
基于电子病历的肺癌诊断决策树算法①
2019-10-18 06:41冯云霞
计算机系统应用 2019年10期
冯云霞,张 润
(青岛科技大学 信息科学技术学院,青岛 266061)
1 引言
肺癌是全球亟待解决的危害生命的最常见癌症之一.2017年,世界卫生组织的最新数据表示,仅仅2015年肺癌导致了约170万人死亡[1].研究表明,肺癌早期患者的治愈率较高,而肺癌晚期患者的存活率仅为15%[2].主要原因是由于肺癌早期症状不明显,而中后期发病速度快,临床诊断时大多为中晚期[3].因此,早期检测成为肺癌诊断研究的重点之一.
随着现代技术的快速发展,计算机技术运用在医学领域的越来越多.特别在疾病预防、诊断、治疗与检测方面,数据挖掘技术发挥着重要的作用.有基于主成分分析的GEP算法[4]、基于遗传算法的GA-SVM模型[5]及GA-BPNN模型[6]、基于粗糙集理论的决策树模型[7]、模糊聚类FCM模型[8]、基于粒子群算法的支持向量机模型[9]等.本文将主成分分析法与C5.0算法相结合,用于早期肺癌辅助诊断.主成分分析法是统计学中的方法,将复杂的原始数据提取出较为简单的数据,并且这些简单数据能够最大程度地代表原始数据的特点,从而达到简化属性的目的.决策树是常用于疾病预测的一种算法,决策树是基于信息论方法的对数据进行分类的数据挖掘经典算法,通过训练大量数据进行分类,从中寻找疾病与患者的生活习性、发病症状、检验数据之间潜在、有价值的信息.
2 相关理论基础
2.1 主成分分析法相关原理及基本思想
主成分分析(Principal Component Analysis,PCA)于20世纪初首次运用在数学领域中,Pearson通过运算将具有很多特征的属性降低到几个具有代表性的属性,这些属性既能克服单一属性不能完全反映数据信息的缺点,又能克服无关属性过多而造成的干扰[10].基本思想是:主成分分析法能将复杂的原始数据提取出较为简单的数据,并且这些简单数据能够最大程度地代表原始数据的特点,从而达到简化属性的目的.
通常在数据选取后,需要进行特征选择,特征的选取若维度过高,需要通过数学变换来将特征对应到低维度空间.对于要处理的肺癌电子病历中的属性,各种属性混杂可能多达上百个,而其中有些属性可能是关键,另一些属性可能没有用,并且还能影响到决策树模型的构建.基于此,选用主成分分析来约简属性,降低特征维度,提高决策树模型的准确度.
主成分分析中常用的几个公式:
(3)样本x、y的协方差:

PCA具体原理可有图1看出,经过坐标变换y1和y2方向作为新的基底,由于y2方向上数据的方差较小,降低数据维度的时候可以保证不会太多的损失信息,因此这一维度的数据可以丢弃.这样重构的坐标系得到的数据与原数据之间的误差降到最低.经过PCA后,新的维度间的数据是线性不相关的,并按照方差由大到小排列选取主成分.

图1 PCA原理
2.2 决策树相关理论
决策树算法是在信息论基础上分类和预测的重要技术之一,采用自顶而下的递归算法建立一棵类似于自然界中的树结构,包括根节点、分枝、叶节点组成[11].决策树产生的标准依据信息熵的计算,通常包括两步:(1)开始所有属性都在根节点,然后根据信息熵的计算决定分裂属性,用不同的测试数据进行分割.(2)决策树的剪枝是为了弥补决策树过拟合现象,通过删除异常的孤立点和噪音,一般分为前剪枝和后剪枝[12].
在ID3算法中,采用最大信息增益作为分支判定.而ID3算法由于不能对连续数据处理,因而C4.5算法进行了改进采用信息增益率作为分支判定,可以对连续数据处理.C5.0算法在C4.5算法的基础上提高了内存和使用效率.
在决策树算法总,计算分裂属性的重要指标有如下3个:
已知数据集M,按照离散度C分成n个特征子集,n个特征子集包括A1,A2,···,An.
(1)信息熵ENTROPY(M):是指数据M中不同特征属性数量的分布均匀程度.若分布不均匀,则信息熵偏低;分布较为均匀,则信息熵较高.其公式如下:

其中,Pi指的是特征属性A在数据集M中所占的比例.

