
预测模型法在油田二次开发中的应用
2020-05-19 09:15仝可佳张文静
云南化工 2020年4期
杨 燕,仝可佳,张文静,冯 磊
(1.西北大学大陆动力学国家重点实验室,陕西 西安 710069;2.西北大学地质学系,陕西 西安 710069;3.中国石油塔里木油田分公司勘探开发研究院,新疆 库尔勒 841000)
自1984年翁文波院士发表泊松旋回模型以来,预测模型方法逐渐成为油气田可采储量计算的重要方法[1-2],陈元千教授[3]按预测模型建立的基础和描述的现象将其分为两类,其中广义翁氏模型、威布尔模型、瑞利模型、HC模型(胡陈模型)及对数正态分布模型属于单峰周期模型即第Ⅰ类广义预测模型[5];HCZ模型(胡陈张模型)及Logistic模型(哈伯特)模型属于累积增长模型即第Ⅱ类广义预测模型,常用预测模型及求解方法可参考相关文献。在应用此类方法进行可采储量预测时,发现其存在以下两个不尽人意之处,其一不同模型对同一组数据的拟合程度相当,这将涉及如何进行模型选择的问题;其二,若重大调整措施或开发方案实施时间较短,以“年”为单位进行评价时,因有效数据点较少导致预测结果可靠性差或不满足行业标准对有效数据点的最少要求。
1 HC与HCZ模型
1) HC模型(胡陈模型)

2) HCZ模型(胡陈张模型)
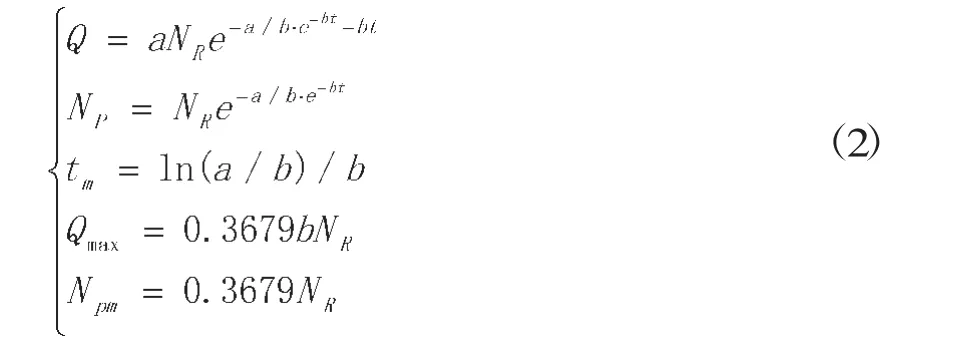
其中:a,b为系数,无因次;t为开发时间,一般取年;Q为预测年产油,104t/a;Qmax为产油量峰值,104t/a;tm为产油量峰值出现时间,年;Npm为tm对应的NP;NP为预测累产油,104t;NR为预测可采储量,104t。
2 预测模型的应用于扩展
2.1 特征参数组的应用
特征参数组主要用于预测模型对历史数据的拟合方面。通过实际资料获得油气藏的实际特征参数组 (tm,Qmax,Npm)Reservoir,可通过油藏年产油及累产油曲线的峰值tm及峰值对应的年产油及累油确定。
对于选择预测模型,通过不断调整线性试差直线段的范围获得特定模型的特征参数组 (tm,Qmax,Npm)model,若模型特征参数组与油藏实际特征参数组的四个参数均接近且线性试差具有较高的精度,则可认为历史数据拟合可靠,从而通过特征参数组反算的a,b,c也可靠即预测模型可靠,可用于油气藏年产油及累产油的预测。
