
基于突破性局部搜索的集装箱班列同步转运作业调度优化①
2019-10-18 06:41栾玉麟
计算机系统应用 2019年10期
何 迅,郭 鹏,栾玉麟
(西南交通大学 机械工程学院,成都 610031)
(轨道交通运维技术与装备四川省重点实验室,成都 610031)
铁路运输作为最为低碳的货运方式,在内陆腹地运输方面极具优势.我国铁路货运总量占比在面临残酷的市场竞争时连年下滑,已由2009年的11.96%降至2017年的7.81%[1].目前我国铁路集装箱运量仅占铁路货运量的5.4%,远远低于发达国家(美国占比49%,法国占比40%,英国占比30%,德国占比20%,日本占比100%)[2].如此大的差距表明我国铁路集装箱运输存在巨大的潜力和发展空间.当前,我国沿海港口积极发展内陆“无水港”,加快港口铁路集疏运,积极推动船、车、班列、港口、场站、货物等信息开放共享.国家“十一五规划”规划建设了18 个铁路集装箱中心站,有利于实现区域集装箱铁路运输与其他运输方式的无缝衔接.在“一带一路”国家战略的带动下,铁路集装箱多式联运更是迎来了弥足珍贵的发展契机,研究提升铁路集装箱多式联运效率具有重要的现实与战略意义.
作为多式联运铁路站场主要活动,转运作业效率直接影响铁路集装箱多式联运的整体运作水平.为了保证自动化堆场作业计划生成的准确性,现有铁路集装箱站场转运作业均要求集装箱班列或卡车经堆场方可实现.经集装箱站场实现不同运载工具之间的转运必然存在两次装卸和一次暂存作业.对于提高转运作业效率来说,暂存和额外的装卸作业完全是无效操作,且会使有限的堆场空间资源更为紧张.减少暂存中转作业的关键是提高同步转运(也叫连续转运或直装直卸)集装箱比率.同步转运旨在通过合理安排集装箱班列进入堆场的作业时间窗,实现在站的两类运输设备之间的集装箱流同步交互,尽可能地缩短集装箱站内中转时间.
国内外学者对铁路集装箱站场的作业效率提升进行了不少研究.Boysen等[3]对铁路站场的设施布局与作业调度优化研究现状进行了归类总结.Otto和Pesch[4]分析了多式联运下铁路堆场中班列与堆场指派问题,以最小化再指派次数为目标更新了下界计算方法.Boysen等[5]构建了铁路-铁路(Rail-Rail)站场的数学规划模型来确定主装卸线上各台起重机的最优作业区域.Kellner等[6]考虑集装箱班列停靠位置对转运作业的影响,并构建数学模型来确定其最佳位置以便减少集装箱移动距离.Boysen等[7,8]提出采用集装箱整理系统支持站内转运,并对比分析了四种不同的集装箱整理系统在铁路-铁路联运站场中的作业效率.起重机作为集装箱站场的主要转运设备,Guo等[9,10]对公铁联运的集装箱中心站轨道式起重机调度问题进行了建模优化,并希望将外部卡车服务水平纳入调度优化模型.王力等[11,12]认为集装箱班列卸箱作业和装箱作业过程相同,以卸箱作业过程建立了中心站起重机调度优化模型,设计了混合粒子群算法进行求解;还考虑堆场混堆优化问题,以两阶段优化模型来平衡堆场各箱区进站箱和出站箱的数量及减少堆存所产生的压箱数.而上述研究聚焦在铁路站场的箱位指派、集装箱班列位置指派、装卸设备调度问题上,尚未考虑同步转运作业.
在不同的运输方式之间利用转运工具实现乘客或货物中转,尽可能保证进出运载工具的同步,能够大幅提升转运效率[13].Boysen等[14]为铁路-铁路(Rail-Rail)集装箱站场调度问题构建了数学模型,通过确定集装箱班列集合中每趟车的服务间隙来最小化班列重回站场的次数和集装箱分割装卸的移动次数,证明了该问题是NP-hard的,并提出了基于动态规划和束搜索的求解算法.该研究对集装箱班列的转运调度进行优化,以求实现同步转运,本文在此基础上提出集装箱班列同步转运调度模型,通过分析问题的特征设计基于突破性局部搜索的求解算法.利用算例验证本文算法可以在提高求解质量的同时,显著缩短求解时间,对站场效率提升具有重要的参考价值.
1 问题描述与数学模型
在集装箱班列同步转运作业调度问题(Freight Trains Scheduling Problem with Synchronized Transferring,FTSPST)中,n趟班列需要进入堆场实施装卸转运操作.堆场铺设有m组并行铁轨,每次最多可牵引m趟班列进入.假设有T个时间段实施牵引进站作业,则有T=n/m.为了方便描述,在此假设n=T×m.在实际作业过程中,若班列数不足n,可通过引入未装载集装箱的虚拟班列来满足.针对班列i(i=1,…,n),最早进入堆场时间段为ei,最晚离开堆场时间段为li.假设班列i和j之间存在Aij个集装箱须进行转运,若两趟班列能够在同一时间段t牵引进堆场,则可成功实现Aij个集装箱同步转运.需要转运到班列i的集装箱位于其他班列之上,用Li表示能与班列i进行同步转运作业的其他班列集合.在此定义决策变量xit与zij,若集装箱班列i进入堆场的时间段为t则xit=1,否则为0;若集装箱班列i和j在同一时间段进入堆场则zij=1,否则为0.以同步转运的集装箱箱数最大化为优化目标,构建如下混合整数规划模型:

s.t.

上述优化模型中,目标函数(1)保证同步转运的集装箱箱数最大化;约束(2)确保一辆班列只能被安排在一个时间段;约束(3)确保同一时间段内进入堆场的班列数不超过铺设的轨道数;约束(4)表示同一时间段进入堆场的班列i和j对应的变量zij必须为1;约束(5)定义决策变量的取值范围.
2 突破性局部搜索算法
突破性局部搜索算法(Breakout Local Search,BLS)是一种自适应的邻域搜索算法,在一般邻域搜索算法的基础上增加了自适应扰动机制,能快速逃离局部最优以及提高稳定性[15].该算法分为局部搜索阶段和扰动阶段.通过某种方法产生初始可行解π0,利用邻域搜索算子产生所有的可行解,从中找出局部最优解π.然后通过适当的扰动对当前解π进行操作以帮助算法逃离当前的局部最优解,扰动获得的解将成为下一轮邻域搜索的起点.上述搜索一直迭代直到达到算法终止条件为止.BLS算法在搜索过程中融入了局部迭代搜索、禁忌搜索与模拟退火算法的操作机制,具有搜索质量高、计算时间短等优点,现已用于求解最大团问题[16]、最大割问题[17]、二次指派问题[15]、装配序列规划问题[18]以及门分派问题[19]等,并获得较好的求解效果.BLS算法流程图如图1所示.

图1 BLS算法流程图
2.1 自适应扰动机制
BLS算法对局部最优解的扰动取决于扰动幅度和扰动类型,扰动的强弱依赖于当前搜索操作的状态,主要是通过当前解π和当前最佳解连续未改善的次数ω来确定扰动幅度K和扰动类型[16].BLS首先搜索邻近的局部最优解,只有当搜索停滞不前,才能移动到下一个邻域.在每次局部搜索后,BLS执行小幅度的定向或近似随机移动,以保证能够逃离当前局部最优解.如果扰动幅度不足以逃离局部最优解,则增加扰动幅度K;否则将其设置为默认值,即K=K0.如果当前最佳解连续未改善的次数超过了给定的阀值Ω,则将扰动幅度设置为最大值Kmax,以保证搜索过程能够脱离当前邻域解空间.
所提出的BLS算法采用置换序列的编码形式,譬如5趟班列与2组铁轨的算例,则当前解序列π={1,5,2,3,4},其中π2=5表示编号为5的班列安排在序列位置2处,若班列1与班列5均可在时间段t=1进入堆场,则其进入堆场的时间段为1.邻域操作与扰动采用交换操作,则π’=π⊕swap(u,v)表示交换位置u和v上的班列序号得到新的候选解.
BLS算法采用以下三种扰动类型:定向,近似随机和随机扰动.定向扰动基于禁忌搜索原则来实施,当搜索到的候选解优于目前为止找到的最佳解时,该操作对应的禁忌状态消除.同时产生候选解的操作在禁忌周期γ之外时,也可消除禁忌状态.定向扰动依赖于上一次迭代搜索的历史信息以及不会禁止良好的扰动操作.针对定向扰动的判断由集合 R表征:

其中,H是上次执行扰动时跟踪迭代次数的矩阵,Iter是当前迭代次数,f是当前解对应的目标函数值,fbest是当前已找到的最佳解对应的目标函数值,u、v为需要进行置换扰动的变量.γ值越大代表着扰动越强烈,在 BLS 算法中γ=n×r1+rand(0,1)×n×r2,其中r1与r2为待确定的常数值.近似随机扰动仅依赖于由H矩阵提供的历史信息,由集合 Z表征为:

随机扰动简单地执行随机均匀的扰动,由集合C表征:

为了实现强化搜索和多样性搜索的平衡,BLS算法引入概率选择操作确定扰动类型.根据当前搜索状态和当前最佳解连续未改善的次数ω动态确定应用特定扰动的概率.在迭代搜索过程中,若找到新的最佳解或ω超过给定阈值Ω时,ω被重置为零.邻域搜索初期算法更偏向于采用定向扰动.随着ω的增加,使用定向扰动的几率逐渐降低,同时随机和近似随机扰动的概率会增加,从而达到自适应的多样性扰动.
另外,从计算分析中已经观察到,保证定向扰动的最小概率是有用的.因此,采用定向扰动的概率p取不小于阈值p0的值:

基于计算出的定向扰动概率p,则可分别通过(1-p)*Q和(1-p)*(1-Q)确定近似随机和随机扰动的概率,其中Q为区间[0,1]之间的常数.确定了各自的概率后,则可通过区间位于(0,1)之间随机数来确定扰动类型.
2.2 基于问题的算法改进
铁路集装箱班列同步转运过程中,存在每辆班列最早与最晚离开堆场的时间段和现有铁轨数的约束.为此需对BLS算法进行必要的改进以适应所考虑的问题.为了加快算法搜索速度,在此设计算法1中的BLS初始可行解产生算法.

算法1.BLS初始解生成流程输入:班列间同步转运的集装箱箱数矩阵A,每辆班列的最早进入或最晚离开堆场时间段,待安排的班列集合Θ.初始化:将决策变量x和z置为0矩阵.1.根据班列最晚离开堆场的时间段对班列进行升序排列.2.班列进入堆场的时间段分为T个.3.时间段计数器t=1.4.while待安排的班列集合Θ不为空do 5. 从集合Θ中依次选择m趟班列.6. if选定的m趟班列能在时间段t进入堆场7. 让m辆班列依次进入堆场.8. 从集合Θ删除已进入堆场的班列序号.9. end if 10. 更新m趟班列间能实施集装箱同步转运的0-1矩阵z和时间段指派矩阵x.11. t=t+1.12. 计算成功实施同步转运的集装箱箱数.13.end while 14.输出:x和z.
邻域搜索与扰动产生的候选解对应的目标函数值计算将耗费大量的计算成本.为了缩短计算时间,在此依据每次班列置换后的增益来计算候选解的目标函数值.针对数学规划模型的特点确定班列置换判断条件.当班列i与班列j进行置换时,班列i与j必须满足置换之前各自被分配在不同的时间段,并且置换后分配的时间段不能超出各自最早进入和最晚离开堆场时间段.π’是当前解π通过交换位置r和s上的班列所得到的邻域解.则当前解π与邻域解π’之间的增益用式(10)计算:

式(10)的时间复杂度仅为O(n).如果π’是通过交换r和s后得到的邻域解,则对增益矩阵δ(π’,u,v)进行计算i 被标记为禁忌状态;重复上述过程直至达到班列j 的最大集装箱数或所有班列均为禁忌状态为止.?

