
VMD样本熵特征提取方法及其在行星变速箱故障诊断中的应用
2018-09-03 03:04杨大为冯辅周赵永东江鹏程
振动与冲击 2018年16期
杨大为, 冯辅周, 赵永东, 江鹏程, 丁 闯
(陆军装甲兵学院 机械工程系,北京 100072)
行星变速箱广泛应用于大型工程机械中,具有传动比大,机构紧凑,传递效率高等优点,其工作环境恶劣,齿轮故障时有发生,不及时进行处理,将严重影响变速箱功能。行星变速箱传动机理复杂,振动传感器测得信号干扰和衰减严重,为典型的非线性非平稳信号,行星轮故障和太阳轮故障难于区分。而现有的很多研究还停留在套用定轴变速箱故障诊断方法,不能针对行星变速箱特点进行有效的分析[1]。某型行星变速箱为多档位行星变速箱,同时存在多个定轴轮系和行星轮系,行星轮系还存在复合框架和两级复合行星排,多数档位需要由2~3个行星排同时工作,而且每个行星排至少有3个行星齿轮,并且结构非常紧凑,箱体为圆柱体并且表面存在大量散热筋,内部有三个离合器和两个制动器共五个操纵件,传感器测点选择十分困难。这些自身原因给该型行星变速箱的故障诊断工作带来了更大的困难。
Dragomiretskiy等[2]提出一种全新的自适应非递归信号处理算法变分模态分解,迭代寻找变分问题最优解以确定每个IMF分量的中心频率和带宽,实现信号频谱的划分及各分量的有效自适应分解。不同于EMD、EEMD和LMD传统递归算法,VMD算法摆脱了传统信号分解的递归筛分剥离模式的约束,有着坚实的数学基础,可以缓解模态混叠和边界效应,还有运算效率高和鲁棒性强的优势[3]。样本熵是一种对近似熵进行改进的计算时间序列复杂度的算法,非常适合处理非线性非平稳信号[4]。与近似熵对比,样本熵提高了统计精度,降低了对时间序列长度的依赖,具有更好的一致性。系统不同的运行状态对应着不同的样本熵值,所以样本熵可用于表征系统的运行状态[5]。
本文针对传统样本熵的不能有效提取行星变速箱故障特征的问题,提出结合VMD与样本熵的特征提取方法,并将其应用于某型行星变速箱。首先依据中心频率观察法选取VMD的分解尺度和依据样本熵最小原则选取二次惩罚因子,再利用VMD将振动信号分解为若干个IMF分量,然后依据敏感度最大原则确定VMD分解各IMF与原信号相关系数阈值,选取大于相关系数阈值的IMF分量重构信号,最后对重构后的信号计算样本熵,依据熵值判断行星变速箱的运行状态。
1 VMD样本熵特征提取方法
1.1 VMD算法原理
VMD是一种区别于EMD、EEMD和LMD的非递归新算法,能够自适应地分解信号,得到k个中心频率为ωk的模态函数uk,其中k为预设尺度数。VMD分解过程的实质就是构造和求解变分问题的过程[6]。
