
一种基于机器学习识别贫困人口的数据分析方法研究
2017-05-30 04:28梁骁张明覃琳
企业科技与发展 2017年5期
梁骁 张明 覃琳
【摘 要】自党的十八大以来,党中央对脱贫攻坚工作进行了新的部署,提出减少贫困人口、为贫困县摘帽、解决区域性整体贫困,是建设小康社会的底线工作,是党对人民的承诺,必须言必信、行必果。脱贫攻坚已作为政府重点突破的工作之一,而通过大数据技术手段分析各类扶贫数据,制定有效的扶贫策略,对提高政府脱贫攻坚成效具有重大意义。文章提出了一种利用机器学习分析贫困户数据的方法,旨在为建设扶贫攻坚大数据分析平台及精准识别贫困户工作提供支持。
【关键词】贫困人口;机器学习;随机森林;数据分析
【中图分类号】TP181 【文献标识码】A 【文章编号】1674-0688(2017)05-0039-03
1 贫困人口判别标准
根据2011年11月29日中央扶贫开发工作会议提出的标准,我国扶贫标准为人均纯收入2 300元。此标准逐年调整,至2016年调整为3 000元。但实际工作中仅仅考虑人均纯收入并不科学,还应把包括但不限于地方政策、社会环境、技术环境、经济环境的诸多因素作为判断的参考。
根据各地相关政策,可把以下示例指标作为贫困人口判别的部分参考标准:是否在城镇有购买商品房;是否拥有多处房产;是否拥有商铺;是否经营私人企业;是否有轿车、高档摩托车、高档冰箱、空调、电脑等高档消费品;是否有大中型农业机械、加工机械、工程机械、运输工具;家庭成员中是否有人是现任公务员或事业单位在编人员;家庭成员中是否有自费出国留学人员;家庭成员中是否有购买商业养老保险人员;是否种养大户或长期雇佣他人从事生产经营活动。更详细的贫困人口判别标准和不得列入贫困人口的标准参照各地实际实施的政策。
2 数据分析过程
为了实现自动、准确、高效地分析贫困户数据,引入机器学习技术能够发挥重要作用。简单来说,机器学习的过程就是使用大量数据信息对学习系统进行训练的过程。在这一过程中,系统根据获取的信息完成模型建立、模型训练等步骤,最终找到问题的最优或次优解。利用机器学习进行贫困人口识别分析要经过以下过程。{1}数据采集。尽可能地收集贫困人口数据,收集的广度和深度都会影响分析模型的准确度。数据量越大涉及的细节越细,则模型分析的准确度就越高。{2}数据预处理。清洗和整理数据集,提高数据集的有效性。{3}特征库构建。关联数据集中的主属性和分支属性,形成多维度的特征库。{4}特质筛选排序。分析特征的重要性,选取重要性高的特征形成模型的训练集。{5}生成模型。根据实际工作需要设计分析模型。{6}训练模型。将训练集输入分析模型,得到最终完成训练的模型。{7}应用分析。获得了最终完成训练的分析模型就可以将其应用在贫困人口识别分析软件或相关平台上,对其中的贫困人口数据进行处理。
3 数据采集
根据各地扶贫工作实际情况的不同,可把以下数据收集纳入分析模型进行精准分析和有效运用。
(1)下乡扶贫工作中建档立卡采集的数据。这是分析工作所需的最基础的数据,根据这些数据能够获得基本的分析结果,但精度上难以达到精准识别的要求,仍需要更多的数据来提高分析精度。
(2)国土、公安、住建、工商、财政、编办、国税等部门的信息。这部分数据很重要,尤其是其中一些关键特征会直接影响对贫困户的分析评价结果。这些外联数据越详细、越准确,分析的结果也越准确。
