
从WOS地址字段提取二级机构数据的半自动数据清洗方法
2017-09-06 20:48何春建
新世纪图书馆 2017年8期
关键词:科技查新
何春建


摘 要 各高校都需要统计本校各个二级机构Web of Science (WOS)发文情况,论文提出一种基于正则表达式的半自动数据清洗方法,可从WOS地址字段中提取出发文机构排名、所属二级机构名称以及对应作者群,并以2015年南京师范大学WOS发文统计为例,进行实证研究,分析出各院系发文情况和作者发文情况。
关键词 二级机构 正则表达式 数据清洗 WOS地址字段 科技查新
分类号 G250.78
DOI 10.16810/j.cnki.1672-514X.2017.08.012
A Semi-automatic Data Cleaning Method for Extracting Secondary Institutions Data from WOS Address Field
He Chunjian
Abstract Chinese higher education institutions need to count the articles included in Web of Science (WOS) by their secondary institutions. This paper puts forward a semi-automatic data cleaning method based on regular expressions for extracting ranking of the dispatch agency, name of the secondary institutions and the corresponding authors from WOS address fields. At last, it takes the statistics of articles included in WOS of Nanjing Normal University in 2015 as an example to conduct an empirical study, and analyze the situation of the articles issued by various faculties and authors.Keywords Secondary institutions. Regular expression. Data cleaning. WOS address field. Sci-tech novelty search.
0 引言
Web of Science(WOS)不仅是世界范围内最权威的科技文献索引工具之一, 也是科研评价的一种依据。科研机构被WOS收录的发文总量及被引用次数, 反映整个机构的科研, 尤其是基础研究的水平。各高校均需对本校WOS发文进行统计,这些WOS论文的收录及被引情况是机构内部重要的考核指标。而在统计这些WOS论文的时候,需要将检出的所有文献全部准确地划分到各个二级机构,最终归属到具体作者,以便主管部门全面了解各院系科研情况并统计考核教职工的科研工作。然而直接从WOS数据库下载的数据中没有专门的二级机构字段。二级机构的信息包含在地址字段中,所以需要对地址字段进行数据清洗,以便准确快速地获取二级机构的信息。
梁桂英等[1]研究了如何构建非特异性机构论文检索式,丁海德等[2]研究了地址信息著录差异与错误分析,苗艳荣、房文革[3-4]研究构建合适的机构检索式,兼顾查准率与查全率,这些文献的焦点均是查准查全一级机构发文,没有关注二级机构。张晋辉等[5]提出一种SCI地址字段数据清洗方法,也不以二级机构为研究对象。张红燕、胡小洋等[6-7]提到了高校WOS发文的院系分布情况,但没有提及是如何进行文献清洗的。刘贤玉[8]报道了一种快速统计学校中二级机构学院论文的方法。本文通过分析、對比、拟选取WOS中的地址字段为研究对象,利用正则表达式对该字段进行文本处理,清洗数据后可获得二级机构变名,再辅以人工识别将得到的二级机构变名划归到具体的学院。本文不预设二级机构的变名,不依赖于对作者的熟悉程度,最大程度地降低了人工排查的工作量,使得数据统计既快捷又准确。
