
云环境下基于SQL的图书清点方案设计与实践——以安徽师范大学图书馆为例
2016-01-19 02:52朱东妹安徽师范大学图书馆安徽芜湖241003
图书馆理论与实践 2015年8期
●朱东妹(安徽师范大学图书馆,安徽 芜湖 241003)
云环境下基于SQL的图书清点方案设计与实践
——以安徽师范大学图书馆为例
●朱东妹(安徽师范大学图书馆,安徽芜湖241003)
[关键词]云环境;图书清点;SQL
[摘要]设计一种基于结构化查询语言SQL的图书清点方案,同时根据工作实践,对清点过程中出现的各种难题加以分析,以力求清点的准确性与全面性,为领导决策和图书馆的藏书建设提供依据。
中国高等教育文献保障系统(CALIS)三期推出了基于SaaS技术的数字图书馆云服务平台,直接面向图书馆提供最终的应用服务,其中CALIS文献搜索引擎“E读”,[1]通过整合成员馆提交的馆藏OPAC数据以及电子资源相关数据及接口,将单个成员馆的馆藏信息资源集合起来,形成一个全国范围内的集成化的馆藏信息资源库,将整合后的资源提供给所有的成员馆用户使用。[2]在E读的检索平台中,既可以在全国范围内检索,也可以在本省、本市、本校范围内进行检索。在这种环境下,对图书馆馆藏数据的准确性要求更高,必须通过图书清点,解决馆藏数据库OPAC检索的显示状况与书库中实际图书状况不一致的现象。
1 安徽师范大学图书清点工作
安徽师范大学图书馆藏书年份较长,历经八十五年的历史嬗递,图书馆以馆藏古籍为特色,目前是CALIS成员馆之一。1999年,开始利用ILAS图书管理系统做机编数据,并对以前的图书进行回溯建库,当时由于时间紧、人员少等因素,势必影响建库质量。2008年新馆建成,对全馆馆藏布局进行调整,并对藏书进行整合和划分,部分阅览室进行搬迁,整个过程可能会导致一些图书错架、遗失,这些都会影响馆藏数据的准确性。每年暑假阅览室工作人员都会专门对图书进行整理与清点,但都是局部简单地进行图书实际册数和ILAS系统里统计的图书数量进行比较,没有在全馆数据范围内深入地进行数据比对与分析。因此,始终有一些遗留问题长期得不到解决,如有实物无数据、有数据无实物、条码破损等问题。基于此,2014年暑假对全开架的借阅图书进行彻底地清点,包括花津校区敬文图书馆的三个社会科学图书阅览室和自然科学图书阅览室,赭山校区图书馆的自然科学阅览室和社会科学阅览室。根据整体部署,安徽师范大学图书馆工作人员按校区区域分步实施,清点期间停止清点区域所有图书的典藏、流通业务,闭架整理,避免因新书典藏或读者借阅带来的图书流动影响清点结果的准确性。
2 图书清点的基本方案设计
为了利用SQL对图书清点数据进行深入分析与挖掘,制定了图书清点工作的基本方案,主要包括图书清点前准备、系统数据提取、条码信息采集、数据比对、后续处理等环节。
2.1图书清点的准备工作
