
脉冲神经元序列学习方法的影响因素研究
2015-12-06 06:11徐彦,杨静
计算机工程 2015年11期
徐 彦,杨 静
(1.南京农业大学信息科技学院,南京210095;2.北京师范大学珠海分校管理学院,广东珠海519087)
·人工智能及识别技术·
脉冲神经元序列学习方法的影响因素研究
徐 彦1,杨 静2
(1.南京农业大学信息科技学院,南京210095;2.北京师范大学珠海分校管理学院,广东珠海519087)
远程有监督方法(ReSuM e)通过计算神经元运行时的输出脉冲和输入脉冲的时间差调整突触权值,是目前在理论基础和实际应用上都较出色的脉冲神经元有监督学习方法,但是当期望输出脉冲序列较长时,ReSuM e方法的学习精度较低。为解决该问题,分析影响ReSuM e方法性能的2个主要因素:在线、离线学习方式及学习过程中更新突触权值时输入脉冲的选取。在线学习精度一般高于离线学习,但是学习精度的差异随着参数或者其他设置的不同有较大差别。针对输入脉冲的选取,提出一种新的学习策略以改进ReSuM e方法,该策略在计算权值调整幅度时综合考虑期望输出与实际输出脉冲序列,从而避免增强与减弱权值时输入脉冲出现重叠干扰。实验结果表明,新的学习策略可以有效提高ReSuMe方法的学习精度及其解决实际问题的能力。
脉冲神经元;远程有监督方法;脉冲序列学习;脉冲神经网络;脉冲反应模型
1 概述
在生物神经系统中,神经元之间通过具有特定频率和形态的脉冲序列来传递信息[1]。这些信息通过激发率和激发时间2种方式进行编码[2]。传统人工神经元模型可以看成是激发率编码的一种近似。但是,仅使用激发率编码会使得以精确激发时间表达的信息丢失。因此,更加接近真实神经元运行方式的脉冲神经元和网络被提出[3]。脉冲神经元以脉冲激发时间作为输入和输出,可以更好地模拟生物神经元,进而可以更有效地模拟人的智能活动。现已证明,脉冲神经网络具有比传统人工神经网络更强的性能[4-5]。
在人工神经网络的研究中,有监督学习理论一直都属于核心研究内容。脉冲神经元与网络的有监督学习也是其研究领域中一个极重要的组成部分。以脉冲激发时间编码的脉冲神经网络的有监督学习是在一段运行时间内输出神经元通过学习能够精确地在指定的时刻激发出脉冲。由于脉冲神经元的运行方式接近于真实的生物神经元,而人们对生物神经系统如何进行有监督学习的完整机理尚不清楚,因此脉冲激发时间编码的脉冲神经网络有监督学习方法研究有其自身的特点和难点。
脉冲神经元有监督学习方法的研究是实现更复杂的神经网络有监督学习的基础。基于时间编码的脉冲神经元的有监督学习就是具有多个输入突触的单个脉冲神经元通过学习在期望时刻激发出脉冲,即脉冲序列,所以又称为脉冲序列学习。为了更好地模拟真实神经元,大多数研究者都致力于寻找具有生物学基础的有监督学习方法[6-7]。
文献[8]提出一种称为远程有监督方法(Remote Supervised M ethod,ReSuM e)的脉冲神经元有监督学习方法。该方法由输出脉冲序列与输入脉冲序列结合时间相关可塑性(Spiking Tim ing Dependent Plasticity,STDP)规则[9]调整权值。ReSuM e方法具有明显的优点[10],但是研究者最初提出的ReSuM e方法存在着一些问题,其中较大的不足是当期望输出脉冲序列的时间段较长时,ReSuM e方法的精度下降较快[11],这直接影响了其解决复杂问题的能力。
