
基于扩展短文本词特征向量的分类研究
2019-04-19 05:18孟涛,王诚
计算机技术与发展 2019年4期
孟 涛,王 诚
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
1 概 述
随着社交网络和电子商务的飞速发展,微博、Twitter、商品评价、实时新闻推送等短文本形式已成为互联网的主流内容。短文本通常长度较短,范围在10到140个字。研究短文本中热点话题的分类挖掘以及监测网络舆情信息对各种领域决策方面有着重要的应用前景,因此如何高效正确地挖掘短文本成为了一个研究的热门方向[1]。
针对常规文本分类,大多是利用传统的向量空间模型(vector space model,VSM)将文本向量化并按向量之间的欧氏或余弦距离计算文本间的关系,在处理长文本时取得了很好的分类效果[2]。但是由于短文本文档长度较短,词项共现信息相对于常规文本非常匮乏,会存在向量空间信息稀疏问题。而VSM忽略了词语之间的语义相似度,词本身无法存储语义信息,会严重限制短文本主题分类的质量[3]。
对于缺乏语境信息而导致向量空间信息稀疏性的短文本问题,现有方法主要遵循两个方向来丰富短文本。第一种是仅使用隐藏在当前短文本上下文中的规则或统计信息来扩展特征空间[4],称为基于自我资源的方法。另一种是通过外部资源扩展特征空间,称为基于外部资源的方法[5],该方法可以分为四类,包括基于链接的方法[6]、基于Web搜索的方法[7]、基于分类的方法[8-10]以及基于主题的方法[11]。其次还有一种方式是将词矢量作为输入特征,利用卷积神经网络进行训练[12]。
现有的短文本研究存在的问题:引入背景知识和对外部相关数据的过度依赖,未从句子语义层面出发,无法深度挖掘短文本所表达的语义;改进短文本词向量的权重计算方法,但忽略了上下文因素。
针对短文本特征向量较少的问题,提出使用神经概率语言模型中的Word2vec技术进行词嵌入来训练扩展短文本中的词向量[13]。词嵌入也被称为词向量和词的分布式表示,已被证明在捕获语言中的语义规则方面是有效的,具有相似语义和语法属性的词被投影到向量空间中的相同区域,由此产生的语义特征被用作补充信息来克服短文中语境信息的局限性。词嵌入具有两个优点:维度缩减,上下文相似性。为了更好地利用词嵌入后向量空间中的词矢量,进一步将背景语料与词的语义相关度相结合,并用改进后的特征权重的计算方式去区分词汇的重要程度,去除大多数背景词在语义上没有关联的词汇。最后通过KNN分类方法对所提出的改进算法进行实验分析比较,以验证该方法可提高短文本分类精度的有效性。
2 相关工作
2.1 Word2vec
Word2vec是Google发布的一个NLP(neuro-linguistic programming,神经语言程序学)开源工具。 Word2vec采用distributed representation表示词向量,这种表达方式不仅可以避免one-hot representation的维数灾难问题,使词向量的维度变小,而且可以比较容易地用普通统计学方法来分析词与词之间的关系。
Word2vec模型使用CBOW(continuous bag-of-words)和skip-gram[14]两种结构作为学习模型。CBOW模型是使用上下文来预测目标词,而skip-gram模型的思路是使用特定的词去预测对应的上下文。这两种方法都需要利用神经网络对大规模语料进行语言模型训练,同时能够得到描述语义和句法关系的词矢量。CBOW模型使用上下文来预测目标词,会因为窗口大小的限制丢失短文本训练语料集中的相关语义信息;而Skip-Gram模型使用当前词来预测目标上下文可避免该问题,能够高效进行词矢量的训练,所以文中选用Word2vec的skip-gram模型。
2.2 针对短文本的权重改进
TF-IDF[15](term frequency-inverse document frequency,词频-逆文档频率)是一种用于信息检索与数据挖掘的传统加权方式,如式1所示:
(1)
其中,Wij是词tj在短文本di中的权重;tfij是词tj在短文本di中的词频表示;idfj是词tj的逆文档频率;N是语料库中短文本文档的总数;nj是训练背景语料库中出现tj的短文本数量。
由于短文本的数据稀疏性,导致TF-IDF权重算法的特征权重区分度不足。因此文中提出改进词频TF以及IDF权重以解决短文本分类中的数据稀疏性与文本区分度问题。
针对IDF权重算法,Basili提出了IWF权重算法[16],表达式如下:
(2)
相对于传统的IDF部分,显著区别在于IWF权重算法中对词逆文档频率做平方处理,其共同目的都在于降低高频率出现且相对来说无意义的词。Basili认为IDF的逆频率方面太过绝对,因此为了平衡各词的贡献,采用了平方去降低并缓和语料库中包含出现该词的文档对该词权重的影响,该方法也被证明相对IDF有更好的分类效果。同时,IWF应用到短文本领域对关键词快速提取也起到了更精确的效果,因为短文本本身的特性,该方法可以有效缓解短文本中计算词权重的偏向程度。
相比IDF与IWF的改进方式,对于TF采取类似的改进方式。tfij的定义是短文本di中词tj的词频,由于短文本相对于长文本字数较少的特性,其词频也相对较低,所以单纯使用原公式的TF相对于短文本并不适用。针对短文本的稀疏性使得难以从词频信息来判断该词的重要程度,需要降低并削弱词频对权重的影响,所以做出以下改进:
(1)考虑采用对数函数log(底数为10)对tfij作处理,由于tfij是小数,直接进行log处理会是负数,所以做加1处理,即log(1+tfij)。
(2)考虑到扩展后的短文本中关键词相对扩展的集中性,用对数函数削弱会导致词频降低的太过绝对,词频之间相差会比较大,从而影响短文本分类的性能。所以引入方根来缓和差异性较大的问题,但是对于缓和程度,即方根的次数θ,需要结合实际短文本做实验来确定,即(log(1+tfij))1/θ。
该方法改进的意义在于,选用对数函数来降低词频的影响,但是对于短文本词频来说对数函数削弱的太过绝对,所以引入方根来做缓和,该方法的有效性将通过具体实验进行验证。综合以上改进,得到改进后的权重计算公式,记为TF’-IWF。
(3)
3 改进后的特征权重算法处理扩展后的短文本词特征向量
对于短文本稀疏的特性,使用外部语料集来扩展短文本。首先,通过收集相关训练语料库作为训练短文本的扩展词典,并使用Word2vec模型处理该语料库,并测试扩展后的语义相关性;然后通过Word2vec训练词的语境相关概念并用来处理扩展短文本的词向量。该方法的一般框架如图1所示。

