
百度百科网页质量的自动化评价
2015-05-05 03:01仝召娟
信息资源管理学报 2015年2期
仝召娟 许 鑫
(1.上海财经大学图书馆,上海,200433; 2.华东师范大学商学院信息学系,上海,200241)
百度百科网页质量的自动化评价
仝召娟1许 鑫2
(1.上海财经大学图书馆,上海,200433; 2.华东师范大学商学院信息学系,上海,200241)
本文给出了一种高度自动化、可操作性强的百度百科网页质量评价方法。论文首先阐述了百度百科网页质量评价的必要性,介绍了国内外网页质量评价的现状;然后给出了百度百科网页质量的自动化评价思路,包括确定并自动化提取网页特征值、训练评价模型和自动化评价网页质量等步骤;以百度百科中“中华烹饪文化”相关的网页为实验对象,在对比分类结果的基础上,选取J48分类器实现了自动化评价,并探讨了各特征值对评价结果的影响;最后讨论了这种自动化评价方法的局限及后续研究。
网页质量 百度百科 自动化评价
1 引言
无论是日常搜索还是学术活动中,百度百科都已成为满足人们信息需要的重要工具。百度百科从2006年4月上线至2014年5月,已有470余万用户为其贡献了超过800万的词条[1]。日常搜索中,百度百科的网站访问比例约占百度域名访问比例的8.5%,人均页面访问量约为3.3个,居百度新闻、百度图片之前[2]。在学术活动中,开放式网络百科信息的影响力也在逐步上升,2006~2012年,中国学术期刊网络出版总库中,来自百度百科、维基百科、搜搜百科、互动百科的引用记录共有16041条,其中来自核心期刊的引用共有4447条,由此可见作者和期刊二者均在一定程度上默许了百科类信息作为参考文献[3]。
百度百科内容为用户生成的概念性、定义性信息,这保证了其较高的内容更新速度和参考价值。尽管百度百科有质量审核制度,但其信息质量很大程度上依赖于词条创作人员和审核人员,而词条创作人员和审核人员有很多不确定因素,如主观性、认知程度等。另外,百度百科的创作元数据随意性较强,用户在创建词条时,某些字段如参考文献、标签等可以为空,这使得用户有了词条创作自由的同时,其内容可信性下降。自由的内容生成机制、不完善的质量评价措施和海量的网页数目,使得百度百科网页质量的评价仍是一个亟需解决的问题。
2 网页质量评价现状
国内外关于网页质量评价的研究较多,对这些研究中用到的评价方法进行归类,大体包含以下一些技术路线:
(1)用户评价方法。Rafiei等给出了一种基于用户访问模型的网页质量评价方法,实现了Topic试验系统用以测试一个寻找特定主题的随机访问用户愿意访问此网页的概率[4]。薛宇飞等比较和分析了基于用户浏览关系图结构的几种主要网页质量评估算法[5]。张甫等从用户角度出发,建立了一套基于用户信息需求的网页相关性评价方法[6]。用户评价方法以信息利用者为中心,提高用户体验,但用户评价网页时往往有一定的主观因素,不同用户对于同一网页质量的评价可能差别很大,很难有一个客观明确的标准。
(2)基于网页本身特征的定量评价方法。Laporte等在评价医学类网络信息资源时提出通过计算网络资源被检索或引用的次数来测定网络资源的重要性[7]。Bauer等人研究了网址类型和其对应的网页质量之间的关系[8]。Joachims等提出了用点击量来反映网页与用户需求的相关性方法[9]。Adler等人给出了利用作者信用评级系统来控制维基百科的网页质量的方法[10]。Blumenstock通过实验得出文章长度和维基百科文章质量存在很强的正相关性的结论[11]。Lipka等研究了写作风格和维基百科文章质量之间的关系[12]。这类方法的研究对象多为外文网页,试图通过某个网页外在特征来判定网页质量,这对海量网页信息的评价有重要借鉴意义,此类方法大多未考虑多个网页特征间的相互影响。
(3)基于网页排名的评价方法。Pagerank方法是被公认较为有效的网页排名评价方法,国外相关研究较多。国内袁毅等人通过实例研究了Pagerank评价网页质量的可靠性及可行性[13];过仕明分析了Pagerank技术及其存在的不足,并结合用户对页面的点击率建立了网页重要性的综合评价模型[14]。Pagerank评价方法的前提假设是“质量高的网页会有较多的链接”,这种方法广泛应用于互联网网页评价,但一些低质量网站正是利用这一前提假设,通过人为增加网页链接数以提高网页的Pagerank值,从而使网页成为搜索引擎认为的高质量网页。