式(11)在计算增益方面采用前解指导后解的思路,在保留每一阶段的最优值同时进行置换计算,大大提高目标函数值计算效率.
BLS算法终止须满足下列条件之一,则停止迭代输出最佳解结果:1)达到给定最大迭代次数10 000次;2)达到给定最大计算时间600秒.
3 算例分析
为了验证算法的求解质量与效率,将所提出的算法BLS与Boysen等[14]提出的束搜索算法(Beam Search,BS)和数学规划模型的计算结果进行对比.数学规划模型求解采用Gurobi8.0求解器,计算时间设定为1800秒.BLS和BS算法采用C#编程并在Visual Studio 2013中实现.所有方法在CPU为Inter(R)Core(TM)i7-4790M@3.60 GHz、内存为8 GB以及系统为Windows7的个人电脑完成测试.将各个方法求解得到的目标函数值转换成相对百分偏差(Relative Percent Deviation,RPD),以此作为算法性能分析的响应变量.RPD计算如下式所示:

3.1 算例设计
针对所研究的集装箱班列转运调度问题,尚未有公开的算例测试集.在此利用Boysen等[14]提出的方法产生本问题的测试算例.为了生成测试算例,表1中列出了用于产生算例相关参数的取值范围.矩阵Aij产生方式如下:用车厢数量乘以载荷系数产生班列间能够交互的最大集装箱箱数;对于每辆班列j,随机选取另一辆班列i,其能够转运的集装箱箱数从区间[1,MaxTr]中采用均匀分布随机产生,其中MaxTr是指两辆班列之间能够转运的集装箱箱数上限;随后,班列

表1 算例参数表
算例的产生充分考虑时间限制的生成.若不限制的话,则班列i设置ei=1和li=T.若仅有进入时间限制,则从区间[1,T]随机确定ei并且所有li=T,其中ei=1有50%的概率出现而其余则采用均匀分布随机产生.若进入与离开均有时间限制,则从区间[1,T/2] 中选择ei,区间[T/2,T]中选择li,对于ei=1有50%的概率出现,对于li=T也有50%的概率出现.在此所有生成的算例都需要试算以保证至少存在一个可行解,否则将重新生成.表2为算例中班列与轨道的关系.

表2 班列数与轨道数取值范围
根据班列的进出堆场的时间段将算例分为FTSPST1,FTSPST2和FTSPST3三种类型,FTSPST1代表所有班列最早进入与最晚离开堆场时间段一样;FTSPST2代表所有班列最早进入堆场时间段不同最晚离开堆场时间段相同;FTSPST3代表所有班列最早进入最晚离开堆场时间段都不相同.针对表2所示的班列数和轨道数生成105组算例,其中12-2,12-4和16-2,16-4的算例总共生成5组,其余都为1组.
基于初始计算测试,BLS算法采用表3所示的参数将获得不错的计算性能,以求在较短的时间给出不错的求解结果.

表3 BLS算法参数表
3.2 算例计算分析
将班列数在50辆以下的归为小规模算例,而将班列数在50辆以上归为大规模算例.由于篇幅限制,在此仅列出班列数为12和80的算例计算详细结果.表4给出了班列数为12的一组算例计算结果.在该表中列出了各个算法求得的目标函数、计算时间以及利用式(12)计算出的相对百分偏差RPD,其中BLS与BS的计算时间为600秒内首次搜索到该算例最佳解时记录的时间.下标BLS表示BLS算法相关的结果,下标BS表示束搜索算法相关的结果,下标G表示优化器Gurobi的相关结果.从中可以看出3个方法均能够在较短的计算时间内给出最优解,但BLS的计算时间最短,BS次之,优化器Gurobi耗时最长.

