
基于数据挖掘的关联规则研究
2018-10-16 02:31倪东
太原学院学报(自然科学版) 2018年3期
倪 东
(合肥职业技术学院,安徽 巢湖 238000)
引言
当前人类社会处于一个信息爆炸时代,已经步入了超大数据时代,因此如何对海量数据进行处理,并从中找到隐含的有效知识和联系,仅仅依靠当前的检索查询和统计学方法已无法满足需求了。因此,如何将海量的数据高效转换为有用的信息,并从中发现数据之间的关联信息就尤为迫切。
近些年随着挖掘技术的进一步发展,它能将隐含的、未知的有价值数据从海量的数据中挖掘出来。数据挖掘关联规则对数据中的关联性进行分析,找出数据之间的潜在关联,并在实际应用中起到指导和决策作用。
1 数据挖掘技术
数据挖掘技术[1-3]的主要目标是从数据库中挖掘出潜在的、用户感兴趣的、有意义的数据,并通过对这些数据进行分析,将其转换为可供处理的数据格式,并通过经典的算法如Apriori算法[4-5]提取出用户需求的数据,对用户工作进行预测和决策。当前数据挖掘技术已广泛应用在多个交叉学科领域中,例如人工智能、神经网络、数理统计等。
数据挖掘的对象一般为各类数据库,如关系数据库、对象数据库。数据挖掘技术通常是随着各类学科领域技术的发展而快速进步的,接下来对其应用的范围进行分类如表1所示。
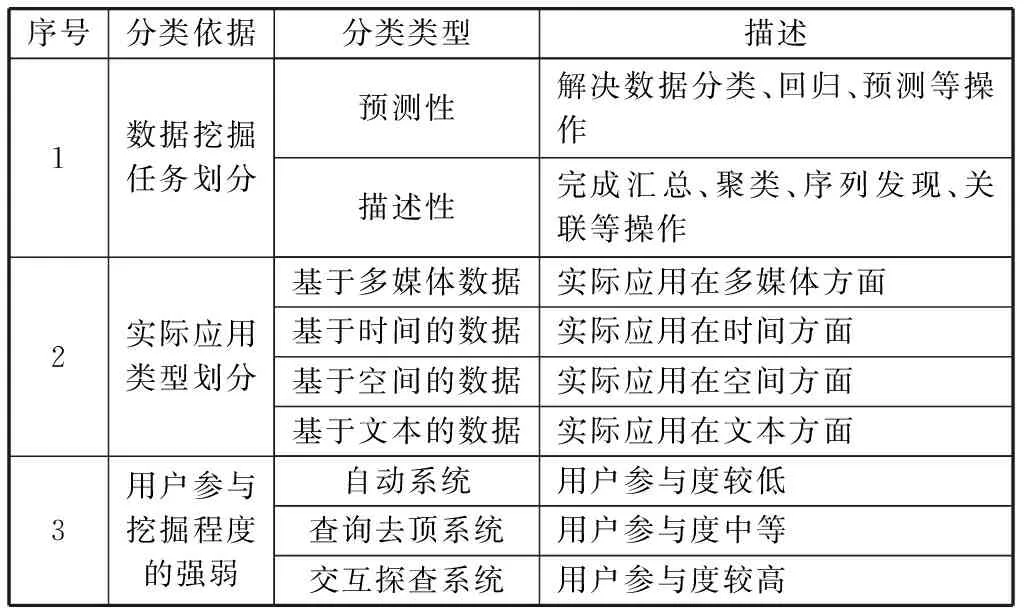
表1 数据挖掘应用范围分类
数据挖掘过程是一个较为复杂的价值数据的发现过程,一般分为五个阶段如图1所示。
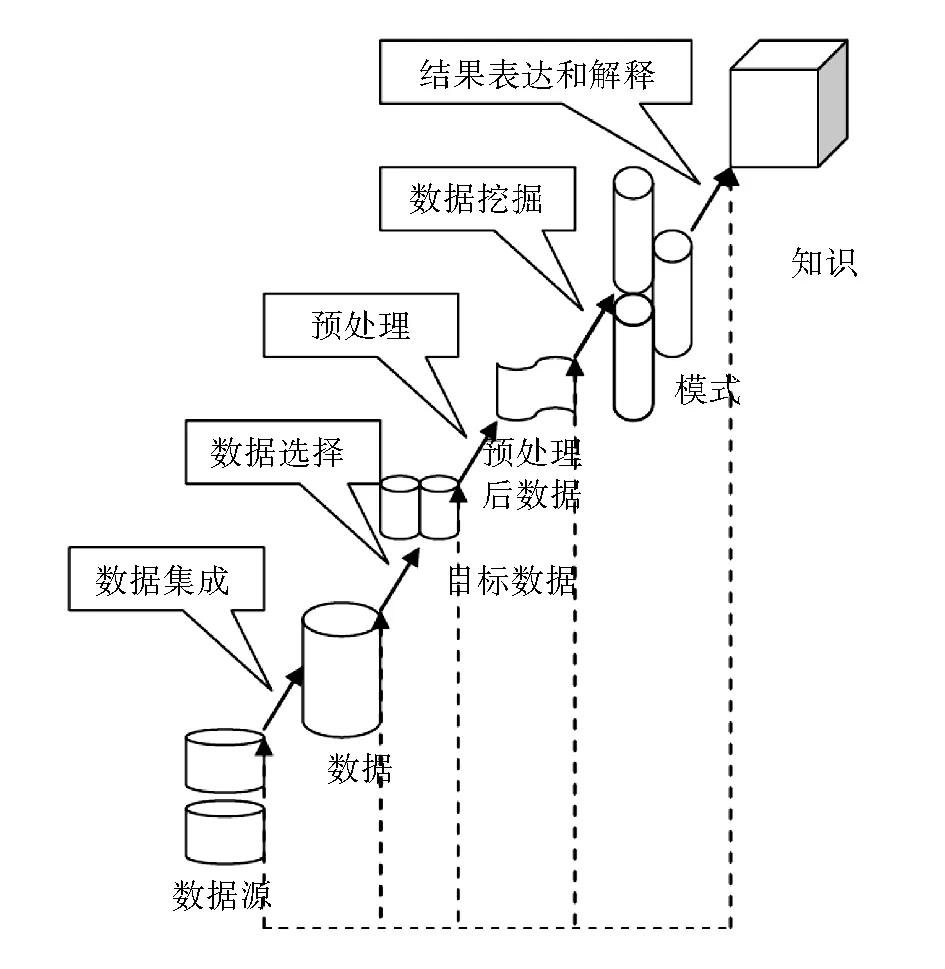
图1 数据挖掘过程
数据集成:确定数据源的存储状态,若数据是分散存储的,则需要提前选定好数据源,并根据数据确定好数据抽取原则,明确数据的结构和信息;接下来需要设计好数据的组织结构、数据的交换机制、安装机制;最后则正确抽取每个数据源中的需求信息,并以源数据的形式保存用户动作。
数据选择:通过在源数据中设置某些限制条件或约束条件,应用某些算法来选择有价值的数据,删除无价值的数据,进而获取得到和挖掘任务紧密联系的数据集,从而提高挖掘的效率。
数据预处理:在数据预处理之前,要检查数据的一致性。若源数据中存在不一致、不完整、含杂质的数据,则必须对源数据进行清洗、删除、修补,通常不完整的数据完善可通过全局值属性为补充未知的数据;采用平均值法补充空缺项;利用回归或线性工具预测可能值进行填充;定义数据源的变换规则,从而使得在数据挖掘前保持数据形式的统一。
数据挖掘算法:数据挖掘的核心是挖掘算法的选择和应用,不同的挖掘算法在不同领域中的优势是不一样的,具体的数据挖掘方法如表2所示[6-8]。

表2 数据挖掘算法
2 关联规则的数据挖掘技术
关联规则是近年来在数据挖掘技术领域中应用较为广泛的技术,它通过定义一种规则来描述数据的特征[9-10]。本文中的关联规则挖掘技术的基本概念如表3所示。
关联规则表示数据之间的相互关系,例事务X和Y,其中XI和XY,且X∩Y=φ,则称X为先决条件,Y为结果,此关联规则表示为事务X和事务Y不可能同时出现的,相互排斥。根据应用场景范围不同,关联规则可分类为:

表3 关联规则挖掘基本概念
1)基于源数据中变量的类型——布尔型和数值型
布尔型变量的值一般都是离散的,反应了这些变量之间的关联,例如年龄=“18”=>职业=“学生”。数值型变量一般为多维或多层关联项结合,通常需要对数值型进行动态处理。再如工作年限=“5”=>收入=7000。
2)基于源数据中的抽象层次——单层、多层关联规则
单层关联规则中源数据中的数据都是单一的,并不对其进行扩展分析;多层关联则对源数据中的多个方面都进行扩展分析,必须充分考虑各方面的情况。例如Levono电脑=>HP打印机是一个单层关联规则;电脑=>HP打印机,则是一个多层关联规则。
3)基于源数据中的维数——单维和多维关联规则
单维关联规则通常是在同一个空间中进行数据关联,是单一项之间的关系,但多维规则将会涉及多个事务之间的关系。例如面包=>牛奶,都是用户可能会想买的日常品,所以这是一个单维关联规则;年龄=18=>职业=“学生”,涉及到“年龄”、“职业”两个不同的事务,则是多维规则。
3 经典Apriori算法及改进
3.1 经典Apriori算法
Apriori算法是常见的挖掘项频繁集的高效算法之一,它基于频繁项集理论递推方法,通过多次迭代来逐步挖掘出相关的规则,而这些规则中的数据之间的支持度和置信度都不小于给定的最低值,因而第一次迭代时,计算数据库中每个项的支持度并将所有的频繁项记录为K-;后续的迭代中每一个频繁项都会生成对应的k+1候选集,在K轮迭代过程中,必须计算每一次迭代后中的所有候选项集(k+1)项的实际支持度,以此来生成下一个子项集;循环直至迭代过程不在产生新的项集则结束。
Apriori算法的实现过程如下:首先将数据库进行全集的扫描后,将包含所有项的项集为n阶为初始值;然后在此项集中进行迭代,直至项集为空,迭代规则为i阶迭代,都对i-1次阶中的项集Ii-1进行Apriori运算,进而得到i阶的候选项集Ci;接下来继续在数据库中扫描,并获得相对应的支持数,找到Ci中大于等于最小支持数的i阶项集。算法的伪代码如下:

输入:数据集D,以及最小的支持度min-up 输出:最大的频繁项集Ii,事务t0=D 1I1=D 2for(i=2;Ii-1≠ϕ;i++) 3Ci=Apriori(Ii-1) 4while(t∈D) 5Ct=subset(Ci,t) 6while(C∈Ct) 7C.sup++ 8Ii={C∈Ck|C.sup≥min.up}
关联规则在生成的过程中分为两个步骤:根据计算获取得到所有的频繁项集,然后找到强频繁项集中的强关联规则。如何快速精确地获取得到频繁项集是关联规则算法中的核心内容,强关联项之间的关联则相对来说比较简单,具体的关联规则的基本思想为:
设D为数据库中的m个项集合,其中事务I为非空子集。而在X的关联规则生成中,X,Y都是I的子集,且当中的D包含了X的百分比,则认为是X关联规则的支持度,而在事务X中包含了Y的百分比则是置信度。若X关联规则的置信度和支持度均大于设置的最小值,则表示事务X,Y具备关联性。