安徽师范大学图书馆在图书清点工作之前,专门成立由馆领导班子和相关部门主任组成的暑期工作小组,制定《图书馆关于今年暑期阅览室开放、图书清查与整架工作实施方案》,利用暑期时间集中力量分批对普通图书阅览室图书进行全面、彻底的整架和数据清查工作。整个清点工作小组分别由技术组、编目组、条码采集组和后勤组组成。技术组负责计算机、条码采集等设备的安装及后期数据分析等工作;编目组负责条码采集技术的培训工作及每天采集数据的收集、整理及复核等工作;条码采
集组负责图书的整架及条码采集;后勤组负责电源及各种书车的协调保障工作等,以减少不必要的工作环节和后续工作的复杂性。
2.2系统数据提取
由于本次图书清点比对分析整个过程不是在图书管理系统ILAS中自带的图书清点模块中进行,而是利用SQL SERVER 2008工具,所以首先需要对图书馆的所有图书馆藏信息进行提取,导入到SQL SERVER 2008对象资源管理器中,进行比对分析。系统数据的提取可以在图书管理系统中的馆藏输出中进行,也可以在后台数据库中利用SQL语句按需要直接提取中央馆藏库中的数据。前者简单,但是数据提取速度慢;后者数据提取速度快,但是必须在熟悉图书管理系统中各表之间的关系基础上,才能准确提取数据。提取的图书信息包括书条码号、题名、责任者、出版者、出版地、价格、索取号、分类号、ISBN号、馆藏地点、流通类型、馆藏状态等字段。
2.3条码信息采集
条码信息采集过程中,对每个阅览室的工作人员进行了分组,每组2人,分成5组,合计10人。条码信息采集使用的采集工具,就是平时各阅览室借还图书的普通条码采集器。方法是将条码采集器连接在普通台式电脑主机上,作为条码采集的输入设备,电脑主机放在书车上,每台电脑主机都接在有足够长的电源线的电源插线板上,可以移动,以便条码的采集。
条码采集前先做好图书的整架工作,对每个阅览室书架进行编号,同时对各个书架各层进行明显的编号和分隔,点清每个架上实际图书数量,条码采集中按顺序进行,以便使每个条码与图书位置对应。每个小组负责若干个书架,值得注意的是同一个书架的条码采集最好由一个小组完成。对条码采集过程中不能正常识别的条码图书,要进行手工录入,并在相应的图书书脊处贴上色标,以便采编部门最后统一重新打印条码。
条码采集输入是选择在excel工作表中进行,因为excel中可以方便看到当前条码对应的序号。为了防止条码采集输入过程中缺位、多位及识别出非法字符,对工作表输入列,进行了通用数据校验设置。方法是在excel工作表中选中将要存入条码数据的列,再选择数据菜单下的数据有效性进行设置。这样可以减少数据的出错率。文件保存时,命名规则是“阅览室+清点架号+清点类别数量+初始确认+复核确认+抽查通过”。
2.4数据比对
在数据比对前,初步分析每个阅览室采集到的条码数据,主要分为三部分:①本阅览室的图书;②系统中应属于其他阅览室的图书;③系统中没著录信息的图书。同时每个阅览室系统中提取的图书信息数据,主要分为三部分:①本阅览室的图书;②系统数据在该阅览室,但是实体图书在别的阅览室;③丢失或损坏。
数据比对思路:将各阅览室提取的馆藏数据及收集到的条码,首先在本阅览室进行比对分析,然后再分别与全馆条码和全馆系统数据进行比对,全馆范围数据的比对主要用来获得乱架图书在馆里的真实馆藏地点、图书是否丢失、图书在系统中是否有著录信息等。最后得出图书馆藏信息与扫码信息比对关系(见图1)。图1中各部分从某阅览室“馆藏数据”、收集到的“条码数据”两个不同的角度分析,分别表示不同的意义。