(2)信息增益(info_Gain):信息增益是形容数据集M中,特征属性X在M中的复杂程度.表示为分支前M的复杂程度-分支后A的复杂程度,若信息增益值越大则说明节点的复杂程度高;反之,则节点复杂程度低.其公式如下:

信息增益是ID3算法中属性分支的衡量标准,但其缺点是更倾向于特征属性最多的那类,因此,C5.0算法采用信息增益率来选择属性分支.
(3)信息增益率(info_GAINRATIO):信息增益率是C4.5算法以后所运用的标准,表示信息增益与分裂信息之间的比值.在决策树模型中,某个节点的信息增益率越大,代表该属性的分支效果越好.其公式如下:
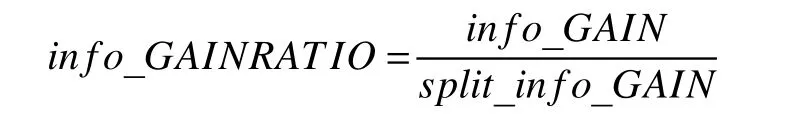
其中,split_info_GAIN是分裂因子,表示分支后的子结点的信息增益,其计算公式如下:

3 基于优化决策树算法的早期肺癌辅助诊断模型
3.1 基于主成分分析法的特征简化
由于决策树模型具有不稳定性,数据集稍微改动,则会造成决策树的完全改变.因此,在选取输入的训练属性要格外注意,若数据的本身属性过多,有与肺癌不相关的属性存在,那么决策树模型可能选择无关属性分类,造成结果不准确.因此,我们在建模之前进一步对数据降维,从而达到简化模型的目的,提取特征属性的主要成分,达到最优模型.在主成分分析法中,最重要的定义是对累计贡献率的设定,若设定过低,则难以达到降维的目的;若设定过高,则造成数据过多的信息损失.另一种是对特征根大于1的属性作为分界点选取合适的属性.
基于主成分分析法的特征降维步骤如下:

输入:电子病历样本集G={x1,x2,xm},降维维数d';输出:属性降维后的样本集.images/BZ_263_1675_1153_1916_1194.png1.病历集取中心化处理:images/BZ_263_1652_1234_1869_1275.png.在这里不需要对数据去中心化,因为在数据预处理中已经对数据标准化,排除数据量纲不同造成的影响.2.求协方差矩阵XXT.3.特征分解法求XXT的特征根和特征向量.∑ images/BZ_263_1290_1579_1453_1604.png5.返回4.满足特征根>1或累计贡献率>0.85的d'个特征值对应的特征向量.images/BZ_263_1390_1621_1632_1663.png
3.2 早期肺癌辅助诊断模型构建
肺癌辅助诊断决策树模型的实现过程:

输入:主成分分析法简化后的病历特征属性.输出:基于C5.0算法的决策树模型.1.对主成分分析法简化后的23个特征属性计算每个特征属性的取值范围.2.如果当前的病历集的特征取值全部相同,则叶子节点即为决策属性.3.否则,计算23个特征属性的信息熵增益;针对连续值,年龄、日均吸烟量等2个特征求其离散值和基于决策属性的信息增益率;针对离散值,剩下的性别、咳嗽咳痰等特征,直接求其基于决策属性的信息增益率.4.选择信息增益率最大的特征作为决策树模型的节点,最后将此特征从条件属性中删除.5.按照特征的取值划分样本集,并返回到步骤2.6.返回决策树模型T.
3.3 模型剪枝
决策树容易造成过拟合现象,对训练数据诊断结果良好,对测试数据却没有较好的诊断效果.因此,本文针对决策树算法的不足,对其进行优化处理,通过剪枝操作解决过拟合现象.模型优化的思路:对生成的决策树T0,计算每个非叶子节点α值,根据设定的最小α值进行剪枝,分别得到T1,T2,···直到只有根节点Tn;在测试集上,根据实际的误差值分别对这n个决策树进行估计,选择损失函数最低的树Tk作为优化后的决策树.
决策树优化过程伪代码如下:

输入:决策树 T, α.输出:剪枝后的决策树Tk.1.计算每个非叶子节点α值.2.对系数α最小的节点进行剪枝得到Ti (i=0,1,…,n).3.计算以r节点为根的子树Tr剪枝前后的损失函数.4.若 C1≥C2,则剪枝.images/BZ_264_958_923_1163_952.png5.重复步骤1~4直到只有根节点Tn停止,得到剪枝后的决策树系列.6.在测试集上,根据实际的误差值分别对这n个决策树进行估计,选择损失函数最低的树Tk作为优化后的决策树,返回决策树Tk.images/BZ_264_218_1082_389_1115.png
4 实验验证
4.1 数据预处理
本实验所使用的数据均来自本市某三甲级医院的肿瘤科电子病历,数据选取2017年3月至2018年9月的患者病历,该电子病历记录患者从入院的身份数据、主诉、医嘱、检验数据到出院的各项数据.首先要对数据进行预处理,包括对数据合并、数据结构化、数据清洗、以及数据转换等步骤.本次实验共选取肺部肿瘤患者共28个属性,包括性别、年龄、吸烟史、肺部疾病等信息进行分析,预处理后的数据如图2所示.
(1)数据合并:从医院His系统导出来的电子病历分为医嘱、诊断、检验等模块,需要将根据患者唯一的PID标识进行关联,将患者的诊断、主诉、既往史、检验数据同步,所以运用excel表格对数据集成合并处理.
(2)数据结构化:使用ICTCLAS作为分词工具,建立医学用户词典,提取按词频分类结果的结构化属性表.
(3)数据清洗:提取特征属性的结构化电子病历存在异常数据、缺失值数据[13].缺失值处理中,对数值型数据,选择均值代替;对字符型数据,选择众数代替.存在大量缺失值的数据,选择直接删除.异常值处理中,计算出每类数据所占比例,并画出正态分布,对于所占比例过低的数据判断为异常值[14].异常值的处理方式与缺失值相同.
(4)数据转换:在进行数据挖掘前,要对连续性数值离散化处理.以吸烟史为例,从未吸烟为0,1至10年为1,10至20年为2等.