(4)基于评价指标体系的评价方法。Smith等人[15]、Harris[16]、Wilkinson等[17]分别提出了不同的评价指标体系,他们共同考虑的方面主要包括目的和用户群,信息内容(范围、准确性、权威性、新颖性、时效性),信息组织(元信息、导航、美观),信息利用(可获取、稳定、界面友好)等指标。国内的窦志[18]、梁君[19]、王巍[20]、李洋[21]、魏超等[22]分别基于不同角度给出了各自的评价指标体系。刘鹏程等[23]、唐梦莎等[24]、许卫卫等[25]在给出指标体系的基础上还通过手工评分的方法对结果进行评价。通过建立指标体系对网页进行质量评价的方法能够较为全面客观地反映网页质量,但这种方法需要大量的人工工作,且某些指标一定程度上依赖于评价者的主观认知。
(5)其它评价方法。Wohner等人在统计的基础上,给出了基于生命周期的网页质量评价方法[26]。雷粉红对各种评价方法进行了对比分析后,提出了HFGH算法评价模型[27]。王海鹰等人利用蚁群算法量化用户的偏爱度,提出了一种多目标优化模型的网页价值综合评价体系[28]。在微博广泛应用的背景下,齐娜等人还对医疗健康领域的微博信息的质量问题作了探讨,综合问卷调查、统计分析、专家访谈、对比分析等方法得出网络信息质量问题的主要原因[29]。这些方法为网页质量评价提供了一些新的思路和视角。
以上方法都在一定程度上推动了网页质量评价的研究,然而这些方法仍需要大量的手工工作。文献[10-12]以英文的维基百科网页质量为对象展开了研究,其研究探讨了某一类网页特征对维基百科网页质量的影响,但由于语言的不同,这些研究结论未必适用于中文百科类网页。本文参考了网页特征与网页质量可能相关这一前提假设,在此基础上,较为全面地结合百度百科网页的多个特征,实现从网页信息采集到网页特征获取,再到网页质量评价多个环节的自动处理,这对海量中文百科类网页的质量评价有较强的实践意义。
3 百度百科网页质量自动化评价框架
由上述相关文献[7-14]可知,一些可定量的网页特征,包括文章长度、网址类型、链接情况等可能和网页质量之间存在相关关系,某个网页特征值和网页质量之间的对应关系可能是两元线性相关、非线性相关,多个网页特征值和网页质量之间可能是多元复相关,当然也有某些特征值与网页质量无关联。对此,本文在这些可能的相关关系基础上,引入机器学习的方法来对网页质量进行自动分类。
机器学习是人工智能的重要研究领域之一,其主旨是利用计算机模拟或实现人类学习活动,在一定的数据学习经验基础上,使机器建立起特征值和结果之间的联系,基于这种联系,机器对新输入的条件值进行判断分析,从而给出判断结果。自出现以来,机器学习已发展成为一门涉及多个领域的交叉学科,涉及统计学、概率论、统筹学、计算机算法等学科知识,在很多领域中被研究和应用。利用机器学习方法进行网页信息质量评价的框架可简单表示为图1。
按照学习策略,机器学习可以分为机械学习、示教学习、演绎学习、类比学习、解释学习、归纳学习等。其中以接收为学习主要目标的是机械学习和示教学习。机械学习是其中最简单的学习方法,机器无需推理转换,只需接收知识;示教学习仍是以接收知识为主的学习形式,但需要对不断接收的知识进行整合。演绎学习类似于公理推导的过程,其反面为归纳学习。类比学习涉及的模块更多,需要通过比较找出两种知识的相同相异之处,进而推导出目标知识。解释学习和本体的概念有类似之处,机器通过学习概念、实例和操作规则,实现解释概念、实例和操作间关系的目的。归纳学习是较高级的学习方法,机器需要利用提供的实例和反例归纳出某个概念的描述,归纳学习的应用较广泛,因为在完成归纳学习的基础上,机器很容易判断出一个新的实例是否属于该概念的描述范围,这就实现了利用机器学习进行分类的功能。

图1 基于机器学习的网页信息质量评价框架
按是否给出分类结果,机器学习可分为监督学习和无监督学习。监督学习即利用已知类别的样本,在机器学习的过程中给出学习结果的评判。机器在接收到原来结果是否正确的基础上,通过不断调整算法,使学习误差尽量减小,以完成分类或预测。无监督学习即在机器学习的过程中,不提供给机器学习结果,而让机器通过归纳学习机制,自主完成学习的过程,这种方法通常用于处理未被分类标记的样本集。
针对像百度百科这样的开放式网络百科类的信息资源来说,机器需要在已知小样本信息质量数据所属类别的基础上,对未分类的数据做出类别判断,因此本文用到的机器学习方法属于归纳学习和监督学习。
