
基于多描述子特征编码的人体行为识别
2018-08-21 01:59宋相法
计算机技术与发展 2018年8期
宋相法,姚 旭
(河南大学 计算机与信息工程学院,河南 开封 475004)
0 引 言
人体行为识别在人机交互、视频监控、机器人视觉以及体感游戏等领域有着广泛的应用[1-6]。过去,研究人员主要利用图像和视频研究行为识别问题;如今,研究人员开始利用微软Kinect传感器捕获的三维人体骨架序列研究行为识别问题。
人体是链式结构的,行为可由三维人体骨架关节点表示。例如,文献[7]提出了基于三维人体骨架关节点子集和多核学习的行为识别方法;文献[8]提出了基于运动姿态描述子和KNN算法的三维人体骨架序列行为识别方法;文献[9]提出了基于离群流形的三维人体骨架序列行为识别方法;文献[10]提出了基于联合学习身体部件行为特征和分类器的三维人体骨架序列行为识别方法;文献[11]提出了基于分层姿态特征的三维人体骨架序列行为识别方法;文献[12]提出了基于角度描述子协方差特征的三维人体骨架序列行为识别方法;文献[13]提出了一种基于改进的动态时间规整算法的三维人体骨架序列行为识别方法。
在上述研究的基础上,为提高三维人体骨架序列行为识别精度,文中提出了一种基于多描述子特征编码的行为识别方法。该方法利用集成学习的思想,尽可能利用三维人体骨架序列的多个描述子特征编码方法构造不同的基分类器,通过对这些基分类器的结果进行集成来决定最终识别结果。
文中方法为充分利用三维人体骨架序列不同区分能力的描述子,弥补单一描述子提取时存在信息量不足的缺点,结合运动姿态描述子[8]和角度描述子[14]来构造描述子集;为有效地将描述子组织起来提高识别性能,分别采用向量量化编码[15]、稀疏编码[16]和局部线性约束编码方法[17]对运动姿态描述子和角度描述子进行编码,从而得到六种特征,将这六种特征的识别结果进行集成,得到三维人体骨架序列的最终识别结果。
1 多描述子与特征编码
利用微软Kinect传感器捕获的20个人体骨架关节点位置如图1所示。
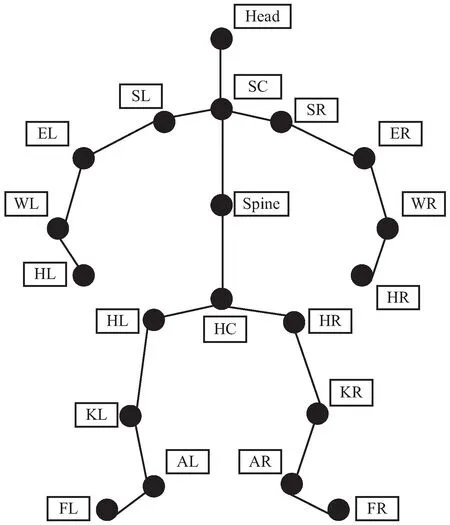
图1 微软体感传感器捕获的人体骨架关节点位置