为估计各模态函数uk的带宽,如下步骤构造变分问题:
(1)通过对每个uk进行Hilbert变换,获得其相应的单边频谱;
(2)通过指数混合调制方法,将每个uk的频谱移动到各自估算的中心频率;
(3)依据高斯平滑度和梯度平方准则对信号进行解调估计各uk的带宽。
约束变分问题则可表示为:
(1)
(2)
式中:uk:={u1,u2,…,uk}为各模态函数;ωk:={ω1,ω2,…,ωk}为各模态函数的中心频率。
为求解该约束变分问题,引入拉格朗日乘子λ(t)和二次惩罚因子α,将其变为非约束变分问题,得到增广拉格朗日表达式为:
L({uk},{ωk},λ):
(3)
迭代步骤如下:
(2)迭代次数n=n+1;
(3)fork=1∶K
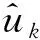
(4)
(5)
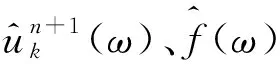
(4) 根据式(6),对于所有ω≥0,进行双重提升,更新λ;
(6)
式中:τ为噪声容限,可设为0以达良好去噪效果。
1.2 样本熵原理
样本熵适用于了量化非线性非平稳信号的复杂度,具有无需自我匹配度、计算快、精度高的优点[7]。样本熵可以衡量行星变速箱振动信号复杂程度,如果振动信号成分单一,周期性越明显,信号噪声干扰越少,信号复杂程度越低,样本熵值越小,反之信号噪声干扰越多,信号复杂程度越高,样本熵值越大。
给定序列X{x(n),n=1,2,…,N},计算样本熵步骤如下:
(1) 对序列X进行相空间重构,获得矩阵Y,m为模式维数。
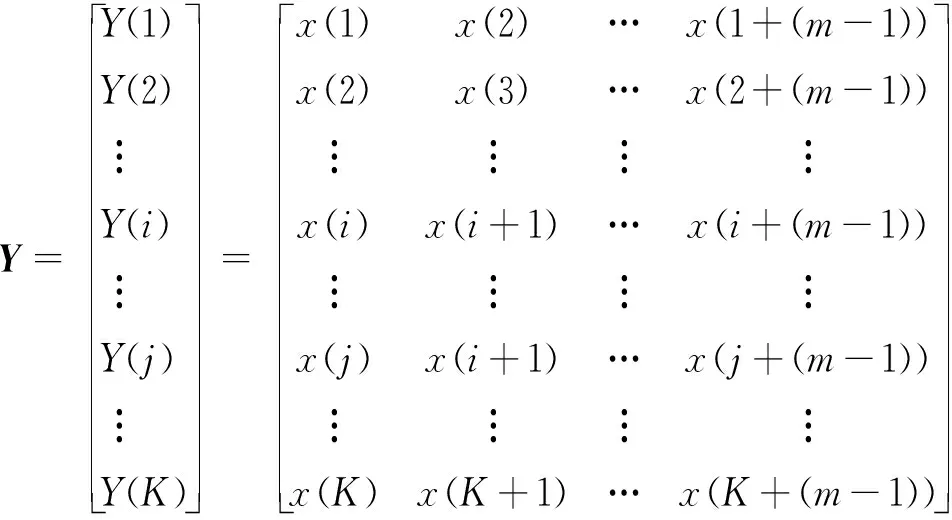
(7)
1≤i,j,K≤N-m+1
(2) 计算向量Y(i)与Y(j)中对应元素最大差值,将其绝对值定义为两者的距离d(i,j)
d(i,j)=maxx(i+k)-x(j+k)
0≤k≤m-1
1≤i,j≤N-m+1,j≠i
(8)
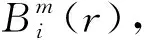
(9)
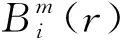
(10)
(4) 维数增加到m+1,获得一组m+1维向量,重复(1)~(3),得到Bm+1(r),
(5) 理论上,样本熵定义为
(11)
当N为有限值时,样本熵的估计值为
(12)
由式(12)可知,模式维数m和相似容限r的取值都会影响最后计算所得样本熵值。根据文献[8]的研究结果和试验对比,应取m=2,r=0.15×Std(Std为信号的标准差)。