针对ReSuMe方法进行深入研究可以得到提高其学习性能的方法,并且对脉冲神经网络有监督学习的研究具有较高的理论和实际价值。本文着重对ReSuM e方法学习时涉及的2个因素进行研究:(1)ReSuM e方法以在线和离线方式学习时的神经元性能差别;(2)初始ReSuM e方法权值调整时需要选取输入脉冲。
2 脉冲反应模型及ReSuM e方法
2.1 脉冲反应模型
虽然ReSuMe方法并不限定于适用某一种特定的脉冲神经元模型,但是本文以常用的脉冲反应模型(Spiking Response Model,SRM)[1]作为研究对象。对于其他脉冲神经元模型[1],本文研究结果一样适用。
在SRM模型中,神经元的输入为沿着众多突触传输到神经元的离散脉冲的到达时间,每一个脉冲到达后都会在神经元内部产生一个突触后电位(Postsynaptic Potential,PSP),神经元的内部状态即膜电位值(m embrane potential)为所有的输入脉冲产生的PSP在其各自传输突触权值影响下的总和。
假设神经元有N个输入突触,第i个突触有Gi个脉冲输入,它们到达神经元的时间集合记为,在当前时刻t(>0)之前最近的一次脉冲激发时刻为t(fr),则神经元的膜电位表达式为:
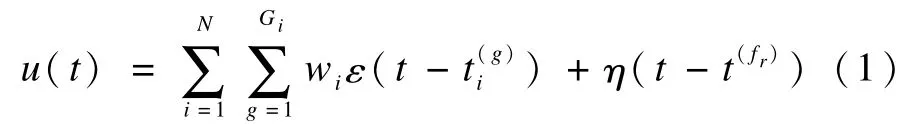
其中,wi是神经元第i个输入突触的权值。一个输入脉冲产生的PSP由反应函数ε(t)决定,本文中脉冲反应函数表达式为:
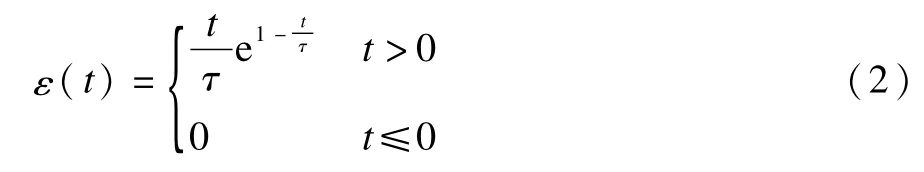
其中,τ是决定反应函数性态的时间延迟常数。
当神经元的膜电位在某个时刻由低到高超过激发阈值ϑ,神经元会在这个时刻激发出一个脉冲(本文用t(f)表示激发的脉冲及其激发时间),并且会进入一个在短时期内不会再次激发脉冲的过程,称为绝对不应期[12]。随后神经元会进入称为相对不应期[12]的过程,这时膜电位值较低并且难于再次激发脉冲。膜电位表达式中的η(t-t(fr))描述相对不应期的影响,函数η(t)的表达式为:
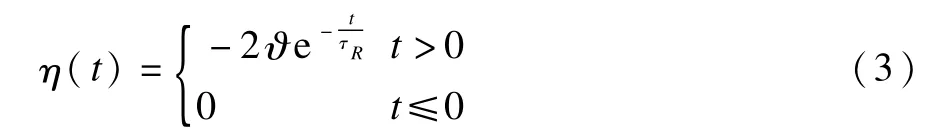
其中,τR是决定不应期函数性态的延迟常数。本文中只考虑离当前时刻最近的一个脉冲激发产生的不应期影响而忽略更早的其他脉冲激发。本文中脉冲神经元的参数设置如下:ϑ=1,τ=7,τR=80。
2.2 ReSuM e方法的权值更新规则
脉冲神经元的有监督学习是依据输入与输出脉冲序列通过调整神经元的突触权值来实现的。ReSuM e方法的权值更新分为2个部分。
(1)权值的增强:当神经元运行时遇到任何一个期望输出脉冲所在的时间点td,就要在这个时间点根据输入脉冲的时刻计算增强突触权值,对于第i个输入突触,其权值wi的增强调整规则[10]为:
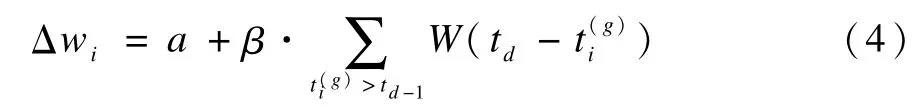
其中,td-1为td之前最靠近td的一个期望输出脉冲。
(2)权值的减弱:当神经元在运行过程中一旦激发出脉冲to,就要在这个实际输出脉冲的时间点根据输入脉冲的时刻计算减弱突触权值,对于第i个输入突触,其权值wi的减弱调整规则[10]为:
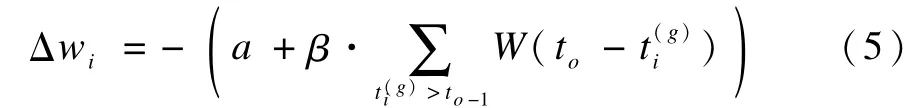
