
基于神经网络与注意力机制的中文文本校对方法①
2019-10-18 06:41郝亚男乔钢柱
计算机系统应用 2019年10期
郝亚男,乔钢柱,谭 瑛
(太原科技大学 计算机科学与技术学院,太原 030024)
自然语言OCR识别后文本错误自动校对,已经引起越来越多的关注.近年来,我国法治建设的快速发展,类型多样的法律案件数量增多.由于实际情况所限制,我国司法机关处理的案件卷宗以纸质卷宗为主,想要在较短的时间内获取有效的信息,较为困难.随着信息技术的广泛普及,我国已逐渐将电子卷宗应用辅助办案系统中.为加快纸质卷宗电子化,电子化过程中采取OCR识别技术.但是由于纸质卷宗的打印质量低或扫描不当等原因,导致纸质卷宗OCR识别效果不好.因此,在电子卷宗应用于后续任务前,需要有效的校对器来帮助纸质卷宗OCR识别后的文本自动校对.
由于中文文本与英文文本特点不同,中文文本校对是在错误文本的字词、语法或语义等来进行校对的.目前,针对字词级的OCR识别后的中文文本校对研究相对比较充分,但在OCR识别后的中文文本还存在许多其他类型错误,这些错误从字词级的角度来看,可能不存在问题,但是不符合当前文本中的上下文语义搭配,例如:“透过中间人向另一方表示无欠债关系.”.其中,“透过”就是不符合文本语义搭配,此处应表示为“通过”.因此,本文主要是研究如何结合语义校对中文文本中的错误.
1 相关工作
在20世纪60年代起,国外就开始对英文文本拼写自动校对进行研究.在研究初期主要是建立语言模型与字典来进行字词级[1-4]的校对.近年来,字词级校对的研究已经较充分,但在真词错误校对时,若不限制给定语境,那文本校对的可靠性就难以保证.因此,学者们在基于语义对文本校对展开进一步研究.
Hirst[5]等在文本校对的计算中加入语义信息,采用WordNet来计算词与词间的语义距离,若词间语义距离较远,则判断这个词是错误的,反之,若发现与上下文距离语义较近的词就可能被作为正确的词.Kissos等[6]是基于OCR识别后的阿拉伯语校对,其采取的方式是通过与混淆矩阵相结合的语料库形成候选数据集;然后对每个单词所提取的特征对单词分类,将候选集中排名最高的单词作为校对建议.Sikl[7]等将校对问题看作翻译问题来解决,把错误文本作为被原语言,纠正文本作为目标语言进行文本拼写纠错.张仰森等[8]提出了一种基于语义搭配知识库和证据理论的语义错误侦测模型,构建三层语义搭配知识库以及介绍了基于该知识库和证据理论的语义侦测算法,有效地进行语义级错误侦测.Konstantin等人[9]提出基于边际分布和贝叶斯网络计算的方法,在一定程度上提高了低质量图像的文档字段OCR识别后校对准确率.陶永才等[10]基于构建词语搭配知识库,综合使用互信息和聚合度评价词语关联强度,进行词语搭配关系校对.Liu等人[11]提出基于注意机制的神经语法检错模型,将解码端视为二进制分类器进行语法检错.刘亮亮等人[12]面向非多字词错误提出基于模糊分词的自动校对方法.姜赢等人[13]提出基于描述逻辑本体推理的语义级中文校对方法,通过描述逻辑推理机来判断提取的语义内容的逻辑一致性,并将检测出的逻辑一致性错误映射为中文语义错误.Xie等人[14]通过具有注意机制的编码器和解码器的递归神经网络来进行字级别的英文文本校对.Yu等人[15]通过语言模型、拼音及字形完成校对工作.
分析以上文献发现,在以往中文文本自动校对的方法中均进行了大量知识的准备工作,知识库的完善程度对校对结果有很大影响.为了减少知识库等相关知识对校对效果的影响,采用深度学习模型的思路完成文本自动校对任务.通过模型的自学习获取词间相关性,来完成文本校对任务,在一定程度上减少了人为干预.模型采用端到端序列模型,在解码端与编码端构成成分的选择上,主要是从时间方面考虑选取了门控循环网络与注意力机制层结合构成,最后通过Dense层和Softmax层完成文本自动校对任务.
2 基于神经网络与注意力机制的校对模型
2.1 门控循环神经网络
长短期记忆网络(Long Short-Term Memory,LSTM)在自然语言处理任务中有着广发的应用,但LSTM在训练耗时长、参数多等问题.研究人员在2014年对LSTM进行优化调整,提出了门控循环神经网络(Gated Recurrent Unity,GRU).
GRU保持LSTM优点的同时又使得内部结构更加简单.GRU由更新门和重置门两个门组成,更新门用于控制前一时刻的隐层输出对当前时刻的影响程度,更新门的值越大说明前一时刻的隐藏状态对当前时刻隐层的影响越大;重置门用于控制前一时刻隐层状态被忽略的程度,重置门值越小说明被忽略的越多.
GRU的结构如图1所示.
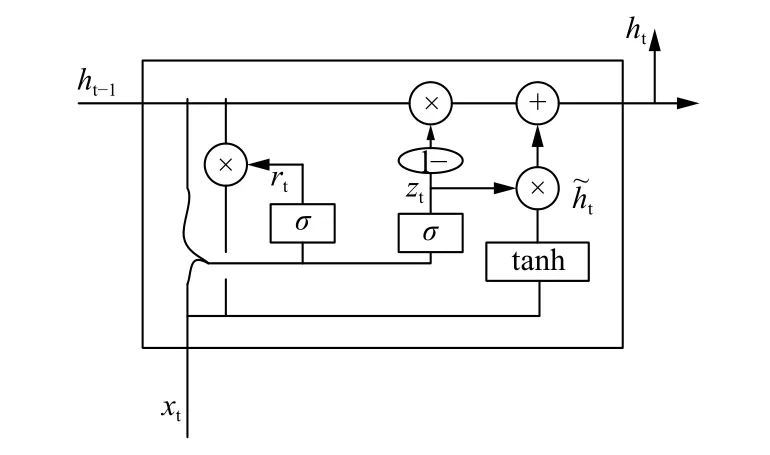
图1 GRU神经元结构图
GRU的更新方式如式(1)至式(5)所示:
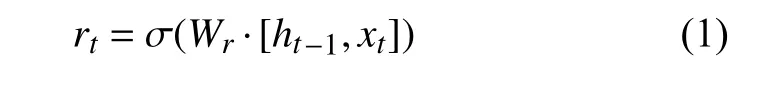