图1 图书馆藏信息与扫码信息比对关系
以某阅览室“馆藏数据”角度分析,图1中的大圆c1表示系统中全馆馆藏数据,小圆c2表示系统中本阅览室馆藏数据,矩形j表示本阅览室收集到的条码数据,阴影P1部分表示本阅览室馆藏信息和条码信息比对命中的数据,即正确数据,阴影P2部分表示其他阅览室的图书乱架(或馆藏地点错误)到本阅览室的图书数据,大圆c1之外矩形j之内空白P3部分表示有条码但是图书管理系统中没有著录信息。
以某阅览室“条码数据”角度分析,图1中的大圆c1表示全馆收集到的条码数据,小圆c2表示本阅览室收集到的条码数据,矩形j表示系统中本阅览室的馆藏数据,阴影P1部分表示本阅览室条码信息和馆藏信息比对命中的数据,即正确数据,阴影P2部分表示本阅览室的图书乱架(或馆藏地点错误)到其他阅览室的图书数据,大圆c1之外矩形j之内空白P3部分表示系统有馆藏信息但是没有条码,表示图书丢失。
2.5结果核对与反馈
将各种比对结果,生成表格,分发给各个阅览室进行问题图书的核对与处理。核对正确就可以在系统中通过导入条码文件进行批量修改。同时,技术部数据分析工作人员、采编部编目工作人员及流通部工作人员,几方进行沟通,总结分析各种问题图书发生的原因,以便在日后的工作中进行改进。
3 图书实物条码、馆藏数据比对过程中的关键问题
3.1建立比对数据库
在SQL SERVER 2008对象资源管理器中建立比对数据库,数据库中包括各阅览室图书馆藏信息表、各阅览室条码表、全馆馆藏信息视图、全馆条码视图,视图是在各种表的基础上建立的。其中,各阅览室条码表,包括字段:条码号、条码序号、架号、扫码地点、扫码日期。下面以社科(一)阅览室为例,说明数据比对过程中关键问题及其SQL语句的使用,语句中用“S1”表示社科(一)。
3.2以某阅览室“馆藏数据”角度分析
(1)比对步骤。从某阅览室“馆藏数据”角度出发,进行数据比对,可以得到本阅览室乱架到其他阅览室的图书、丢失图书,具体比对分析流程(见图2)。图2中将该阅览室馆藏数据与在该阅览室采集到的条码进行比对,比对到的数据,就是正确的馆藏数据。没有比对到的数据再与全馆其他所有阅览室采集到的条码进行对比,此时比对到的数据就是其他阅览室乱架(或馆藏地点错误)到该阅览室的图书。再次没有比对到的数据就是图书丢失或破损数据。
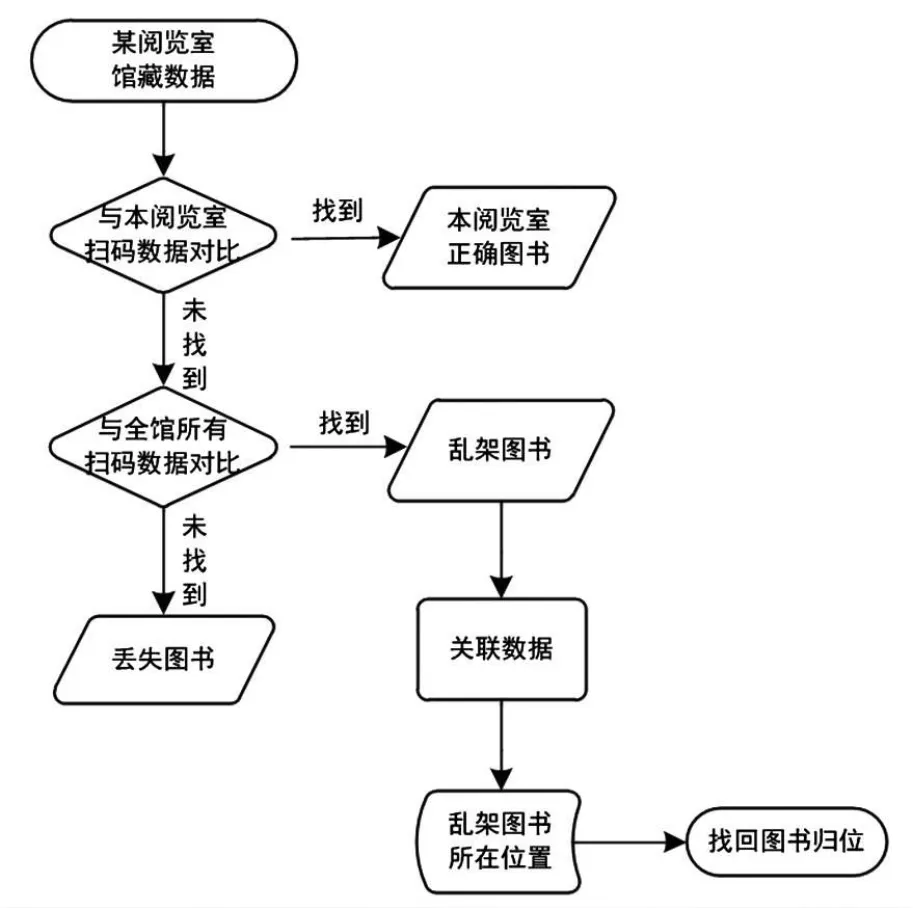
图2 以某阅览室“馆藏数据”角度比对分析流程
s
(2)比对语句。步骤1:用S1系统数据在S1收集到的条码中寻找确实存在的数据,即比对出正确的数据。
select * into S1_FIND_CORRECT from dbo.S1 where书条码号in(select条码号from dbo. S1_TM)
步骤2:用S1系统数据在S1收集到的条码中寻找没存在于条码中的数据。