其中,to-1为to之前最靠近to的一个实际输出脉冲。
在式(4)、式(5)中的a是一个权值更新的常数,表示权值更新时一个恒定不变的更新量;β是学习速率。W(s)称为学习窗口函数,它决定了根据输入脉冲时刻与实际或者期望输出脉冲时刻之间的间隔得到的权值更新幅度。
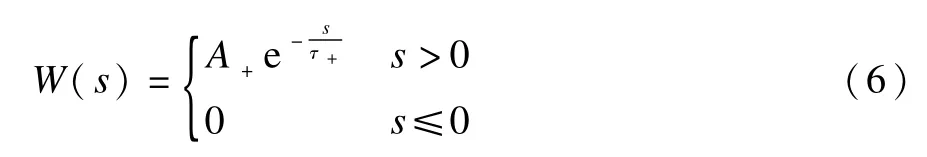
其中,A+是常数;τ+是决定学习窗口函数性态的时间延迟常数。本文实验中ReSuM e权值更新规则参数设置如下:a=0.001,A+=0.5,τ+=5。
已有研究结果显示,ReSuM e方法调整突触权值可以使神经元以较高的精度激发出期望输出脉冲序列。同时,ReSuM e方法具有较好的适用性,它可以适用于多种不同的脉冲神经元模型[10]。另外,ReSuM e方法采用的作为权值调整基础的STDP规则是生物神经元突触强度调整机制的理论总结,这使得ReSuM e方法具有十分明显的生物学基础。因此,无论在理论基础还是实际应用上ReSuM e方法都是目前较出色的脉冲神经元有监督学习方法。
在脉冲序列学习中,评价学习结果的好坏就是判断神经元在学习结束后实际激发的脉冲序列与期望输出脉冲序列的接近程度。这实际上是度量2个脉冲序列之间的距离。本文采用基于相关性的度量C[13]来描述该距离:
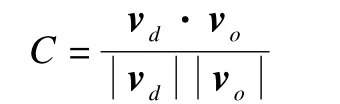
其中,vd和vo分别为期望输出脉冲序列和实际输出脉冲序列与高斯低通滤波器作卷积(离散)之后得到的向量。等式中的分子是2个向量的内积,分母是2个向量模的乘积。当2个脉冲序列完全相同时C值为1,随着它们的差别越来越大逐渐趋于0。
3 影响因素分析与学习策略的提出
3.1 在线与离线学习
已知传统BP算法有2种常见的运行方式,即在线方式和批处理方式[14]。这2种方式各有利弊,批处理方式可以消除样本学习顺序对学习结果的影响,使得学习更加稳定,而且更适合理论研究和并行处理;在线方式则需要更少的存储空间,当样本顺序正确时学习可以更快收敛,所以,通常性能更强。BP算法的这2种方式的区别为在线方式是在每一个训练样本输入网络计算后立刻调整权值,而批处理方式则是当所有样本都计算完成后统一调整更新权值。
对于脉冲神经元有监督学习的ReSuM e方法,也可以讨论类似2种学习方式在学习性能上的差异。根据ReSuM e方法的特点,神经元突触权值的调整可以按2种方式处理:(1)在神经元运行过程中遇到实际或期望输出脉冲时立刻调整更新权值;(2)在神经元运行过程中遇到输出脉冲时不立刻更新权值,而是在神经元运行完成后根据实际与期望输出脉冲序列计算更新权值。本文称第(1)种为在线学习方式,第(2)种为离线学习方式。
本文通过一组实验考察ReSuM e方法在这2种学习方式下性能。在实验中神经元输入与输出脉冲序列的长度由短到长逐渐变化,而其他设置保持不变。神经元有400个输入突触;输入与期望输出脉冲序列的激发率分别为10 Hz和100 Hz的Poisson序列;脉冲序列的长度在200 ms~3 200 ms内以间隔200 ms逐渐增加。在每种长度下分别进行50次实验,实验结果如图1所示。
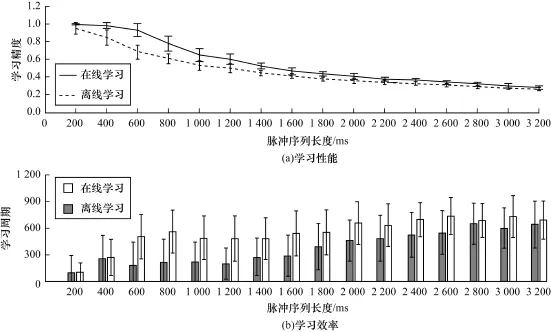
图1 初始ReSuM e方法基于在线和离线方式的学习效果对比
