
基于机器人视觉的目标追踪算法研究*
2018-11-27 05:08王忠飞张朋涛
机电工程 2018年11期
王忠飞,张朋涛
(浙江工业大学 机械工程学院,浙江 杭州 310000)
0 引 言
通常,机器人通过获取到的图像的颜色和轮廓信息进行外界场景的静态分析,但如果需要进行动态场景追踪时,简单的颜色和轮廓信息就无法胜任了,需要用到特征检测。
尺度不变特征变换(SIFT)是LOWE[1]在1999年提出来的,利用SIFT所产生的特征点对旋转、缩放以及亮度的变化有很强的鲁棒性,有一定的抗视角变化和抗仿射变换的属性,同时具有很高的可扩展性,但是由于SIFT的特征向量描述子具有128维,计算成本高、匹配实时性差,易产生错配误配;为了提高特征向量匹配速度,KE Y和SUKTHANKAR R[2-3]提出了PCA-SIFT算法,将SIFT的特征向量的维数从128减少到36,匹配速度提高3倍,但匹配精度下降;BAY H等人[4]提出的SURF,使用积分图像代替了卷积积分,借助积分图像,图像与高斯二阶微分模板的滤波转化为对积分图像的加减运算,并且将特征向量的维数降到了64维,运算速度提高了3倍左右。以上皆为提高特征提取时的实时性,却很少提到提取到特征点后的匹配算法的优化以及其中所出现的问题该如何解决。
本研究将采用降维的思路,把128维的SIFT特征向量映射到一维空间内进行最近邻的检索,并通过实验对该算法进行验证。
1 SIFT特征点的提取
1.1 尺度空间极值提取
1983年WITKIN提出尺度空间理论,1984年KOENDERINK[5]在把这种理论扩展到二维图像,并且证明了高斯卷积核是实现尺度变换的唯一变换核。二维图像在不同尺度下的尺度空间表示可由图像与高斯核卷积得到,即:
L(x,y,σ)=G(x,y,σ)*I(x,y)
(1)
其中,高斯核为:
(2)
式中:I—图像数据;L—图像的尺度空间;(x,y)—目标图像的像素坐标;σ—高斯正态分布的方差,在这里被称为尺度空间因子,它的值越大表征图像被平滑越大,对应的尺度越大[6]。
Lowe使用尺度空间中的差分高斯(difference of gaussian,DOG)极值作为判断的依据。DOG算子定义为两个不同尺度的高斯核的差分,设k为两个相邻尺度间的比例因子,DOG算子的定义如下:
D(x,y,σ)=(G(x,y,kσ)-G(x,y,σ))*
I(x,y)=L(x,y,kσ)-L(x,y,σ)
(3)
式中:I—图像数据;L—图像的尺度空间;(x,y)—目标图像的像素坐标;σ—高斯正态分布的方差。
已知高斯金字塔分为很多组,每组又分很多层,层与层之间有不同尺度的区别,下一组尺度为σ的图像的最底层,是由上一组中尺度为2σ的图像进行参数为2的降采样所得到[7]。由于DOG金字塔出自于两个不同尺度的高斯平滑图像相减得到,虽然DOG需要在每层金字塔多做一次高斯操作(即为了得到S+2张DOG图需要S+3张高斯模糊图),但通过减法取代高斯核的计算过程,显著减少了运算次数,提高了运算效率[8]。
高斯金字塔与DOG金字塔如图1所示。

图1 高斯金字塔与DOG金字塔
可见,DOG金字塔比高斯金字塔每组多出一张图像。完成金字塔的构建后,即可开始检测DOG的极值。极值的检测如图2所示。

图2 DOG空间局部极值检测
每个像素需要跟在同一尺度下的周围邻域8个像素和相邻尺度相应位置的9×2个像素比较,总共需要与26个像素进行比较,只有当被检测点的DOG值大于或是小于该26个点的时侯才能将此点保存,并进行下一步的计算。
1.2 特征点定位
笔者使用拟合三维二次函数用以确定关键点的位置和尺度,粗略得到图像的SIFT特征点集合X0。但还需要对数据做进一步的筛选。
删除对噪音比较敏感的对比度比较低的点,将需判断的特征点x的偏移量设为Δx,对比度为D(x),对x的DOG函数进行泰勒展开为:
(4)
(5)
式中:X—筛选后的稳定的SIFT特征点的集合。
由于边缘梯度方向主曲率值较大,而边缘方向曲率较小,可以将主曲率比值大于一定阈值的点将其剔除。通过一个2×2的Hessian矩阵可求出主曲率[9],即:
(6)
式中:Dxx,Dxy,Dyy—候选点邻域对应位置的像素差分。
候选点的DOG函数D(x)的主曲率与2×2的Hessian矩阵特征值成正比,令α为H的最大特征值,β为H的最小特征值,且α=γβ,则D(x)主曲率的比值与γ成正比,有:
(7)
式中:Tr(H)—矩阵H的迹。
(γ+1)2/γ只与两特征值有关,与特征值自身大小无关,当两特征值相等时最小,且随着γ增大而增大,再取一阀值,当γ大于阀值时认定为边缘特征点删除。
1.3 特征点方向参数赋予