1.3 特征提取性能评估
为量化特征参数对行星变速箱状态的分类能力,引入双样本Z值检验法。双样本Z值检验法能有效地对两类样本在统计上的差异进行评估,计算结果Z值可以作为特征参数的分类能力进行的评价指标,在相同情况下,Z值越大,两类样本的分类距离越大,说明特征参数的分类能力越强。
X1{x11,x12,…,x1j}和X2{x21,x22,…,x2j}分别是两类样本,定义特征参量的Z值(敏感度)为
(13)
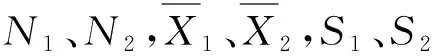
1.4 结合VMD与样本熵的特征提取
结合VMD与样本熵的特征提取具体方法流程如下:
(1) 依据基于信号频谱特性和VMD分解能力的中心频率观察法确定VMD分解尺度,依据重构信号样本熵值最小原则确定VMD二次惩罚因子,使用VMD分解振动信号。
(2) 计算分解所得的各IMF分量与原信号的相关系数,依据敏感度最大原则确定相关系数阈值,选取大于等于阈值的IMF分量进行重构。
(3) 计算重构信号的样本熵值,作为故障特征参数,使用敏感度指标对特征参数分类能力进行评估,验证特征参数的有效性。
2 实例分析
2.1 行星变速箱故障模拟试验介绍
实验对象为某型三轴式离合器换挡三自由度行星变速箱,其主动轴齿轮和中间轴齿轮为定轴齿轮,主轴上有三个行星排,K1排为外啮合双行星排,其余两排为简单行星排。故障模拟试验台的组成如图1(a)所示,试验工况设定输入转速为1 500 r/min,负载为900 N·m,均为试验台所能达到最大转速和最大加载,此时齿轮振动最为剧烈,便于提取故障特征。变速箱挡位设置在Ⅳ档,此时K3太阳轮固定,由内齿圈传入动力,内齿圈带动行星轮转动,从而使行星架转动将动力输出。行星变速箱此时只有K3行星排传动方式为行星传动, K1和K2行星排整体旋转,可以排除其他行星排的干扰。传感器测点安置在右侧输出轴端的箱体内部靠近K3内齿圈的位置,如图1(b),该测点距振源近,受传递路径干扰小,能更好地采集齿轮故障的振动信号。故障设置在Ⅳ档K3行星排的太阳轮Z=30的某轮齿齿面上,利用线切割将其某个齿切除来模拟断齿故障,实物图为图1(c)。
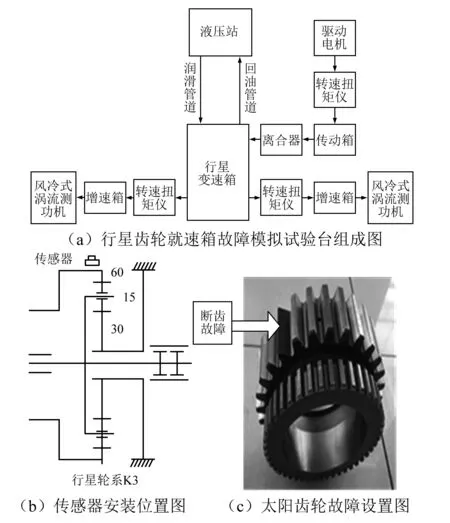
图1 行星变速箱故障模拟试验有关情况Fig.1 Introduction of planetary gearbox fault simulation experiment
