
基于网络搜索数据的房地产价格指数的短期预测
2018-05-17 06:49胡本田年靖宇
铜陵学院学报 2018年6期
胡本田 年靖宇
(安徽大学,安徽 合肥 230601)
2016年,合肥、厦门、南京、苏州4个城市的房价涨幅一度领跑全国,带来了一轮全国房价的快速上涨,引起了诸多的社会经济问题。因此提前对房价进行预测,能够起到维护经济稳定的作用。考虑到房地产市场中一般会存在三个主体,即消费者、房地产开发商和政府,房价上涨或下跌的因素有部分来源于这三个主体的行为,在购房或开发房地产之前消费者和房地产开发商会预先利用手头的资源去更全面的了解房地产情况,这时候,他们往往会利用网络搜索引擎去查询搜索所需要了解的信息,这就会在搜索引擎的后台留下数据,比如谷歌指数,百度指数等等,因此可以利用网络搜索引擎后台所记录的关键词搜索量,来了解人们对于房地产的需求状况。
据中国互联网网络发展状况统计报告显示,截至2017年12月,我国网民规模达7.72亿,普及率达到55.8%,其中手机网民占97.5%,而网民使用频率最高的应用仍为即时通信、搜索引擎、网络新闻等等,在国内各大搜索引擎中,百度搜索是人们最常用的搜索引擎,在2016年就已经有82.9%的网民使用,搜狗搜索位于第二,有41.1%的网民使用,鉴于百度搜索在网民中具有很好的渗透率,所以本文欲利用百度指数上的关键词搜索数据,通过找寻搜索数据与房地产价格指数之间的关系,以此来对房地产价格指数进行短期预测。
目前对于房价的预测可以分为以下几个阶段,先是有王聪,王昊,盖美、田野利用多因素回归模型来对房价进行预测,找到影响房价的因素,利用这些因素所代表的指标进行回归,从而达到预测的目的[1-3]。然后有学者将灰色理论应用到房地产价格的预测中去,任文娟、杜葵表明房地产市场是一个有着已知因素和未知因素的灰色系统,因此可以使用GM(1,1)模型来对房地产价格进行预测[4]。之后学者利用数据挖掘算法来对房价进行预测,在数据挖掘算法中,研究利用最多的是SVR算法和BP神经网络,对于SVR算法,申瑞娜,张彦周、贾利新,袁秀芳等都建立了基于SVR的商品房价格预测模型[5-7]。而周学军等,高平等就利用BP神经网络算法对房价进行预测,均取得了不错的效果[8-9]。但是上述的研究中,所使用的房价数据基本上都是年度数据,此数据非公开并且没有时效性用,有学者就开始研究房地产价格指数数据。对于房地产价格指数的预测的最新研究是通过利用网络搜索数据,通过引入网络搜索数据,一般是谷歌指数或者百度指数上面关键词搜索量数据,以此来建立模型。该理论最先是Ginsberg et al.利用Google搜索数据成功地预测美国流感疾病趋势[10],在取得不错的效果之后,Kulkarni R.et al.,Schmidt T,Vosen S分别利用网络搜索数据对失业率和caseshiller指数中进行预测,能够在官方数据发布前提前知晓情况[11-12]。董倩等利用网络搜索数据对15个大中城市的房价指数进行预测[13],庄虹莉等,张娟以百度指数上面的关键词为解释变量,分别建立模型对房地产价格指数进行预测[14-15],蒲东齐等(2018)则得到利用搜索数据预测商品房价可领先于官方发布数据10-15天的结论[16]。
