
优化K 均值聚类在冗余特征剔除中的应用研究∗
2019-11-29 05:14李丽敏温宗周宋玉琴
计算机与数字工程 2019年11期
李丽敏 温宗周 宋玉琴
(西安工程大学电子信息学院 西安 710048)
1 引言
随着信号处理技术在机械故障诊断领域的应用越来越频繁,许多隐藏在振动信号中的特征被挖掘出来,为精确地诊断某种机械故障提供了研究基础[1~2]。近年来,由信号处理技术提取的特征包括时域特征、频域特征和时-频域特征。时域特征如偏度、峭度和根均值方差等,可以反映信号在整个周期内的变化情况[3];频域特征如傅里叶变换和快速傅里叶变换,能够获得振幅谱和功率谱的分析结果[4];时频域特征如小波包能量和希尔伯特边缘谱能够在时域和频域共同交叉的方面分析信号[5]。上述特征可以通过组合为高维特征集合共同决策当前的故障类型,能够提高诊断精度,但由此带来的严重问题是随着特征的增多,计算复杂度越来越大,训练分类器的难度增加,而且训练出来的分类器鲁棒性变差。因此目前,怎么样平衡计算复杂度和诊断精度之间的矛盾成为研究热点。
为了减少计算复杂度,传统的方法是直接减少特征的维数,相关的方法包括局部线性嵌入(LLE)[6]、局部保留投影(LPP)[7]和主成分分析(PCA)[8]。这些方法通过空间映射降低特征的维数,但在本源特征集合中,有些特征本身就对诊断起到相反的作用,对于得到诊断结果是不利的,这也会降低诊断精度,特别是当使用支持向量机方法(SVM)[9]用于机械故障诊断的分类器时,对特征的依赖性很强,因此特征集合的优劣影响SVM分类器的性能。
为了解决上述问题,本文从特征集合本身出发,采用基于K 均值聚类[10]的冗余特征剔除方法,将对诊断作用不大或者相反的特征剔除掉,保留最有利于诊断的那些特征,剔除冗余特征后的特征集合再用于训练分类器时,即能保持原多个特征用于诊断时对精度的提高,同时能够降低时间复杂度,有效地平衡时间和精度之间的矛盾。
2 基于特征权值优化的K均值聚类
K 均值聚类能够将包含n 个数据的数据集合X={X1,X2,…,Xn}分 割为k 类,其中Xi=(xi,1,xi,2,…,xi,m)表示每个数据被提取了m维特征[11~14]。
K均值聚类的目标函数如下:

式(1)中,U(n*k 维)是由优化上述目标函数计算出的分割矩阵,U 中的元素ui,l=1 表明第i 个数据属于l 类。 Z={Z1,Z2,…,Zk}是由K 均值聚类计算出的聚类中心,d(xi,j,zl,j)是第i 个数据和第j 个数据之间的距离,可由式(2)计算得出。

式(1)的约束条件为式(3)。

式(3)的约束条件指数据集X 中的每个数据只能归属于1 类。优化式(1)的目的是通过最小化目标函数P求解出U和Z。
为了计算出每个特征的权值,本文中,在K 均值聚类的目标函数P 中加入了这个权值W,因此获得了一个新的K均值目标函数:
其中β 为ωj的系数。
通过式(4),可以计算出K 均值聚类出的每个特征的权重。
3 基于K 均值聚类的冗余特征剔除在SVM 多分类的机械故障诊断中的应用
通过K 均值聚类方法获取到所有特征的权值后,剔除冗余特征的步骤如下:
1)设置权值阈值η;
2)将求出的每个权值wi(1 ≤i ≤m)与设置的阈值η 比较;
3)如果wi≤η,则剔除该特征;
4)如果wi>η,保留该特征;
5)将数据集合按照保留下来的特征重新组合。
SVM 的基本思想是通过非线性变化将数据从原始空间映射到高维特征空间,从而找到最优的分割超平面,该超平面拥有最大的边界从而将数据集合进行分类。一般的SVM 分类器主要用于1 对1或者1 对多的分类情况,但现实情况是,同一条件下可能有各种故障都需要分类出来,因此本文针对该种情况,选择1 对多的分类器。具体操作步骤如下:
1)采集机械设备的振动信号,提取特征,按照序列排序;
2)从上述信号中取部分信号xi(xi∈RD,i=1,2,…,l)作为训练样本,同时为这些样本设置训练标签;将xi和yi输入给SVM 的目标函数,如式(5)所示。