行星轮系的运动方式不同于定轴轮系为复合运动,行星轮既自转又公转,采集的数据应该包括相同个行星齿轮回到初始位置的完整周期,这样得到的相同工况的样本信号对应着行星轮系运行的相同物理过程,此时计算的样本熵才具有意义,否则采样所取完整周期数不同,测得信号对应的物理过程不同,故障产生的冲击数也不同,这样将多个振动信号的样本熵做横向比较将失去意义。所以针对行星轮系的特殊情况,需要考虑行星齿轮回到初始位置周期的问题。

表1 K3齿轮参数
依据齿轮相关参数和理论计算可得K3行星排参数如表1,由表知,行星轮自转频率为行星架转频的2倍,即行星架每转一圈,行星轮就要自转两圈,行星轮与太阳轮啮合两个周期30个齿,刚好是太阳轮齿数的一倍,太阳轮啮合一个周期,行星轮刚好旋转到初始位置。即行星架转一圈,行星轮刚好旋转到初始位置,一个完整周期历时t=1/17.65≈0.056 6 s。为保证采集信号的可用性,本次试验采样频率20 kHz,每次采样取30个周期,间隔30个周期,即每次采样1.7 s,间隔1.7 s,连续采集52组数据用于处理。
实测正常和太阳轮断齿信号时域波形如图2所示,从时域看,故障信号冲击脉冲不凸显,并且没有明显的周期;从频域看,实测信号干扰较多,频带成分复杂,低频段定轴齿轮啮合频率及其边频带和噪声干扰严重,找不到太阳轮断齿的故障特征频率,仅从时域和频域都不能区分正常和故障信号。
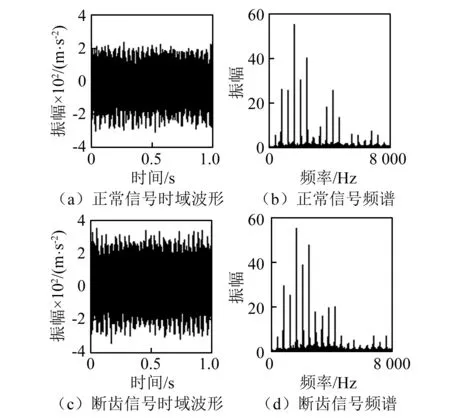
图2 实测信号时域及频谱图Fig.2 Measured signals in time domain and corresponding spectrum
2.2 VMD分解重构参数优化选取
使用VMD时需要选定预设尺度数K和二次惩罚因子α,预设尺度数K和二次惩罚因子α都会对分解结果产生影响,由于实测信号复杂多变,使用VMD算法的难点和关键在于如何选定合适的Κ和α值。
目前,使用VMD时一般选择默认的Κ和α值,不能保证VMD参数选取最优,极大限制了VMD的性能。文献[11]采取粒子群算法对VMD参数进行优化选取,取得了比较好的效果,但该优化过程繁琐复杂,粒子群寻优需要很长的时间,不利于在线监测以及实时诊断,且所处理信号分解后不涉及信号重构,没有考虑相关系数阈值对信号重构的影响。因此,本文提出一种简单快捷且考虑相关系数阈值的方法对VMD算法参数进行优化选取。
2.2.1 基于中心频率观察法的分解尺度选取
由于VMD分解得到的IMF分量的中心频率是由低频至高频分布的,如预设尺度数K值从小到大取值,则最后一层IMF分量的中心频率首次达到最大值时,将不会出现分解不足的问题,若随着K值增大,最大中心频率仍然保持相对稳定,则可认为此时K的取值为最佳取值[12]。
