
大数据在电信行业的应用研究
2015-12-21 02:41丁亦志李邵平牛瑛霞DingYizhiLiShaopingNiuYingxia
互联网天地 2015年6期
丁亦志,李邵平,牛瑛霞/Ding Yizhi,Li Shaoping,Niu Yingxia
(中国移动通信集团设计院有限公司 北京100080)
1 引言
大数据(Big Data)技术或称巨量资料,是指所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到撷取、管理、处理,并整理成为帮助企业经营决策更积极目的的资讯。自2012年以来,大数据一词越来越多地被提及,人们用它来描述和定义信息爆炸时代产生的海量数据,并命名与之相关的技术发展与创新。数据已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。
作为云计算、物联网后IT 行业又一颠覆性的技术革命,大数据随着近年来互联网和信息行业的发展而引起人们的广泛关注,本文旨在对电信行业中的大数据应用进行研究探讨。
2 大数据发展趋势及应用场景
2.1 大数据发展趋势
通过对互联网行业大数据的研究,归纳出以下4 项发展趋势。
(1)去小型机化
“传统数据库+小型机+高端阵列”的模式在性价比上很难再延续,SMP的扩展能力接近上限。
(2)计算与数据处理一体机化
软硬件垂直整合带来高性能优势和高集成度。
(3)内存和多核计算的崛起
磁盘已经落伍,内存才是王道;1 TB RAM PC已可行,新的压缩算法允许在内存里完整储存大量数据;16 核扩充至64 核,为CPU 提供足够的指令和数据是高效处理数据的关键。
(4)MPP/列存储,Hadoop 低成本海量分布式架构强势
通用x86 服务器+Linux+高速网络+SSD 存储、MPP+列存储集群的Scale Out 和OLAP 高性能、Hadoop 生态圈的蓬勃发展。
2.2 大数据应用场景
洛杉矶警察局和加利福尼亚大学合作利用大数据预测犯罪的发生,Google 流感趋势(Google Flu Trends)利用搜索关键词预测禽流感的散布,统计学家内特·西尔弗(Nate Silver)利用大数据预测2012年美国选举结果。类似的应用在互联网行业不胜枚举,对运营商来说,大数据又有哪些方面的价值?本文总结出以下6 种典型的应用场景,见表1 所列。
3 大数据的平台架构
3.1 运营商大数据价值体系
本文提出移动互联网时代运营商的大数据价值体系,包括客户研究、精准营销、智能管道、全业务融合和新业务模式等,如图1所示。