(3)互联网数据。这部分数据的主要关注点在于贫困户以个人或组织的身份在互联网上的行为,如参与互联网金融商业活动的信息、网上交易信息等。这些信息能够在一定程度上反映该户人口的财务状况,为判定其贫困与否提供线索。
4 数据预处理与特征库构建
对采集到的数据进行清洗和整理,清洗内容包括编写数据的计算逻辑,处理异常值、缺失值,将有效结果输出或者直接编写数据去除和整理逻辑函数,然后将这些逻辑运算打包成分布式任务进行分布式计算,最后得到对业务有价值的数据源。
贫困户信息特征库由农户数据和外联数据2个部分组成。在数据挖掘的初始阶段,在各类源数据中抽取足够多维度的相关信息进行特征库的构建。首先,抽取农户数据中的人物属性数据(户主姓名、住址、家庭成员姓名及与户主关系等)和资产属性数据(财产、家庭年收入、房屋结构、装修情况等)。其次,根据人物属性数据关联各单位部门的外联数据。例如:{1}以人物属性作为主字段关联车管所信息,得到户主及家庭成员、直系亲属的所属车辆信息(车辆品牌、类别、价值、年限等)。{2}以人物属性作为主字段关联教育部门信息,获取户主及家庭成员、直系亲属的教育程度、受教育时间、技能培训等信息。{3}以人物属性作为主字段关联工商局系统,获取户主及家庭成员、直系亲属名下的注册商铺信息。{4}以人物属性作为主字段关联银行数据系统,获取存款、名下信用卡、刷卡消费等信息。{5}以人物属性作为主字段关联帮扶需求数据,获取主要致贫原因、次要致贫原因、“一主两辅”帮扶需求、帮扶措施、帮扶单位、帮扶责任人及其联系电话等信息。以此得到一个关于“贫困户”的1*n维的信息特征库,该特征库包含所有和“贫困户”直接相关或间接相关的信息。此步骤的关键要点在于以下2个方面:结合业务特性抽取尽量多的字段信息来构建特征库;各贫困户的特征维度需要保证一致性。
5 特征筛选排序
特征筛选与排序的目的是从贫困户信息特征库中筛选出有代表性的特征信息,这些特征信息可以有效地衡量单个贫困户的贫困程度,同时降低精准识别模型数据的复杂度。随机森林是一个包含多个决策树的分类器,它有一个特性就是在决定类别时,能够评估变量的重要性。基于此特征,可以使用该方法完成特征的排序,并选择排名靠前的m个特征作为模型训练的训练集。
5.1 建立随机森林
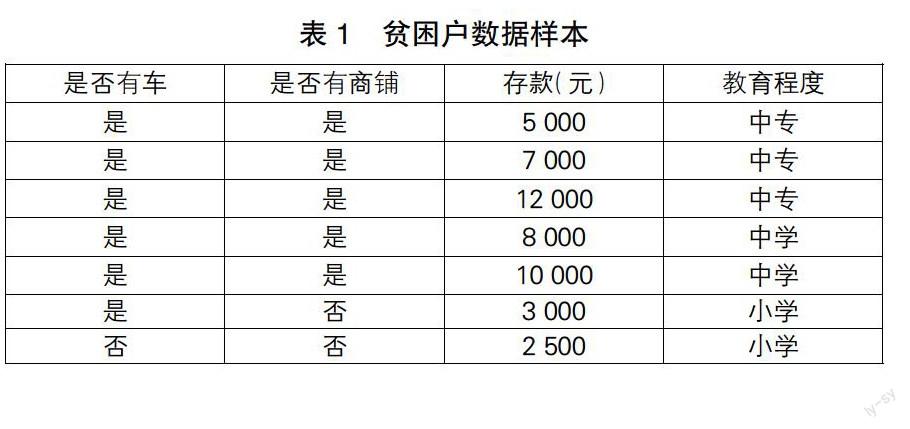
建立随机森林时,要对輸入的数据进行行采样和列采样。行即是数据集中的样本,列即是样本的特征(见表1)。在进行行采样时,采取有放回的采样方式降低过度拟合出现的可能:假设输入样本集包含样本数量为M个,则作为决策树根节点的采样样本数量也应为M个,这使得每一颗决策树包含的样本都不是样本集的全集。在进行列采样时,当样本有T个特征,则在分裂决策树的节点时,从样本的T个特征里随机选择t个,并且t<
5.2 特征筛选排序
通过对每一颗决策树应用袋外数据并加入干扰数据,可以测算特征的重要性程度。对多个特征随机加入干扰数据之后观察袋外准确率的变化,哪个特征在被影响后导致袋外准确率下降的幅度比其他特征更大,则说明该特征的影响力更大,重要性更高。将袋外数据误差记为errA,将加入干扰数据后再次计算的袋外数据误差记为errB,而一个随机森林中决策树的数量为N,则可以计算某个特征的重要性:
VI=■(errB-errA)/N
对特征按照重要性计算结果降序排列,并排除一定比例不重要的特征。用剩余特征再次建立新随机森林,再次计算选择重要性高的特征,排除重要性低的特征,如此循环直到剩余的特征数量达到预设的m个。
6 生成和训练数据分析模型
贫困户的精准识别一般采用分类算法,考虑到贫困户信息特征库中所使用的特征信息与贫困程度存在一定的相关性,一般采用决策树类算法模型。XGBoost算法是一種高效并被广泛应用的机器学习算法。它具备一般决策树的优点,并能够并行化实现,对于海量数据处理所需的资源也远远低于一般的算法。
XGBoost相比于传统GBDT在防止过拟合方面有很大的提升。而在分布式算法方面,XGBoost可以分布在不同机器内执行多个特征计算,最后进行结果汇总,从而具有分布计算的能力。在非分布式计算环境下,XGBoost也可以自动利用CPU进行多线程并行计算,同时由于其改进的算法又获得了相较传统GBDT更高的精度。
模型训练的过程是通过根据指定规则或其他方式定义的已人为确认的贫困户样本(该样本数量越多,训练出的模型越准确),并关联到筛选后的贫困户信息特征库中,得到训练样本,并将该训练样本加上贫困户的定义标签,输入到XGBoost模型中进行训练,得到由多个相同深度的决策树组成的分类器即贫困户精准识别模型。
通过参数调整即调整决策树的深度等参数值来调整模型的精度(重要的调整参数见表2),此过程中通过观察预测的精确值和ROC(AUC)值进行评估;可以对训练样本采用交叉验证的方式,通过观测预测的精确值和ROC(AUC)值选择出训练样本最优的模型。利用此模型即可对贫困人口数据进行挖掘分析,筛选出符合标准的贫困人口数据。
7 结语
目前,经过多年的扶贫开发,相关扶贫数据已有一定量的积累,尤其在国家“精准扶贫、精准脱贫”战略工程的推动下,全国各地纷纷加大力量推进精准扶贫工作,加大对贫困地区人口信息、产业资源等数据采集。把机器学习技术引入扶贫领域,促进数据分析技术与脱贫攻坚融合,利用机器学习和数据分析领域的研究基础和技术成果,研究脱贫攻坚数据建模分析、可视化展示等关键技术与应用模式,将在推进脱贫攻坚工作及大数据产业发展方面带来显著效果。
参 考 文 献
[1]程开明.统计数据预处理的理论与方法述评[J].统计与信息论坛,2007(6).
[2]方匡南,吴见彬,朱建平,等.随机森林方法研究综述
[J].统计与信息论坛,2011(3).
[3]路翀,徐辉,杨永春.基于决策树分类算法的研究与应用[J].电子设计工程,2016(18).
[4]杨静,张楠男,李建,等.决策树算法的研究与应用[J].计算机技术与发展,2010(2).
[5]董师师,黄哲学.随机森林理论浅析[J].集成技术,2013
(1).
[6]莫光辉.大数据在精准扶贫过程中的应用及实践创新[J].求实,2016(10).
[责任编辑:钟声贤]
猜你喜欢
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
电脑知识与技术(2016年23期)2016-11-02
中国市场(2016年36期)2016-10-19
商场现代化(2016年22期)2016-10-18
科学与财富(2016年28期)2016-10-14