但是目前国内学者的研究中,存在基期未转换、未进行随机性检验、主成分合成指数不好解释,随机波动性未剔除等问题。鉴于此,本文选取这次涨幅最大的二线城市——合肥市,以2011年1月至2018年2月的新建商品房销售价格指数的同比数据来进行房地产价格指数的预测。由于该指数每五年轮换一个基期,所以为了具有可比性,需要先将2016年至2018年的数据全部转换为以2010年为基期的数据,但因为百度指数的数据在2011年才开始收集,所以为了使数据的时期相同,我们将合肥市2011年的每月数据分别作为基期,计算得到合肥市2012年1月至2018年2月的新建商品房销售价格指数同比数据,对百度指数上的关键词搜索量的处理也按照上述方法来做,之后再通过简单筛选和相关性检验,得到与房地产价格指数有关系的关键词数据,然后利用lasso算法在众多关键词中提取特征,找到最终的解释变量,以时间段为2012年2月至2017年8月的数据作为训练集,2017年9月至2018年1月的数据作为检验集,利用SVR模型对训练集进行训练,通过检验集找到训练模型中的最优模型,最后利用最优模型来预测合肥市新建商品房销售价格指数。
一、模型构建
(一)理论基础
在房地产市场上,存在一个供求关系,
房地产开发商是供应的一方,而购房者则是需求的一方,他们对房地产市场的反应可以用他们的搜索行为来代替,因此可以把这些网络搜索数据加入到预测模型中。此外房地产市场还受到了政府宏观调控的影响。该理论可以用图1来表示。
(二)变量描述
1.被解释变量
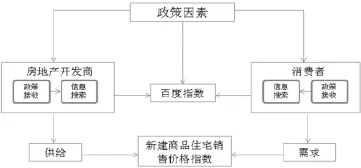
图1供求理论框架图
国家统计局从2011年1月份开始,就开始发布70个大中城市的新建商品房价格指数,分别包括新建住宅销售价格指数和新建商品住宅销售价格指数,由于在2018年1月就已经不公布新建住宅销售价格指数,所以在此我们选取的是新建商品住宅销售价格指数的同比指数来进行预测,通过对数据进行处理之后,我们使用的是2012年1月至2018年1月的扣除了一般物价因素影响的数据,数据见表1,此数据反映了房价的实际变动,具有可比性,我们将此数据作为被解释变量,命名为Y。
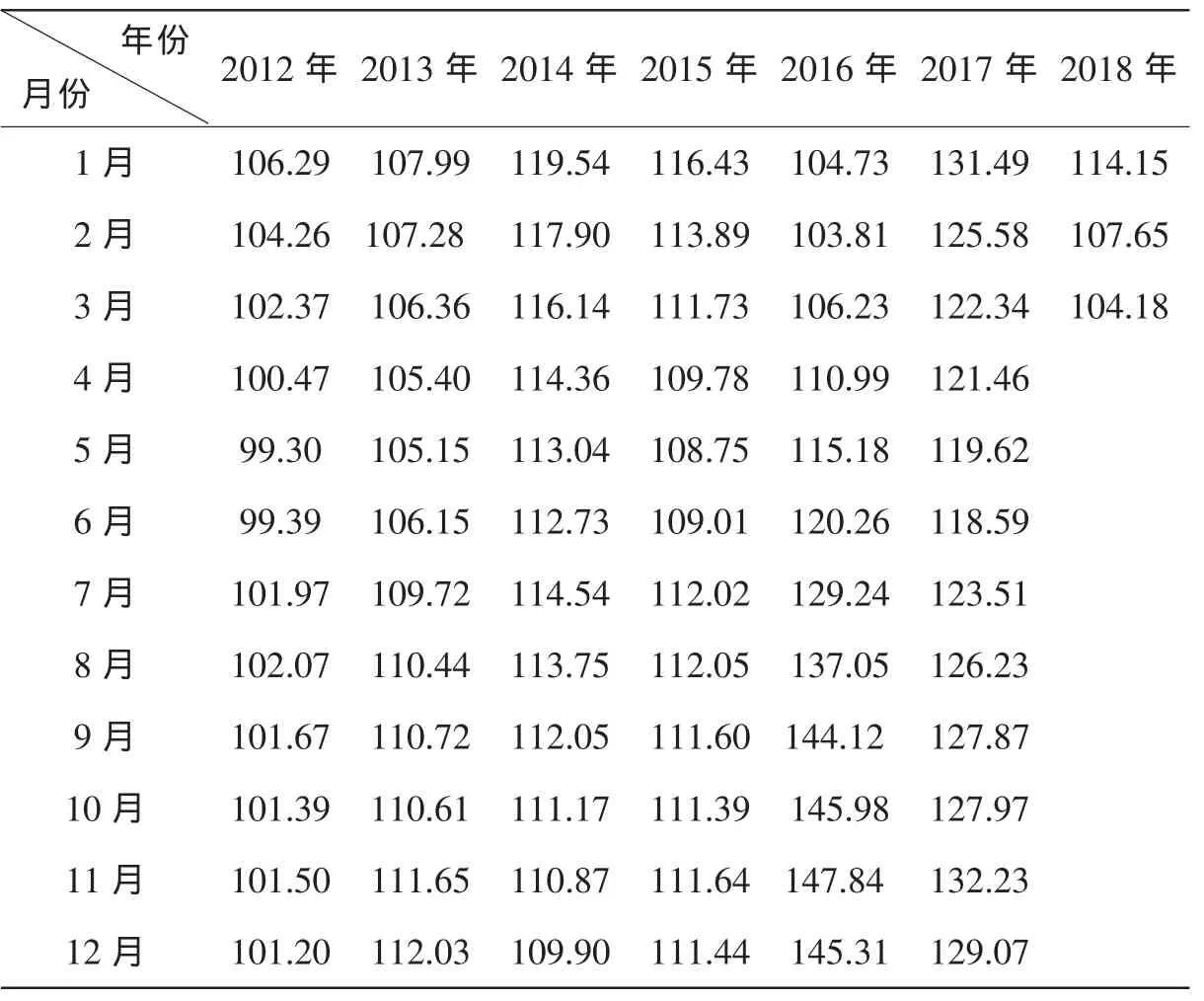
表1剔除一般物价指数后的合肥市新建商品房价格指数的同比指数
2.解释变量
考虑到房地产市场的各个主体,分别从供应、需求、政策三个因素中,确定7个初始关键词,它们是楼盘、中国建材网、合肥市房产网、合肥房价、房价调控、房贷利率、住房公积金,然后再利用百度长尾关键词工具得到102个关键词,关键词见表2。