基于机器学习的网页信息质量评价本质上是一个分类问题。从数据流动的角度来看,将网页数量记为n,网页可分别记为1,2,…,m,…,n;假定选取的网页特征值共μ个,网页特征值可分别记为记为α,β,…,μ,则第n个网页对应的一组特征值数据可记为(αn,βn,…,μn)。则n组网页的特征值数据可记为(α1,β1,…,μ1),(α2,β2,…,μ2),…(αm,βm,…,μm),…,(αn,βn,…,μn)。n组网页特征数据中,选取前m组数据作为训练集的特征值部分,其余的(n-m)组数据作为测试集。接下来,对m组训练集数据对应的网页进行质量评价,将评价结果记为φ,则含有评价结果的第m组训练集数据为(αm,βm,…,μm,φm)。利用机器学习算法,通过建立分类模型,得到(αm,βm,…,μm)与φm的对应关系。对比不同分类模型的分类结果,选取评价准确率最高的作为分类器。最后,将(n-m)组不含评价结果的测试集数据载入分类器中;分类器根据训练过程中学习到的对应关系,得到第n个网页的评价结果φn。至此,所有数据均得到了对应的评价结果。
基于机器学习方法对网页信息质量进行分类大体上可以分为确定特征值、提取特征值、训练并选取模型、利用所选模型进行网页质量评价等几步。具体到百度百科,利用机器学习方法进行自动化质量评价的步骤可表示为图2。

图2 百度百科网页质量自动化评价的步骤
3.1 选取百度百科网页特征
选取百度百科网页特征时,需要兼顾可获得性与相关性,最理想的特征集选取应该能够以最简单的特征较好地实现网页信息质量的分类。通过对百度百科随机网页的源代码分析可知,可以通过网页采集器一次获取的数据有:网址、网页标题、摘要、正文、源代码、编辑次数、最近更新等。通过简单的Excel函数,还可以获取文章长度以及最近更新时间距目前时间的间隔。
编辑次数即网页从生成至今被修订的次数。在网页内容可被用户自由编辑的环境下,通常一个网页的内容被认同时,网页阅览者不会对网页进行编辑修订。因此可认为编辑次数和用户对网页整体质量的评价有一定相关性。
最近更新即最近一次网页被生成或修订的具体日期,网页被生成或修订的日期距离现在越近,则其内容的新颖性和时效性更强。新颖性、时效性是网页内容质量评价重要指标之一[15-17]。最近更新是一个具体的日期,本文将计算出目前时间和最近更新的月数差以方便后续数据处理,这一特征值可表述为“更新距今月数差”。
另外,直观上某个网页的内容字数越多,其内容也越可能更丰富,前人的文献也证明了这种相关性[11],因此本文也将文章长度列为指标之一。本文将统计网页正文对应的字数作为文章长度指标。
从网址的后缀可以看出其域名类型,研究[8]表明域名类型和网页质量之间存在关联,但百度百科所有网址对应的域名类型均为表示工商企业“.com”,不具有分类上的意义;网页标题、摘要、源代码属于可获取指标,但暂无研究或实验表明其与网页质量间存在关联。结合上述分析,同时在相关实验探讨之后,本文最终选取了三个网页特征值进行实验:编辑次数、更新距今月数差、文章长度,这三个网页特征值被定义为α、β、μ。
3.2 自动化提取与处理网页特征值
本文选取LocoySpider[30]和Excel对百度百科的网页特征进行自动化提取与处理。LocoySpider是一款常用的网络数据采集软件。通过百度百科网页的的源代码分析,本文采取前后截取的方式,利用LocoySpider采集待评价的n个网页的网页信息,直接采集到的数据有网址、网页标题、正文、编辑次数、最近更新等;将这些数据保存在一个Excel中,共得到n组网页特征值数据,然后利用Excel中的日期差函数“DATEDIF”处理“最近更新”一列,利用文本长度函数“LEN”处理“正文”一列,自动得出“更新距今月数差”和“文章长度”。
在得到这些初始数据后,还需要初步检查这些数据的完整性和合理性,例如所有数据都应为不可缺省的自然数,再比如文章长度的数据反映的是网页内容的字数,若此数据过小,应返回网页查看正文内容是否抓取完全。
3.3 训练数据并选择学习模型