为了使所得的特征点具有旋转不变性,笔者利用关键点邻域像素的梯度方向分布特性,可以为每个关键点指定方向参数。而后面定义的关键点描述特征符是相对于这个主方向的,因而可以实现匹配时图像的旋转无关性。可以通过梯度直方图统计法来确定关键点的方向,即统计以关键点为原点,利用所有在该区域内的像素点的梯度形成一个方向直方图。
各方向梯度直方图如图3所示。

图3 各方向梯度直方图
本研究在以特征点为中心的邻域内计算出各个方向的直方图,计算出每个方向的幅值。梯度方向的直方图的横轴是梯度方向的角度,范围为0~360°,直方图每10°一个柱,共36个柱,纵轴是各个方向对应的梯度幅值的和,选取直方图中幅值和最大的点的方向作为主方向。
通过以上的计算已经可以找到SIFT特征点的位置、尺度和方向信息。下面就需要使用一组向量来描述关键点也就是生成特征点描述子,这个描述符除了包含特征点,也含有其周围对其有贡献的像素点。描述子应具有较高的独立性,以保证匹配率。为了保证SIFT的旋转不变性,首先需要使坐标轴的方向与关键点的方向保持一致,再在关键点周围取8×8的区域。
特征点的特征向量构造如图4所示。
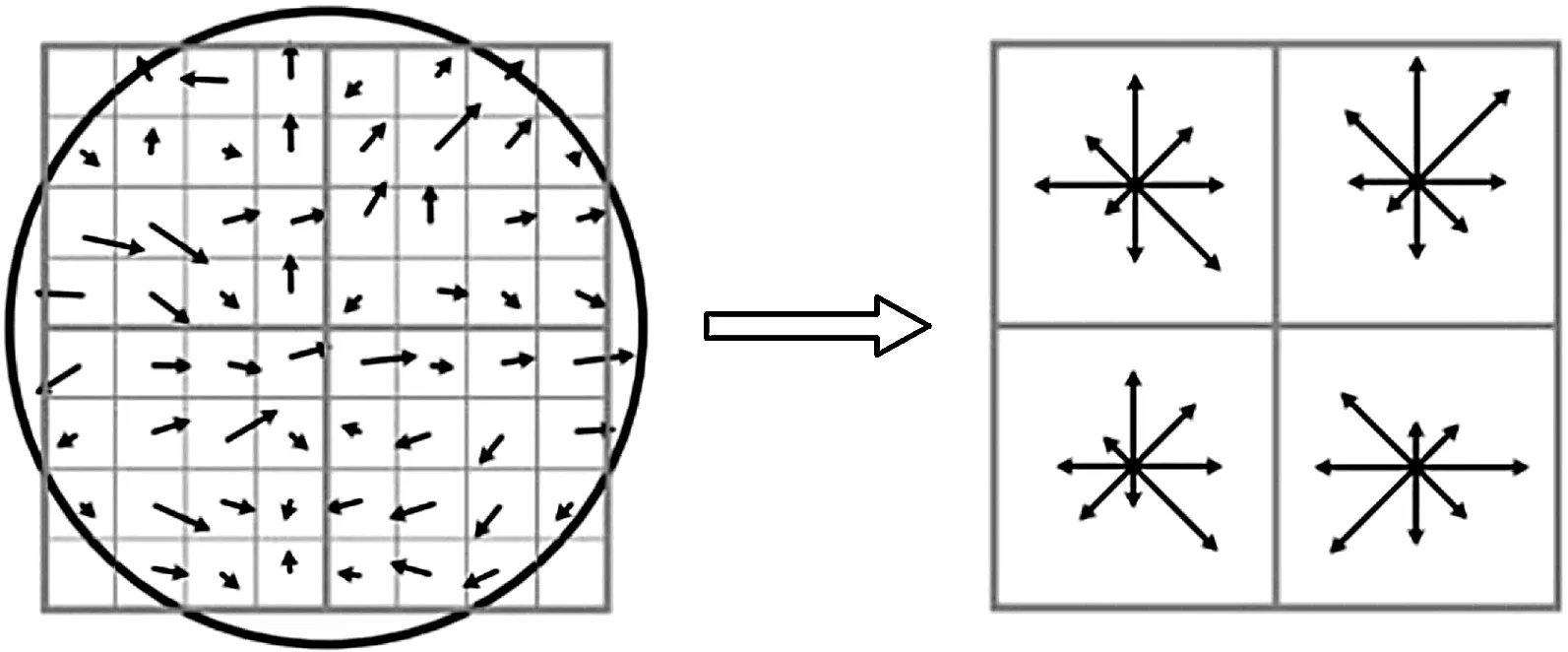
图4 特征点的特征向量构造
图4中,左图的中心点为关键点,周围的方块代表像素点,求取每个像素的梯度幅值与梯度方向,箭头方向代表该像素的梯度方向,长度代表梯度幅值,图中的圈代表高斯加权的范围,越靠近关键点的像素梯度方向信息对结果影响越大,然后利用高斯窗口对其进行加权运算。
最后本研究在每个4×4的小块上绘制8个方向的梯度直方图,计算每个梯度方向幅值的和,构成一个关键点的种子点。4个种子点初步构成了一个完整的SIFT特征向量。这样的特征向量描述子的构造对于SIFT的特征向量匹配有比较好的鲁棒性。在实际应用中,为了加大特征向量的稳定性,常常使用4×4共16个种子点来描述一个特征向量,因此,每个特征向量产生128个数据,最终形成128维的SIFT特征向量。
SIFT算法的特征点匹配本质上就是高维向量的最近邻搜索问题[10-11],而最基本的高维搜索方法即为穷举搜索法。穷举搜索法可不受维数限制,并且始终能在所有可能解中得到最优解[12]。但是对于128维的SIFT特征向量来说,由于提取出一幅图片的特征向量通常在千个数量级上,使用穷举搜索法进行特征点匹配的效率非常低、计算量大、时间长,不是最佳解决办案。