该算法的优势为支持度较低的情况下,扫描数据库的次数较少且空间复杂度较低。但该算法会产生大量的候选集和数据库的扫描次数剧增,这就会占用大量的内存空间,增加了运算时间和降低了运算速度。
3.2 Apriori算法改进
通过对经典Apriori算法的研究可知,在性能方面需解决两个问题:数据库的多次迭代问题造成的I/O负载过大;候选集的大量生成给内存空间造成的压力。针对以上两个问题,提出了一种基于频繁项集树模式的改进算法,具体的形式描述为将海量的数据应用切块技术对其进行划分处理;并将切块后的数据应用二位数组存储在内存中;最后应用动态剪枝技术将非目标节点删掉,应用深度遍历方式扫描频繁项树种的节点,以此来获取得到数据间的关联规则。计算的步骤如下:
1)应用划分技术,随机的将源数据划分为n块,并导入数据库,得到数据集D={D1,D2,…,Dn};
2)经典Apriori算法中的频繁项集将数据库保存在磁盘中,本文将其保存在主存中,因此设计特殊的二维数组类型来存储有效信息,行表示项,列表示事务;
3)设D中频繁项集Tk={t1,t2,…,tn},全集Tall中的所有项集都是按照Tk={t1,t2,…,tn}排序,就将第一前缀划分到不同的项集中,并以此为依据推算出之后的频繁项集;
4)根据全集Tall的长度n确定要构造的链,并固定其位置,然后随机的选择一个项集,并以其为根节点进行遍历,从而建立相对应的规则链,直至项集为空。此方法是通过对生成的规则进行遍历过滤,来获取置信度最小的关联规则。
3.3 改进算法性能分析
实验环境:内存2G,CPU 2.59GHZ,Windows7系统。
原始数据采用的是某高校的录取信息,共有3000多条信息,格式如图2所示。
并通过经典的Apriori在时间上进行对比,可知其在构造频繁项集数算法Tree-Alr在时间上是占据比较大的优势如表4所示。

表4 实验结果对比
4 结论
本文是基于数据挖掘的关联规则的研究,针对经典的挖掘关联算法Apriori中数据库扫描次数较多,占用较多内存空间的情况下,提出了一种新的频繁项构造方法,通过划分块的方式,并采用二维数组来保存数据库,将频繁项集构造为树结构,并获取得到关联规则。实验结果表明,改进算法能够降低迭代次数,使用的时间更短。
图2 某高校录取信息数据集
猜你喜欢
节能与环保(2022年7期)2022-11-09
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
河南水利年鉴(2020年0期)2020-06-09
计算机技术与发展(2019年11期)2019-11-18
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
计算机与数字工程(2017年2期)2017-03-02
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
智能系统学报(2013年2期)2013-01-28