训练与评价阶段用到的主要工具为基于JAVA环境下开源的机器学习软件Weka(Waikato Environment for Knowledge Analysis)[31]。在得到网页特征值数据后,将这些数据分成两部分,从n组网页特征值中选取前m组数据,则n组数据被分为(1,2,…,m)和(m+1,m+2,…,n)两部分。人工评价对应于(1,2,…,m)的m个网页的质量,其中第m个网页的评价结果记为φm。含m组特征值(αm,βm,μm)和评价结果φm的数据将作为训练集。训练集的评价结果将直接影响网页质量自动化评价的精确度,因此人工评价时应尽可能精确,保证其科学合理性。
按照Weka对文件格式的要求,将含有网页特征值和评价结果的训练集数据进行格式转换并载入,在Classify功能下选取不同的算法训练数据。对比不同算法得到的分类结果,选取精确度较高的算法对应的模型作为网页质量分类器。
3.4 自动化评价网页质量
将(n-m)组测试集(m+1,m+2,…,n)的网页特征值载入所选分类器中。对于每一组新输入的网页特征值(αn,βn,μn),网页质量分类器将根据之前的学习规则对其进行判定,根据特征值和评价模型的相似度,给出每一组特征值新的评价结果φn,便得到了测试集对应质量的评价结果(φm+1,φm+2,...,φn)。
4 实验与讨论
中华烹饪文化博大精深,既关乎日常实践,又是一种独特的物质和精神财富。本文作者曾利用互联网信息资源构建了中华烹饪文化专题知识库[32],正是在此过程中开始了对网页质量的自动化评价研究。本文以“中华烹饪文化”作为检索词,在百度百科中进行词条搜索,截止2013年7月15日,共得到相关词条1330条,以此数据集作为实验对象进行网页信息质量自动化评价实验。
4.1 实验数据预处理
本文采用LoclySpider V7.7版本对网页特征进行初步采集。为了综合比较不同特征选取下的比较分类效果,在初步采集时尽可能多地采集了各类网页特征,包括网址、网页标题、正文、源代码、编辑次数和最近更新等信息。因为除了最终选取的3个特征以外,本文也在预研究阶段对基于网址URL特性分类、网页标题与正文相似度计算、根据“中华烹饪文化”字样分别在网页标题或正文中出现赋权等其它特征选取策略进行了实验,最后依据“最省力”原则,在最终实验结果可以接受的情况下选取了最简单的3个特征。
具体的数据采集及处理包括在采集配置页面中批量导入检索“中华烹饪文化”所得到的1330个网址,即网页个数n=1330;然后根据源代码填入最终所选取特征的截取规则,并将相关记录保存到本地Excel文件;再按照前文所述原则,检查数据的完整性和合理性。进一步对Excel文件中的数据进行处理,对Excel文件的“正文”列使用函数“=LEN()”,得到新的一列“内容长度”;对“最近更新”列使用函数“=DATEDIF(“最近更新”,”目前日期”, “M”),得到新的一列“更新距今月数”;最后将“编辑次数”和这两列另存至新的Excel中。
4.2 评价小样本网页质量
将1330个网页分为两部分,随机抽取其中的200个网页作为小样本网页,即m=200。含有小样本网页特征值和质量分类结果的数据即训练集,其余只含有网页特征值的数据为测试集,训练集和测试集数据分别保存在两个Excel文件中。为尽可能保证评价标准的科学与严谨,研究中参照了以前研究者对于网页质量评价的一些研究成果[15-25],以网页与主题的相关性、文本丰富度、可信性、可读性、新颖性等作为实际标引网页质量的标准,从信息的内容、组织和利用各个层次对网页质量进行综合评价,评价结果被标记为“H”(高质量)和“L”(低质量),即φ的值为“H”或“L”。
4.3 训练数据并选取模型
按照Weka3.6.9版本对文件类型的要求,在训练集和测试集中添加必要的属性和关系声明,并转存为“.arff”文件。需要注意的是,评价结果必须放在最后一列,测试集中需要用“?”表示其评价值为空。
在Explorer模块中载入训练集,在“Classify”功能中选择十折交叉验证,选择不同的分类算法进行数据训练,对比分析各结果发现,选用RandomForest算法、ADTree算法、J48算法的精确度较高,分别为83%、85%、87%,其中J48算法得到的结果精确度最为理想。从图3所示的混淆矩阵中可以看出,J48算法分类器对于高质量的网页和低质量网页的召回率分别为88%和83%,其相比较而言对于高质量网页的召回率更高些。J48算法的基本思想是不断选择最优的属性并建立相应节点,对数据集作划分,其优点是产生的分类规则易于理解,准确率较高,缺点是效率较低。