其中,rt和zt分布表示为t时刻的重置门和更新门,、分别表示t时刻的候选激活状态、激活状态.ht-1为(t-1)时刻的隐层状态.
2.2 双向门控循环神经网络(BiGRU)
BiGRU能够同时将当前时刻的输出同前一个时刻的状态与后一时刻的状态产生联系.BiGRU是由单向、方向相反、当前时刻的输出由方向相反的两个GRU输出共同决定的神经网络模型.BiGRU的结构模型如图2所示.
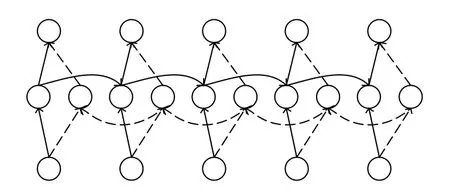
图2 BiGRU结构模型图
在t时刻BiGRU的隐层状态计算公式如式(6)至式(8)所示:

其中,GRU()表示对输入词向量的非线性变换,将词向量编码为GRU隐层状态.wt为t时刻前向隐层状态对应的权重,vt为t时刻反向隐层状态对应的权重,bt为t时刻隐层状态对应的偏置.
2.3 注意力机制
注意力机制就是通过对关键部分加强关注、突然局部重要信息,简单来说就是计算不同时刻数据的概率权重,突出重点词语.多头注意力机制[16]将序列分为key,values和query.多头注意力机制通过尺度化的点积方式并行多次计算,每个注意力输出是简单拼接、线性转换到指定的维度空间而生成的.多头注意力机制结构如图3所示.

图3 多头注意力机制结构图
多头注意力机制层可以视为一个序列编码层,从初始隐层状态到新隐层状态z的计算公式如式(9)所示.
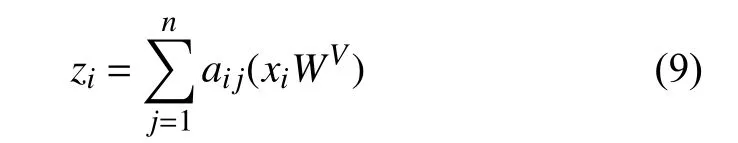
其中,权重系数aij的计算公式如式(10)所示.