分别对这102个关键词进行百度指数的查询,发现在102个关键词中,有28个关键词未被百度指数所收录,因此在网站上爬取不到这28个关键词的有效数据。在百度指数的页面,输入关键词,再通过审查元素就可以得到网页的源代码,利用java和maven两个软件,可以抓取剩下的74个关键词从2011年1月至2018年2月每天的搜索数据,将爬取到的关键词天数据累加为月度数据,按照处理被解释变量的方法对这些关键词数据进行处理。又由于网络搜索数据有很大的波动性,所以处理之后我们再用HP滤波法对数据进行长期趋势的提取,得到初步的解释变量。

表2部分关键词数据
在这74个解释变量中,首先需要进行简单的筛选,剔除那些搜索记录为0的变量,发现所选变量均未出现上述情况,然后对剩下的变量进行随机性检验,然后再检验各个变量与被解释变量的相关系数,相关系数如果小于0.4,认为显著不相关,所以剔除。将相关系数绝对值大于0.4的变量留下,最后留下了36个变量。由于变量之间存在很严重的共线性,利用主成分分析法进行降维又存在很多问题,而lasso算法能够有效处理多重共线性,它的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使得残差最小化,从而可以将所选入的一些对模型没有贡献的指标系数直接压缩为0,达到特征选择或者压缩变量的目的。在R语言中可以使用Lars函数包实现这一过程,利用AIC准则给统计模型的变量做一个截断,实现降维过程。通过程序运行的结果,我们最终选用5个变量作为解释变量,这五个变量代表的关键词分别是房贷利率表,合肥房产地图,房贷利率优惠,房价调控,个人所得税,我们将这五个变量依次命名为 X1、X2、X3、X4、X5,可以看出,这五个变量基本上未涉及到房地产开发商的行为,即使我们在确定初始关键词的时候,选取了房地产开发商可能会进行搜索的关键词,但是发现与我们所要研究的房价指数并没有什么明显的关系,所以在接下来的建模过程中,利用上述五个解释变量可能会遗漏关于房地产开发商的影响因素,这也是文中的不足之处,但是由于技术水平的限制,如何找到与房价有关的供给方面的关键词,还需要进一步的研究。
3.解释变量与被解释变量的关系
分别作出Y与X1-X5的折线图,如图2-6所示,可以看出,X1、X2、X3与 Y的整体趋势刚好是相反的,而X4、X5与 Y的整体趋势是相同的,尽管在某些时间内存在一些差异,因此利用搜索数据来预测房价指数是可行的。
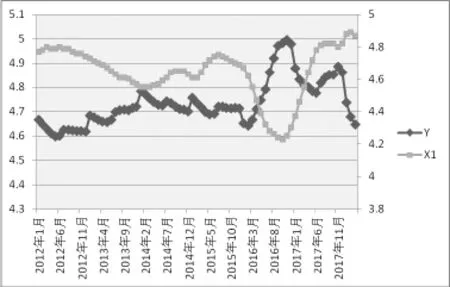
图2 Y与X1的双轴图
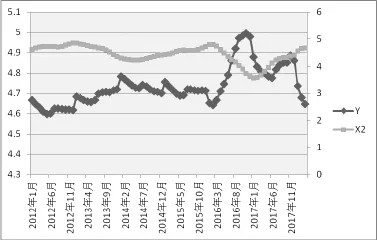
图3 Y与X2的双轴图
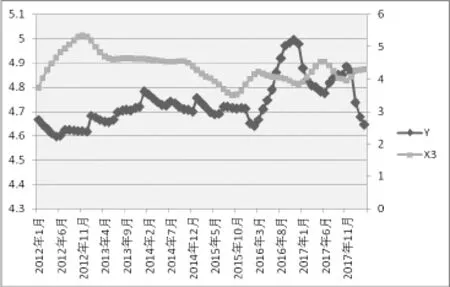
图4 Y与X3的双轴图