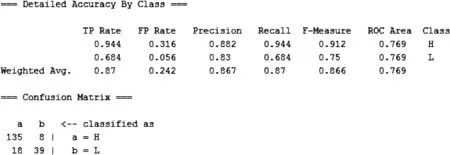
图3 用J 48算法训练小样本特征值的结果
4.4 自动化评价结果
选择“Classify”功能中的“Supplied test set”,将其余的1130组数据载入所选的J48分类器中,分类器根据之前的学习经验,对照新输入的每一组特征值,开始自动化评价。结果显示,1130个百度百科网页中共有1027个高质量网页和103个低质量网页。结合之前训练集的评价结果可以看出,在进行试验的所有1330个网页中,高质量网页数量共有1180个,占所有网页数目的88.7%,这也表明在“中华烹饪文化”领域,百度百科相关网页的整体质量较高。
为了研究各个特征指标对最终结果的贡献,本文将三个特征值α,β,μ的其中一个逐一剔除,再次进行试验。评价结果显示,剔除文章长度α这一特征值对试验结果的影响最大,剔除编辑次数β和更新距今月数差μ对结果的影响较小且影响度基本相同,这也表明百度百科的网页质量对文章长度α的依赖性更强。
5 结语
本文在前人研究的基础上,提供了一种自动化实现百度百科网页质量评价的方法,以最为简单的3个特征指标实现了87%的网页信息质量分类精度,对于海量网页的质量评价具有较强的实践意义,在国内百科类网页质量自动化评价研究方面具有一定的创新意义。同时,随着网页生成越来越规范,这种方法对于任意类型网页的质量评价也具有一定的借鉴意义。由于本文重点考虑网页特征的可自动获取的特性,因此一些需要大量手工统计才能获取的网页特征,如网页好评率、作者等级及擅长领域等未被讨论,这是本文的局限所在,也是海量网页质量评价面临的一个难题。进一步研究将集中在如何保证训练集评价结果的科学性,并在此基础上通过领域专题对比、网页类型对比、特征指标选取对比和分类算法选取对比,将该自动化评价思路推广至更多领域专题,应用于更多网页类型。
[1] 百度百科. 百度百科[EB/OL].[2014-05-24]. http://baike.baidu.com/
[2] Alexa China[EB/OL].[2014-05-14]. http://alexa.chinaz.com/index.asp?domain=baidu.com
[3] 丁玉东, 张春峰, 刘颖. 期刊论文引用中文Wiki网络百科的统计与分析[J]. 情报杂志, 2013(3): 113-116
[4] Rafiei D, Mendelzon A O. What is this page known for? Computing Web page reputations[J]. Computer Networks, 2000, 33(1): 823-835
[5] 薛宇飞,刘奕群,张敏,等. 基于用户浏览图的网页质量评估方法的比较分析[C]//中国计算机语言学研究前沿进展(2007-2009). 北京:中文信息学会,2009:491-497
[6] 张甫, 吴新年, 张红丽.基于用户信息需求的网页相关性评价研究[J]. 情报理论与实践,2011(5):30-33
[7] LaPorte R E, Marler E, Akazawa S, et al. The death of biomedical journals[J]. British Medical Journal, 1995, 310(6991): 1387-1390
[8] Bauer C,Scharl A.Quantitive evaluation of Web site content and structure[J].Internet Research,2000,10(1):31-44
[9] Joachims T, Granka L, Pan B, et al. Accurately interpreting clickthrough data as implicit feedback[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval. New York: ACM, 2005: 154-161
[10] Adler B T, De Alfaro L. A content-driven reputation system for the Wikipedia[C]// Proceedings of the 16th international conference on World Wide Web(WWW’07). New York:ACM, 2007:261-270