1.1 描述子提取
文中分别利用能反映数据不同性质的运动姿态描述子和角度描述子,充分发挥每种描述子在识别性能上的优势和互补性,弥补使用单一描述子时造成的信息量不足的缺点,从而提高识别率。
运动姿态描述子[8]由每一帧关节点的位置、运动速度和加速度组成,具体实现详述如下。
在三维人体骨架序列中,每一姿态(帧)可表示为所有关节点坐标pi(t)=(px,py,pz)构成的向量,其中i∈{1,2,…,n},n为关节点总数。所以,对于每一姿态(帧),其关节点位置特征向量表示为:
P=[p1(t),p2(t),…,pn(t)]
(1)
由于惯性、肌肉运动延迟等因素会影响人体行为,因此,可以用一个二次函数来近似表示人体行为[8]。如果把帧表示为人体关节点坐标随时间变化的连续函数,则在以t0时刻为中心的窗口内,其二阶泰勒展开式为:
P(t)≈P(t0)+δP(t0)(t-t0)+
(2)
其中,一阶导数δP(t0)表示t0时刻帧的运动速度;二阶导数δ2P(t0)表示t0时刻帧的运动加速度。
式2表明t0时刻的瞬时帧向量及其一阶导数、二阶导数包含了以t0为中心的时间片段内的帧函数信息。所以,t0时刻的运动姿态描述子可表示为帧向量P(t0)、一阶导数δP(t0)和二阶导数δ2P(t0)的级联。
因为三维人体骨架序列中帧与帧之间存在时间间隔,所以当前帧P(t0)的一阶导数为:
δP(t0)≈P(t1)-P(t-1)
(3)
当前帧P(t0)的二阶导数为:
δ2P(t0)≈P(t2)+P(t-2)-2P(t0)
(4)
其中,P(t-1)表示当前帧的前一帧;P(t1)表示当前帧的后一帧,依次类推。
综上所述,t0时刻的运动姿态描述子表示为:
Pt0=[P(t0),δP(t0),δ2P(t0)]
(5)
角度描述子[14]通过计算微软Kinect传感器的深度摄像头位置(深度摄像头位置坐标ZP=(0,0,0))及三维人体骨架关节点位置之间的角度和对应的角速度得到,各角度名称及对应属性,如表1所示。

表1 角度名称及对应属性