通过解式(5),可以获得权值ω ∈Rn,b ∈R,松弛变量ξi和惩罚因子C。
上述函数的约束函数如式(6)所示。
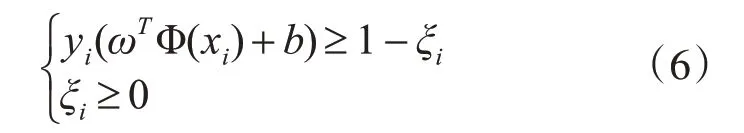
由此,xi被映射到高维的特征空间,在这个特征空间中,找到优化的分类超平面,决策函数如式(7)所示。

3)该函数设置的初衷是用于二分类的,因此当用于K 分类时,具体做法是将K 个二分分类器组合起来。
4 实验验证与分析
为验证本文方法的有效性,利用凯斯西储大学轴承实验室的实验数据作为测试数据[15]。选择轴承的型号为6203-2RS JEM SKF,选取其中的正常状态、内圈故障和外圈故障的振动加速度数据,这些数据采集于电机运行于1797r/s 的速度下,内圈故障和外圈故障的损失程度为0.1778mm,采样频率为12kHz,如图1所示,为本文选取的三组测试数据原始采样值的曲线,横坐标(Sample point)表示采样点,纵坐标(Amplitude)表示每个采样点的振动幅值。
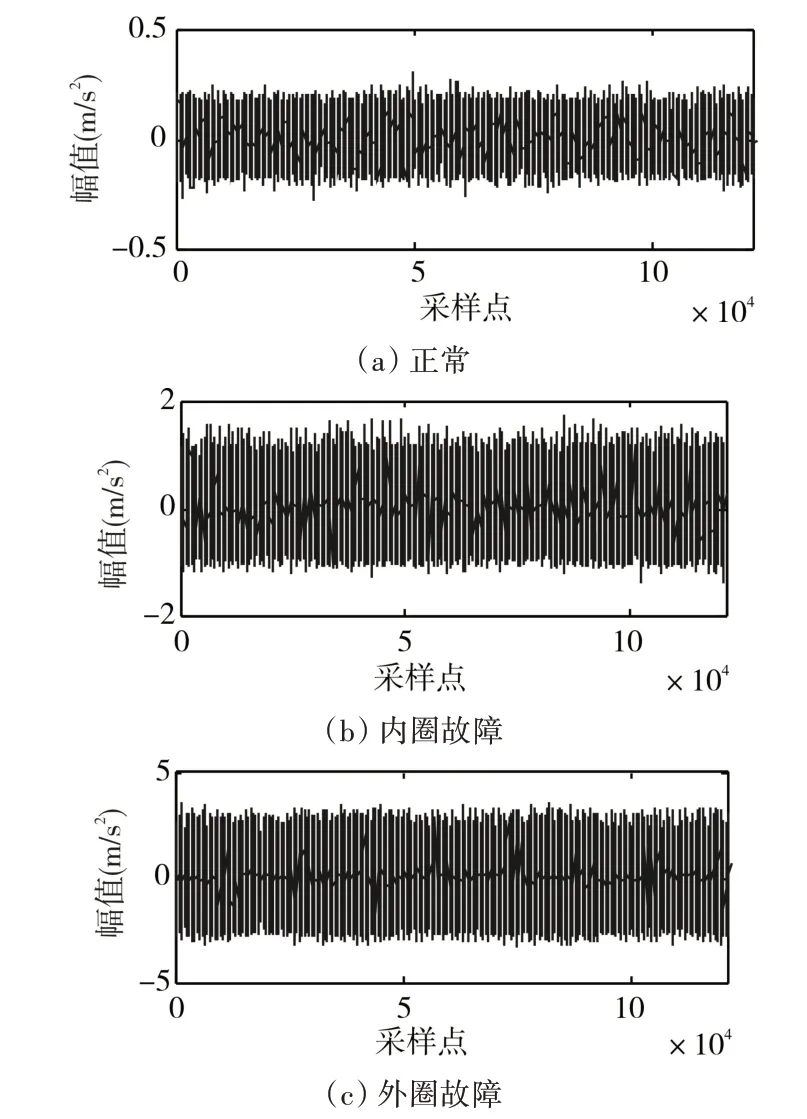
图1 三组用于测试的振动加速度原始信号曲线
对三种原始振动信号分别提取了32 种特征,这些特征既包含时域特征、频域特征,还包含时频域混合特征,利用第2 节中所述方法,计算出每种特征用于3分类时的权值,即贡献率,结果如下:


根据上述计算出的权值,当分别将阈值设置为 η(1)=4.9386e-06 ,η(2)=5.6806e-05 ,η(3)=0.0002,和η(4)=0.0034 时,会分别剔除掉2 个、7个、12个和22个冗余特征,则剩余有用特征分别为30 维、25 维、20 维和10 维。为比较本文方法与一般的LLE、LPP 和PCA 方法的性能,对相同的振动数据的32 维特征,利用上述三种方法也分别选择出30维、25维、20维和10维特征。
利用SVM 多分类器对每种故障的100 个多维故障数据样本进行训练,得到多分类器;将三种类型数据的50 个样本点混合后输入给训练好的SVM多分类器中,观察诊断误差和诊断所需时间。如图2所示为本文方法剔除冗余特征后,剩余25维特征时,与利用LLE、LPP和PCA提取25维特征后,进行多分类的结果,从图中可以直观看出,本文方法在对正常、轴承内圈故障和轴承外圈故障进行分类时,分错的数据点仅有1 个,说明本文方法优于其他三种方法。

图2 本文方法与LLE、LPP和PCA方法在降维后利用同一多分类器进行故障诊断的性能比较
为全面验证,其他相关实验开展了对30 维、20维和10 维特征下故障诊断性能的比较,比较结果如表1所示。

表1 本文方法与LLE、LPP和PCA方法在分类准确率性能方面的比较
表1 所示,本文方法在4 种维度下,采用SVM多分类器诊断的结果表明,本文方法的诊断准确率均高于其他三种方法,甚至在利用本文方法将特征维数降低到10 维后,其诊断准确率仍高于其他三种方法,从而验证了本文所提方法的有效性。为验证本文方法在解决时间复杂度和诊断准确率之间的矛盾所做工作的有效性,冗余特征剔除后,进行SVM 多分类时,记录了其运行时间。前提条件为,采用计算机主机频率为2.5GHz。比较结果如表2所示,很明显维度越低,时间耗费越小,32 维和10维之间时间消耗相差约4倍。

表2 时间复杂度性能比较
综合分析表1和表2的结果,可以总结出,基于K 均值聚类方法的冗余特征剔除方法,当采用SVM多分类器进行故障诊断时,诊断准确率优于PCA、LPP和PCA 方法,同时冗余特征剔除带来的最直观的性能提升是时间复杂度大大降低,但没有影响诊断准确率,因此本文达到了平衡时间复杂度和诊断准确率之间的矛盾的目的。
5 结语
本文提出了一种基于优化K 均值聚类的冗余故障特征剔除方法,针对旋转机械的轴承故障诊断,有效地解决了多维特征造成的时间复杂度高的问题,同时通过与其他常用三种方法比较发现,本文方法并没有降低诊断准确率。通过对凯斯西储大学轴承实验室的测试数据进行实验验证,结果表明本文方法有效地改善了多维特征用于诊断时,时间复杂度和诊断准确率之间的矛盾,为信号处理技术更好的服务于机械故障诊断领域提供重要参考。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
电子产品世界(2022年4期)2022-04-21
社会科学战线(2022年2期)2022-03-16
计算机系统应用(2021年2期)2021-02-23
成都信息工程大学学报(2021年6期)2021-02-12
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
计算机测量与控制(2019年4期)2019-05-08
科技视界(2016年1期)2016-03-30