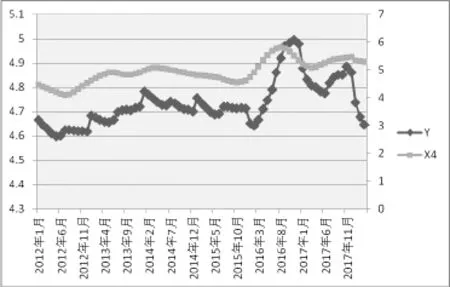
图5 Y与X4的双轴图
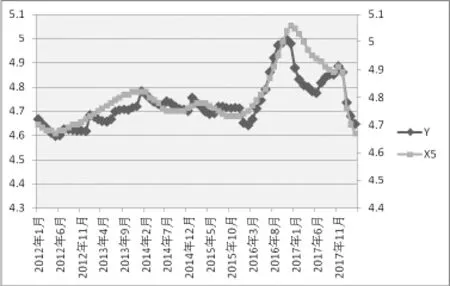
图6 Y与X5的双轴图
4.预测模型的建立与分析
(1)SVR 模型
SVR(支持向量机回归)模型实际上是SVM(支持向量机)的一种推广形式,支持向量机是目前最为常用、效果最好的分类器之一,因为其本身的优化目标是结构风险化最小,而不是经验风险最小,因此减低了对数据规模和数据分布的要求,能够在小样本训练集上有突出的表现,SVM的提出首先是为了解决分类问题的,而SVR则是解决回归问题的。因此这两种模型的目标函数都是一样的,与SVM相似,通过最小化结构风险函数构造的原始优化问题可以求解权重向量以及常数:
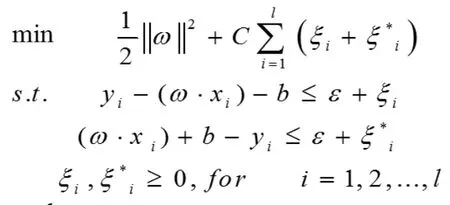

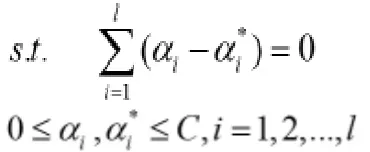
(2)模型的评价指标
使用MSE(均方误差)和NMSE(标准均方误差)来比较两个模型,其中,模型的稳定性由MSE判定,模型的拟合度由NMSE判定,两个评级指标的数值都是越小越好,两个指标的公式如下:
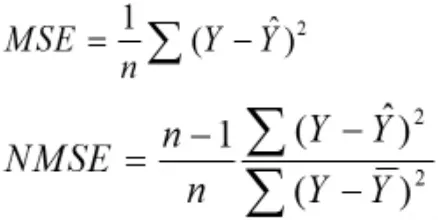
二、实证研究
考虑到需要检验模型的可靠性,我们将样本分为训练集和检验集,训练集的时间区间为2012年1月至2017年12月,检验集的时间区间为2018年1月至2018年3月,以训练集来建立模型,以检验集来检验模型的可靠性。
(一)SVR模型的建立与分析
将数据导入R语言中,利用kernlab函数包来实现SVR的过程。在SVR中需要确定参数的最优值,使用train.auto函数确定最优值,得到最优值为ε=0.1,C=10,通过运行已经写好的程序,对训练集进行拟合,计算出该模型的MSE和NMSE分别为2.34和0.018,可以看出模型的预测精度很好。为了验证该模型的预测效果,我们引入传统的时间序列模型SARIMA模型与其进行比较。
(二)SARIMA模型的建立与分析
SARIMA模型是指带季节差分ARIMA的模型,如果时间序列只包含趋势性,可以表示ARIMA(p,d,q)模型,如果时间序列同时包含季节性和趋势性,则可表示为 SARIMA(p,d,q)×(P,D,Q)s。 其中,d,D 分别为逐期差分和季节差分的阶数,p,q分别为自回归和移动平均的阶数,P,Q分别为季节自回归和季节移动平均的阶数。
考虑到异方差的问题,在建立模型前,对数据都进行了取对数处理,然后导入数据,利用R软件画时序图,发现房价指数序列存在季节性和趋势性,利用zoo函数包和forecast函数包来实现SARIMA模型的预测,通过arima.auto函数寻找拟合最优的模型,最终得到最优的模型为 SARIMA (1,1,0)×(2,1,0)12,ar1的系数为 0.5638,sar1的系数为 0.6892,sar2的系数为-0.2759,该模型的MSE和NMSE分别为5.69和0.043。