求解角度首先需要选择相应的位置坐标,以左肘关节点角度θ5为例说明计算方法。首先选取左肩关节点、左肘关节点和左腕关节点,然后通过微软Kinect传感器获取到三维坐标数据,分别为左肩SL(SLx,SLy,SLz)、左肘EL(ELx,ELy,ELz)和左腕WL(WLx,WLy,WLz),则关节点方向向量为SL_EL(SLx-ELx,SLy-ELy,SLz-ELz)和EL_WL(ELx-WLx,ELy-WLy,ELz-WLz),最后利用余弦定理计算角度大小,如下所示:
(6)
由于帧与帧之间存在时间间隔,所以当前帧的角速度表示为:
δθ(t0)≈θ(t1)-θ(t-1)
(7)
综上所述,t0时刻的角度描述子表示为:
θt0=[θ1(t0),…,θ35(t0),δθ1(t0),…,δθ35(t0)]
(8)
1.2 特征编码
在特征编码过程中,不同的编码方法会导致不同的性能。文中选取常用的向量量化编码、稀疏编码和局部线性编码。
为表述方便,文中使用X=[x1,x2,…,xm]∈d×m表示从三维人体骨架序列中提取的一个d维的描述子集合,其中xj∈d表示第j(j=1,2,…,m)个描述子。相应地,用B=[b1,b2,…,bl]∈d×l表示视觉字典,其中bk∈d表示第k(k=1,2,…,l)个视觉单词,l表示字典大小。
向量量化编码[15]利用量化思想,使用一个较小的视觉字典对描述子进行表示。向量量化编码只在最近的视觉单词上响应为1,其余视觉单词上响应为0,因此又称为硬量化编码,如下所示:
(9)
其中,视觉字典B使用聚类算法得到,sj表示每个xj在视觉字典B上量化得到的特征表示,S=[s1,s2,…,sm]∈l×m。根据S和特征汇聚方法可以得到一个特征向量F,作为三维人体骨架序列的特征表示。
稀疏编码[16]近年来在计算机视觉领域得到了广泛关注,它在最小二乘重构的基础上加入1-约束,从而实现在一个过完备视觉字典上响应的稀疏性,得到稀疏表示。稀疏编码减少了重构误差,使得重构后的描述更详细,拥有更强的判别力,如下所示:
(10)
其中,sj表示每个xj在视觉字典B上的稀疏表示系数,S=[s1,s2,…,sm]∈l×m,λ>0为正则化参数,‖sj‖1表示系数sj的1-范数。
求解式10的优化问题,就可以得到输入向量集X的稀疏系数矩阵S和字典B,根据S和特征汇聚方法可以得到一个特征向量F作为三维人体骨架序列的特征表示。