其中,eij的计算公式如式(11)所示.
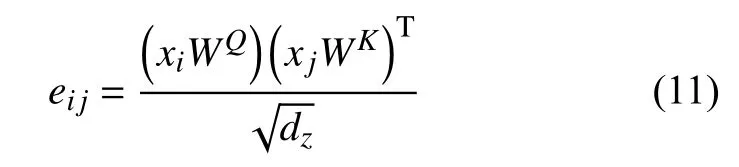
选择了可扩展的点积来实现兼容性功能,从而实现高效的计算.输入的线性变换增加了足够的表达能力.是参数矩阵,.
2.4 基于神经网络与注意力机制的校对模型
对于文本采用生成的方式进行校对,首先句子是由字、词和标点组成的有序的序列,若对句中某个字词进行纠正,则需要通过上下文信息进行推断和生成.在中文文本校对的研究中,仅使用神经网络抓取的上下文特征信息作为语义校对是不够的.上下文信息对当前字词的校对影响力不同,不能作为同一标准对当前字词的校对产生作用.因此,本文构建了一个基于注意力机制的序列到序列的中文文本校对模型.模型引入基于注意力的神经网络,以增强获取词与词间的依赖性的能力.
整体模型架构如图4所示.2.4.1 文本向量化
模型进行文本校对时,首先要将文本向量化.通过一个特定维度的向量代表词,词向量可以刻画词与词在语义上的相关性,并将词向量作为神经网络的输入.

图4 模型架构
将训练语料、测试语料集以及开始标志等所有字词建立一个大小为N的词字典矩阵,N表示字典的大小.建立一个词到词字典的映射关系查找表,将输入的词转换为序号,之后将序号转换为词嵌入向量.
2.4.2 序列到序列端
模型的编码端由BiGRU层构成,文本向量化后的词向量作为BiGRU层的输入.BiGRU层主要目的是对输入的待校对文本进行特征提取.正向GRU通过从左向右的方式读取{输入的待校对}句子X,从而得到正向的隐层状态序列.反向GRU是从右往左的方式读取输{入的待校对句}子X,同样可以得到反向隐层状态序列.将正向和方向隐层状态序列进行连接得到编码端的隐层状态序列h,其中:

模型的解码端是采用单向GRU,每一时刻的隐层状态wi均由前一时刻的隐层状态wi-1和上一时刻的输出yi-1.

注意力机 制层通过计 算输入序列x1,x2,x3,· · ·,xn每个字词对于i时刻输出值yi的影响权重加权求和所得.在生成校对结果时,解码信息融合了输入序列对输出序列每个时刻的概率分布.
2.4.3 基于集束搜索的校对算法
采用集束搜索(beam search)求解校对位置的最优结果.基于集束搜索的校对算法如算法1所示.

算法1.基于集束搜索的校对算法#xi为待校对句子#proba用来记录候选词yi以及得分score,#beam的值设置为N# max_target_len为目标句子的最大长度for i in rang(max_target_len)#predict 根据xi预测所有可能的字词及其得分proba=predict(xi)#生成对所有候选集排序for j in len(x):for yi,score in proba:if score>new_score:new_top=yi new_score=score else:t=[yi, score]new_beam.append(t)#取new_beam中最好的beam个候选集c c=get_max(new_beam)
3 实验结果与分析
校对方法由两个阶段组成:训练和校对.如图5所示.

图5 基本框架
3.1 实验数据
实验采用在网站中抓取的公开法律文书文本整理后的句子作为训练集,样本数据总量为10.7 MB,随机抽取404句作为测试集.例如,“透过中间人向另一方表示无欠债关系.”应为“通过中间人向另一方表示无欠债关系.”.
3.2 建模过程及参数
使用基于Keras的深度学习框架进行模型实现.基于双向门控循环神经网络和注意力模型的方法已在第2节中介绍.首先,将输入句子向量化,作为模型的输入;其次,添加BiGRU和GRU层,并在GRU层后添加注意力机制层;然后,添加双层Dense层,在Dense层采用ReLU激活函数.同Sigmoid激活函数相比,ReLU激活函数能实现单侧抑制[17],能够有效防止过拟合.因此,在实验中选取ReLU激活函数;最后,构建Softmax层对文本进行校对,作用是将输出转变成概率,通过输出的概率向量结合词典反向映射获得当前时刻的输出词.
在解码时,“GO”表示一个句子的开始标志,“END”表示一个句子的结束标志,“PAD”为补充长度的符号.“GO”和“END”在解码器端作为开始解码和结束解码的标志,并一次生成一个字词直到遇到结束标志符号.
训练模型使用Adam优化[18],词向量维度为128,每层神经元个数设置为128,loss函数采用categorical_crossentropy.
3.3 实验评价标准
本文采用准确率(P),召回率(R)以及F0.5值作为实验的评价标准.准确率反应校对结果的准确程度,召回率表示校对结果的全面性,F0.5值为准确率和召回率的综合评价的指标.