当K取不同值时,取一组太阳轮断齿故障信号进行VMD分解,得到IMF分量的中心频率如表2所示,由表2得,当K=5时,IMF1取到中心频率最小值950 Hz并当K≥5时,IMF分量的中心频率最小值趋于稳定。当K=8时,IMF8取到中心频率最大值8 028 Hz并当K≥8时中心频率最大值趋于稳定。当时,IMF1中心频率对应行星变速箱主动轴定轴齿轮的啮合频率,是频谱低频段的主要特征频率, IMF8中心频率对应着信号频谱最后一个明显峰值,符合信号实际情况。当K≥8时中心频率最大值和最小值都保持相对稳定,不再出现新的中心频率最大值或者最小值,从而保证VMD分解不会遗漏更高或者更低的中心频率,则认为此时VMD分解能力最佳,故本次取预设尺度K=8。
2.2.2 基于样本熵值最小原则的二次惩罚因子选取
VMD算法中二次惩罚因子α越小,分解得到的各IMF分量的带宽越大,α越大则带宽越小[12]。使用VMD算法处理信号后,如果信号包含的故障信息较少,与故障相关的周期性冲击脉冲不凸显,信号干扰和噪声较强,样本熵值较大。如果包含的故障信息较多,出现与故障相关的周期性冲击脉冲,信号的干扰和噪声较弱,呈现出较强的规律性,样本熵值较小,故选取最优的二次惩罚因子α应使重构信号的样本熵值最小。在使用VMD算法时,采用不同的惩罚因子对信号进行VMD重构后求样本熵将得到不同的结果。本文在预设尺度K=8的条件下采用不同的惩罚因子处理试验52组
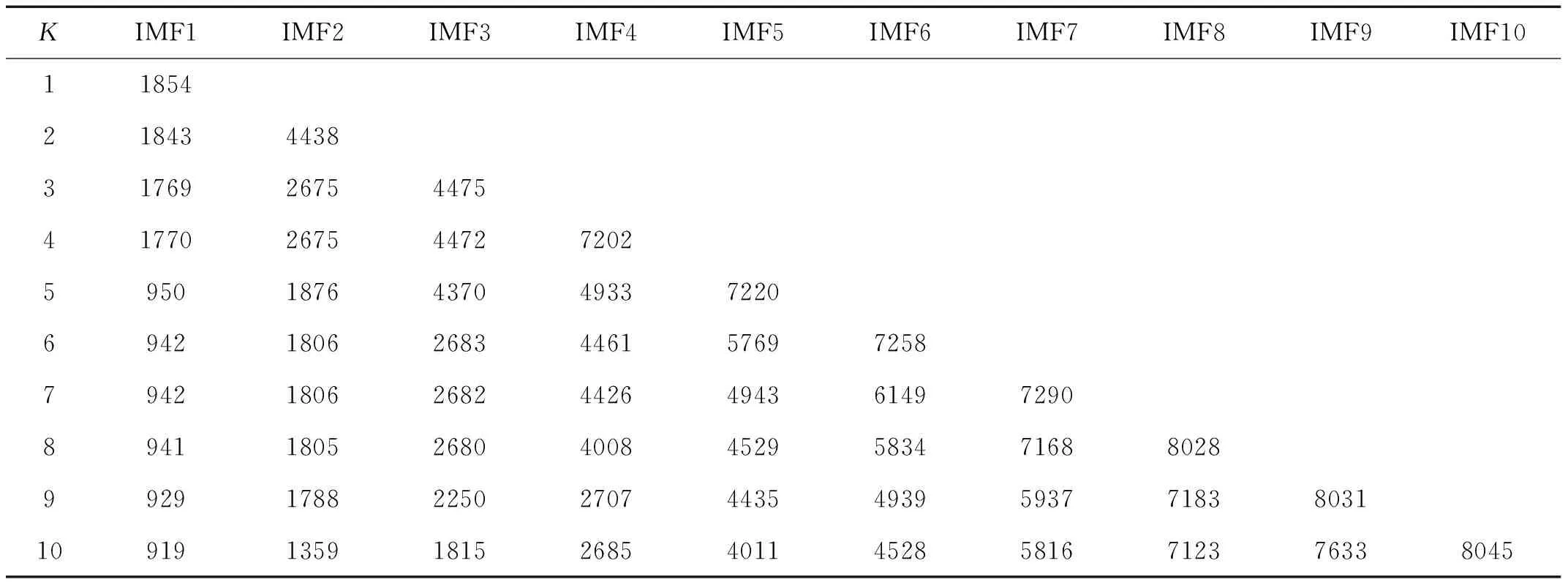
表2 取不同K值时VMD分解后各IMF分量中心频率
实验数据,所得样本熵均值如图3,可知当α=2 500时,重构信号的稀疏性最强,样本熵值到达最小值,故本文取二次惩罚因子α=2 500。
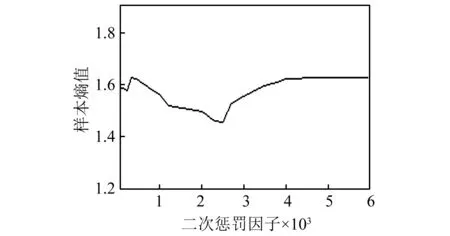
图3 二次惩罚因子和VMD重构信号样本熵值关系图Fig.3 Relationship of secondary penalty factor and sampleentropy of VMD reconstructed signal
2.2.3 基于敏感度最大原则的相关系数阈值选取
