
基于模式识别的质量可分级视频编码算法
2016-03-15 02:15艾新宇,黎洪松
桂林电子科技大学学报 2016年1期
关键词:模式识别
基于模式识别的质量可分级视频编码算法
引文格式: 艾新宇,黎洪松.基于模式识别的质量可分级视频编码算法[J].桂林电子科技大学学报,2016,36(1): 19-22.
艾新宇,黎洪松
(桂林电子科技大学 信息与通信学院,广西 桂林541004)
摘要:为了降低质量可分级视频编码算法的复杂度,提出一种基于模式识别的质量可分级视频编码算法。该算法将自组织神经网络用于可分级视频编码,利用较粗糙的特征模式库对图像编码生成基本质量层,通过精细的特征模式库对重建图像质量较差的部分区域编码生成质量增强层,从而实现质量可分级编码。仿真实验结果表明,该算法具有较好的质量可分级编码性能,在高压缩比情况下,其压缩性能优于传统的粗粒度质量可分级编码算法。
关键词:视频编码;模式识别;质量可分级;SOM
随着互联网、智能终端和无线宽带通信技术的发展,视频应用越来越普及,同时也对视频编码技术提出了新的挑战。不同的智能终端具有不同的分辨率和解码能力,各种无线网络传输带宽也不尽相同。为了应对这些挑战,视频编码需要引入可分级技术。可分级视频编码(scalable video coding,简称SVC)作为H.264/AVC视频编码标准的扩展部分,是为了满足这些新的视频应用需求。SVC提供了时间可分级、空间可分级以及质量可分级3种可分级视频编码方式。2014年制定的基于新一代视频编码标准HEVC(high efficient video coding)的可分级编码扩展标准SHVC,除了支持时间、空间和质量可分级外,还支持混合编码可分级、比特深度可分级和彩色gamut可分级[1-6],其中,质量可分级编码主要包括粗粒度质量可分级(CGS)[7]、中间粒度质量可分级(MGS)[8]和精细粒度质量可分级(FGS)[9]。但这些可分级视频编码方法的不足是算法越来越复杂,对处理速度的要求越来越高。
自组织特征映射(self-organizing feature maps,简称SOM)是一种高效的聚类方法,它模拟了人脑对新事物的学习归纳推理过程,通过对大量训练样本的学习,可得到最佳匹配的特征模式匹配。目前SOM广泛应用于故障检测[10]、大数据分析[11]、医学检验[12]、图像以及视频处理[13-17]等领域。Murguia等[15]提出一种基于SOM的背景减除算法用于视频运动对象的检测和分割,该算法优于传统算法。Quintana等[16]将SOM与细胞神经网络(CNN)相结合,提出了一种新的视频运动对象分割算法,比传统算法具有更好的自适应性。Pagel[17]在视频监控中引入SOM算法,实现了事件检测。为了降低可分级视频编码算法的复杂度和提高编码性能,提出一种基于模式识别的质量可分级视频编码(PR-QSVC)算法。
1编码方案

图1 基于模式识别的质量可分级视频编码算法Fig.1 Quality scalable video coding algorithm based on pattern recognition
基于模式识别的质量可分级视频编码的基本思想是:利用模式矢量大小不同对重建图像质量的影响,对于不同质量层采用具有不同大小模式矢量的模式库进行编码,从而实现视频的质量可分级。基于模式识别的质量可分级视频编码算法如图1所示。
基于模式识别的质量可分级视频编码步骤如下:
1)对编码视频的所有图像采用较大尺寸进行分块,分割后的图像块作为训练矢量集,采用SOM算法训练学习,得到基本层特征模式库。重复上述步骤,分别采用中等尺寸和较小尺寸对视频图像进行分块,并利用SOM算法训练得到增强层1特征模式库和增强层2特征模式库。
2)基本层编码。对每帧图像以较大尺寸分块,使用基本层特征模式库对每个图像块进行模式匹配,得到最佳匹配的模式矢量,并将与之对应的索引进行编码作为基本层码流。
3)增强层1编码。通过已编码的基本层索引对基本层图像块进行预测,并计算该预测图像块与原图像块的均方差,与预设的增强层1的均方差阈值对比,若小于该阈值,对该图像块进一步细分,并使用增强层1特征模式库对细分后的图像块进行匹配编码作为增强层1码流。
4)增强层2编码。对已编码的基本层图像块和增强层1图像块重复步骤3),并使用增强层2特征模式库对再次细分后的图像块进行匹配编码作为增强层2码流。
当只接收到基本层码流时,可解码出较低质量的视频;当同时接收到基本层和增强层1码流时,可解码出中等质量的视频;当接收到全部的码流时才能解码出最高质量的视频。
2特征模式库生成
使用SOM算法训练特征模式库的步骤如下:
