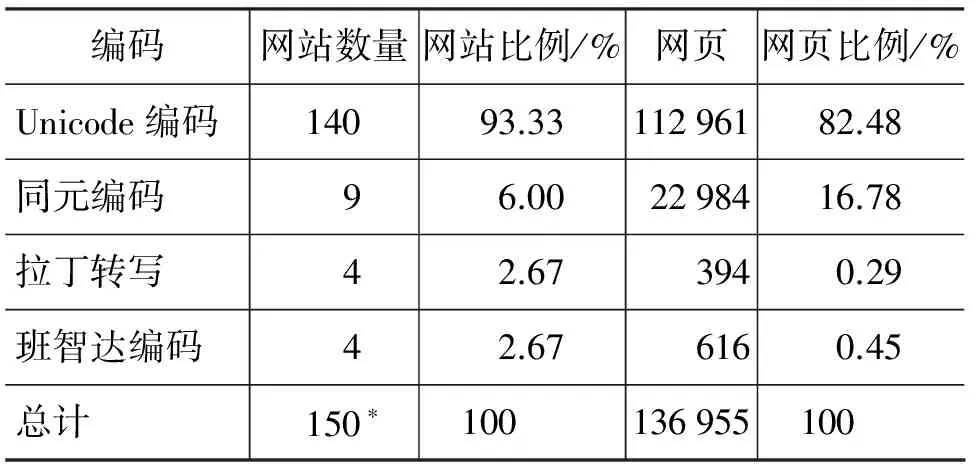
表3 藏文网站和网页使用藏文编码情况
*部分网站同时使用两种编码,计算网站总数时只算一个
需要注意的是,部分网站存在同时使用两种编码的情况。其中,http://zw.tibet.cn和http://ti.tibet.cn 大部分使用同元编码,但其中有少量网页使用了Unicode编码,他们都是“中国西藏网”的域名,但新版的网站(http://tb.tibet.cn)已经改用Unicode编码。西藏农牧经济信息网旧版使用同元编码,新版使用Unicode编码。而使用藏文拉丁转写的网站中一般也包含Unicode编码的藏文文本。
以上这些数据和事实表明,人们正在逐步地弃用以前自定义的藏文编码,转而使用Unicode编码。
4.4 Web藏文文本内容分布情况
我们的系统中采集到的藏文网站,从组织形式来看,既有普通网页,也有blog和wiki,甚至还出现了当前最流行的微博;从内容形式上来看,既有文字,又有图片、音乐和视频;从主办方来看,既有新闻媒体和政府机构,也有寺院和企事业单位,甚至还出现了个人主办网站的情况。下面根据网站主要功能分类作简单介绍。
新闻综合类网站一般包括与藏区有关的各方面的信息,包括新闻、政治、社会经济、语言文化、科技教育、宗教、文化艺术、旅游、环境、藏医藏药等。主要有: 中国西藏新闻网、人民网藏文版、中国藏族网通藏文版、中国西藏网、新华网西藏频道、青海湖网、康巴传媒网等。
政府机关类网站以宣传各类政策法规、介绍辖区政治经济等方面情况为主要内容。主要有: 果洛藏族自治州人民政府网藏文版、西藏农牧经济信息网藏文版、海西州人民政府政务网藏文版、青海天俊法院网等。
教育类网站以提供教育教学相关信息为主要内容,主要有: 中国藏族教育网、中国藏族中学网、青海尖扎民族教育网,以及西藏藏医学院、年保玉则小学、西海民族寄校、多杰旦民族职业技术学校等网站。
语言文化宗教类网站以提供藏族传统文化、宗教、藏医学相关信息为主要内容,主要有: 中国藏学网藏文版、西藏文化网藏文版、年保玉则文化中心、宗喀巴文化艺术研究网、中国格萨尔研究网、藏族民俗网、藏语言文字网、藏密文化网、喜马拉雅苯教网、雍仲苯教网、医学藏文网等。
藏文信息技术和软件类网站以提供藏文软件下载、介绍软件使用方法、藏文信息技术推广为主要内容,包括: 藏文软件园、藏文字体软件音乐图书中心、Dzongkha Linux、Tibetan and Himalayan Library等。部分网站提供在线电子词典查询服务,例如,http://www.tsikzoe.net、http://dictionary.thlib.org。这些网站为藏文信息技术的推广应用做出了贡献,也在一定程度上反映了藏文信息技术发展的现状。
5 Web藏文文本资源的利用价值分析
从自然语言处理的角度来看,Web是藏文语料的一个重要来源,既可作为单语语料使用,配合使用相关软件工具,也可以从Web上提取双语的藏文语料。