图2 数据预处理
4.2 实验过程
(1)传统决策树模型:首先运用C5.0算法对预处理后的数据进行建模,将结果保存下来.
(2)运用主成分分析法对数据进行降维处理,将结果保存下来,再对降维后的数据用C5.0算法建模,得到实验结果.
4.3 实验结果
4.3.1 两种主成分分析特征降维结果
经过主成分分析算法降维后,本文根据主成分特征根大于1以及主成分累计贡献率大于85%来提取特征:
(1)基于Kaiser标准化的正交旋转法提取特征根取值大于1的属性,旋转18次后迭代收敛,如图3所示.共有14个特征根属性大于1,因而选取14个主成分属性,分别为:结节面积、毛刺征、分叶征、D-二聚体、癌胚抗原、神经元特异烯醇化酶、细胞角蛋白19片段、钠、氯、总蛋白、咳嗽咳痰、胸闷憋气、年龄、咳血.这14个属性总共代表70.604%的数据信息量,说明该14个属性作为建模输入值对结果影响最大.

图3 提取主成分特征根取值大于1的属性
(2)基于Kaiser标准化的正交旋转法提取主成分累计贡献率大于85%的属性,旋转13次后迭代收敛,如图4所示.共有23个特征根累计贡献率86.313%,因而选取23个主成分属性.
由于两种主成分特征简化方式来看,第一种提取特征根大于1的主成分仅能代表70.604% 病历集的信息,而第二种特征根累计贡献率提取的主成分能代表86.313% 病历集的信息.因此,在简化特征的同时尽可能减少数据信息的损失,我们选取第二种方式简化特征.采取主成分累计贡献率的PCA方法与C5.0算法相结合,在不降低模型的精度同时又能防止决策树算法的维度过高,从而避免过拟合现象.4.3.2 决策树构建结果

图4 提取主成分累计贡献率大于85%的属性
采用基于主成分累计贡献率特征降维的C5.0建模,训练集60%,测试集40%.生成的决策树模型如图5所示.模型剪枝的置信因子设定为0.75,建模运行时间仅用了0.32秒.其中,按照变量重要程度由大到小依次为结节面积、分叶征、癌胚抗原、中性粒细胞等,这与综合多篇文献的临床诊断指标相吻合.而结节面积对于整个模型来说重要程度最高,这也说明结节面积对于模型是最重要的变量,它的具体指决定着模型判断的结果,当结节面积越大,就越有可能患癌.其他的变量相对影响程度较小,但对模型也有一定影响.
两种模型实验准确率结果对比如表1.通过对算法执行时间及三组诊断准确率数据对比,传统C5.0决策树模型的测试集相对来说诊断精度较低,而PCAC5.0模型的测试集效果较好,说明优化后的模型不存在训练过度拟合的现象.因此,我们能得出结论,基于PCA-C5.0算法构建的肺癌辅助诊断模型提高了诊断准确率,并在执行速度上也有一定提高.

图5 生成的决策树

表1 PCA-C5.0算法与C5.0算法比较
5 结束语
影响肺癌发病的原因是多方面的,各种因素之间具有不确定性,肺癌的发病与发病症状、检验数据之间存在着复杂的关系.本文提出的基于肺癌电子病历的早期辅助诊断方法,结合了PCA算法和C5.0算法的优点.针对C5.0算法的存在模型不稳定和过拟合的不足将其进行优化,结合主成分分析法的优势,实现早期肺癌辅助诊断,模型在测试及的准确率达到了87.89%.主成分分析法以数学理论为基础,在保证特征信息的前提下,能够去除数据之间的冗余性,减少噪音影响,提高数据集的质量.本文通过建立的优化决策树模型能够适用于肺癌早期辅助诊断,挖掘肺癌与电子病历中的发病症状、实验数据之间的潜在信息,适用于肺癌临床诊疗.
猜你喜欢
心理学报(2022年10期)2022-10-12
湖北大学学报(自然科学版)(2021年5期)2021-08-20
北京航空航天大学学报(2021年6期)2021-07-20
作文评点报·低幼版(2020年25期)2020-07-23
科学与信息化(2019年28期)2019-10-21
西江文艺(2017年15期)2017-09-10
科学与财富(2016年32期)2017-03-04
中国社区医师(2016年8期)2016-12-20
办公室业务(2013年21期)2013-08-15
决策与信息·下旬刊(2013年1期)2013-03-11