1)设自组织神经网络为(N,M),N为模式库大小,M为模式矢量的大小。
2)对所有视频图像分块,将所有的图像块组成训练矢量集X(n),n=1,2,…,L,其中L为训练矢量个数。
3)将训练矢量按照均方差从小到大排序,然后分为2个训练矢量集X1(n)和X2(n),其中X1(n)为低频部分,X2(n)为高频部分,分别从X1(n)和X2(n)中以间隔i1和i2(i1=L1/N1,i2=L2/N2,N1+N2=N,L1+L2=L)抽取模式矢量,组成初始模式库W(n)。
4)以均方差为失真准则,分别计算输入的训练矢量与初始模式库中各模式矢量的失真D(j),选择具有最小失真的模式矢量j*为获胜模式矢量,
(1)
5)对获胜模式矢量j*及其领域范围内的模式矢量进行调整,
(2)
其中:a(t)为学习函数,用于调整模式矢量的幅度;N(t)为邻域函数,用于调整模式矢量的范围。
6)重复步骤2)~5),直至训练完L个训练矢量。
3实验结果与分析
实验中的特征模式库训练和视频编码均采用标准视频测试序列foreman,每帧图像分辨率为352×288×24,共20帧。为了客观评估算法的性能,采用视频图像亮度分量的峰值信噪比(PSNR)作为测量标准,
(3)
其中:Y为视频图像的亮度分量;Y′为重建的亮度分量;EMS为原始图像与重建图像的均方差。对于可分级视频编码算法性能的测度采用压缩比CR=BI/BO,BI为原始视频文件的比特数,BO为编码后视频文件的比特数。对比算法分别为非可分级的single-layer算法和基于H.264的CGS算法,测试平台为可分级编码标准测试模型JSVM9.19。
为了便于对比,PR-QSVC算法和CGS算法都设置为一个基本层和2个增强层。图2为2种算法解码后基本层图像质量。从图2可看出,CGS算法解码后图像的质量较为稳定,但PR-QSVC算法解码后图像的整体质量优于CGS算法,而此时PR-QSVC算法的压缩性能仅略逊于CGS算法(见表1)。
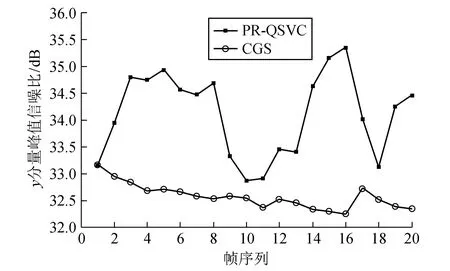
图2 PR-QSVC算法和CGS算法解码后基本层图像质量Fig.2 The quality of base layer decodedby PR-QSVC and CGS

质量层PR-QSVC算法CGS算法Ry,PSN/dBCRRy,PSN/dBCR基本层34.0406155.323932.5687166.3993增强层135.216499.458934.877574.6308增强层236.656336.068237.373536.7362
图3为视频原图像和PR-QSVC算法解码后各质量层图像。从图3可看出,采用PR-QSVC算法的基本层图像质量较差,增强层1的图像质量明显好于基本层的图像质量,而增强层2的图像质量与原图像相差很小,表明PR-QSVC算法能实现对视频的质量可分级编码。图4为PR-QSVC算法、CGS算法和single-layer算法的编码性能。从图4可看出,PR-QSVC算法可实现较平缓的质量可分级视频编码,压缩比较小时,该算法稍逊于CGS算法,压缩比较大时,PR-QSVC算法则优于CGS算法。

图3 原图像与PR-QSVC算法解码后各质量层图像Fig.3 The quality of original image and decoding images

图4 PR-QSVC算法、CGS算法和single-layer算法编码性能Fig.4 The coding performance of PR-QSVC, CGS and single-layer algorithm
4结束语
提出了一种基于模式识别的质量可分级视频编码算法,采用基于SOM算法代替传统的基于DCT系数的质量可分级编码方案。实验结果表明,PR-QSVC算法在压缩比较大的情况下具有较好的编码性能。下一步的工作是研究如何将SOM算法与时间可分级、空间可分级相结合,以取得更好的可分级视频编码性能。
参考文献:
[1]朱秀昌,王国刚,陈杰,等.HEVC标准的多层视频编码扩展[J].南京邮电大学学报(自然科学版),2015,35(3):1-10.
[2]YEY,ANDRIVONP.ThescalableextensionsofHEVCforultra-high-definitionvideodelivery[J].MultimediaIEEE,2014,21(3):58-64.
[3]严烨.可伸缩高性能视频编码的扩展技术研究[D].合肥:中国科学技术大学,2015:14-19.
[4]路洪运.基于HEVC的质量可伸缩视频编码研究[D].北京:北方工业大学,2014:5-8.
