
卷积神经网络并行训练的优化研究
2018-08-21 01:59李相桥田丽华张玉龙
计算机技术与发展 2018年8期
李相桥,李 晨,田丽华,张玉龙
(1.西安交通大学 软件学院,陕西 西安 710049;2.中航工业西安飞行自动控制研究所,陕西 西安 710065)
0 引 言
近年来,神经网络在图像识别、语音处理等方面取得了巨大的成果并得到了广泛的关注。特别是2012年出现的AlexNet卷积神经网络在图像分类方面取得了巨大的突破,在ImageNet数据评测集上将错误率大大降低[1]。之后改进的卷积神经网络将错误率降低到到人类水平[2]。在语音处理与理解方面,微软亚洲研究院以及其他研究学者们利用神经网络模型同样获得了非凡的效果[3]。
卷积神经网络(convolution neutral network,CNN)属于人工神经网络(artificial neutral network,ANN)的一种,训练时采用误差反向传播算法(back propagation,BP)[4],该算法目前已经广泛应用于机器学习和模型识别中。但由于CNN模型的计算量巨大,模型训练往往需要消耗大量的时间。目前一般使用多GPU的方式进行并行训练,但在并行的过程中由于需要相互等待以及配置并行本身会引入额外的开销。随着并行度的增大,同步等待时间不断增大,使得GPU间的数据通讯变得缓慢,从而影响到了模型训练的速度,这无疑成为目前需要解决的一个问题。
国内外的学者已经针对神经网络的并行训练问题展开了相关研究。文献[5]提出了一个由1 000台机器共16 000块CPU组成的并行的神经网络模型训练系统DistBelief,并对训练算法进行了改进,抛弃传统的同步算法改为异步的方式。异步算法无需等待,从而节省了同步等待时间,加快了模型的训练速度。但由于异步算法的不确定,无法保证网络模型一定会收敛,有些神经网络模型由异步算法训练出来会有明显的性能下降[6]。文献[7]将每次所用的Minibatch进行并行,将训练数据均匀划分给GPU同时进行计算,节约所需时间,同时还利用支持PCI-E 3.0规范的Peer-to-Peer协议来加速数据传输。文献[8]则利用分布式内存进行模型的并行训练,训练数据以及中间结果都存储在内存中,减少磁盘I/O带来的额外开销。文献[9]在语音识别方面,利用多个GPU构建了一个并行架构,并取得了不错的效果。文献[10]对经典的深度学习模型进行性能测试,分析了深度学习及并行算法的性能问题。
在上述研究的基础上,文中针对卷积神经网络并行训练中的参数通讯以及数据加载进行进一步优化,通过算法流程的重新排布使得计算和通讯可以同时进行,同时改进通讯的方式以加快数据通讯的速度,最后利用异步拷贝与预加载的方式将训练所需的数据提前加载,减少数据加载与拷贝的时间消耗。
1 模型训练
本节主要分析神经网络模型训练中的BP算法以及并行训练过程,确定目前并行过程中影响并行效率的主要因素。
1.1 BP训练算法流程
假设一个神经网络模型被定义为输入x到输出y的映射,表达形式如下:
y=f(x,w)
(1)
其中,f(x,w)为一种映射;w为模型参数。