局部约束线性编码[17]利用局部性比稀疏性更为本质的思想,通过加入局部线性约束,在一个局部流形上对描述子进行编码重构,如下所示:
(11)
其中,sj表示每个xj在视觉字典B上的稀疏系数,S=[s1,s2,…,sm]∈l×m,λ>0为正则化参数,局部正则化项‖wj⊙sj‖2能够确保相似的特征向量具有相似的编码。⊙表示向量内元素两两相乘,wj∈l且
(12)
其中,dist函数表示特征向量xj和视觉单词bk间的欧氏距离;1表示全部元素为1的向量,约束1Tsj=1保证编码的平移不变性。
为加速编码过程,文献[17]提出一种简单的近似LLC编码方法。该方法首先采用聚类算法学习视觉字典B,然后对任意一个待编码的特征向量xj,选取视觉字典B中距离其最近的t个视觉单词,形成子字典Bj=[b[1],b[2],…,b[t]];最后使用子字典Bj重构特征向量xj,即优化式13得到编码sj∈l,如下所示:
(13)
1.3 文中方法
文中方法的实现框架如图2所示。
对于三维人体骨架序列训练集,首先提取运动姿态描述子和角度描述子,其次对每种描述子通过聚类和字典学习的方法得到不同的视觉字典,将运动姿态描述子和角度描述子分别采用与之对应的视觉字典进行特征编码,并在向量量化编码、稀疏编码和局部约束线性编码的处理下得到6种特征。最后将训练样本集的这6种特征分别采用线性分类器(http://www.csie.ntu.edu.tw/~cjlin/ liblinear/)进行训练,得到6个基分类器。
对于三维人体骨架序列测试样本,首先分别提取运动姿态描述子和角度描述子,每种描述子在与之对应的视觉字典上分别进行向量量化编码、稀疏编码和局部约束线性编码,最终将得到6种不同的特征;然后用训练时得到的6个对应分类器进行识别,得到6种不同的识别结果;最后通过投票策略将6个基分类器的识别结果集成起来,得到最终的识别结果。
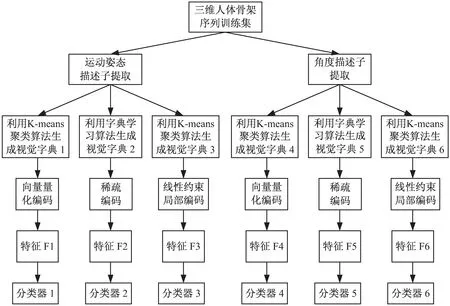
(a) 训练阶段
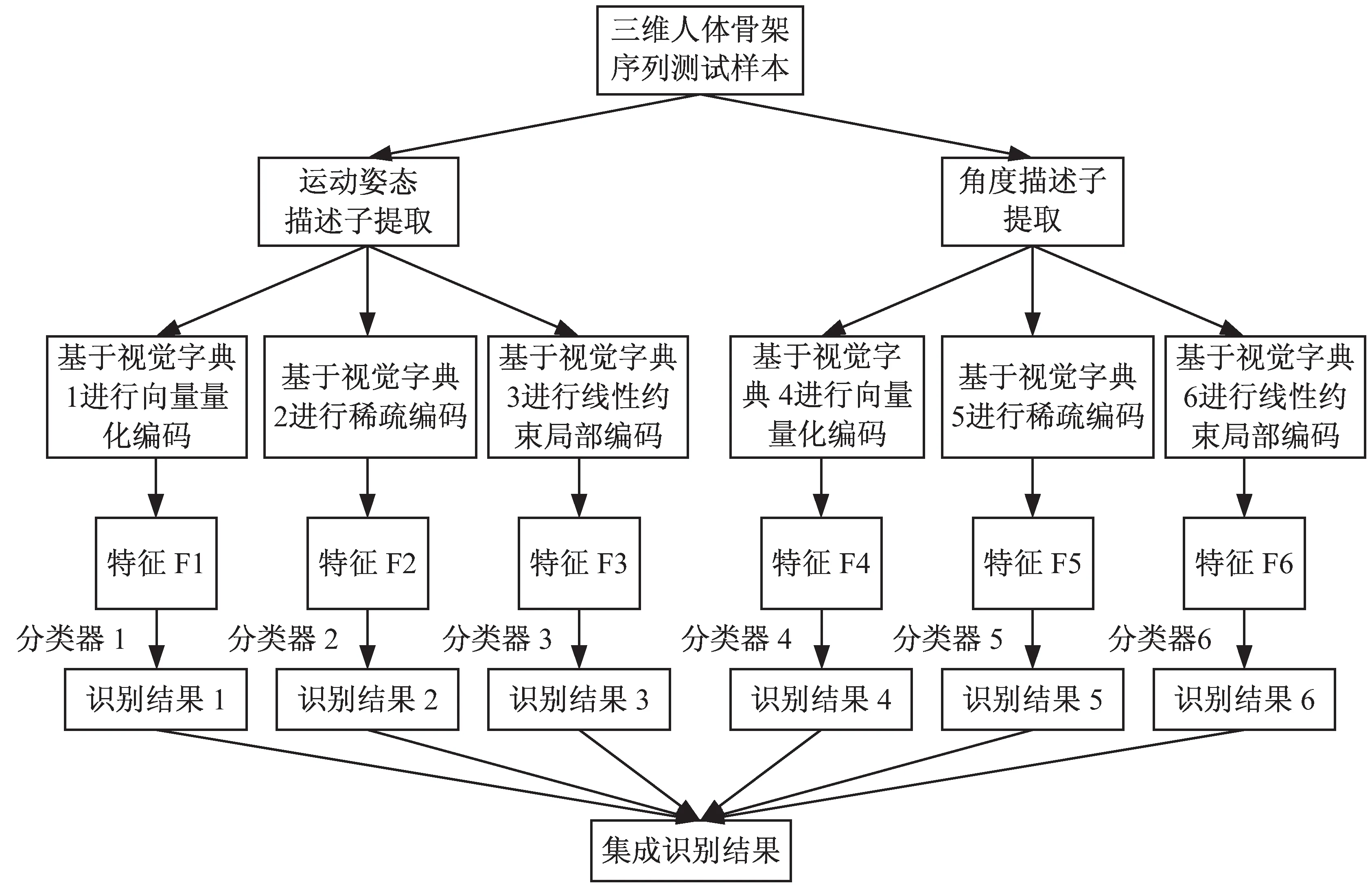
(b) 测试阶段
2 实验结果与分析
为验证文中方法的有效性,在最常用的三维人体骨架序列行为数据集MSR Action3D上进行实验。