[5]TOHIDYPOURHR,POURAZADMT,NASIOPOULOSP,etal.AnewmodeforcodingresidualinscalableHEVC(SHVC)[C]//2015IEEEInternationalConferenceonConsumerElectronics,2015:372-373.
[6]LIX,CHENJ,KARCZEWICZM,etal.Asymmetric3DlookuptablebasedcolorgamutscalabilityinSHVC[C]//DataCompressionConference,2015:3-12.
[7]SHIZ,SUNX,XUJ.CGSqualityscalabilityforHEVC[C]//2011IEEE13thInternationalWorkshoponMultimediaSignalProcessing,2011:1-6.
[8]KAIZ,HUIJUANC,KUNT.OptimizedbitextractionofH.264-SVCMGSstreamovererror-pronechannels[C]//2014IEEEComputingCommunicationsandITApplicationsConference,2014:56-61.
[9]洪佳庆.基于HEVC的FGS视频编码算法研究[D].泉州:华侨大学,2014:14-19:7-16.
[10]MINHOEK,SOUHWANJ,MINHOP.Adistributedself-organizingmapforDoSattackdetection[C]//2015IEEESeventhInternationalConferenceonUbiquitousandFutureNetworks,2015:19-22.
[11]SANGHVIY,GUPTAH,DOSHIH,etal.ComparisonofselforganizingmapsandSammon'smappingonagriculturaldatasetsforprecisionagriculture[C]//2015IEEEInternationalConferenceonInnovationsinInformation,EmbeddedandCommunicationSystems,2015:1-5.
[12]MITTALD,GAURAVD,SEKHARRS.Aneffectivehybridizedclassifierforbreastcancerdiagnosis[C]//2015IEEEInternationalConferenceonAdvancedIntelligentMechatronics,2015:1026-1031.
[13]HIKAWAH,KAIDAK.NovelFPGAimplementationofhandsignrecognitionsystemwithSOM-Hebbclassifier[J].IEEETransactionsonCircuitsandSystemsforVideoTechnology,2015,25(1):153-166.
[14]BENHAM,AMIRIH.Content-basedimageretrievalinthetopicspaceusingSOMandLDA[C]//2015IEEE3rdInternationalConferenceonControl,EngineeringandInformationTechnology,2015:1-6.
[15]CHACON-MURGUIAM,RAMIREZ-ALONSOG,Gonzalez-DuarteS.Improvementofaneural-fuzzymotiondetectionvisionmodelforcomplexscenarioconditions[C]//The2013IEEEInternationalJointConferenceonNeuralNetworks,2013:1-8.
[16]RAMIREZ-QUINTANAJA,CHACON-MURGUIAMI.Self-adaptiveSOM-CNNneuralsystemfordynamicobjectdetectioninnormalandcomplexscenarios[J].PatternRecognition,2015,48(4):1137-1149.
[17]PAGELF.Unsupervisedclassificationandvisualrepresentationofsituationsinsurveillancevideosusingslowfeatureanalysisforsituationretrievalapplications[C]//IS&T/SPIEElectronicImaging.InternationalSocietyforOpticsandPhotonics,2015:94070H-1-94070H-9.
编辑:翁史振
A novel quality scalable video coding algorithm based on pattern recognition
AI Xinyu, LI Hongsong
(School of Information and Communication Engineering, Guilin University of Electronic Technology, Guilin 541004, China)
Abstract:In order to reduce the complexity of quality scalability, a novel quality scalable video coding algorithm based on pattern recognition is proposed. The self-organizing neural network is used for scalable video coding in the proposed scheme. A coarse pattern library is used for coding the base layer and two fine pattern libraries are used for recoding the area of the picture which has a bad reconstructed quality. Experimental results show that this algorithm has a better performance than the traditional coarse-grain quality scalable coding algorithm.
Key words:video coding; pattern recognition; quality scalability; SOM
中图分类号:TP37
文献标志码:A
文章编号:1673-808X(2016)01-0019-04
通信作者:黎洪松(1963-),男,湖北监利人,教授,博士,研究方向为智能信息检测、处理和控制。E-mail:hongsongli@guet.edu.cn
基金项目:国家自然科学基金(61261035);桂林电子科技大学研究生教育创新计划(GDYCSZ201451)
收稿日期:2015-12-02
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
中成药(2018年2期)2018-05-09
中成药(2018年4期)2018-04-26
智能系统学报(2018年6期)2018-02-04
中成药(2017年10期)2017-11-16
智能系统学报(2017年5期)2017-01-22
燕山大学学报(2015年4期)2015-12-25
海军航空大学学报(2015年1期)2015-11-11
智能系统学报(2015年3期)2015-01-29
智能系统学报(2014年1期)2014-02-01