2 算法描述
为提高SIFT特征匹配速度,本文提出一种基于欧氏距离和特征向量夹角的最近邻搜索算法。该算法可描述为:设在q维欧式空间Rq中,存在2个高维向量集合A1={Vi|Vi∈Rq,i=1,2,…,n}和A2={Vl|Vl∈Rq,i=1,2,……,l},在A1中的∀Vi∈A1要在集合A2中搜索出其最邻近的值。选取q维欧式空间中的原点O(0,0,…0)作为参考点,计算出集合A2中所有的向量到原点的欧氏距离D(Vl,O),并进行升序或降序排列;保存起来在集合A3中,再计算出∀Vi∈A1到原点O(0,0,…0)的欧氏距离d,根据设定的误差检索范围e将查询范围确定在A3={Vl|Vl∈Rq,D(Vl,O)∈[d-e,d+e],i=1,2,…,l}中。再在集合A2中随机选择一个参考向量Vr,计算集合A2中所有的向量到参考向量Vr的夹角
这样,只需要输入一个参数,就可以快速查询出期望的最理想的邻近点作为匹配的特征向量。基于欧氏距离和向量夹角的最近邻搜索算法的具体实现步骤为:
(1)在n维欧式空间Rn中,求出所有包含所有特征向量的集合Tn中的每一个特征向量相对于原点的欧氏距离,并保存在数组Ao中;
(2)在n维欧式空间Rn中,选择一个参考向量Vr,利用余弦定理求出所有包含所有特征向量的集合Tn中的每一个特征向量相对于参考向量Vr的夹角,并保存在数组Aj中;
(3)对数组Ao和Aj中的值进行升序或是降序排列,由于同一个特征变量通过上面的两次计算所得的索引值不同,故将两者排序后的索引值做个映射保存在对象Om中,以备后面步骤中检索;
(4)输入需要查询的特征向量Vc,计算出其到原点的欧氏距离。由于在数组Ao中存在已经计算出的查询向量Vc的欧氏距离值,故搜索到此值时返回其对应的索引值index并保存在变量中;
(5)根据所选定的查询范围参数e确定的索引范围[index-e,index+e];
(6)根据所选定的查询范围参数e计算出需要查询向量的最大角度误差α;
(7)利用余弦定理计算出需要查询的特征向量Vc与(2)中选取的参考向量Vr的夹角θ;
(8)在限定的较小的索引空间内,利用(3)中的映射对象Om查询出该范围内所有特征向量与参考向量Vr的夹角;