[11] Blumenstock J E. Automatically assessing the quality of Wikipedia articles.[EB/OL].[2014-09-24].https://escholarship.org/uc/item/18s3z11b
[12] Lipka N, Stein B. Identifying featured articles in Wikipedia: writing style matters[C]// Proceedings of the 19th international conference on World Wide Web. New York: ACM, 2010:1147-1148
[13] 袁毅, 徐曼. PageRank判断网页质量的可靠性分析[J]. 情报杂志,2006(2):58-60
[14] 过仕明. PageRank技术分析及网页重要性的综合评价模型[J]. 图书馆论坛,2006(1): 80-81
[15] Smith, Alastair G. Testing the Surf: Criteria for evaluating internet information resources[J].The Public-Access Computer Systems Review 1997,8(3):1-14
[16] Harris R. Evaluating Internet research sources[OL].[2014-07-15] http://www.virtualsalt.com/evalu8it.htm
[17] Wilkinson G L, Bennett L T, Oliver K M. Consolidated listing of evaluation criteria and quality indicators[EB/OL].[2014-07-15]. http://itechl.coe.uga.edu/faculty/gwilkinson/wsbeval.html
[18] 窦志. 网络体育信息资源评价探究[J]. 武汉体育学院学报,2006(9):93-95
[19] 梁君. 第三方B2B电子商务网站质量评价体系研究[D]. 杭州:浙江大学,2008:38-49
[20] 王巍. 基于B/S结构的网络学术信息资源评价系统的研究与实现[D]. 大连:大连交通大学,2009:24-34
[21] 李洋. 网上学术信息质量评价研究[D]. 长春:吉林大学, 2010:39-46
[22] 魏超, 陈飞, 许丹飞,等. 网页质量评价体系的研究[J]. 中文信息学报, 2011,25(5): 3-8
[23] 刘鹏程, 王德斌, 洪倩,等. 国内有关儿童发热的网络信息质量评价初探[J]. 中华疾病控制杂志,2010(5):436-439
[24] 唐梦莎, 王德斌, 柴静,等. 国内有关儿童龋齿的网络信息质量评价[J]. 预防医学情报杂志,2010(7):557-561
[25] 许卫卫, 张士靖, 刘海通,等. 网络医疗卫生信息资源评价研究——以心理健康网站为例[J]. 医学信息学杂志,2012(6):50-55
[26] Wohner T, Peters R. Assessing the quality of wikipedia articles with lifecycle based metrics[J]. WikiSym, 2009(10):25-27
[27] 雷粉红. 网络科技资源质量评价方法的研究[D]. 西安:西北大学,2010:28-41
[28] 王海鹰, 魏颖. 基于蚁群算法的多目标网页综合评价策略[J]. 计算机工程与应用,2011,47(4):223-225
[29] 齐娜, 宋丽荣. 医疗健康领域微博信息传播中的信息质量问题[J]. 科技导报,2012,30(17):60-65
[30] 火车头数据采集平台. 火车采集器LocoySpider网页数据采集利器[EB/OL].[2014-07-15]. http://www.locoy.com/