客户研究包括用户内容偏好、用户行为偏好、用户位置轨迹、用户交往圈、用户分群。精准营销包括内容偏好营销、事件营销、位置营销、业务交叉推荐、渠道协同营销、体验式营销。智能管道包括管道可视化、差分服务、公平使用、策略计费、信息与内容过滤、竞争/替代业务监控分析。全业务融合包括统一客户信息提升管理水平、统一产品信息提升优化程度、统一服务信息改善客户体验、统一资源信息保障协同调度。新商业模式包括后向收费模式支撑、合作产品引入分析、新流量产品引入分析、行业分析报告发布、数据服务开放共享。

表1 运营商典型应用场景
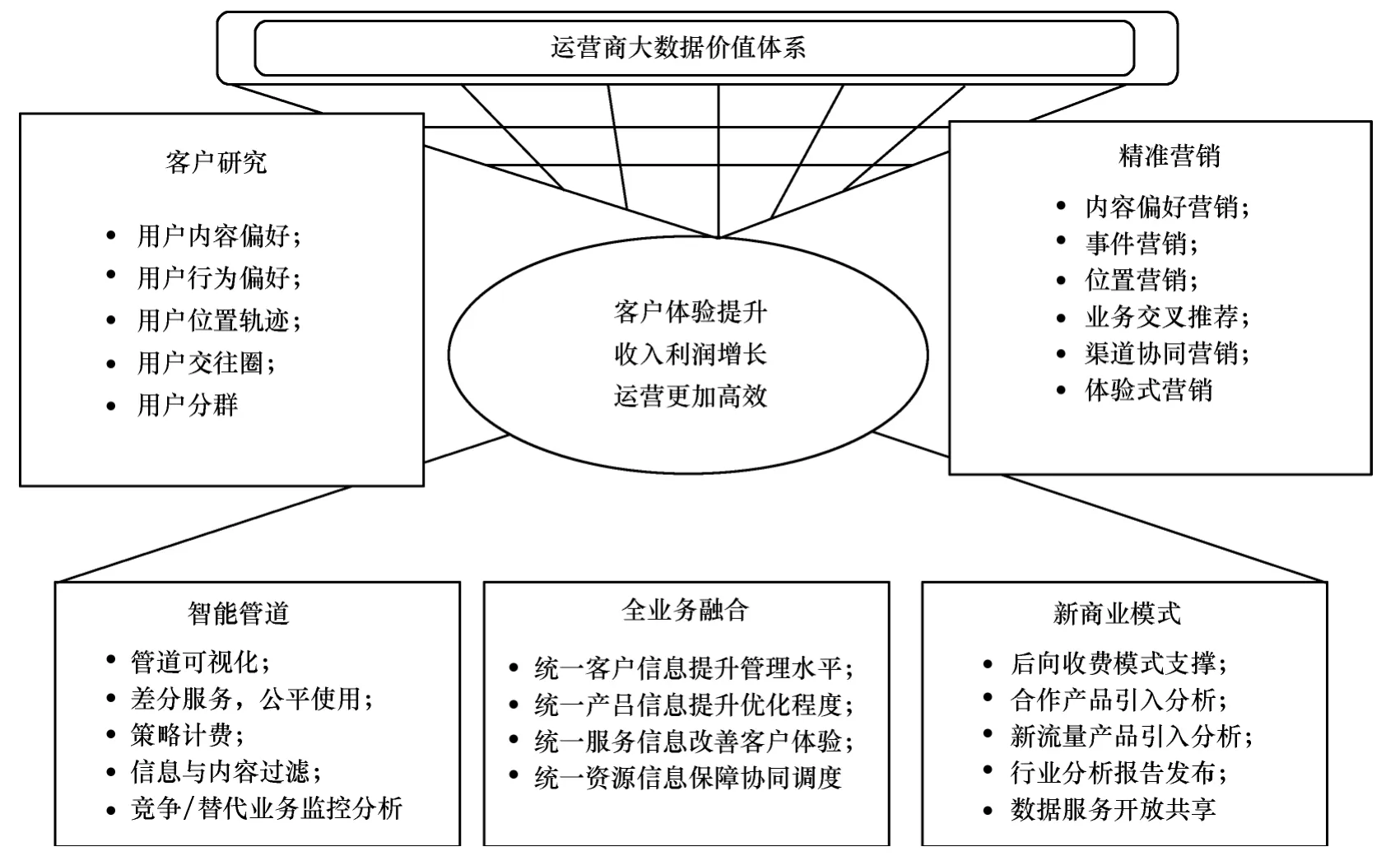
图1 运营商大数据价值体系
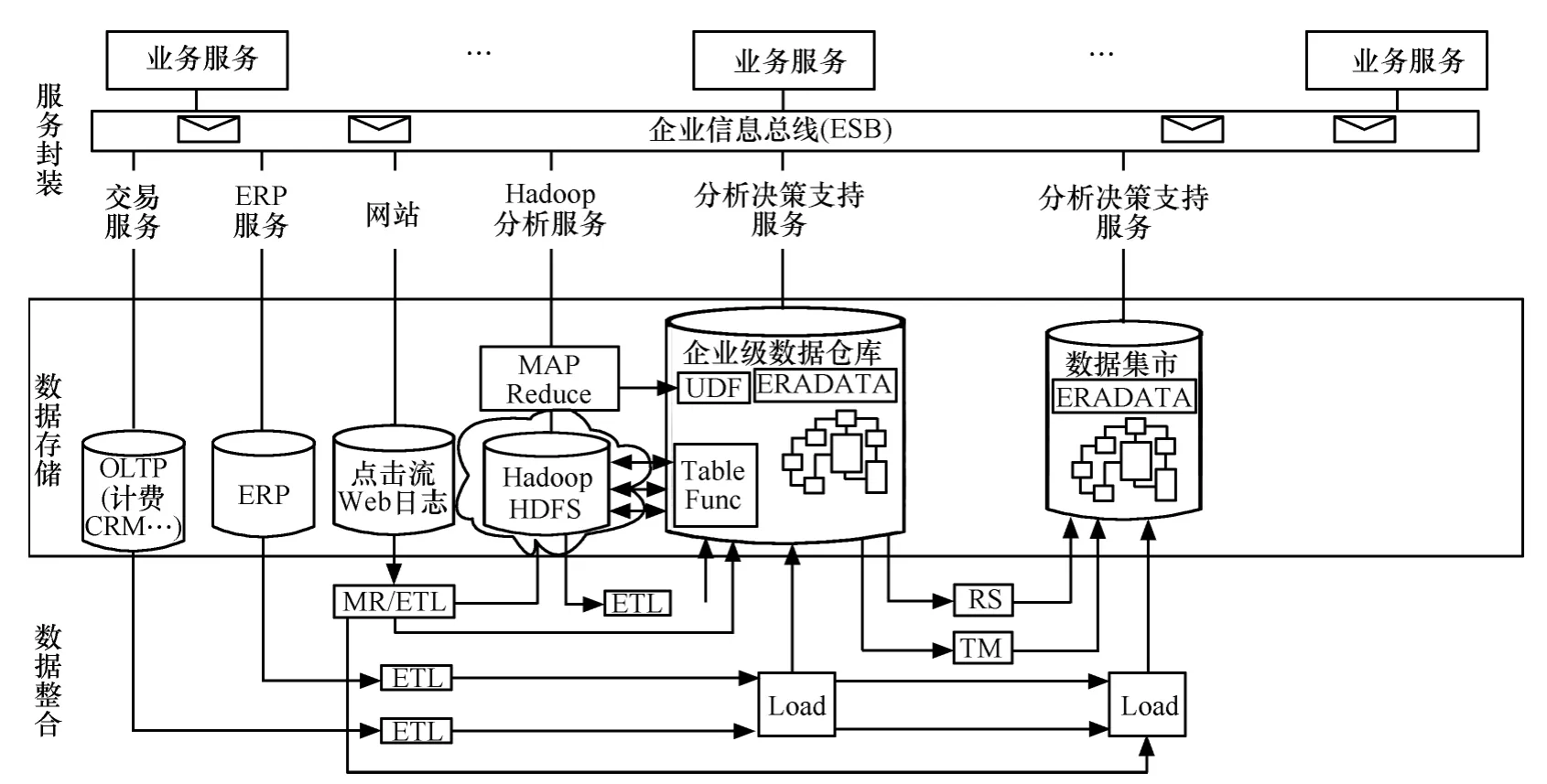
图2 割裂式混搭架构
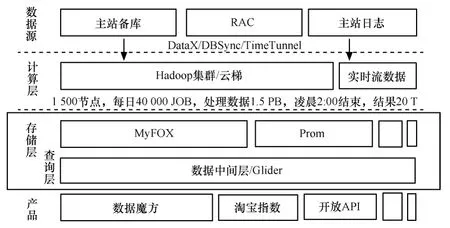
图3 混搭架构+深度定制化部件架构
3.2 大数据平台架构
大数据平台架构主要包括割裂式混搭架构、混搭架构+深度定制化部件、Hadoop 深度定制架构和自主研发新架构4 类架构。
(1)割裂式混搭架构
割裂式混搭架构模式是Hadoop+MPP RDB/SMP RDB,以Hadoop 处理非结构化为辅,RDB 处理结构化为主。主要应用于eBay、KDDI、中国移动省级经分等,架构如图2所示。
(2)混搭架构+深度定制化部件
混搭架构+定制化部件是Hadoop+MPP RDB+NoSQL/MyFox/Prom/glider/OceanBase、Hadoop 海量结构化/非结构化存储、ETL 和离线计算基础;MPP DB面向高速访问存储和部分实时计算; 专用场景部件,例如基于NoSQL的Prom/OceanBase,解决特定业务场景问题(全属性查询)和复杂的实时计算。阿里巴巴和淘宝是此架构最好的代表,如图3所示。
(3)Hadoop 深度定制架构
Hadoop 深度定制架构即Hadoop Enhanced,围绕Hadoop 生态圈进行深度定制和优化。腾讯和百度是此架构的代表,如图4所示。
(4)自主研发新架构
自主研发架构包括Caffeine、Pregel、Dremel、Power Drill、Storm、Qubole、RCFile 等,拥有核心知识产权和创新技术驱动业务革新。Google、Twitter、Facebook 都是基于自主研发的新架构,如图5 和图6所示。
(5)运营商平台架构的演进