图1(a)表示度量C可以达到的最大值在50次实验下的平均值及均方误差;图1(b)表示度量C达到最大值所需要的学习周期数在50次实验下的平均值以及均方误差。由图1(a)可知,在学习精度上,2种方式下ReSuM e方法呈现出相似的结果,即随着期望输出脉冲序列长度的增加精度会逐步降低,这也是脉冲序列学习的一个普遍规律。比较2种方式的学习精度,可以发现以在线方式运行的精度在每一个序列长度下都高于离线方式。在400 m s~1 200 m s这一范围内在线方式的精度优势更加明显。例如在序列长度为600 ms时,在线方式的度量为C=0.936,而离线方式的度量仅为C=0.686。随着脉冲序列长度的增加,在线方式与离线方式下学习精度的差别越来越小。对于学习效率,由图1(b)可知离线方式下ReSuM e方法达到最大学习精度需要的平均学习周期数要少于在线方式。但是对于脉冲序列学习,在学习周期数没有巨大差别的情况下,学习精度的差别对于学习算法的实际应用影响更大。
由这一组实验可以发现,对于ReSuM e方法,在线方式在学习精度上优于离线方式。其原因为,除了在线方式固有的性能优势之外,还有一个可能的原因来自于生物学基础。脉冲神经元的运行方式仿照真实的生物神经元,而生物神经元是在有脉冲激发时按照一定的机制(如STDP)立刻调整突触强度,即在线调整,所以,脉冲神经元按照ReSuM e方法以在线方式进行有监督学习更加符合这一生物学规律,因此也获得了更高的学习精度。
3.2 输入脉冲的选取
ReSuM e方法的权值更新幅度是通过实际输出或期望输出脉冲与输入脉冲之间的时间差经过学习窗口函数计算得到的。在这些关键因素中期望输出脉冲的时刻是固定的,实际输出脉冲的时刻是由神经元运行产生的,这2个在计算权值更新的幅度时都不可更改。每个输入突触上输入脉冲的时刻是固定的,学习过程中也不能更改。但是在每一个实际或者期望输出脉冲之前需要考虑的输入脉冲的个数,即在窗口函数计算中考虑的输入脉冲个数是可以选择的。
在初始的ReSuM e方法中,期望输出脉冲序列与实际输出脉冲序列在学习时是独立的,即在遇到期望输出脉冲增强权值时,增强幅度的计算只涉及输入脉冲和当前期望输出脉冲,并且由于神经元激发出脉冲之后存在不应期[13],考虑的输入脉冲只位于当前时刻和前一个期望输出脉冲的时刻之间,如式(4)所示。对应地,在遇到实际输出脉冲减弱权值时只涉及输入脉冲和当前实际输出脉冲,并且考虑的输入脉冲只位于当前时刻和前一个实际输出脉冲的时刻之间,如式(5)所示。
如图2所示,Si为一个脉冲神经元的某一个输入突触,其上依时间次序传输到达神经元的输入脉冲依次为…;神经元的期望输出脉冲序列为Sd,其中前3个期望输出脉冲依次为;在某一次运行过程中神经元的实际输出脉冲序列为So,其中前2个实际输出脉冲为。
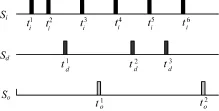
图2 ReSuM e方法学习时输入脉冲的选取
神经元在这次运行过程中,按照时间顺序最先到达的是第1个期望输出脉冲的时刻。按照ReSuM e方法,在这个时刻需要增强输入突触的权值。按照文献[8]中提出的初始ReSuM e方法,此刻对于输入突触Si的权值wi计算增强幅度需要考虑之前的输入脉冲。随着神经元的运行到达第一个实际输出脉冲的时刻,按照ReSuM e方法,在这个时刻需要减弱输入突触的权值,由初始ReSuM e方法,由于期望输出和实际输出脉冲序列在学习时互相独立,此刻对于权值wi计算减弱幅度需要考虑的输入脉冲为。神经元的运行到达第2个期望输出脉冲的时刻,此刻对于权值wi计算增强幅度需要的输入脉冲将不再考虑之前的,只需考虑位于和之间的。同样地,对于后面的期望输出脉冲的时刻以及实际输出脉冲的时刻,计算增强和减弱权值wi时将分别只考虑位于和之间的以及位于和之间。