MSR Action3D数据集包含20种人体行为,这些人体行为包含手部行为、腿部行为、躯干行为以及复杂行为。由于数据集中存在许多非常相似的行为,彼此之间容易混淆,这使得该数据库识别起来很具有挑战性,每种类型的人体行为由10个表演者重复表演2至3次。
为了进行公平的比较,参照文献[7-12]的设置,将编号为1、3、5、7、9的表演者的骨架序列数据集作为训练数据,编号为2、4、6、8、10的表演者的骨架序列数据集作为测试数据,实验中视觉字典的大小l=4096。
表2给出了文中方法和其他方法[7-12]的识别结果。由表2可知:文中方法的识别率达到了94.9%,相比于其他6种方法,识别精度提高了1.3%~6.7%;相比于Angles Covariance使用基于角度描述子协方差特征方法进行识别,文中方法的识别精度提高了3.8%;相比于Moving Pose使用运动姿态描述子和KNN方法进行识别,文中方法的识别精度提高了3.2%。上述结果说明了该方法能够提高识别率。
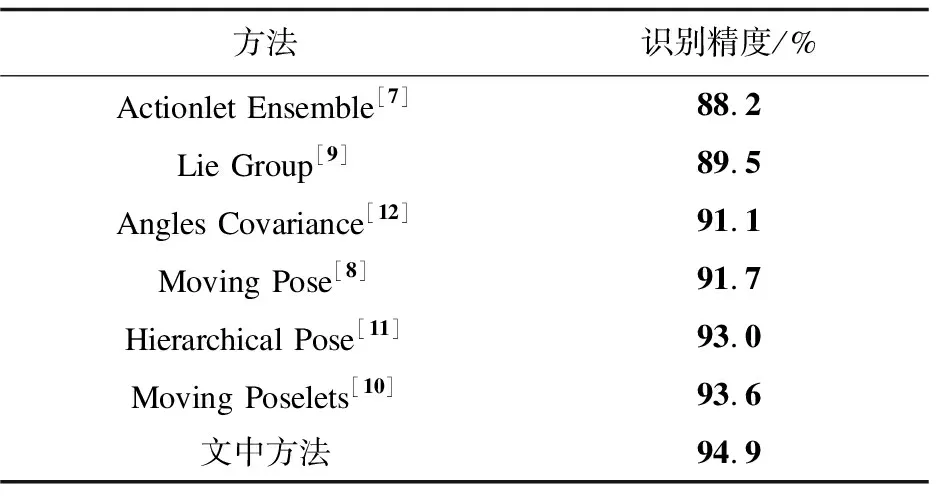
表2 各种方法在MSR Action3D数据库上的实验结果
为考察视觉字典大小对文中方法识别性能的影响,分别采用6种不同大小的视觉字典,即256、512、1024、2048、4096和8192,在MSR Action3D数据集上进行了实验,识别性能对比情况如图3所示。从图3可以看出,视觉字典大小为4096时获得的识别准确率最高,而256时最低,字典大小为1024、2048和8192时获得的识别准确率相近,但都低于4096时获得的识别准确率,因此,文中将视觉字典的大小设置为4096。
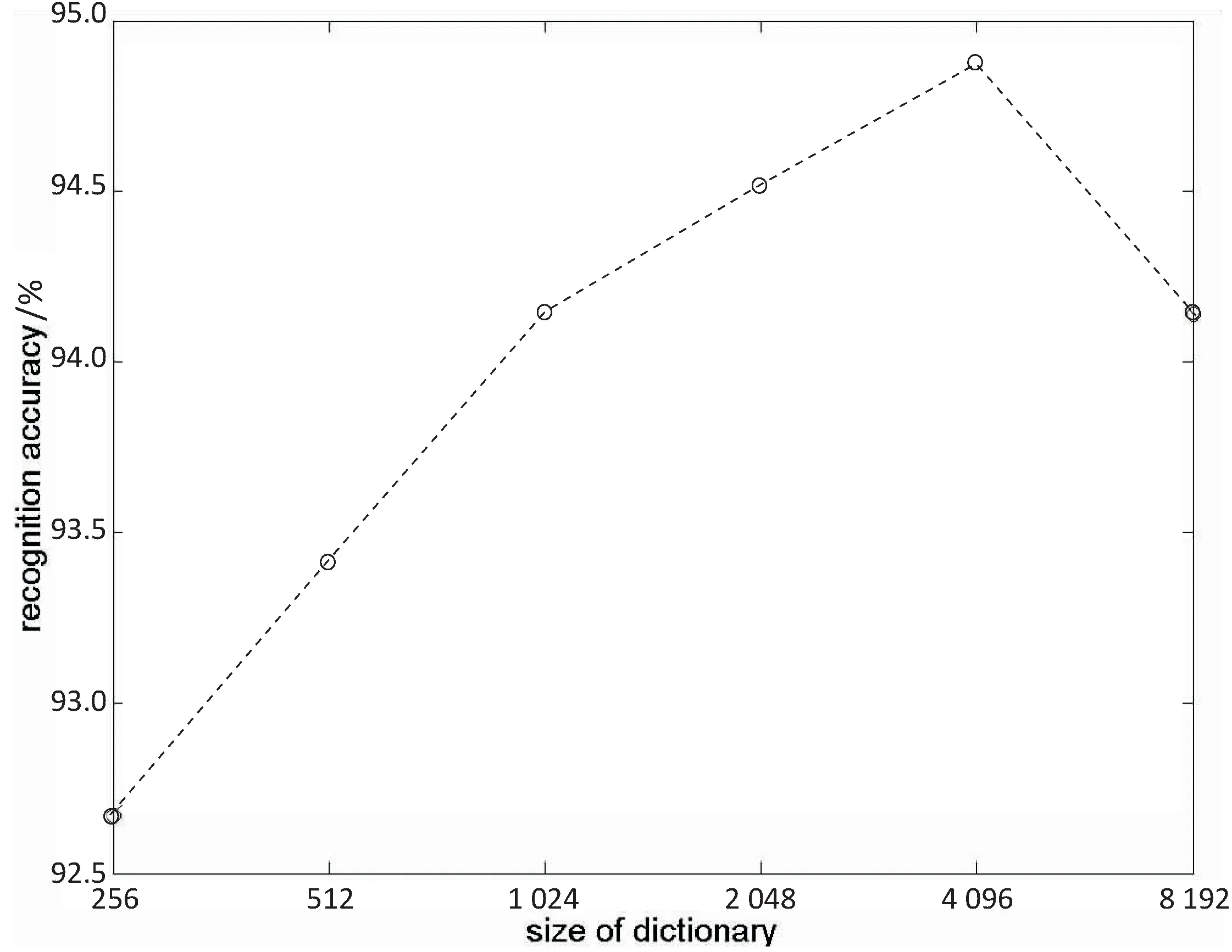
图3 视觉字典大小对文中方法识别性能的影响
为验证文中方法能有效解决使用单一描述子提取的信息量不足,及单一特征编码方法对三维人体骨架序列造成信息丢失等问题,同时为验证该方法具有性能提升的潜力,进一步对描述子和特征编码的各种组合对MSR Action3D数据集的识别率性能的影响进行了实验,内容如下。