(三)模型预测结果的比较
通过训练集的拟合结果来看,加入了搜索项的SVR模型要优于仅使用历史数据的SARIMA模型,为了推广到未知样本的情形,我们利用检验集再一次的检验两个模型的预测效果,在此我们以平均误差率来评价模型的精度,计算得到的平均误差率见表3,可见如果未来发生波动,SARIMA模型由于只能利用历史数据,预测效果就会变差,而SVR模型由于利用了即时的信息,预测效果不会发生很大的改变,因此可以利用SVR模型对合肥市的房价指数进行预测。 预测得到合肥市2018年4月的新建商品住宅销售价格指数为106.25。(本文中的预测值均是扣除了一般物价指数因素后的值)
三、结语
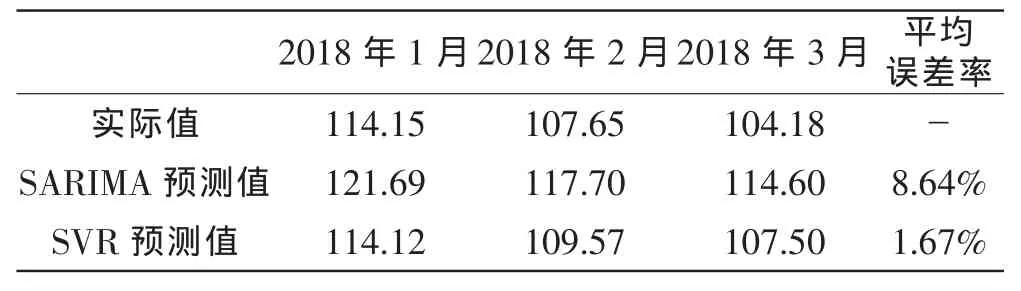
表3两个模型的预测值及平均误差率
本文首先从供需理论出发,找到百度指数关键词搜索数据与房价指数之间的相关关系,然后以合肥市2012年1月至2018年1月的新建商品住宅销售价格指数以及“合肥房价”、“楼盘”、“建材网”等74个关键词数据,通过lasso算法选取进入模型的关键词,以此来对房价指数进行拟合与预测,得到结论:
1.加入搜索数据的SVR模型的预测效果要好于ARIMA模型,这说明网络搜索数据是可以用于房价指数的预测中去的。
2.不仅仅是房价指数数据,只要能够从理论出发,利用网络搜索数据可以对其他变量进行预测,比如股票的收益率,CPI指数、失业率等。
3.只要每个月月底对搜索数据进行处理,就能得到该月的房价指数,而官方数据发布时间通常是下个月15-20号,因此利用模型预测房价指数可以比官方数据提前15-20天,能够实时的对房地产市场进行监控,有很好的预警效果。
4.利用网络搜索数据建立预测型,怎样科学的选取关键词是难点,在本文中,即使综合考虑了三个方面的因素,也不能完全代表房地产市场的各种因素,这也是本文中存在缺陷的地方。百度指数上的关键词搜索数据,并不能完全代表消费者和房地产开发商的整体行为,因为还有一部分人买房是通过其他搜索引擎或传统方式 (传统媒体或亲戚朋友口耳相传)收集信息的,所以下一步研究还得考虑到各个地区网络普及率的情况。
猜你喜欢
纺织服装周刊(2022年15期)2022-05-12
今日农业(2021年5期)2021-11-27
房地产导刊(2021年8期)2021-10-13
房地产导刊(2020年11期)2020-12-28
Defence Technology(2020年4期)2020-07-02
中华建设(2019年8期)2019-09-25
青年与社会(2018年2期)2018-01-25
大众理财顾问(2016年10期)2016-12-02
大众理财顾问(2016年9期)2016-10-11
商业文化(2016年3期)2016-04-19