为能更好地提取特征,需要选取分解结果中有效的IMF进行重构。相关系数可以衡量各IMF分量和原信号的相关性,各IMF分量与原信号的相关系数越小者,表明它与原信号的相关性越低,包含原信号的可用信息越少,可能属于噪声干扰成分,反之,表明该IMF中包含原信号的可用信息越多[13]。相关系数阈值过小不能有效去除噪声干扰或对故障不敏感的IMF分量,阈值过大可能会遗漏对故障较为敏感但比较微弱的IMF分量,因此相关系数阈值选取对信号重构结果有很大影响。根据与原信号的相关系数大于等于给定阈值的原则,筛选出有用的IMF分量,从而进行信号重构,采用区分故障的敏感度指标最大的原则确定相关系数阈值,使重构信号的样本熵对故障状态最为敏感。
图4为断齿信号VMD分解所得8个IMF分量,表3为各IMF分量与原信号的相关系数。本文在分解层数K=8和惩罚因子α=2 500的条件下,采取不同的相关系数阈值对VMD处理后的52组信号进行重构,然后对重构信号求样本熵,并用敏感度指标进行评估。由表4可知,在相关系数阈值取r=0.3时,敏感度指标最大,说明此时VMD样本熵区分断齿故障状态与正常状态的能力最强。因此,取相关系数阈值r=0.3。
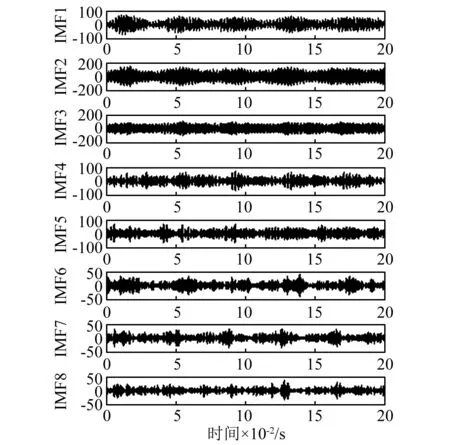
图4 VMD分解结果Fig.4 The result of VMD
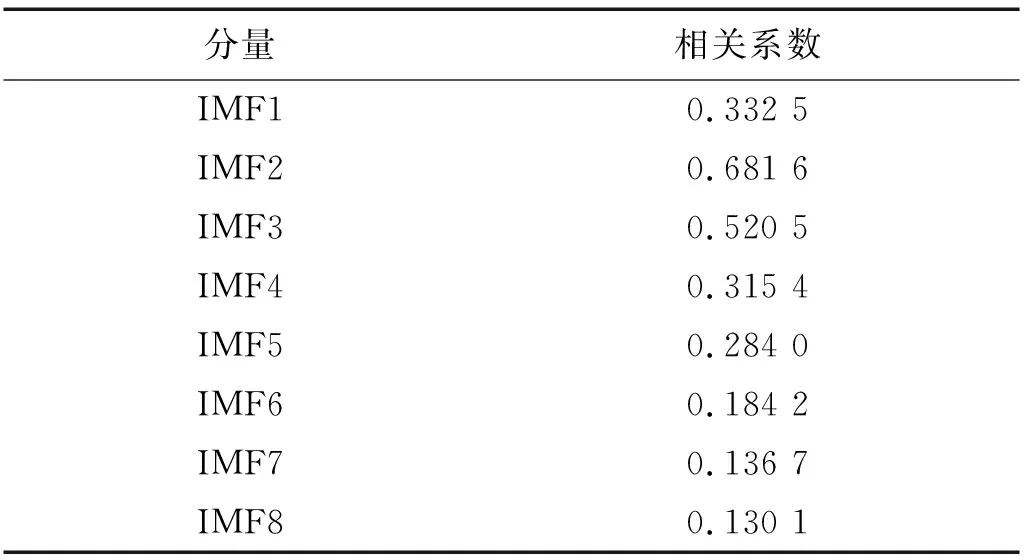
分量相关系数IMF10.332 5IMF20.681 6IMF30.520 5IMF40.315 4IMF50.284 0IMF60.184 2IMF70.136 7IMF80.130 1
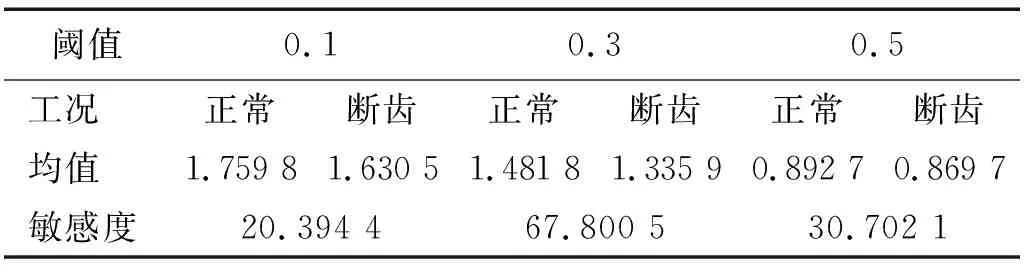
表4 不同相关系数阈值重构样本熵
依据确定的VMD参数对太阳轮断齿故障信号进行重构,得重构前后信号局部频谱如图5。由图5可知,重构后的信号频谱更加清晰,噪声干扰得到有效抑制,行星轮系啮合频率(529 Hz)及其二倍频(1 058 Hz)、三倍频(1 587 Hz)更加凸显,证明了VMD重构方法的有效性。但其频谱主要频率成分仍为变速箱定轴部分特征频率,行星轮系故障特征频率仍然较为微弱,需要结合样本熵进一步分析处理。
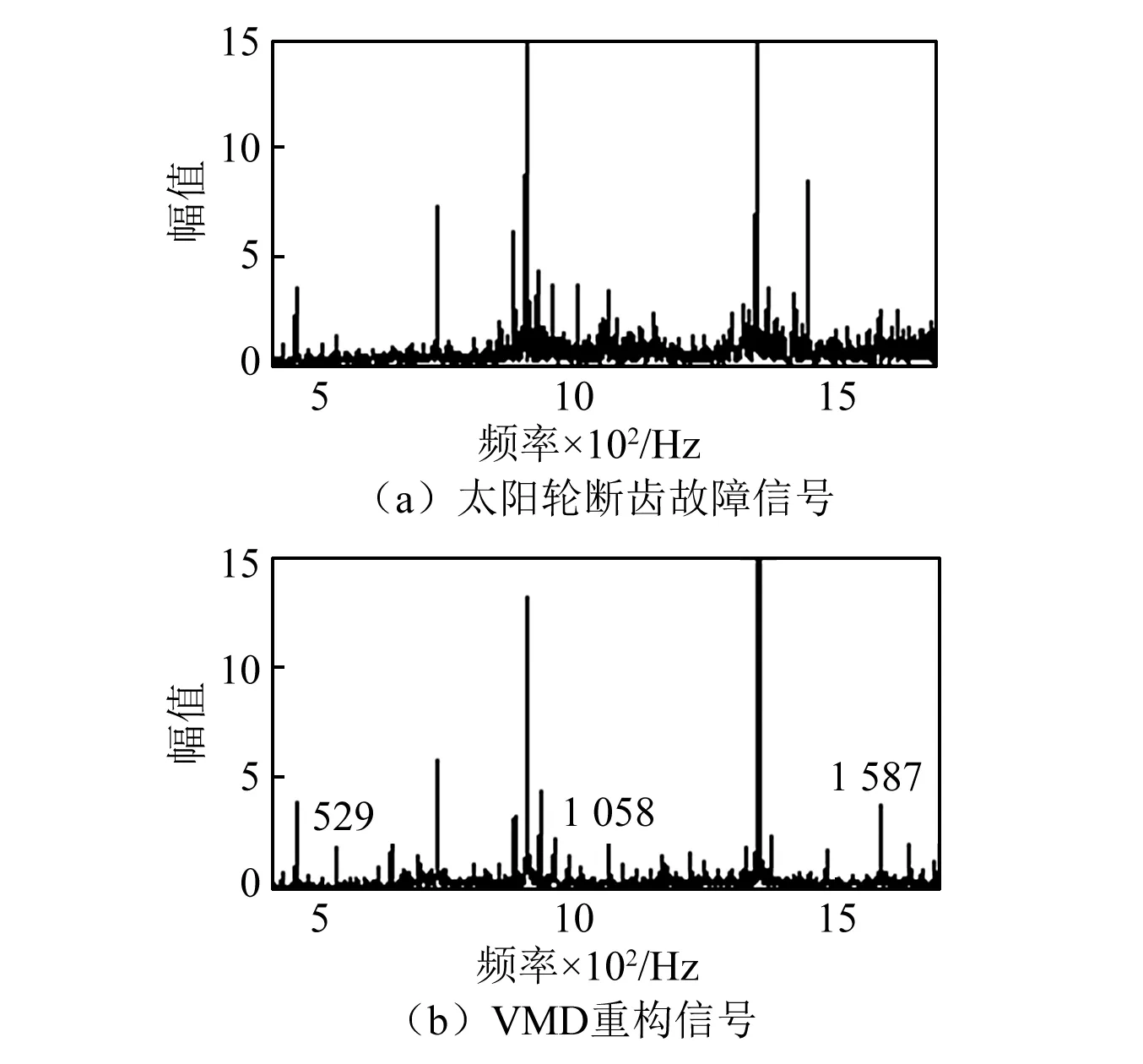
图5 信号频谱图Fig.5 Signals frequency spectrum
2.3 结果分析
使用VMD算法和EEMD算法[14-17]对52组实测信号进行重构,然后分别计算齿轮正常状态及齿轮断齿故障状态的样本熵值(直接样本熵)、EEMD重构后的样本熵值(EEMD样本熵)、VMD重构后的样本熵值(VMD样本熵)。图6和表5给出了输入转速为1 500 r/min和负载为900 N·m时齿轮正常状态和太阳齿轮断齿状态的样本熵计算结果。