上文直观地分析了初始的ReSuM e方法学习时在每一个输出脉冲的时刻计算权值更新时输入脉冲的选择方式,这种方式下期望输出脉冲和实际输出脉冲之间互不干扰、相互独立。图1中的实验是按照这种方式进行的,由在线方式的实验结果可知,这种方式下当期望输出脉冲序列长度较长时,ReSuM e方法的学习精度会有明显下降。例如,当脉冲序列的长度为600 ms时,学习精度可以达到度量C= 0.936,而当序列长度为1 200 ms时,度量下降为C= 0.606。这就是初始ReSuM e方法性能上的一个不足。分析原因,在这种方式下,输入脉冲对于期望输出脉冲和实际输出脉冲的计算是可以有重叠的。例如图2中,对和的计算都考虑了,而这种重叠会导致对同一输入突触权值增强和减弱之间发生干扰,这种干扰在一定程度上影响了初始ReSuM e方法的学习精度。
为了提高学习精度,本文对ReSuM e方法进行改进,提出一种新的学习策略,该策略改变学习过程中遇到期望输出脉冲或者实际输出脉冲时计算权值更新幅度所考虑的输入脉冲选择。其关键是对期望与实际输出脉冲在调整权值时选择的输入脉冲避免出现重叠。
在遇到期望输出脉冲td增强权值时,权值增强幅度的计算选择位于当前期望输出脉冲时刻和该时刻前最靠近该时刻的期望或实际输出脉冲之间的输入脉冲,其表达式为:
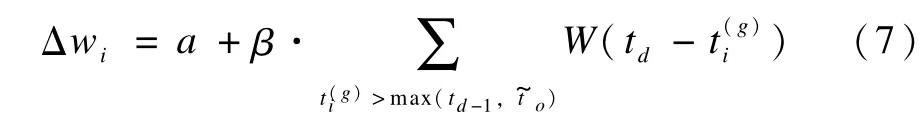
其中,td-1为td之前最靠近td的期望输出脉冲;为 td之前最靠近td的实际输出脉冲。
同样地,在遇到实际输出脉冲to减弱权值时选择位于当前实际输出脉冲时刻和该时刻之前最靠近该时刻的期望或实际输出脉冲之间的输入脉冲,其表达式为:
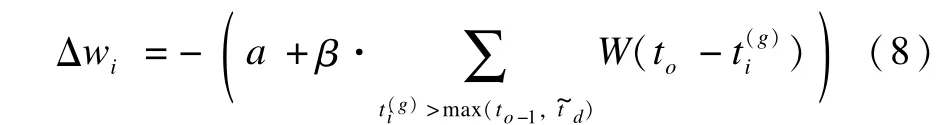
其中,to-1为to之前最靠近to的期望输出脉冲;d为to之前最靠近to的期望输出脉冲。
由上述学习策略可知,其消除了初始ReSuM e方法在权值更新过程中期望输出脉冲和实际输出脉冲互不干扰的特点,无论是增强权值还是减弱权值都要综合考虑期望与实际输出脉冲。
4 实验与结果分析
通过实验验证ReSuM e方法的学习策略效果,为了表述方便,称以本文提出的学习策略进行学习的ReSuM e方法为改进ReSuMe方法。前2组实验分别采用在线和离线方式运行。实验设定和图1的实验设定相同,即神经元有400个输入突触;输入与
期望输出脉冲序列的激发率分别为10 Hz和100 Hz的Poisson序列;脉冲序列的长度在200 m s~3 200 m s内以间隔200 m s逐渐增加。在每种长度下分别进行50次实验,本节实验中用于考察实验结果的数据和图1一致。实验结果分别如图3和图4所示。
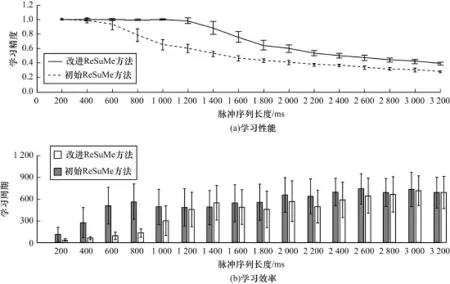
图3 改进ReSuM e方法和初始ReSuM e方法基于在线方式的学习效果对比
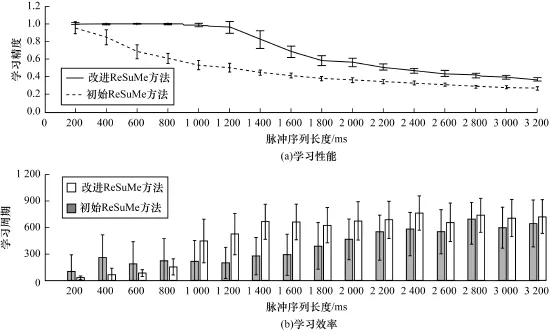