1 数据收集与清洗方法
1.1 数据收集
检索策略及方法: 在WOS数据库的检索页面中的地址栏输入“Nanjing normal univ”, 在日期范围内输入“2015—2015”。选择数据SCI-EXPANDED、SSCI、A&HCI、CPCI-S、 CPCI-SSH,检索时间2016年1月10日,共计检索出982条记录。
将检索到的文献记录选择“保存为其他文件格式”,选择记录内容为“全记录”,文件格式为“制表符分隔(win)”分批选择“1-500”“501-982”,分批将检索到的记录下载并合并,获得982条数据记录,并以其中的地址字段(C1)为研究对象。
1.2 数据清洗
在2008年系统升级后,WOS数据库的地址字段就比较规范,下面是其中一条典型的地址字段记录:[Lu, Si-Yuan; Zhou, Xing-Xing; Zhang, Guang-Shuai] Nanjing Normal Univ, Sch Comp Sci & Technol, Nanjing 210023, Jiangsu, Peoples R China; [Wei, Ling] Shanghai Jiao Tong Univ, Sch Elect Informat & Elect Engn, Shanghai 200030, Peoples R China。
WOS的地址字段可以归纳为下面的模型:[authors(N,1)] address(N,1); …[authors(N,x)] address(N,x); …[authors(N,Y)] address(N,Y); 其中authors(N,x)是第N条记录的第x个作者群,address(N,x)是第N条记录的第x个作者群的共同署名机构。
将得到的数据记录中的C1字段复制到文本处理软件Emeditor中,利用正则表达式,查找“; \[”,替换为“; /t[”。处理后的文本记录可以表达为:[authors(N,1)] address(N,1);…[authors(N,x)] address(N,x);…[authors(N,Y)] address(N,Y); 再将处理后的数据复制到excel中,我们可以获得第N条记录中第x个作者群和机构信息为C1(N,x)=[authors(N,x)] address(N,x);再对C1(N,x)分析,利用正则表达式,查找“] ”,并替换为“]/t”,进而可以得到authors(N,x)以及相应的address (N,x)。通过上述的文本处理和excel处理,就获得了所有记录的所有排序的署名作者群及相应的署名作者机构信息。
在excel中对address(N, x) 字段分析,依次遍历x=1…Y,判断address(N, x)是否包含“nanjing normal univ”, 假设address(N, k)是第N条记录中第一个包含“nanjing normal univ”的地址信息,记录jg (N)=k,taget(N)= address(N, k),authors(N)= authors(N, k)。在进行上述数据分析时发现有一条记录的整个C1字段中不包含“nanjing normal univ”,经研究发现这条记录之所以被检出,是因为在通讯作者字段(RP)中出现了“nanjing normal univ”。如果是第M条记录的CI字段中没有出现nanjing normal univ,则假定jg (M)=0,taget(M)=null。将address(N,x), N=1…982,进行遍历处理,数据清洗后获得三组数列jg (N)、taget(N)、authors(N)。jg (N)是南京师范大学(以下简称“我校”)在第N篇论文的机构排名,taget(N)是我校的具体署名地址信息,authors(N)是对应的作者群。