(9)利用(7)中的角度误差范围搜索最邻近值,如果在这个范围内存在且不止一个,则分别计算出匹配向量与它们的欧氏距离,进行单独比较,欧式距离最小的特征向量,即可作为理想的正确特征向量保存,如果不存在则默认要查询的特征向量无正确的匹配向量。注意此时应忽略查询特征向量Vc本身计算出的夹角,无须比较。
由此可见,该算法只需一次数据预处理,即可将海量的高维空间数据检索简化为一个在较小的一维空间范围内的检索,从而提高SIFT特征点匹配的速度。
3 算法验证与结果分析
为验证基于欧氏距离和特征向量夹角的最近邻搜索算法(使用EVA表示该算法)的有效性,本文选取了BBF算法作为比较,验证改进的SIFT匹配算法(即基于欧氏距离和特征向量夹角的最近邻搜索算法)的有效性和优越性。
实验所采用的算法为Rob Hess维护的SIFT算法库。实验用的样张来自与牛津大学VGG实验室的Affine Covariant Features图像测试库。
3.1 性能评价标准
(1)正确匹配总数。正确匹配指的匹配对中的两个特征点之间的欧氏距离小于给定的阈值,并且两个特征点对应在不同图片空间中的相同物理位置,本文中描述的正确匹配总数为在进行Ransac算法剔除误匹配点后的匹配点对数;
(2)配准率。配准率=1-错误率,可以表述为:


(3)计算速度。计算速度是指SIFT在进行特征点的匹配时所耗费的时间。
3.2 算法验证
本研究对两种算法中的一些参数进行预置和说明。针对最近邻与次近邻的比值,经过对大量任意存在尺度、旋转和亮度变化的两幅图片进行匹配结果,本文预置为0.5且全程不变。在EVA算法中欧氏距离计算时所需要的参考点均采用高维空间中的原点,在进行向量夹角计算时需要的参考向量均采用Vr={1,2,3,…,128}。在BBF算法中,除了搜索最近邻个数的阈值变化以外,其他的参数均保持不变,全部保持默认参数。实验中选取查询范围参数0~0.5 mm,每次变化的步长为0.05 mm。
牛津大学VGG实验室图像测试如图5所示。

图5 牛津大学VGG实验室图像测试
SIFT识别效果图如图6所示。

图6 SIFT识别效果图
本研究对两幅图片做经典SIFT特征识别,检测出的尺度不变性特征点的个数为2 909个,耗时362 s。在不进行误配点剔除的情况下,能看到有很多误配点,但好在基数大,在进行误配点剔除后,仍能得到很多有效的配对点。