图1 短文本分类过程
3.1 预处理
在对短文本做功能扩展之前对短文本进行预处理,包括三个主要步骤:中文版分词、停用词过滤和特征选择。文中采用比较成熟的中文分词工具-结巴分词将短文本收集成分词;之后对停用词进行过滤,通过功能选择保留了有代表性的词;最后,使用式3对特征进行加权,得到短文本的向量表示。
3.2 构建扩展词向量的相关工作
文中使用整理好分类的新闻语料库,总共包含39 247篇新闻,分为历史、军事、文化、经济、教育、IT、娱乐、法制总共八个类别。对于词嵌入扩展的新闻数据集,使用中文的百度百科网站上抓取的10万篇文档信息和已整理好的新闻语料库的新闻内容当作训练语料词典,即语料库。
首先,使用Word2vec模型去训练整理好的新闻语料库,得到词的相关语境概念。对于使用Word2vec训练得到的词相关语境概念只是为了预测之后测试短文本过程中的副产物,而不是结果。
(1)训练语料库中词的相关语境概念。
定义训练的新闻语料库为词库vocab,其中文本数定义为di,文本中出现的词定义为tk,M是指词向量维数。
vocab={tk|k∈[1,M]}
使用Word2vec模型训练该语料库,将得到词相关语境的向量空间Ck(disk,1,disk,2,…,disk,n),一个输入单词,有n个输出概率结果,n是指该词在相关词库出现的次数。该训练过程只包括该词的语义环境,并不针对整个词库。
该相关语境的词向量空间Ck不是预测的目标(语义相关度才是需要的),该词向量是为之后测试输入词用来学习的表达,是为了测试短文本任务中预测所给单词的语义环境。该相关语境的词向量Ck是Word2vec模型在试图通过不断学习该词的一个好的数学表达来提高预测词分类的精确结果。在模型重复循环的过程中,不断调整完善词的数学表达。
(2)测试短文本与相关语境之间的语义相关度。
在得到训练语料库中词的相关语境概念后,需要测量测试短文本中词的语境向量Ci与其相关词语境向量空间Ck之间的语义相关度。其中测试短文本词的语境向量Ci是用Word2vec得到词ti在该文本语境中的矢量表示,表示形式为Ci(disi,1,disi,2,…,disi,n)。
文中用Word2vec来处理,得到测试文本中词的语境向量Ci与训练语料库中词的相关语境向量概念Ck,并测量两者的语义相关度,具体过程如图2所示。