BP算法就是通过数据以及标签信息不断地迭代计算,寻找最适合的模型参数w,使模型达到最优的效果。BP算法的单次计算过程分为两个部分:前向计算和后向计算。前向计算时,一组输入数据会逐层经过网络模型计算输出结果,中间的每一层都会使用上一层的输出作为本层的输入进行计算。后向计算中,首先根据网络模型的输出和真实的标签进行比较,计算误差函数,然后将误差项逐层传递并计算每一层参数的梯度,最后通过随机梯度下降法(stochastic gradient descent,SGD)调整模型参数w,使误差向减小的方向进行。整个迭代计算并修改模型参数w的过程可以表示为:
wi+1=wi-ηE(wi)
(2)
其中,i为当前的迭代次数;η为学习率;E为误差项。
在后向计算过程中,每一层根据来自上一层的误差项计算本层参数的梯度,并计算本层的误差项,计算完成后将本层输入误差项传递给下一层。由此将误差信息通过反向传播的方式逐渐向下层传递。
1.2 并行训练过程
目前CNN模型的并行训练主要分为模型并行和数据并行两种方式。在文献[5]中主要利用数据并行方式实现大规模的并行训练,文献[11]针对卷积神经网络给出了并行策略的使用建议。文献[12]对于卷积神经网络的训练给出了基于分布式的一些并行策略,文献[13]中对数据并行与模型并行进行了实验对比,说明了数据并行的效率要高于模型并行,因此文中也主要针对数据并行进行研究与优化。在数据并行方式中,每次迭代计算时使用的一批数据构成一个mini-batch,数据并行就是对mini-batch进行划分,每个GPU使用部分输入数据进行计算,最终再将所有计算结果汇聚起来,进行模型参数更新,其结构如图1所示。
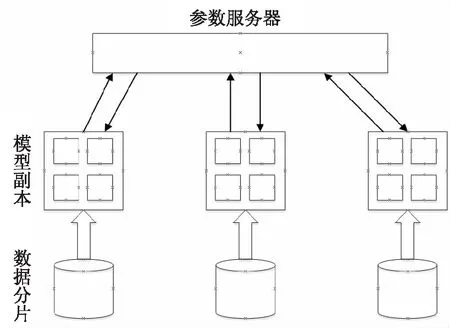
图1 数据并行结构示意
从图1可以看出,模型副本首先从参数服务器处获取最新的模型参数,接着在本地使用自己的训练数据进行一次前向与后向计算,计算完成时将参数的梯度发送给参数服务器。参数服务器收到所有模型副本的梯度后,一般会利用随机梯度下降法更新模型参数。最后将更新后的模型参数发送给各个模型副本开始下一轮的迭代计算。这种方式与串行训练完全等效,并且实现也较为简单。但在上述过程中,由于参数服务器需要等待所有的模型副本发送完梯度后才能进行参数更新,这样已经发送完成的模型副本就需要同步等待。当模型副本数目较多时,各自完成计算的时间稍有差异,导致同步等待时间过长,从而严重影响模型训练的速度。
2 优化策略
针对上述过程中影响计算速度的因素,文中将通过改变通讯以及训练数据加载的方式,减少因等待带来的额外开销,提高模型训练的效率。
2.1 梯度计算和参数通讯的并行化
由1.1节可知,利用BP算法训练神经网络时分为前向计算和后向计算两个部分,其中后向计算主要完成梯度的计算。在数据并行训练过程中,后向计算在完成梯度计算时,还需要将计算的结果作为参数传递给参数服务器,参数服务器则利用接收到的数据对全局模型进行更新。这个过程中一个很重要的问题就是数据传输必须在梯度结果计算完成后进行,这样当参数量较大时数据的通讯会消耗较多的时间。对于这个问题,文中拟通过对计算流程重新排布的方式来做到并行执行,利用梯度计算的时间来掩盖参数通讯的时间。