2 南京师范大学二级机构及作者分析
2.1 一级机构分析
对jg (N)分析可以了解982条记录中不同署名排序的发文情况。我校发表的WOS论文中第一署名机构发文573篇,占比58.4%,非第一作者机构发文409篇。
对非第一作者机构的发文部分,再分析它们的address(N,1)即第一署名机构,可知我校与144家机构合作,共发表论文419篇。其中发文1篇的97家,发文2-3篇的22家。发文4篇以上的25家机构共计发文259篇,占南京师范大学非第一机构合作论文数的61.8%,见表1。从表1可知我校的主要合作机构以中科院和江苏高校为主,省外合作以及国际合作的论文较少。
2.2 二级机构分析
从taget(N)数列的获取方法可知:如果我校有多个二级机构同时参与该论文,只取排序靠前的那个二级机构。将taget(N)数列在excel中利用分类汇总显示署名机构共有467种不同写法,直接分析taget(N)数列工作量很大。taget(N)数列中包含了二级机构的信息,可以把它们提取出来。
首先来看一条典型的taget(N)的信息:“Nanjing Normal Univ, Sch Math Sci, Inst Math, Nanjing 210023, Jiangsu, Peoples R China”。从上述格式可以看出,署名机构的一般格式中会包含“南京师范大学,二级机构名称, 邮编,省, 国家”等信息。上述信息中我们关心的其实只有二级结构名称如“Sch Math Sci”,通过这个信息我们就可以判断这条记录属于南京师范大学数学科学学院。我校的二级机构基本上是某学院、某系、某实验室、江苏省某重点研究中心等,而这些二级机构在taget(N)中大多以sch、coll、fac、inst、dept、lab、key、ctr、jiangsu開头,也有作者署名时书写不规范导致有少部分记录的二级机构名以sch、coll、fac、inst、dept、lab、ctr为结尾。利用这个规律,可通过对taget(N)的处理获得对应的二级机构名称。
将taget(N)数列复制到文本处理软件“Emeditor”中,利用正则表达式,反复查找“(.*),[ ]?((coll|sch|dept|ctr|lab|inst|fac|Jiangsu |key)[^,]*)(.*)”,并替换为“\1\t\2\t\4”,通过这个步骤可以处理所有开头是coll、sch、dept、ctr、lab、inst、fac、key、Jiangsu的二级机构名称,再反复查找“(, )([^,]*(coll|sch|dept|ctr|lab|inst|fac)),”并替换为“\1\t\2\t”,通过这个步骤可以处理所有结尾是“coll、sch、dept、ctr、lab、inst、fac”的二级机构。通过上述两次查找替换可以把taget(N)数列中所有的二级机构前后均加上制表符,再把处理后的数据复制到excel中,就可以获得二级机构数列inst(N),其中有49条记录的inst(N)为空,是因为taget(N)中不包含任何二级机构信息,其署名信息如:“Nanjing Normal Univ, Nanjing 210023, Jiangsu, Peoples R China”。
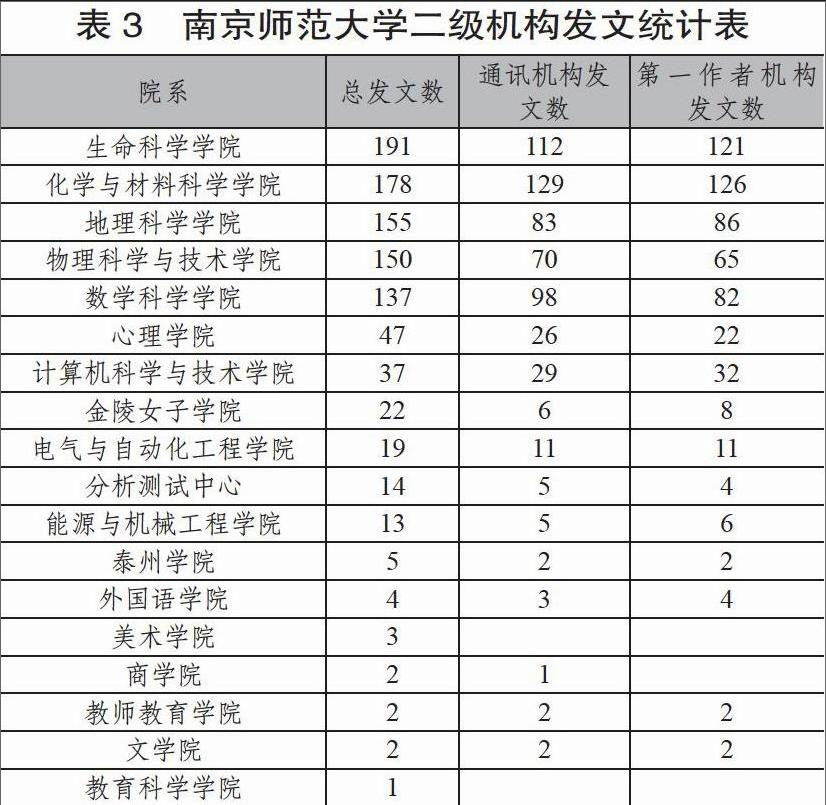