图4 改进ReSuM e方法和初始ReSuM e方法基于离线方式的学习效果对比
图3 显示在线方式下的实验结果。由图3(a)可知,本文提出策略有效提高了ReSuM e方法的在在线方式下的学习精度。从600 m s序列长度开始,改进ReSuMe方法的学习精度明显高于初始ReSuM e方法。例如,在1 200 m s时,初始ReSuM e方法的学习精度C为0.606,而改进ReSuM e方法的度量C为0.983。在200 ms~1200 ms的范围内,改进ReSuMe方法可以使C保持在0.98以上,即学习基本上接近完全成功。而初始ReSuM e方法只能在200 m s和400 m s 2点处获得接近完全成功的学习精度。由图3可以看出,在线方式下改进ReSuM e方法达到最大学习精度所需的平均学习周期数要少于初始ReSuM e方法,因此,本文策略也提高了ReSuM e方法的学习效率。
图4显示离线方式下的实验结果。由图4(a)可知,与在线方式下的结果相似,本文提出策略有效提高了ReSuM e方法在离线方式下的学习精度,而且相比初始ReSuMe方法,提高效果比在线方式下更加明显。在1 200 ms时,初始ReSuM e方法的学习精度C为0.503,而改进ReSuMe方法的度量C为0.956。在200 ms~1 200 ms的范围内,改进ReSuM e方法可以使度量C保持在0.95以上,虽然略低于在线方式,但对期望输出脉冲序列的学习依然接近完全成功。图4(b)显示离线方式下改进ReSuM e方法达到最大学习精度所需的平均学习周期数在大多数情况下多于初始ReSuM e方法。
图5比较了改进ReSuM e方法分别在在线和离线方式下的学习结果。图5(a)显示改进ReSuM e方法以在线方式运行的学习精度略高于离线方式下的学习精度,但是对比图1中初始ReSuM e方法在线和离线方式下学习精度的差异,改进ReSuM e方法在2种方式下的精度差别较小。由此可以看出,影响ReSuMe方法在线与离线方式下精度的因素很大程度上源于学习时相关参数和细节的设置。为了更加全面地衡量改进ReSuM e方法的学习效果,下面进行另一组实验。这组实验中神经元输入与输出脉冲序列的激发率比前面的实验高。更高的激发率会导致神经元需要学习激发的期望输出脉冲的个数和输入脉冲的个数增加,因此理论上学习的复杂程度和难度会相应增加。在实验中,神经元有400个输入突触;输入与期望输出脉冲序列都为激发率为200 Hz的Poisson序列;脉冲序列的长度在200 m s~2 800 m s内以间隔200 m s逐渐增加。在每种长度下分别进行50次实验。采用在线学习方式的实验结果如图6所示。由此可知,当输入和输出脉冲序列的激发率都为200 Hz时,改进ReSuM e方法的学习精度依然高于初始ReSuM e方法。但是对比图3可以发现,此时改进ReSuM e方法优于初始ReSuM e方法的幅度要小于激发率较低时的情形。在200 ms~1 400 ms长度范围内,改进ReSuM e方法相比初始ReSuM e方法的度量C高出0.09~0.15。在1 400 m s之后,两者的差距逐渐缩小,到2 000 m s之后2种方法的精度基本没有差别。由图6(a)可以看出,在这一组实验中改进ReSuM e方法的平均学习精度的均方误差明显低于初始ReSuM e方法。因此,当输入输出脉冲序列激发率较高时,改进ReSuM e方法学习精度的稳定性要优于初始ReSuM e方法。对于学习效率,由图6(b)可以看出,在脉冲序列比较短时,改进ReSuM e方法达到最大学习精度所需的平均学习周期数少于初始ReSuM e方法,但是当序列长度超过1 000 m s时,初始ReSuM e方法的周期数又少于改进ReSuM e方法,两者的差距随着序列长度的增加变得越来越少。