组合1:角度描述子和向量量化编码组合识别人体行为。
组合2:角度描述子和稀疏编码组合识别人体的行为。
组合3:角度描述子和局部约束线性编码组合识别人体行为。
组合4:运动姿态特征描述子和向量量化编码组合识别人体行为。
组合5:运动姿态描述子和稀疏编码组合识别人体行为。
组合6:运动姿态描述子和局部约束线性编码组合识别人体行为。
组合7:角度描述子与文中的3种编码方法集成识别人体行为。
组合8:运动姿态描述子与文中的3种编码方法集成识别人体行为。
组合9:运动姿态描述子和角度描述子与文中的3种编码方法集成(即本文方法)识别人体行为。
各种组合的实验结果如表3所示。从中可以看出,单独使用角度描述子和特征编码方法的识别精度比文中方法下降了9.2%~12.1%,单独使用运动姿态描述子和特征编码方法的识别精度比文中方法下降了1.5%~3.7%,角度描述子和文中的3种编码方法集成的识别精度比文中方法下降了6.6%,运动姿态描述子和文中的3种编码方法集成的识别精度比文中方法下降了0.4%。上述结果均说明,文中方法具有识别性能更好的优点。
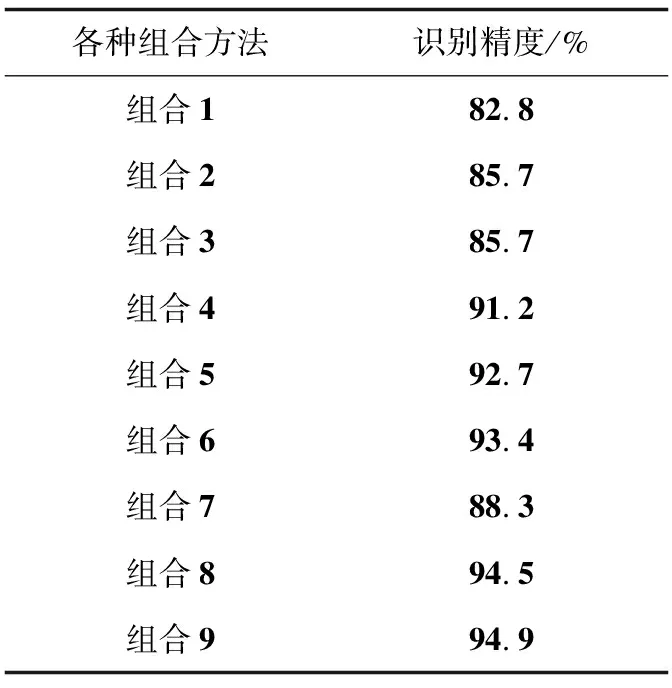
表3 各种组合在MSR Action3D数据库上的实验结果
3 结束语
为解决利用单一描述子和单一特征编码方法进行三维人体骨架序列行为识别导致识别率较低的问题,提出一种多描述子特征编码的三维人体骨架序列行为识别方法,在MSR Action3D数据集上的实验结果表明该方法能够提高识别精度。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
学生天地(2020年3期)2020-08-25
中国新技术新产品(2020年5期)2020-05-06
小学阅读指南·低年级版(2019年11期)2019-07-01
汽车观察(2018年9期)2018-10-23
小天使·一年级语数英综合(2017年11期)2017-12-05
农业工程技术·温室园艺(2017年3期)2017-07-13
汽车零部件(2016年6期)2016-07-18
读者(2016年14期)2016-06-29
诗选刊(2015年4期)2015-10-26