[31] WEKA. Weka 3: Data Mining Software in Java[EB/OL].[2014-07-15]. http://www.cs.waikato.ac.nz/ml/weka/
[32] 许鑫, 郭金龙. 基于领域本体的专题库构建——以中华烹饪文化知识库为例[J]. 现代图书情报技术,2013,29(12):2-9
Automatic Evaluation of Baidu Encyclopedia Web Pages
Tong Zhaojuan1Xu Xin2
(1.Shanghai University of Finance & Economics Library,Shanghai,200433;2.Department of Information Science,Business School,East China Normal University,Shanghai,200241)
This paper presents an automatic and practical evaluation method of Baidu encyclopedia web pages. Firstly it expounds the necessity of the quality evaluation of Baidu encyclopedia web pages and the current situation of the web pages quality evaluation methods. Then the paper introduces the framework of automatic evaluation of the Baidu encyclopedia web pages quality, including confirming and automatically extracting the web pages’ features, training the evaluation model and automatically evaluating the web pages’ quality. Taking the webpages related to Chinese cuisine culture from Baidu encyclopedia as experimental subjects,based on the comparisons between the classification results,this paper selects the classifier to realize the automatic evaluation and discusses the influence of the eigenvalues on the evaluation results. Finally, it discusses the limitations and further direction of this automated evaluation method.
Web pages quality Baidu encyclopedia Automatic evaluation
仝召娟,女,助理馆员,硕士,研究方向为数字图书馆、信息资源建设;许鑫,男,副教授,博士,研究方向为管理信息系统、网络信息处理与分析,Email:xxu@infor.ecnu.edu.cn。
G203
A
2095-2171(2015)02-0063-07
10.13365/j.jirm.2015.02.063
2014-07-10)
猜你喜欢
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
数学物理学报(2021年3期)2021-07-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
成都信息工程大学学报(2021年6期)2021-02-12
创新作文(5-6年级)(2019年3期)2019-09-03
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
小溪流(故事作文)(2014年6期)2014-07-31