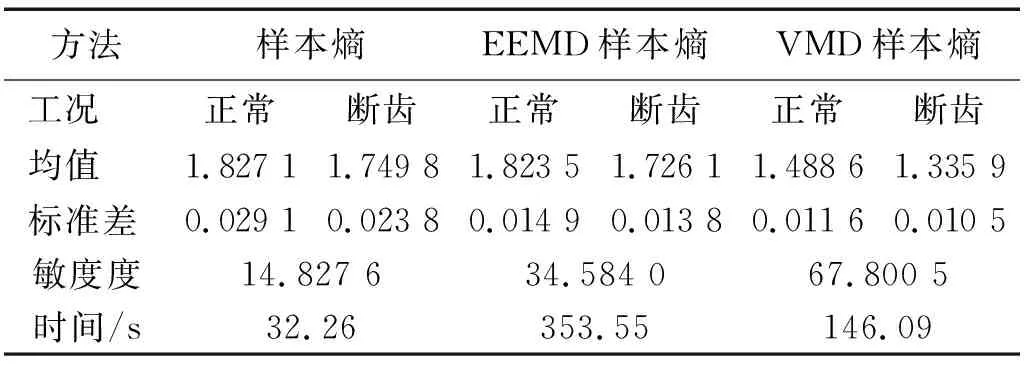
表5 实测信号样本熵对比
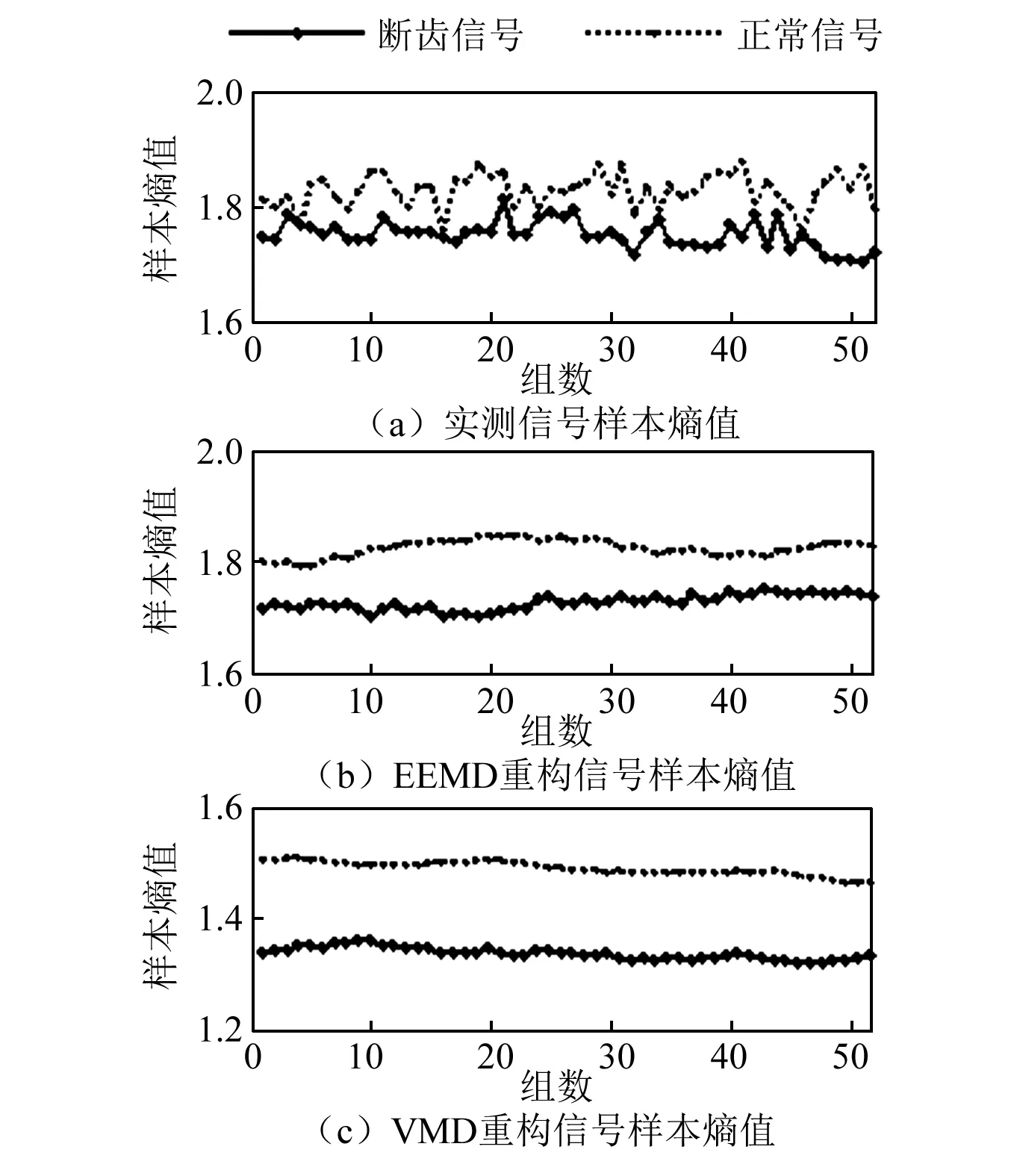
图6 不同方法样本熵对比图Fig.6 Comparison of sample entropy with different methods
由图6和表5知,断齿故障状态的样本熵值小于正常状态的样本熵值。因为在行星变速箱正常工作状态时,齿轮振动幅度较小,振动信号相对复杂,并无明显规律性,故其样本熵值较大;当发生齿轮断齿故障时,振动信号中会产生与齿轮故障相关的有规律的冲击脉冲,导致信号复杂程度降低,样本熵减小,证明样本熵能衡量振动信号的复杂程度,描述行星变速箱齿轮运行状态。
行星变速箱振动信号成分复杂,信号的直接样本熵通常无法准确区分故障,故样本熵不能直接作为判断故障的依据。而VMD样本熵和EEMD样本熵值较直接样本熵值小,表明VMD样本熵和EEMD样本熵在保留不同状态信号特征差异的基础上有效降低了信号中的随机成分,同时VMD样本熵的均值和标准差更小,说明了VMD样本熵较EEMD样本熵具有更好的稳定性,在更好地去除背景噪声的同时凸显了冲击成分。
通过敏感度指标评估三种方法的分类能力,结果表明,相同试验工况下VMD样本熵敏感度最大,说明VMD样本熵对断齿故障状态和正常状态的分类能力最强,对齿轮故障状态最敏感,可以作为评判齿轮状态的依据。
为检验VMD算法在低采样频率的优势,对实测数据进行重采样,分别使用VMD算法和EEMD算法处理采样频率为625、1 250、2 500、5 000、10 000、20 000 Hz的信号,结果如图7所示。从对相同信号的处理结果可以看出,在各个采样频率下,VMD算法得到的输出信号信噪比和敏感度都明显高于EEMD算法,且VMD算法处理信号的时间明显少于EEMD算法,这就意味着VMD算法可在采样频率较低的情况下仍旧能够获得高信噪比的输出信号,结合样本熵算法能更好地区分正常和断齿故障,降低对硬件的要求,减少运算量。
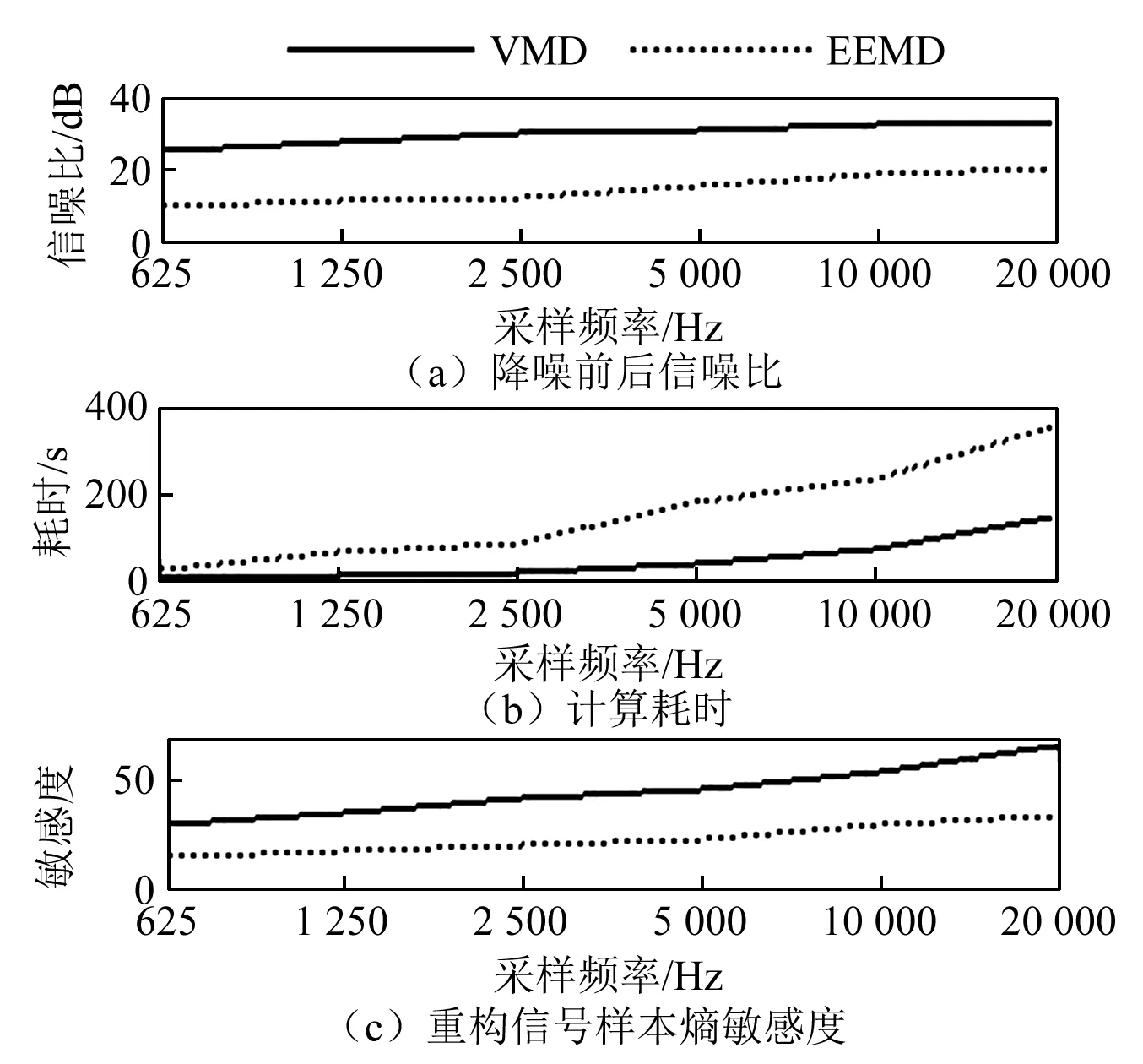
图7 不同采样频率下两种重构方法对比图Fig.7 Comparison of results from two reconstruction methodsusing different sampling frequencies