Web藏文文本可以作为藏文单语语料的来源。虽然同汉语和英语相比,藏文的Web文本资源要少的多,但是作为一般的藏文自然语言处理的研究,现有的Web文本已经具有一定的规模,能够满足作为基础语料资源的需求。这些Web页面中,绝大部分页面都包含文章标题和内容,可以作为基本的篇章语料使用;藏文网页所属的栏目可以作为文本分类的天然标记使用,构建分类文本语料;部分网页还提供作者、发布时间、稿件来源等信息,可以作为藏文命名实体识别的语料;根据网页中的自然标注信息如HTML标记和标点符号等[15],配合统计方法,可以从篇章语料中抽取互联网藏文词库,可以用于词频统计和训练藏文语言模型,这些作为基础数据可以用于开发以词语(短语)为单位支持连续输入的藏文输入法。这些基础数据还可以用于藏文分词、藏文信息检索等研究任务。
Web藏文文本可以作为藏文双语语料的来源。藏文圣经网提供的PDF格式文件中包含了段落对齐的汉藏双语基督教《圣经》文本。利用HTML的超级链接标记“”中的TITLE等属性可以从部分藏文网站(例如,http://nbyzsc.nbyzwhzx.com)提取汉藏对照词语(短语);部分网页提供了双语对照文本,如网站http://www.tibetebook.com的一个页面提供了588条汉藏对照的各类商店超市的名称,可以用作命名实体识别的语料,也可以用作双语平行语料。国内新闻综合类藏文网站大多有对应的汉文版甚至多语种版本,也可以作为双语语料的来源。
从上文的统计数据来看,Web藏文文本主要集中在部分大型网站,即使只提取20个网站的文本,也可获得10万网页的藏文语料,其分布的集中性为藏文文本的采集提供了方便。
6 结束语
语料是统计自然语言处理中必不可少的基础素材,但是当前藏文信息处理中存在严重的语料匮乏问题,本文结合链接分析技术和藏文编码识别技术,使用网络爬虫实现对互联网上Web文本资源的挖掘,并配合人工方式,相对全面地考察分析了Web藏文文本资源的分布情况。根据我们的分析,首先,国内藏文网站主要集中在我国北京、青海、西藏、四川、甘肃等省(市、区),其中50%以上在青海省。其次,现有藏文网站组织和内容形式比较丰富,既有普通网页,也有blog和wiki,还出现了微博;从内容形式上来看,既有文字,又有图片、音乐和视频;所提供的信息涉及新闻、政治、社会经济、语言文化、科技教育、宗教、文化艺术、旅游、环境、藏医藏药等各方面的内容。再次,旧有的藏文编码正在被逐步地弃用,人们转而使用国际标准的Unicode编码来制作Web页面。最后、Web藏文文本资源分布比较集中,约87%的藏文网页集中分布在31个大型网站中。
我们同时研究了这些网络文本资源对于藏文自然语言处理研究的潜在利用价值。Web藏文文本资源分布的集中性为文本采集加工提供了一定的方便。利用HTML标记和标点符号等自然标注信息对这些文本进行抽取,可以构建篇章语料、文本分类语料。配合统计方法,可以从篇章语料中抽取互联网藏文词库,可以用于词频统计和训练藏文语言模型,这些基础数据还可以用于藏文分词、命名实体识别、信息检索等研究方向。同时还可以结合双语词典和搜索引擎技术抽取双语平行语料,用于统计机器翻译。
在后续的研究中,我们将进行有针对性的Web藏文文本资源采集和加工处理,为藏文自然语言处理的研究提供基础的数据资源。
[1] 陈玉忠,李保利,等. 基于格助词和接续特征的藏文自动分词方案[J].语言文字应用,2003,(2): 75-82.
[2] 孙媛,罗桑强巴,杨锐,等. 藏语自动分词方案的设计[C]//第十二届中国少数民族语言文字信息处理学术研讨会论文集,2009.