图2 语义相关性的具体过程
语义相关度的定义如下:
(4)
经过以上处理,最终得到测试短文本的文档向量表示C(di),C(di)=((C1,R1),(C2,R2),…,(Cn,Rn)),其中Ri(1≤i≤n)是词ti的语境向量Ci和涉及到的Ck的语义相关度。
3.3 扩展短文本的特征权重处理
扩展特征项是短文本分类的核心,基于语料库扩展短文本特征的方式有助于解决数据稀疏性问题和传统缺乏描述短文本类特征的能力。在对短文本进行预处理后,得到特征项列表及其加权值为((t1,tf'iwf1),(t2,tf'iwf2),…,(tm,tf'iwfm)),tf'iwfi是特征项ti的加权值,由式3计算,m是短文本中特征项的数量。基于语料库的Ck扩展特征空间,该方法由以下步骤完成。
(1)确定特征词ti有无语料中对应的词嵌入。如果有该词ti的相关语义知识,则继续下一步;如果不是,则更改为下一个特征词。
(2)将相关语义加到特征向量中,得到语义词Ci和相关语境集合Ci((C1,R1),(C2,R2),…,(Cn,Rn))的特征项ti。对于扩展性能是否合理以及最佳性,需要设定阈值φ来判断词嵌入的质量。
(3)使用特征权重定义扩展后短文本集。为了准确衡量扩展后的词对短文本原始语义的影响,结合短文本特征的重要性和扩展语境之间的相关性,通过式5计算扩展项的权重值。
(5)
其中,weighti,j是扩展项j的权重值;tf'iwfi是短文本中特征词ti的加权值;Rj是语义相关度。如式5所示,记为TF’IWF-Rj。
从以上的处理分析可得到短文本的向量空间包含原始特征项和上述处理之后扩展的词向量。
4 实 验
4.1 实验数据集
文中使用整理好分类的新闻语料库,总共包含39 247篇新闻,分为历史、军事、文化、经济、教育、IT、娱乐、法制共八个类别。数据集包括新闻标题及新闻内容,文本采用原新闻标题数据集作为短文本数据集,内容数据集作为背景语料库数据集。按照u:v(u+v=1)的比例将短文本数据集进行分类,其中u是用于训练的数据集,v是用于测试的数据集。
实验平台:两台Linux操作系统的计算机搭建Spark集群,这两台计算机一个Master节点,一个Slave节点,两台计算机都同时部署Hadoop 2.6.4和Spark 2.1.0,Hadoop提供HDFS等底层文件支持。
4.2 分类性能评价指标
分类评价指标主要包括预测准确率Precision、召回率Recall和二者的综合评价指标调和平均数F1。
4.3 实验设计和结果
通过Word2vec获得百度百科网站等新闻语料库中概念的特征矢量。扩展短文本时,根据筛选出的语义相关词的质量来决定阈值φ。设置扩展阈值φ=0.5,该扩展的参数调整使分类准确率达到最高,并设置θ来权衡扩展短文本权重比例对分类的影响。最后使用Spark中可用的KNN分类器实现实验[17]。
4.3.1 改进词频对分类结果的影响
为了验证所提降低词频的算法对短文本的实用性,从语料库中选取已标注关键词的8个类别中不相关的短文本作为测试文本集。
对于式3中方根次数θ的选定,依次选择θ值等于1、2、3、4,并进行实验分析不同方根值对短文本分类结果的影响。比较数据如表1所示。
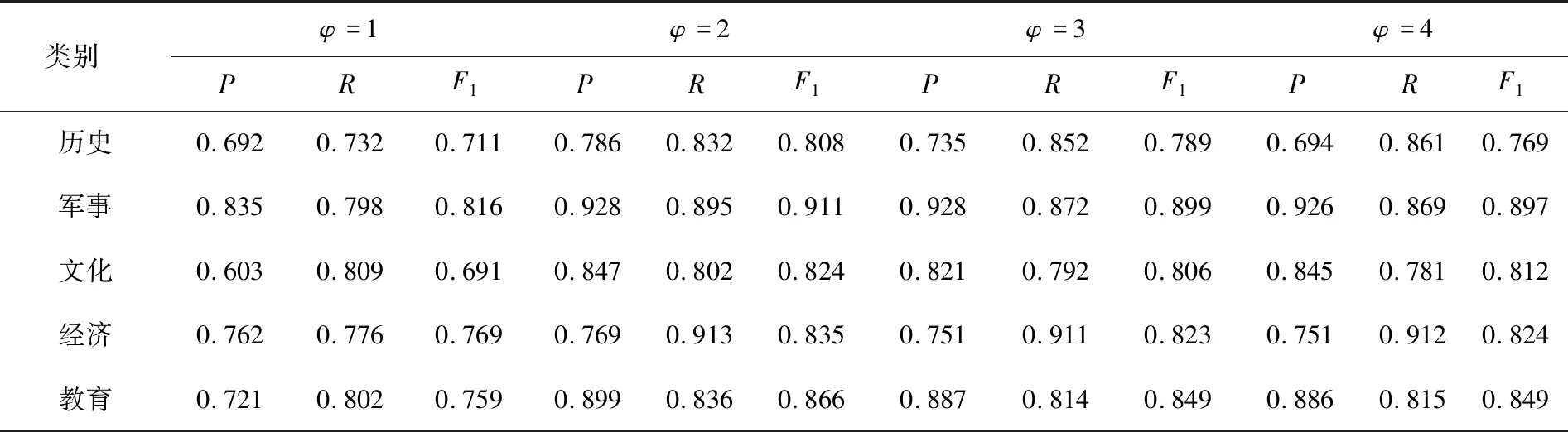
表1 不同θ值对分类结果的影响