由BP算法的介绍可知,在后向计算时每一个网络层的梯度计算依赖于上一层计算的误差项,而不依赖上一层参数的梯度。下层在计算参数的梯度时不会对上层已经计算好的梯度进行修改,因此就可以重新排布计算流程,在下层梯度计算的同时可以将上一层计算后的梯度进行传输,利用计算时间对通讯时间进行覆盖,减少额外的开销。参数的通讯被分解为逐层进行,而不必等到所有网络层后向计算完成时统一进行,具体的结构示意如图2所示。
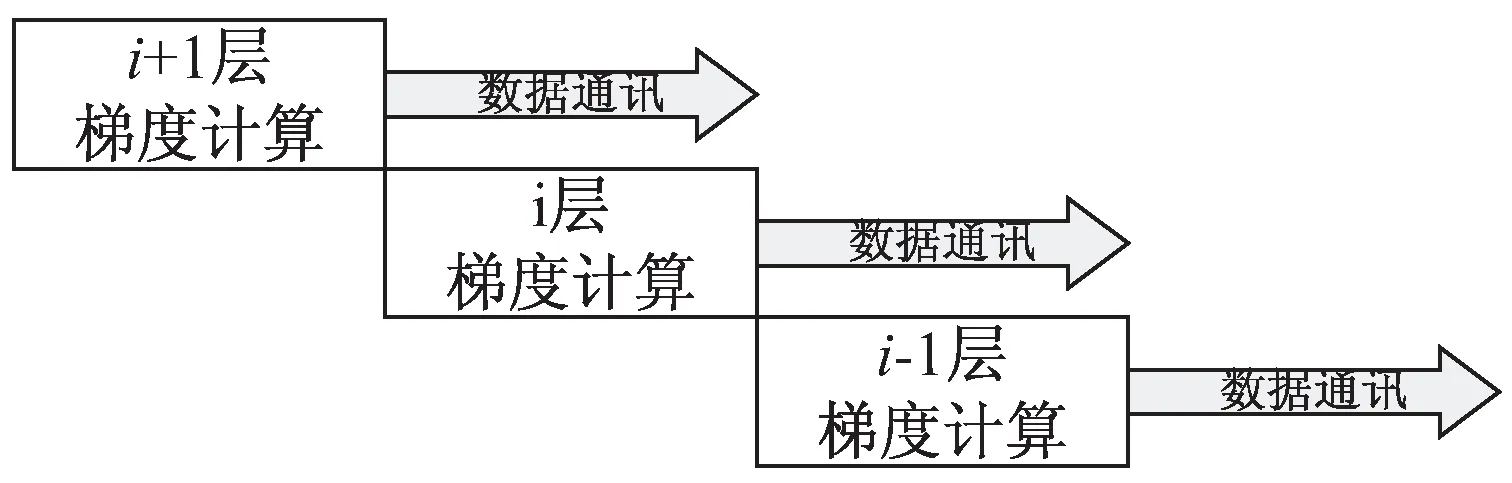
图2 后向计算与数据通讯并行示意
参数服务器对于全局模型的更新也可同样分解为逐层更新,即在第i层进行梯度计算的同时只要接收完所有模型副本发送的第i+1层的梯度即可对第i+1层进行参数更新。通过这种重新排布计算流程的方式可以尽可能地利用计算时间,通过流水并行的形式来减小因数据并行带来的额外开销。
2.2 基于二叉树的归约通讯
在数据并行中,参数服务器需要接收所有模型副本的梯度值并进行求和,计算结果作为一个mini-batch的梯度进行模型参数的更新。随着并行规模的增大,数据通讯所需要的时间不断增加。特别是在多台机器上进行时,虽然梯度计算可以和参数通讯同时进行,但由于数据通讯所需的时间较多导致计算时间无法完全掩盖住通讯所需时间。
参数服务器和模型副本之间实现数据的通讯最简单的方式就是采用点对点通信方式,其通讯过程如图3所示。由于参数服务器存储着全部的模型参数并且所有的模型副本都需要与其进行通讯,在模型副本数目较多时它作为一个单节点存在负载压力相对较大的问题,成为瓶颈制约整个参数通讯的过程。
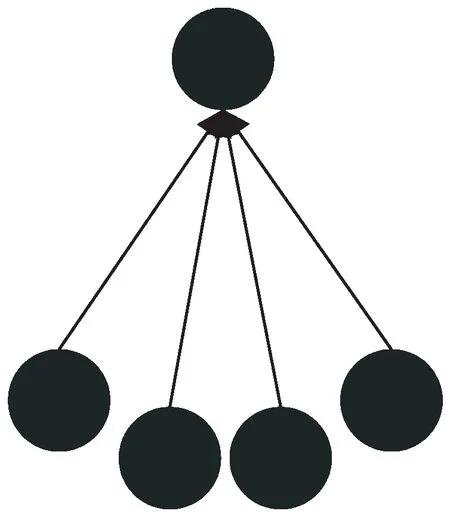
图3 点对点串行通讯示意
针对这个问题,文中设计一种基于二叉树的归约通讯方式,其通讯过程如图4所示。在基于二叉树的归约通讯中,模型副本间首先进行两两间的求和运算,其次将中间计算结果进行累加,最终全局求和的结果汇聚到参数服务器处。整个求和结果的汇聚过程如同一棵二叉树,计算结果从叶子节点不断向根节点汇聚。

图4 归约通讯示意
与传统点对点的串行通讯相比,归约通讯中各个节点相互之间相对独立,因此两两求和的过程可以同时进行,节省通讯所需的时间。假设共有p个模型副本,单次通讯与求和的时间为t,则使用归约通讯时,二叉树的高度为log(p),求全局和的总时间为log(p)t,而串行的通讯求和需要时间为pt。显然当p较大时,归约通讯则可以节省大量的时间。
利用归约的通讯方式,原本参数服务器的求和任务被分解为一个一个小的子任务由各个模型副本共同完成,减少了参数服务器的通讯量以及计算量,解决了参数服务器负载压力相对较大的问题。
2.3 多流异步拷贝的数据预加载
为了减少每次训练数据从硬盘读取所带来的额外时间,可以在每一轮进行迭代计算时将下一次需要用到的数据提前加载,这样利用网络模型计算的时间覆盖数据加载的时间。利用预加载训练数据的方式对数据进行读取,在单次计算完成后,下一次计算所需的数据已经加载到内存空间中,这样就可以节约访问硬盘所需要的时间。