[3] Huidan Liu, Minghua Nuo, Longlong Ma, et al. Tibetan Word Segmentation as Syllable Tagging Using Conditional Random Fields[C]//Proceedings of the 25th Pacific Asia Conference on Language, Information and Computation.2011:168-177.
[4] 刘汇丹,诺明花,赵维纳,等. SegT: 一个实用的藏文分词系统[J]. 中文信息学报, 2012, 26(1):97-103.
[5] 才智杰. 班智达藏文自动分词系统的设计与实现[J]. 青海师范大学民族师范学报,2010,(2):75-77.
[6] 孙萌,才智杰,姜文斌,等. 基于判别式分类和重排序技术的藏文分词[C]//第十三届中国少数民族语言文字信息处理学术研讨会论文集,2011.
[7] 才让加. 面向自然语言处理的大规模汉藏(藏汉)双语语料库构建技术研究[J].中文信息学报,2011,25(6):157-161.
[8] 才让加. 藏语语料库词类描述方法研究[J].计算机工程与应用,2011,47(4):146-148.
[9] 才让加. 藏语语料库加工方法研究[J].计算机工程与应用. 2011,47(6):142-143,150.
[10] 陈琪,李永宏,于洪志,等. 藏文网页抓取及编码统一转换的系统研究[J].西北民族大学学报(自然科学版),2009,30(2):22-26.
[11] 戴玉刚. 藏文网页采集技术研究[C]//第十一届全国民族语言文字信息学术研讨会论文集.2007:527-535.
[12] 珠杰,欧珠,格桑多吉等.基于DOM修剪的藏文Web信息提取[J].计算机工程,2008,34(24):58-60.
[13] 李文博. 基于XML的藏文网页的信息抽取与转存技术研究[D].西北民族大学硕士学位论文,2006.
[14] 刘汇丹,芮建武,吴健,等.藏文网页的编码识别与转换[C]//中文信息处理前沿进展——中国中文信息学会二十五周年学术会议,2006:573-580.
[15] 孙茂松.基于互联网自然标注资源的自然语言处理[J]. 中文信息学报,2011,25(6):26-32.
[16] 黄昌宁,李涓子.语料库语言学[M]. 北京:商务印书馆.2002.
Mining Tibetan Web Text Resources and Its Application
1,2, MA Longlong1, WU Jian1, HE Yeping1
(1. Institute of Software, Chinese Academy of Sciences, Beijing 100190, China;2. Graduate University of the Chinese Academy of Sciences, Beijing 100049, China)
Based on link analysis and Tibetan encoding detection, this paper focuses on mining the Tibetan text resources over the internet with a crawler, and analyzes the distribution of Tibetan text. Statistical data shows that, more than 50% inland Tibetan web sites are hold by organizations in Qinghai province, and about 87% web pages belong to 31 large web sites. People prefer to use Unicode as the encoding of their new web pages rather than legacy encodings. It is practical to to extract Tibetan text from the pages with the natural tag information, such as HTML elements, column information and punctuations. The text can be used to build raw corpus, text classification corpus, and internet word/phrase corpus and so on. Word frequency statistics and language model can also be derived. In addition, some bilingual corpus can also be extracted.
Web; corpus; text mining; information extraction; Tibetan information processing; Chinese information processing

刘汇丹(1982—),博士,工程师,主要研究领域为操作系统中文信息处理、多语言信息处理。E⁃mail:huidan@iscas.ac.cn洪锦玲(1981—),硕士,工程师,主要研究领域为多语言信息处理。E⁃mail:jinling@iscas.ac.cn诺明花(1981—),博士,助理研究员,主要研究领域为多语言信息处理。E⁃mail:minghua@iscas.ac.cn
1003-0077(2015)01-0170-08
2012-04-16 定稿日期: 2012-06-26
国家自然科学基金(61202219,61202220,61303165);中国科学院信息化专项经费资助(XXH12504-1-10)
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
西藏研究(2021年1期)2021-06-09
文化创新比较研究(2020年13期)2021-01-14
布达拉(2020年3期)2020-04-13
天津外国语大学学报(2020年1期)2020-03-25
西夏学(2019年1期)2019-02-10
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