将获得的inst(N)数列在excel中汇总分析,非空的inst(N)共包含101种不同的二级机构变名,共得到论文933篇。其中发文量前二十的我校二级机构变名见表2,这二十个机构变名合计发表论文761篇占全体记录的77.5%。建立101种二级机构变名与二级机构名的映射表,利用建立的映射表通过excel的VLOOKUP函数可分析其中的930篇论文的二级机构名。再将不能区分的3篇以及49篇inst(N)为空的记录利用对应的authors(N)字段进行人工筛选,最后可将所有发文归类到各二级机构。对RP字段采用相同的数据清洗方法可以分析出通讯作者、通讯作者署名机构等信息,最后获得南京师范大学各二级机构的WOS发文情况,见表3。
在對inst(N)分析的过程中发现仅生命科学学院对应的机构变名数就多达14种,包括“Coll Life Sci”“Sch Life Sci”“Dept Life Sci”等,建议由各二级机构引导本单位作者规范署名,以方便将来的成果认领。
2.3 作者分析
为了解我校哪些作者在WOS发文最多,需要将论文划归到具体作者。为避免一篇论文有多位作者认领,设计了如下的划分方案:如果论文的通讯作者是我校作者A,则这篇论文归作者A,如果有共同通讯作者则这篇论文归共同通讯作者中排名靠前的那位;如果论文中我校作者虽非通讯作者但是第一作者,则这篇论文归第一作者;如果我校作者既非通讯作者又非第一作者,则该论文归论文中我校作者排序第一的作者。结合二级机构信息初步区分本校同名作者,再按照划分方案,可将所有982篇论文全部划归到具体作者,其中WOS发文数前十的作者见表4。
3 结语
本文利用正则表达式对WOS的地址字段进行数据清洗,从C1字段提取出署名机构排名、二级机构以及对应的作者群信息。以南京师范大学2015年的WOS发文的统计为例,展现如何获得发文署名排序以及二级机构发文一览表,通过二级机构和对应的作者群信息,初步区分同校同名作者,将全校发文归类到具体的作者,为高校职能部门全面了解各二级机构以及具体作者的科研情况提供基础数据。统计过程中还获得了各二级机构的多种机构变名,并建立机构变名与二级机构的衍射表方便将来的数据统计工作。本文以具体案例向读者展示了WOS论文统计的数据清洗过程,希望对其他学校的论文统计工作有所助益。
参考文献:
[1]梁桂英,袁润.基于Web of Science的非特异性机构论文检索模式构建[J].情报杂志,2015(4):176-180.
[2]丁海德,庞芳芳,李德成.SCI数据库中地址信息著录差异与错误分析[J].现代情报,2008(4):173-174.
[3]苗艳荣.机构检索在不同数据库中的检索方法及技巧[J].高校图书馆工作, 2015(6):59-62.
[4]房文革,王丽君,张红.基于Web of Science的机构检索方法[J].农业图书情报学刊, 2015(4):64-66.
[5]张晋辉,刘清.基于推理机的SCI地址字段数据清洗方法设计[J].情报科学, 2010(5):741-746.
[6]张红燕,董湧,邵晋蓉.基于SCI的宁夏大学科研论文产出统计与分析[J].宁夏大学学报(人文社会科学版),2016(1):193-196.
[7]胡小洋,游俊,赵燕.文献计量分析:专业编辑的可选学术研究方向:以江汉大学1980年以来三大索引收录论文的统计分析为例[J].江汉大学学报(自然科学版), 2012(4):54-58.
[8]刘贤玉,周小东.基于Web of Science快速统计学校(学院) 论文的技巧[J].图书情报工作, 2013(S2):210-212.
猜你喜欢
现代情报(2016年12期)2017-01-16
现代情报(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
中国中医药图书情报(2016年4期)2016-10-20
商(2016年20期)2016-07-04
科技视界(2016年12期)2016-05-25
科技视界(2016年10期)2016-04-26
图书馆界(2016年1期)2016-03-28
企业文化·中旬刊(2015年4期)2015-05-07
医学信息(2015年7期)2015-03-20