在大数据中,运营商在3~5年内仍然是以结构化数据处理为主。但今后的趋势是往混合结构方向演进。当前建设方案应采取Hadoop+MPP RDB 集群的混搭模式,为使上层应用平滑过渡,需要在混搭的架构上建设透明访问层,以屏蔽数据源的异构、多实例特性。Hadoop平台承担了原始海量数据的抽取、转换、加载和轻度汇总等计算任务。同时新建MPP RDB 集群的深度分析库,支撑查询模型复杂、多变的自助分析应用。具体架构演进示意如图7所示。
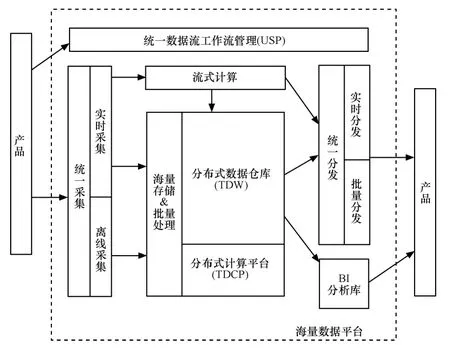
图4 Hadoop 深度定制架构
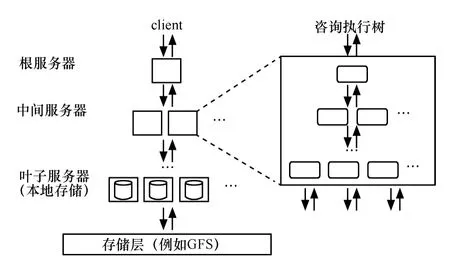
图5 自主研发新架构示意
①专用数据仓库(如TD)+MPP RDB 集群混搭模式,支撑传统的固定查询,如报表类应用等。
②用Hadoop平台支撑流量清单查询,这需要对Hadoop 进行深度定制、改造。否则需要将清单数据加载到MPP RDB 集群的数据仓库中支撑查询。
③MPP RDB 集群支撑自助分析类应用,此类查询模型复杂、多变,且要求实时展现。
4 关键技术
大数据涉及的关键技术主要包括流数据处理、费关系型数据库技术、MPP DB 和文件型分布式存储。
4.1 流数据处理
为应对海量数据实时处理的需求,业界引入了流处理的机制。在数据流动的过程中分析和计算,分析只对一定时间段内(Δt)的数据进行处理,事件/数据触发分析,分析过程始终在线,流处理又分为狭义流处理和广义流处理两大类。
狭义流处理为ESP(Event Stream Process,事件流处理)和CEP(Complex Event Process,复杂事件处理)。
广义流处理不但提供结构化数据的离散事件流处理能力,同时提供非结构数据的连续流处理,如Video、Image、Text。对非结构化数据一般主要提供分布式计算机制。
4.2 非关系型数据库技术
相比于RDBMS,NoSQL 数据存储不需要固定的表结构,通常也不存在连接操作,在解决大规模数据的可扩展性上有独到的解决方案,因此,在大数据存取上具备RDBMS 无法比拟的性能优势,非常适合超大规模和高并发的SNS 型Web2.0 网站;但在一致性方面,则不如RDBMS,不适用于企业的关键应用。
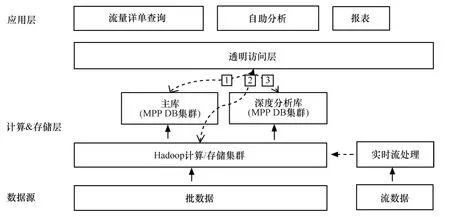
图7 由混搭架构向深度定制架构演进
NoSQL 一般与具体应用强绑定,主要由开源项目推动,Facebook、Digg、Twitter、Amazon 等都是NoSQL的推动者,其中,Facebook的Cassandra、Google的Big Table、Amazon的Dynamo 等都是非常成功的NoSQL商业实现。