为检验VMD样本熵方法的适用性,使用同样方法设置K3行星排Z15行星齿轮断齿故障,选取处理行星齿轮故障信号的VMD参数,分别计算信号的VMD样本熵和EEMD样本熵,如图8所示。由图8可知,VMD样本熵对行星齿轮断齿故障有较好的区分能力,而EEMD样本熵方法则不能有效区分,存在一定的局限性,证明了VMD算法处理非线性非平稳复杂信号相对于EEMD算法的优势。由于K3行星排有6个行星轮,每个行星轮断齿产生的冲击相对于太阳轮断齿产生的冲击弱,加上行星轮复合运动的影响,使信号复杂程度增加,样本熵值增大,且样本熵的稳定性相对降低。
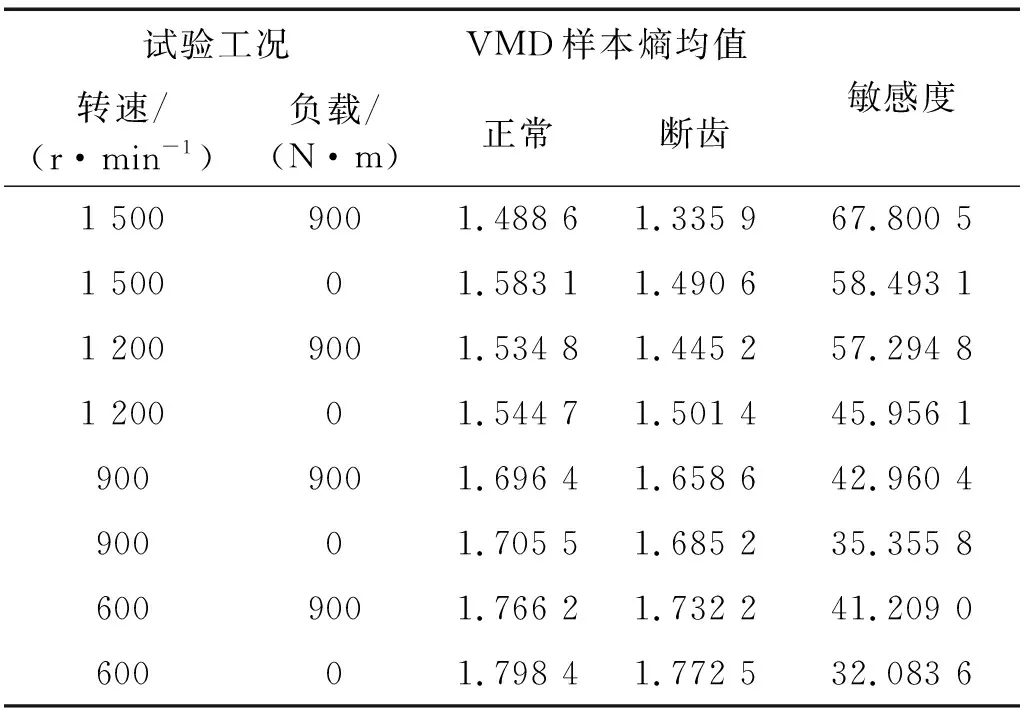
表6 不同工况VMD样本熵
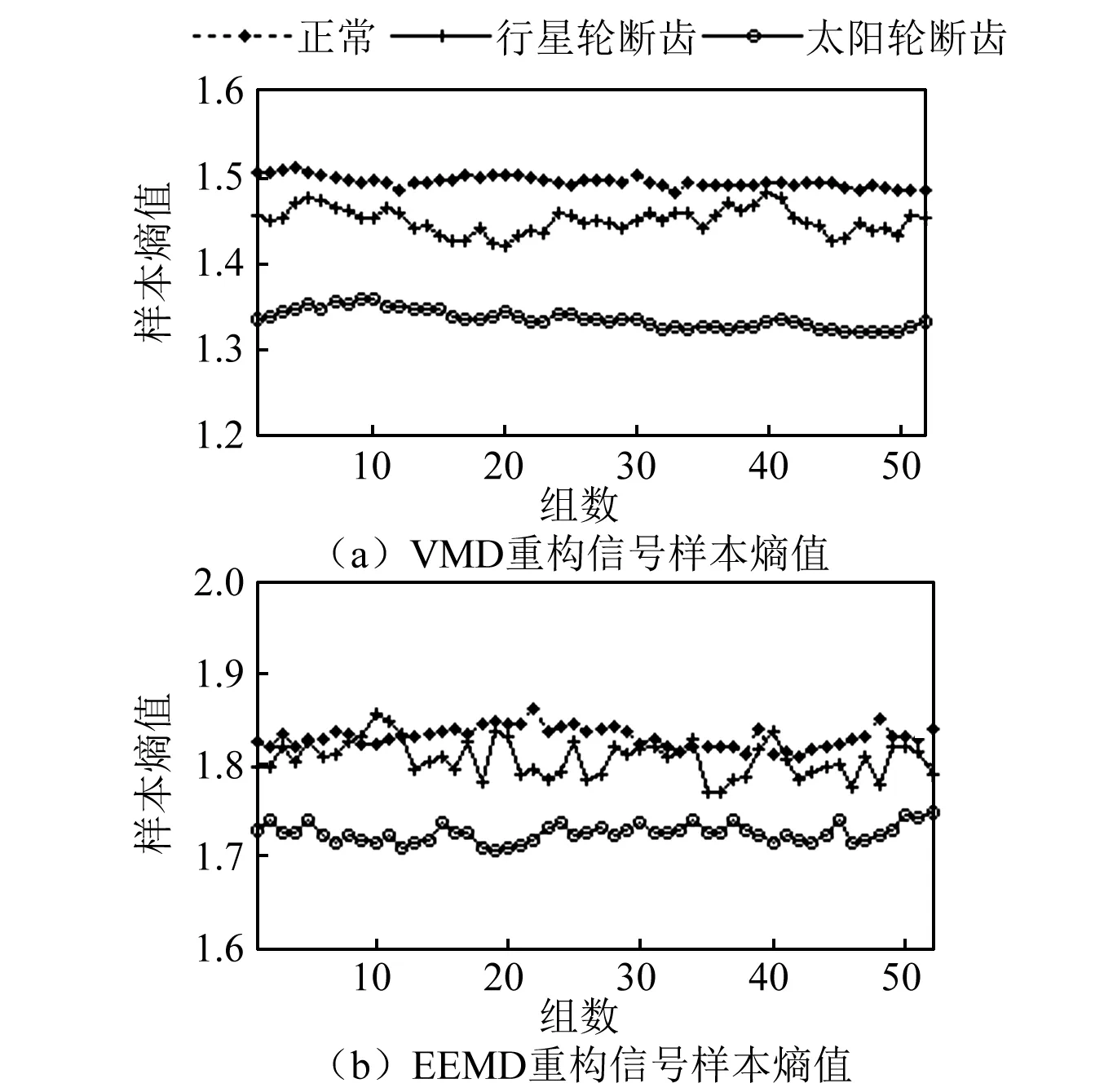
图8 不同状态信号的VMD和EEMD样本熵图Fig.8 VMD and EEMD sample entropy of different condition signals
使用本文方法处理不同工况下的太阳齿轮断齿信号,结果如表6。由表6可知,在行星变速箱不同转速、不同负载的工况下,太阳齿轮断齿信号的VMD样本熵均小于正常信号的VMD样本熵,具有较高的敏感度。并且转速越高,负载越大,齿轮断齿产生的冲击越明显,采集到的信号越规律,样本熵值越小,与正常信号的区别越大,VMD样本熵区分齿轮状态的敏感度越高,进一步证明了本文方法可以有效应用于行星变速箱故障特征提取。
3 结 论
本文采用VMD样本熵方法提取了行星变速箱齿轮故障特征,通过行星变速箱齿轮故障模拟实验和数据处理结果表明:
(1)本文采用的VMD参数选取方法快捷有效,可以应用于VMD分解参数选取,结合VMD和样本熵的特征提取方法相对于EEMD样本熵具有敏感度高,计算耗时少,信噪比高,不依赖采样频率的优势,值得深入研究。
(2)本文考虑了行星齿轮的周期问题,保证了数据的可用性,并在不同试验工况下均可获得良好的效果,证明了方法的有效性,并初步区分了太阳轮断齿和行星轮断齿故障,可以应用于行星变速箱运行状态的特征提取,为下一步的故障识别打下基础。
猜你喜欢
热处理技术与装备(2020年4期)2020-09-03
百科探秘·航空航天(2020年6期)2020-07-09
中学生数理化·八年级物理人教版(2019年5期)2019-06-25
读者(2018年20期)2018-09-27
车迷(2017年12期)2018-01-18
北京汽车(2016年6期)2017-01-06
山东工业技术(2016年15期)2016-12-01
少儿科学周刊·儿童版(2016年1期)2016-03-14
人间(2015年8期)2016-01-09
汽车实用技术(2015年8期)2015-12-26