select * into S1_NO_FIND from dbo.S1 where书条码号not in(select书条码号from S1_FIND_CORRECT)
通过以上两个步骤将S1阅览室系统中的图书分出两部分,一部分是有扫码的,另一部分是没有被扫码的。扫到码的第一部分是正确的,没扫到码的第二部分再寻找原因。
步骤3:将没有被扫到码的S1系统数据再在全馆的扫码中寻找。
select * into S1_FIND_QUANGUAN from dbo.S1_NO_ FINDwhere书条码号in(select条码号fromdbo.View_TM _ZONG)
步骤4:将在其他阅览室找到的图书馆藏数据,与扫码表关联,找出是在哪些阅览室的扫码表中,以便到那些阅览室将书找出来,将馆藏地点改到S1。
SELECT * into S1_乱架_去其他室取回归位FROM S1_FIND_QUANGUAN
LEFT JOIN dbo.View_TM_ZONG
ONS1_FIND_QUANGUAN.书条码号=dbo.View_TM_ ZONG.条码号
步骤5:将(步骤2)中没找到的数据,除去(步骤3)乱架到其他阅览室的图书,并且目前馆藏状态不是“丢失”和“剔除”的数据,剩下的应该是丢失的图书。
select * into S1_丢失from dbo.S1_NO_FIND where书条码号notin(select书条码号fromdbo.S1_FIND_QUANGUAN)and馆藏状态notin('f','g')
3.3以某阅览室“条码数据”角度分析
(1)比对步骤。从某阅览室“条码数据”角度出发,进行数据比对,可以得到其他阅览室乱架到本阅览室的图书、系统没有著录信息图书,具体比对分析步骤(见图3)。图3中将该阅览室采集到的条码与该阅览室馆藏数据进行比对,比对到的数据,就是正确的条码数据。没有比对到的数据再与全馆其他所有阅览室馆藏数据进行对比,此时比对到的数据就是该阅览室乱架(或馆藏地点错误)到其他阅览室的图书。再次没有比对到的数据就是系统没有著录信息数据,
对其进行回溯建库工作。
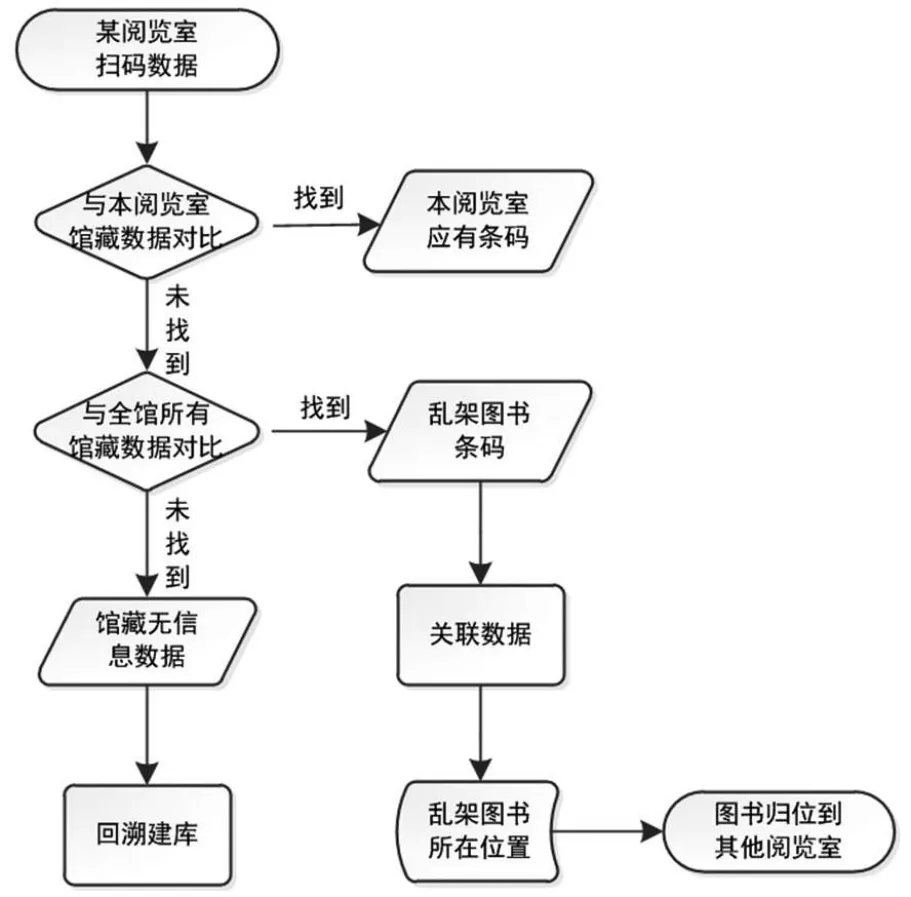
图3 以某阅览室“条码数据”角度比对分析流程
(2)比对语句。步骤1:找出在S1中扫出,但是没用上,即没对比到书的条码。
select * into S1_没用上条码from dbo.S1_TMwhere条码号notin(select书条码号fromS1_FIND_CORRECT)
步骤2:将步骤1中得到的条码,在全馆馆藏数据中寻找。
select * INTO S1_没用上条码_在馆全找到from S1_没用上条码where条码号in(select书条码号from dbo.View_ZONG)
步骤3:将在其他阅览室找到的条码数据,与全馆馆藏数据表关联,找出这些条码图书的馆藏信息,以便将图书找出来给其他阅览室归位,将馆藏地点改到其他阅览室。
SELECT * into S1_乱架_找出给其他室归位
FROM S1_没用上条码_在馆全找到
LEFT JOIN dbo.View_ZONG