目前,NoSQL家族中应用较为广泛的有HBase(Hadoop的衍生项目,类似Google的Big Table)、Cassandra(由Facebook 开发,用于存储特别大的数据,是网络社交云计算方面理想的数据库)、MongoDB(功能最丰富、最像关系型数据库的非关系型数据库,可存储比较复杂的数据类型)。
4.3 MPP DB
MPP DB 是指大规模并行处理(Massive Parallel Processing)数据库,有两种基本形式:Share Disk 和Share Nothing。
Share Disk:性能比较高,由于需要在节点间共享锁和缓存,可扩展性受到一定限制。适合高并发的OLTP 应用和数据量较小的OLAP 应用。
Share Nothing:每个节点的存储、计算、内存完全独立,数据分区存放,可扩展性好。适合大数据量的OALP 引用,但计算设备不容易做到热备,可用性级别略低。
两种基本形态都比较适合大数据的处理。考虑到扩展性,主存储和ETL 数据加工应首选Share Nothing。数据分析要求灵活,扩容压力不大,自定义数据处理的应用建议采用Share Disk,局域网络带宽在不断提升,Share Disk 前景同样很好,与Share Nothing 适用不同的场景。
4.4 大数据的存储—文件型分布式存储
对比MPP DB,文件型分布式存储的优点主要有以下几个方面:
①基本实现了RAID 所具备的数据高可用性要求;
②比RAID 自愈能力更强;
③没有数据库冗余开销。
对比MPP DB,文件型分布式存储的缺点主要有以下几个方面:
①基于指定的Key 散列分布,对数据运用限制很大;
②Key Value 方式连续读写效率不高;
③没有事务、关联、数据版本控制等数据库特性。
5 相关应用与实践
针对大数据,运营商进行了相关尝试,下面以BSS 云化ETL、融合通信、某省日志详单系统为案例进行简单的介绍。
5.1 BSS 云化ETL
移动数据业务和流量的爆发式增长,带来了网络建设和维护费用的成倍增加。数据业务中大量的非价值业务占据了60%以上的流量总带宽。低价值业务造成收入与业务量失去关联性,原有技术方式不能支撑数据业务盈利,使高价值业务的服务质量难以保证,最终导致终端用户的体验和满意度下降。
流量经营分析对云化ETL 和数据挖掘的要求:对各个数据源的日志进行转换装载,将海量数据存储在分布式存储中,基于这部分数据能够进行汇总等计算。对于ETL的诉求,要求能够基于海量数据做E-T-L 操作,同时能够做相应的关联汇总统计等功能。
5.2 融合通信SmartCare