续表1
从图3中可以发现,当θ=2时,分类结果相较于其他值较好,同时也验证了考虑方根值缓和对数函数削弱词频太过绝对性方面是有意义的。

图3 词频中不同θ值对分类性能的影响
4.3.2 改进的关键词提取算法比较
对于关键词加权算法TFIDF与TFIWF和TF’IWF的比较,采用确定值θ=2,通过实验来具体比较它们的性能。一般关键词提取算法的评估是通过精确率和召回率来评测算法性能,比较如图4所示。
从图4中可看出,文中算法提取的关键词在分类的准确率和召回率上相对于传统TFIDF算法提高了10%左右,验证了该算法在短文本上的适用性更可取。

图4 不同关键词提取算法对分类结果的影响
4.3.3 引入Word2vec方法分类对比
通过三个实验来验证该方法的效果。其中使用原始的TFIWF+Word2vec的词嵌入特征测试短文本的分类性能;用Word2vec与改进后的TF’IWF加权方法作为第二组对比实验;最后用文中改进的TF’IWF-Rj方法与Word2vec进行对比。实验数据如表2所示。
从表中可以看出,文中方法比Word2vec和TF’IWF相融合的方法在准确率、召回率都有提高,其中F1值从89.2%上升到91.7%,整体提高了2.5%;与Word2vec融和TFIWF方法相比较,在F1值指标中有8.7%左右的提高。

表2 引入Word2vec的分类结果对比
4.3.4 综合比较
由于以上对比改进的关键词提取算法和引入Word2vec都是基线比较,为了直观表现该方法的有效性,将比较只引入词嵌入的方法1:Word2vec,只引入关键词最优的提取算法作为方法2:TF’IWF,以及与文中所提出的方法3:TF’IWF-Rj+Word2vec作比较。比较结果如图5所示,可以直观地看出文中算法的有效性。

图5 方法综合比较
5 结束语
与传统文本向量空间模型相比,通过Word2vec扩展短文本特征向量,使用语义相关度并融合改进后的权重计算可以有效地改进短文本的稀疏性和缺少上下文语义分析的问题,进而提高了短文本分类的性能。下一步可以考虑分类主题模型的创新以及对扩展训练语料进行研究,从而继续提高算法的精度和适用性。
猜你喜欢
心理学报(2022年5期)2022-05-16
外语学刊(2021年1期)2021-11-04
当代陕西(2020年17期)2020-10-28
亚太教育(2018年5期)2018-12-01
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
师道·教研(2017年11期)2017-12-10
读者·校园版(2015年7期)2015-05-14
外语教学理论与实践(2014年4期)2014-06-13
心理学报(2014年4期)2014-02-02