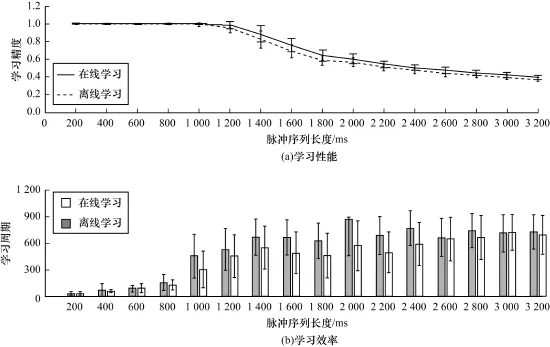
图5 改进ReSuM e方法基于在线和离线方式的学习效果对比
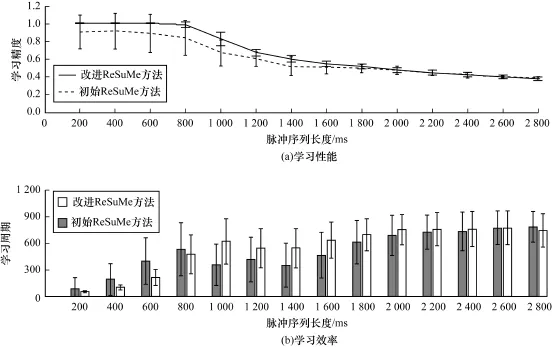
图6 当脉冲序列激发率较高时改进ReSuM e方法和初始ReSuM e方法的学习效果对比
综上所述,本文提出的学习策略通过改变学习窗口函数在计算时涉及的输入脉冲,在多种实验设定下都提高了ReSuM e方法的学习精度,该精度提高明显并且具有较高的普遍性。
5 结束语
脉冲序列学习是利用脉冲神经网络实现各种应用功能乃至人工智能的一个重要基础,对脉冲序列学习方法的研究是促进脉冲序列学习理论和应用发展的有效途径。ReSuM e方法是一种典型的脉冲序列学习方法。本文对ReSuM e方法在线与离线学习方式的分析结果表明,在线学习的精度一般都高于离线学习,但是精度的差异随着参数或者其他设置的不同有较大差别。通过在计算权值调整幅度时综合考虑期望与实际输出脉冲序列,提出一种可避免增强与减弱权值时输入脉冲出现重叠干扰的学习策略。实验结果显示,当期望输出脉冲序列较长时,这一学习策略可以有效提高ReSuM e方法的学习精度。在今后工作中,将继续深入研究ReSuM e方法以及脉冲序列学习的性质,探寻在期望输出脉冲序列较长时具有较高学习精度的方法,并进一步将ReSuM e方法和其他有监督学习方法相结合以提高整体性能。
[1] Gerstner W,Kistler W M.Spiking Neuron Models[M]. Cambridge,UK:Cam bridge University Press,2002.
[2] Rullen R V,Thorpe S J.Rate Coding Versus Temporal Order Coding:W hat the Retinal Ganglion Cells Tell the Visual Cortex[J].Neural Computation,2001,13(6):1255-1283.
[3] Maass W.Networks of Spiking Neurons:The Third Generation of Neural Network Models[J].Neural Networks,1997,10(9):1659-1671.
[4] Maass W.Fast Sigmoidal Networks via Spiking Neurons[J].Neural Computation,1997,9(2):279-304.
[5] Maass W.Noisy Spiking Neurons with Temporal Coding Have More Computational Power Than Sigmoidal Neurons[M].Cam bridge,USA:M IT Press,1997.