考虑到进行数据的预加载时,可能会因为硬盘存在坏道等原因造成读取数据缓慢导致下一次计算时所需的数据未加载完成,此时读取完下一次计算所需的数据还需要消耗一部分额外的时间。目前训练卷积神经网络模型时大多采用GPU进行计算,而GPU无法直接使用内存中的数据进行数值计算,需要将内存中的数据拷贝到显存空间中才能使用。因此加载到内存中的数据仍需要进行拷贝过程才可以被使用,当计算规模较大时这种时间消耗也成为制约计算并行加速的因素之一。
针对上述的实际问题,文中设计了一种多流异步拷贝的数据预加载优化策略。首先,在预加载单次计算所需数据的基础上进行扩展,变为预加载多次计算所需数据的预加载,即单缓存变为多缓存。利用多个线程同时进行数据的预加载,这样即使某个线程数据记载缓慢也会有其他线程加载的数据作为备份,尽可能避免在下一次计算时等待数据加载完成。其次,利用CUDA中多流的方式进行数据的异步拷贝,在GPU进行计算的同时将预加载在内存中的数据异步拷贝到GPU显存空间。利用CUDA提供基于流的操作,创建一个新的流,在计算的同时异步地将数据拷贝到GPU显存空间。下一次迭代计算开始时,预加载的数据已经存在于GPU的显存空间中,此时只需要进行一个指针的交换将网络模型输入数据块的指针指向已经加载好的数据块即可。经过这样处理后,可以充分利用网络模型前向与后向计算的时间与数据加载的时间进行并行,将数据加载带来的额外开销减到最小。
3 实 验
3.1 实验环境
实验使用的卷积神经网络为文献[2]中的GoogleNet网络模型,共含有22个参数层。使用的数据集为ImageNet图像数据集[14],在该数据集上对GoogleNet网络模型进行分类任务的训练。实验平台采用多台GPU服务器,其中单台服务器内含有2块Intel Xeon E5-2630 2.4 GHz的CPU,内存大小为128 GB,同时每台服务器配备4块显存为12 GB的Nvidia GTX Titian X。实验中的网络环境采用Infiniband交换机,最大速率可以达到56 Gb/s。
文中提出的策略在优化效率的基础上,并没有引入额外的误差,因此优化后的数据并行算法在收敛性方面与原算法保持一致。
3.2 实验结果与分析
网络模型更新时的平均单次迭代计算所消耗的时间作为一个性能指标,用来衡量优化前后的加速效果。在训练GoogleNet网络时使用不同数目的GPU进行实验,数据缓存块数目设置为3,每个GPU作为一个模型副本进行数据并行的训练。初始学习率为0.1,单个GPU每次迭代计算使用的minibatch大小为128。表1给出了在不同GPU数目下,优化前后完成单次迭代计算时间的对比。

表1 优化前后单次迭代计算时间对比 s
由表1可以看出,在不同GPU数目下,优化方法的单次迭代计算时间都相比优化前有所减少。相比GPU数目为1的基准,GPU数目为4时单次迭代计算时间较为接近,大部分的通讯时间以及数据加载时间都被网络的前向与后向计算所掩盖,并行的加速效果最好。随着并行度的增大,使用优化策略后节省的时间不断增大,说明优化策略能够有效提高卷积神经网络的并行训练效率。
随着并行GPU数目的增加,网络完成单次迭代计算时间不断增加,额外的开销也不断增加。单个GPU完成一批次采样训练所需的时间与使用p个GPU所用时间的比值为加速比,它作为一个重要的性能指标衡量整个并行训练的效率。在理想情况下,参数通讯和数据加载都不存在额外开销,加速倍数可以达到线性加速。图5展示了文中提出的优化策略以及文献[15]中的优化策略所取得的加速倍数。