本研究取查询范围参数0~0.5 mm,以0.05 mm为步长进行比较,分别计算统计出运算后的正确匹配总数、配准率和计算时间。
查询范围参数与配准率之间的关系如图7所示。
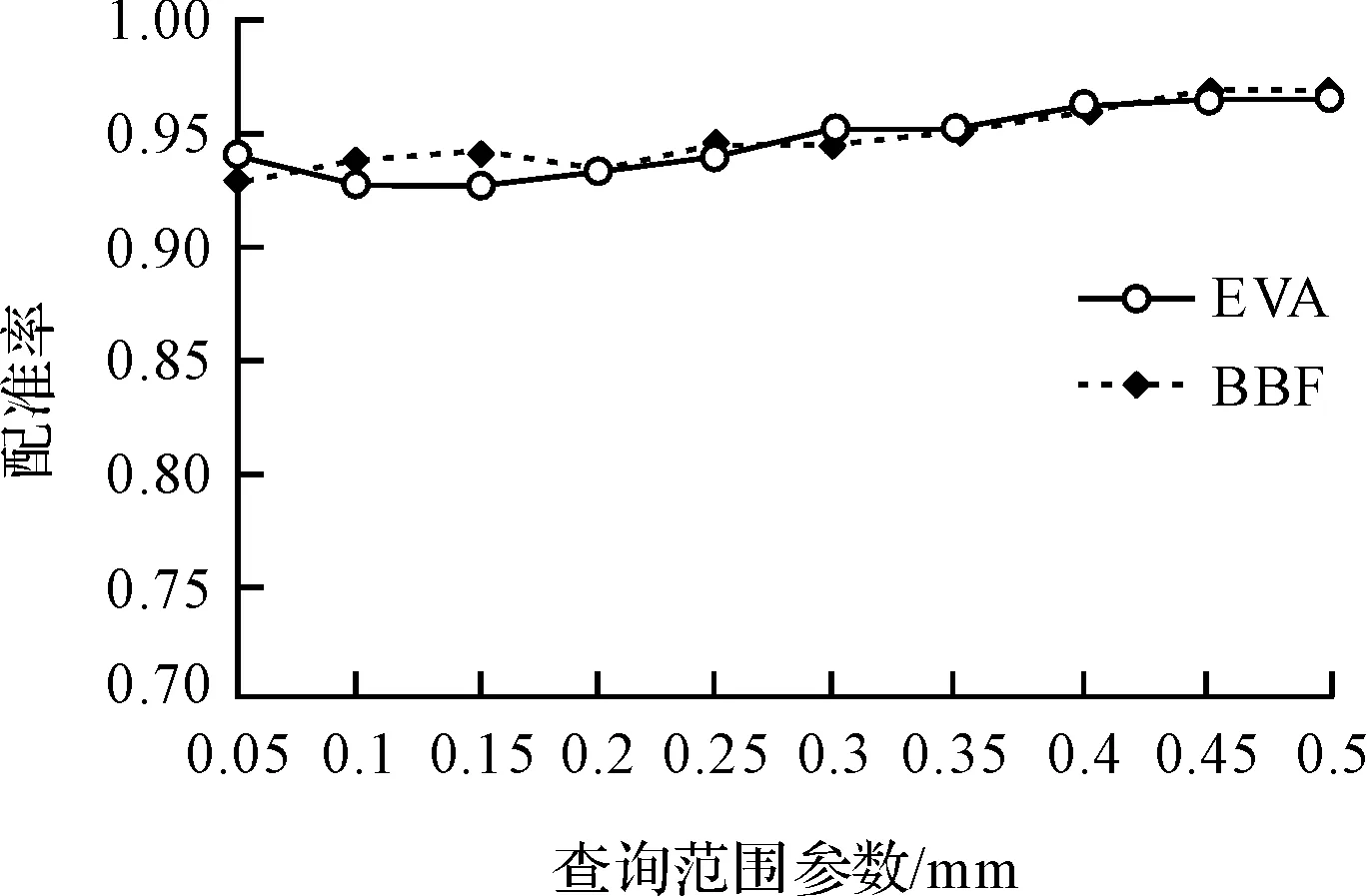
图7 查询范围参数与配准率之间的关系
查询范围参数与正确匹配总数之间的关系如图8所示。
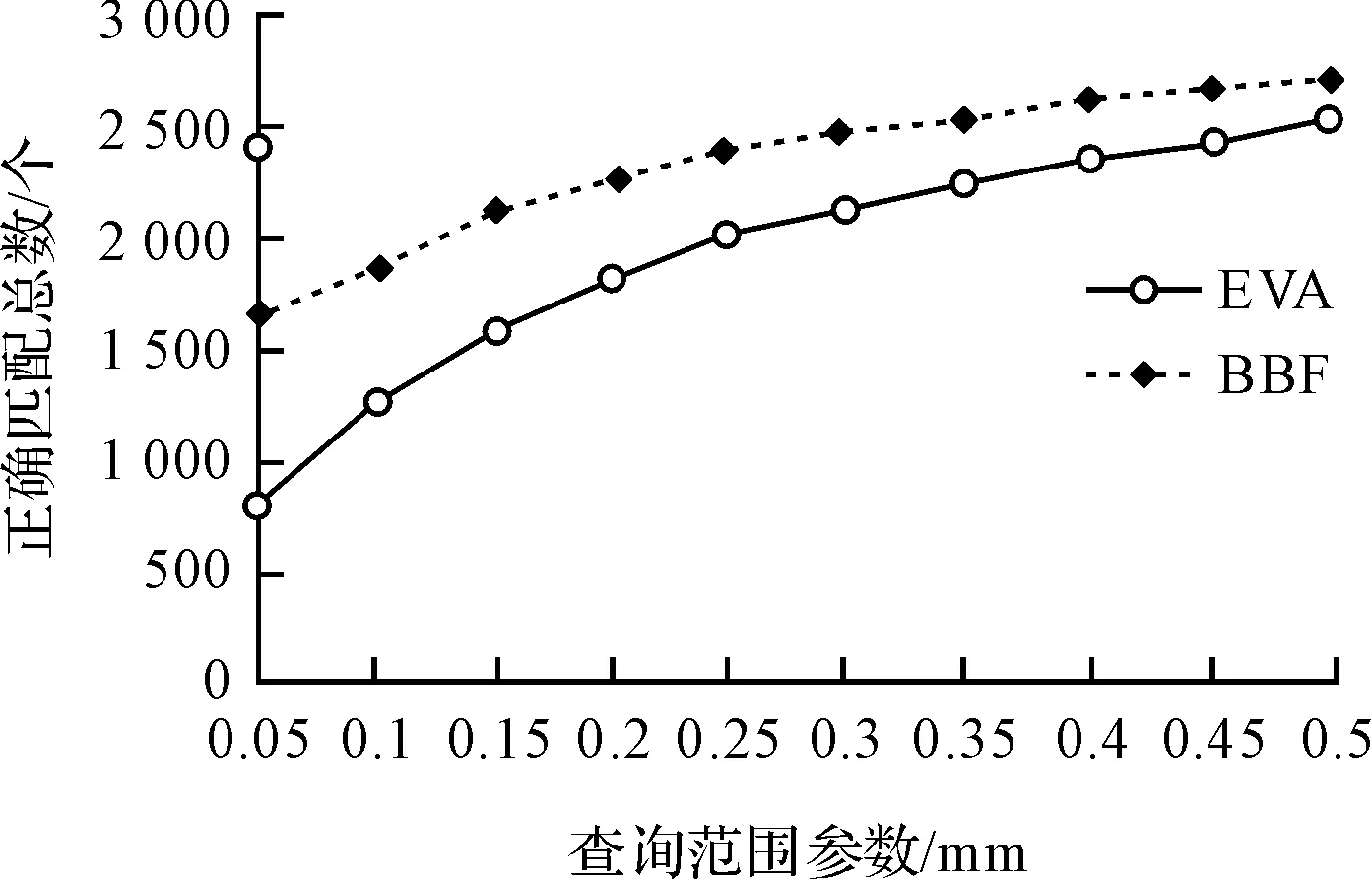
图8 查询范围参数与正确匹配总数之间关系
查询范围参数与匹配耗时之间的关系如图9所示。
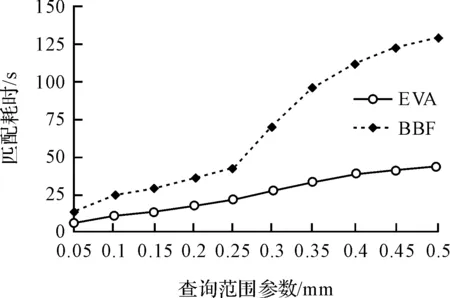
图9 查询范围参数与匹配耗时之间的关系
算法特征点匹配耗时对比结果如表1所示。

表1 BBF与EVA算法匹配耗时对比
3.3 结果分析
由图(7~9)可看出:在查询范围参数不同的情况下,EVA算法和BBF算法的配准率基本相同,正确匹配总数方面EVA算法比BBF算法高出很多,但随着查询范围参数的不断增大,差距不断缩小;在各段查询范围参数中的耗时BBF算法比EVA算法高出许多,EVA算法稳定保持小幅增长,计算耗时基本保持在50 s以内。表1数据表明:EVA算法的计算效率比BBF算法平均提高了2.5倍左右。
4 结束语
本文提出的算法通过欧氏距离和向量夹角的计算,将高维空间的数据简化到一维空间内进行处理,然后通过比较查询向量与所有向量之间的欧氏距离和夹角小于预先设定的某一阈值来进行最邻近查找,大大提高了特征点匹配效率。
本文提出的基于欧氏距离和特征向量夹角的最近邻搜索算法在提高SIFT特征点匹配效率上优势明显,具有一定的使用价值。
猜你喜欢
数学年刊A辑(中文版)(2022年3期)2023-01-05
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
电讯技术(2022年3期)2022-03-27
中学生数理化·七年级数学人教版(2020年12期)2021-01-18
语数外学习·高中版上旬(2020年8期)2020-09-10
数学大世界(2019年7期)2019-05-28
西南石油大学学报(自然科学版)(2018年4期)2018-08-02
中学生数理化·高一版(2018年5期)2018-06-04
中华建设(2017年1期)2017-06-07