[6] Legenstein R,Naeger C,M aass W.W hat Can a Neuron Learn with Spike-timing-dependent Plasticity?[J]. Neural Computation,2005,17(11):2337-2382.
[7] Pfister JP,Toyoizumi T,Barber D,et al.Optimal Spiketiming-dependent Plasticity for Precise Action Potential Firing in Supervised Learning[J].Neural Computation,2006,18(6):1318-1348.
[8] Ponulak F.ReSuM e——New Supervised Learning Method for Spiking Neural Networks[D].Pozna,Poland:Poznan University of Technology,2005.
[9] Bi G Q,Poo M M.Synaptic Modifications in Cultured Hippocam pal Neurons:Dependence on Spike Tim ing,Synaptic Strength,and Postsynaptic Cell Type[J]. Journal of Neuroscience,1998,18(24):10464-10472.
[10] Ponulak F,Kasinski A.Supervised Learning in Spiking Neural Networks with Resume:Sequence Learning,Classification and Spike Shifting[J].Neural Computation,2010,22(2):467-510.
[11] Xu Yan,Zeng Xiaoqin,Han Lixin,et al.A Supervised Multi-spike Learning Algorithm Based on Gradient Descent for Spiking Neural Networks[J].Neural Networks,2013,43:99-113.
[12] Kandel E R,Schwartz J H,Jessell T M.Principles of Neural Science[M].New York,USA:McGraw-Hill,2000.
[13] Scheriber S,Fellous J M,Whitmer D,et al.A New Correlation-based Measure of Spike Timing Reliability[J]. Neurocomputing,2003,52-54:925-931.
[14] Haykin S.神经网络原理[M].叶世伟,史忠植,译.北京:机械工业出版社,2004.
编辑陆燕菲
Research on Affect Factors of Spiking Neuron Sequence Learning Method
XU Yan1,YANG Jing2
(1.College of Information Science and Technology,Nanjing Agricultural University,Nanjing 210095,China;2.School of Management,Zhuhai Cam pus,Beijing Normal University,Zhuhai 519087,China)
Remote Supervised Method(ReSuMe)ad justs the synaptic weights according to the time difference between output and input spiking during neuron runtime.Whether for the theoretical basis or the practical application,ReSuMe method is a kind of relatively excellent supervised learning method for spiking neurons.But when the desired output spriking sequence is long,the learning accuracy of ReSuMe method is relatively low.In order to discusse ReSuMe method more detailed and improve its learning performance,two factors that affect the learning performance of ReSuMe method are studied.The first factor is the offline or online learning model,the other is the choice of the input spiking considered when adjusting the synaptic weights.Online learning accuracy is generally higher than offline learning,but the different of learning precision is big with different parameters or other settings.And a new learning strategy is proposed for the second factor to improve the ReSuM e method,it considers input and output spiking sequence when calculates weight adjustment,avoids the overlap interference of input spiking when increases and decreases weights. Experimental results show that the new strategy can greatly improve the learning accuracy of ReSuMe method under different experiment settings.So it has a strong ability to solve practical problems.
spiking neuron;Remote Supervised Method(ReSuMe);spiking sequence learning;spiking neural network;Spiking Response Model(SRM)
徐 彦,杨 静.脉冲神经元序列学习方法的影响因素研究[J].计算机工程,2015,41(11):194-201.
英文引用格式:Xu Yan,Yang Jing.Research on Affect Factors of Spiking Neuron Sequence Learning Method[J]. Computer Engineering,2015,41(11):194-201.
1000-3428(2015)11-0194-08
A
TP183
10.3969/j.issn.1000-3428.2015.11.034
国家自然科学基金资助项目(61403205);中央高校基本科研业务费专项基金资助项目(KJQN201549)。
徐 彦(1979-),男,讲师、博士,主研方向:人工神经网络,模式识别;杨 静,讲师、博士。
2015-06-17
2015-07-17 E-m ail:xuyannn@njau.edu.cn
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
防爆电机(2021年4期)2021-07-28
航天电子对抗(2021年2期)2021-05-31
中国特种设备安全(2021年11期)2021-05-05
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
铁道通信信号(2020年6期)2020-09-21
中成药(2018年2期)2018-05-09
自动化学报(2017年7期)2017-04-18
电子学报(2016年12期)2017-01-10
现代电子技术(2016年15期)2016-12-01