SmartCare 为用户提供Network Insight解决方案,包括业务质量、用户体验、网络性能等。网络及业务信令实时流入,一方面被存储下来作为详单存储和查询;另一方面被汇总计算得到统计结果,用于OLAP 分析和报表查询。Infosea HDFS 和HBase 被用于详单存储,MR 被用于汇总计算。
其中,HBase 单点入库1.3 万条/s(4.5 MB/s),MR 服务器单点入库1.2 万条/s,单点存储空间为9.6 T(2 T×8 块),xDR 单据产生速率为28.1 万条/s,每条362 Byte。
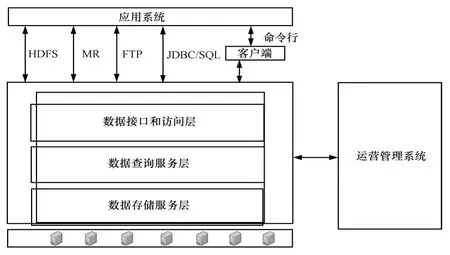
图8 日志详单系统模型
5.3 某省日志详单系统
日志详单类数据云存储系统基于x86 PC 服务器集群,通过软件系统实现高性能和海量存储,具体如图8所示。
设计目标如下。
①高可靠性,通过数据和服务冗余、分布式锁系统来解决PC 硬件故障率较高的问题。
②高可伸缩性,系统可以容易地增加或者减少容量和性能。
业务描述如下。
①基于HDFS的数据存储服务:为数据库系统提供海量结构化数据的存储服务,通常使用具备冗余存储、自动负载均衡能力的云计算分布式文件系统。
②基于MR 和Hive的数据查询服务: 完成用户查询的分解、转换、执行、结果收集和优化工作,由于数据可能被分配在很多存储服务节点上,数据查询服务必须具备分布式查询执行和结果收集能力,同时考虑到硬件的不可靠性,数据查询服务需要具备很高的容错能力。
③数据接口和访问层:连接应用程序和数据查询服务。主要对应用提供两类接口:数据存取接口,如针对非结构化数据的HDFS 接口; 数据查询分析接口,MR 接口、标准JDBC/SQL 接口等。
6 结束语
随着互联网业务的高速发展,大数据的广泛应用是业务发展的趋势。运营商需要加强对大数据的管理,对网络和业务系统进行全方位覆盖,深刻理解业务,精确洞察数据,充分发挥数据价值。后续,大数据技术与流量经营相结合,对大数据应用价值探索,构建大数据流量增值体系将是研究的重点。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
导航定位学报(2022年2期)2022-04-11
煤气与热力(2021年9期)2021-11-06
军民两用技术与产品(2021年5期)2021-07-28
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
电子制作(2019年22期)2020-01-14
当代陕西(2019年14期)2019-08-26