ON S1_没用上条码_在馆全找到.条码号=dbo. View_ZONG.书条码号
步骤4:将(步骤1)中没用上的数据,除去(步骤3)其他阅览室乱架过来的图书,剩下的就是系统没有著录信息的数据。
select * into S1_没信息条码from dbo.S1_没用上条码where条码号not in(select条码号from dbo.S1_没用上条码_在馆全找到)
3.4主题分析
(1)“问题图书”主题分析。在上述步骤中,其中得出了各阅览室馆藏信息与扫码信息一致的图书,对这些图书做进一步分析,发现其中还存在有问题的图书,虽然这些图书数量很少。如:“借出”状态图书还在馆、“丢失”状态图书还在馆、“采编”状态图书在阅览室、“馆藏地点”为空的图书在阅览室、“索取号”为空状态图书在架上、不同的书条码号相同等。如找出“不同的书有相同条码号”的所有图书,SQL语句如下:
SELECT x.条码号,y.架号FROM dbo.FIND_CORRECT_ZONGasx,dbo.FIND_CORRECT_ZONGasyWHERE x.条码号=y.条码号and x.架号=y.架号
(2)“丢失图书”主题分析。步骤1:在所有馆藏图书信息视图的基础上,构建丢失图书分析表。
SELECT书条码号,题名,索取号,分类号,馆藏地点,流通类型,馆藏状态, SUBSTRING(索取号, 1, 1)AS大分类, SUBSTRING(书条码号, 1, 4)AS年into丢书分析FROM dbo.View_ZONG
构建丢失图书分析表过程中,通过截取“索取号”的第1位字母新增为“大分类”字段,截取“书条码号”的前4位新增为“年份”字段。
步骤2:分别计算按“年份”、“大类”分类购置的图书总数。
select年,count(*)fromdbo.View_丢书分析group by年order by年
select大分类,count(*)from dbo.View_丢书分析group by大分类order by大分类
通过以上步骤获取的数据,可以计算出丢失的图书中,按“年”或按“大类”分类的丢失率。如:经过以上分析安徽师范大学图书馆每年购置的图书丢失率最高的是2001年的7.36%,最低的是2011年的2.26%;每大类图书丢失率最高的是I类图书的6.77%,最低的是S类图书的0.98%。
[参考文献]
[1]李郎达.CALIS三期吉林省中心共享域平台建设[J].图书馆学研究,2013(2):78-80
[2]扈志民.从E读推广看图书馆信息资源共建共享新方向[J].图书馆学研究,2011(11):74-76.
[收稿日期]2014-10-15 [责任编辑]徐娜
[作者简介]朱东妹(1975-),女,安徽师范大学图书馆副研究馆员,研究方向:数字图书馆。
[基金项目]本文系安徽省高等学校图书情报工作委员会基金项目“云环境下安徽省高校图书馆云服务模式构建研究”(项目编号:TGW13B17)的研究成果之一。
[文章编号]1005-8214(2015)08-0087-04
[文献标志码]B
[中图分类号]G250.78