3.4 实验结果分析
采用未加注意力机制的序列到序列模型做为基线模型(baseline),实验将本文提出的模型(BiGRU-AGRU)与基线模型以及其他模型进行对比,在同一数据集上进行训练和测试,得到的中文文本校对的实验结果如表1所示.
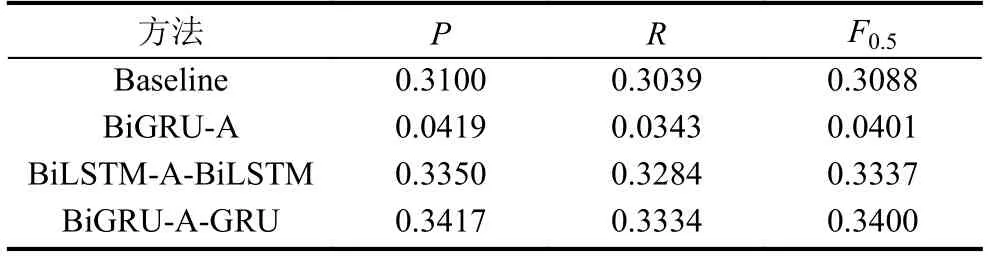
表1 基于不同校对方法的结果
从表1中可以得到,本文提出的模型在语义方面的中文文本校对的完成情况好于基线方法,其准确率、召回率、F0.5值均有一定的提高.这些文本校对效果的提升主要由于BiGRU-A-GRU模型增强了对词间语义关系的捕捉能力,同时该模型减少了因错误侦测产生的影响.
测试集对应最高准确率时的迭代时间为模型的迭代时间,如表2所示.

表2 模型迭代时间对比
BiGRU-A-GRU模型与BiLSTM-A-LSTM模型相比较,均采用了Attention层,区别是一个采用了BiGRU层一个采用了BiLSTM层,表2可以看出在模型迭代时,BiLSTM-A-LSTM模型迭代用时更长.
总之,通过表1,表2及图6可以得知:在本数据集上,BiGRU-A-GRU模型优于BiLSTM-A-LSTM模型,因为BiGRU相比BiLSTM收敛速度快,参数更少,在一定程度上降低了模型的训练时间,Attention层在校对过程中能对句子中关键部分加强关注,突出相关联的词语完成校对任务.
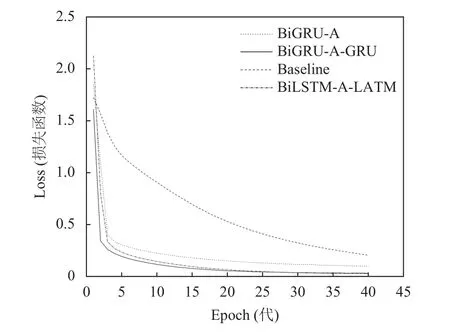
图6 模型训练损失率变化曲线
4 结束语
本文提出一种基于神经网络与注意力机制的中文文本校对方法.将注意力机制引入文本校对任务中,捕捉词间语义逻辑关系,提升了文本校对的准确性.实验证明,深度学习模型中引入注意力机制能够提高中文文本自动校对的准确性.
中文文本词语含义的多样性,对语义错误的文本校对的发展有一定的阻碍性.在未来工作中,将寻找能够提高模型学习词间语义关系的途径,进而更好地完成文本自动校对任务,并且采用对系统的计算和开销等影响较小的方法.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
环球人物(2022年4期)2022-02-22
北京航空航天大学学报(2021年4期)2021-11-24
小资CHIC!ELEGANCE(2021年32期)2021-09-18
软件(2017年6期)2017-09-23
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
小学阅读指南·高年级版(2014年2期)2014-05-27