图5 优化后加速比与理想加速比对比
由图5可以看出,在不同GPU数目的实验中,文中的优化策略所取得的加速倍数要高于文献[15]中的方法。在文献[15]中,针对每次训练使用数据量较小的情况利用流水线的方式做出了前向计算与后向计算并行执行的优化,提高了GPU的利用率。同时也采用了预加载数据的方式,利用计算时间掩盖数据加载的时间。此外,还提出在参数通讯时尽可能使用服务器内同一PCI-E总线上的GPU,进行P2P(peer to peer)通信。文中提出的优化策略在参数通讯方式上进行了进一步的优化,通过重排计算流程将参数通讯隐藏在后向计算的背后,同时利用基于二叉树的归约通讯可以大大减少参数服务器每次与模型副本参数通讯所消耗的时间。在数据加载方面,提前将下次计算所需的数据进行加载并异步拷贝到GPU的显存空间中,进一步节省了部分数据拷贝时间,同时多缓存的存在尽可能避免了单缓存因数据读取缓慢而导致的额外等待时间。相比文献[15],文中提出的优化策略在参数通讯以及数据加载优化方面都有进一步的提高,因此会获得更高的加速倍数。在GPU数目为4时,该优化策略加速比达到了3.9,与理论最优值4相比已经非常接近。随着GPU数目的增多,完成参数通讯时间也在增加,并且各GPU在计算时间上略微的差异都会在归约通讯时间产生一定的影响,使得梯度计算时间无法完全覆盖通讯时间,加速比有所下降。总体来说,加速比依然维持在一个较高的水平,当GPU数目为16时,加速比可以达到13.5倍。
4 结束语
针对卷积神经网络模型训练耗费时间较长的问题进行了分析,给出了参数通讯以及数据加载两方面的优化方法,包括梯度计算和参数通讯的并行、基于二叉树的归约通讯以及多流异步拷贝的数据预加载。通过梯度计算和参数通讯并行的方式,将参数通讯时间尽可能减少。同时利用归约的通讯方式缓解参数服务器作为单节点压力较大的问题,并减少通讯所需开销。通过多流异步拷贝的方式预先加载数据并拷贝到GPU的显存空间中,在下一次计算时可以直接使用,减少数据加载带来的额外开销。通过在ImageNet数据集上对GoogleNet卷积神经网络进行分类训练,实验结果表明优化策略能有效减少时间消耗。特别在GPU数目为16的情况下,取得了13.5倍的加速效果,大大提高了卷积神经网络的训练速度,有利于卷积神经网络在实践中得到更好的应用。
猜你喜欢
茶叶通讯(2022年2期)2022-11-15
茶叶通讯(2022年3期)2022-11-11
中国设备工程(2022年19期)2022-10-12
网络安全和信息化(2020年9期)2020-12-31
网络安全和信息化(2020年7期)2020-08-07
网络安全和信息化(2019年8期)2019-08-28
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
电子制作(2018年1期)2018-04-04
北京航空航天大学学报(2017年12期)2017-04-23
名人传记·财富人物(2016年9期)2016-11-10