表4 12辆班列算例计算结果
表5给出了班列数为80时的计算结果,其中涉及的指标与表4一样.从中可以看出BLS依然给出所有算例的最好解,但其计算时间比BS的用时稍长一些.优化器Gurobi耗光了给定的时间限制1800秒,且求解性能易受算例类型的影响.也就是说进入或离开堆场的时间段的不同使得求解空间的规模不一样,优化器求解性能亦不一样.BS的求解质量相对较为稳定,RPD的均值为13.3%.

表5 80辆班列算例计算结果
表6和表7分别给出了小规模算例与大规模算例的平均计算结果.从计算精度上来说,对于50辆以下的班列数,BLS算法能很快计算出与Gurobi相同的最优解,而BS则与最优解存在1.69%的差距.对于50辆以上班列数的大规模算例,Gurobi的平均计算时间为24分钟,BLS算法为105.59秒,而BS算法仅为26.11秒,可见在大规模算例上BS算法有优势;但是在解的精确度上BLS算法明显比Gurobi和BS的计算结果更好,而且BS算法在解50以上规模的FTSPST2和FTSPST3类型算例时解的精度较差,和Gurobi的计算结果相比存在较大的差距.对于100辆左右的班列数,Gurobi优化器和BS算法很难求出该问题的较优解,而BLS能够在230.66秒的平均计算时间内给出最好的解.因此,BLS算法针对集装箱班列的同步转运调度问题具有较为明显的优势,不仅计算精确度高,而且计算耗时也很短.

表6 小规模算例平均计算结果
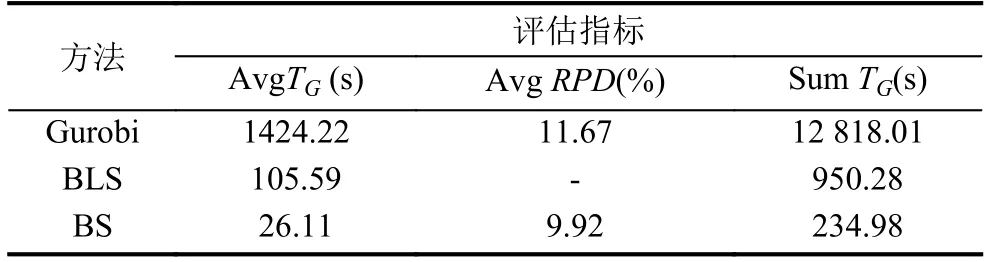
表7 大规模算例平均计算结果
4 结论
本文在考虑同步转运作业需求的前提下,研究了集装箱班列调度问题,以最大化同步转运的集装箱箱数为目标,提出了相应的混合整数规划模型.由于该问题的复杂性,本文提出利用突破性局部搜索框架对问题进行求解.该算法依据搜索状态自适应确定扰动类型与扰动幅度,以突破局部最优解对迭代过程的束缚.基于问题的结构特征,提出利用进入离开堆场时间段排序的方式产生初始解,同时重定义了目标函数值增益矩阵的计算方式.算例分析表明,本文所提出的BLS算法较之Gurobi优化器与文献中的BS算法具有明显的求解优势,且明显提高了调度优化的计算效率.该优化方法对于铁路集装箱站场提升运作管理效率具有一定的理论指导意义.未来将公路-铁路联运的转运需求纳入该调度问题中将进一步提升站内作业效率.
猜你喜欢
全面腐蚀控制(2022年9期)2022-11-19
交通科技与管理(2022年9期)2022-05-24
中国航海(2020年3期)2020-12-09
速读·中旬(2018年4期)2018-04-28
集装箱化(2016年11期)2017-03-29
读写算·教研版(2016年10期)2016-06-08
读写算·教研版(2016年6期)2016-03-28
科技与创新(2015年1期)2015-02-04
集装箱化(2014年12期)2015-01-06
集装箱化(2014年10期)2014-10-31