2.2 特征参数组的求解与扩展
油气藏的开发是一个有限体系的增长问题,同时其累积产量也将最终趋于一个稳定值即可采储量NR。若油气田开发已经进入中期,则可用特征参数组 (tm,Qmax,Npm)描述,该参数组可通过油气田的年产量与累产量曲线获得。以M油田为例,则tm为8.5年,Qmax为115.4万吨,Npm为652.8万吨。
必须强调,若生产数据的单位不是年,则计算的特征参数组 (tm,Qmax,Npm)必须按 (3)式换算,否则无法判断特征参数组的拟合情况,其中i,j,k 取值见表 1。

其中:tm、Qmax及Npm为以“年”为单位计算的特征参数;tm’、Qmax’及 Npm’为以“半年”或“月”为单位计算的特征参数。
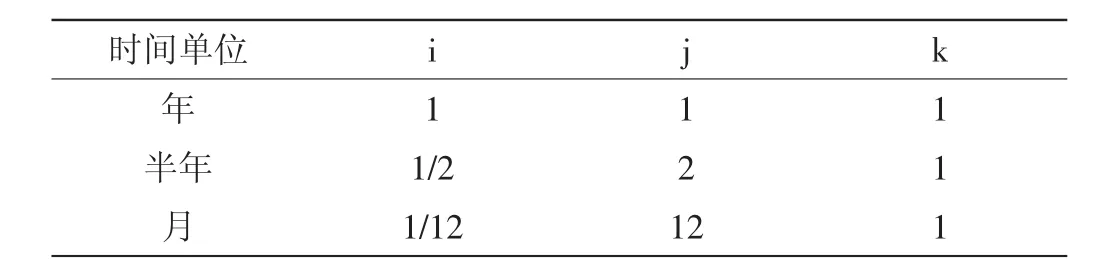
表1 预测模型法特征参数换算表
3 计算实例
1988年LN2井试油发现M油田,1993年开始全面注水开发,2011年以后进入二次开发阶段。因二次开发的时间较短,若按年选取则有效数据仅4个点,为此选择按半年作为计算单位,分别选取广义翁氏模型、HC模型、对数正态分布模型、威布尔模型、瑞利模型、HCZ模型及Logistic模型等7个模型对M油田生产数据进行拟合不同模型的拟合特征参数组及预测结果见表2。将各模型计算的特征参数组 (tm,Qmax,Npm)model与油田的实际特征参数组 (tm,Qmax,Npm)Reservoir进行对比,对比发现Logistic模型预测效果较差,HCZ模型的拟合效果最好,其次是HC模型,其余模型较差。可将HCZ模型及HC模型预测结果的平均作为M油田预测可采储量,按预测可采1761×104t计算,提高采收率幅度约2.73%。
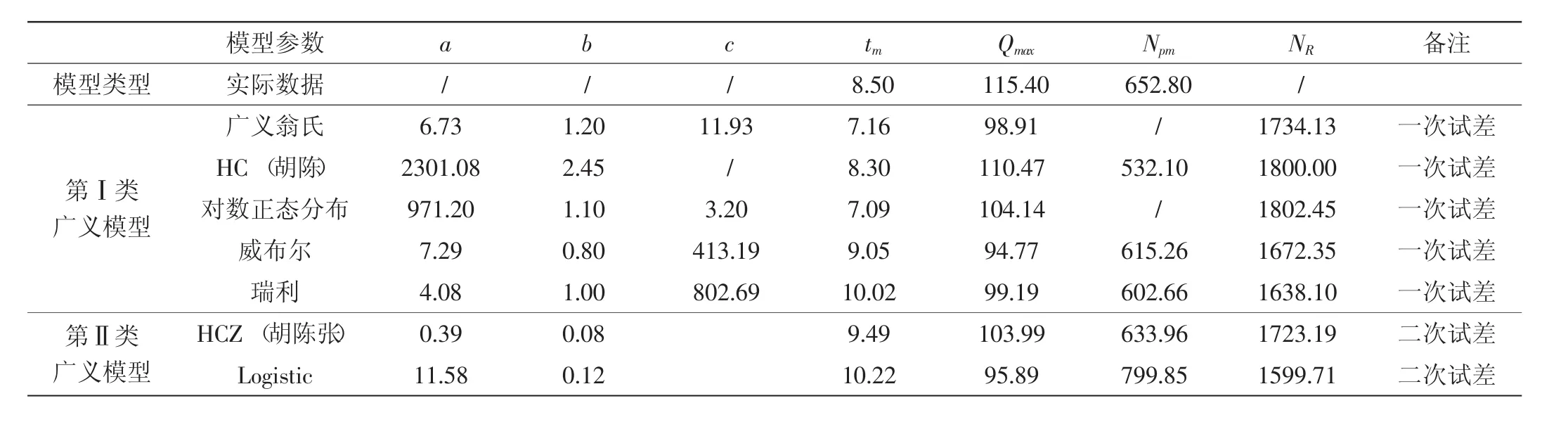
表2 不同预测模型拟合参数及特征参数表
4 结论
1)M油田计算实例表明,不同的预测模型均可实现对实际生产数据的较好拟合但拟合结果差异较大,仅HCZ模型与HC模型的特征参数组与油田实际的特征参数组接近,推荐使用以上两个模型预测M油田可采储量。2)预测模型特征参数组的数值与计算数据的单位有关,给出以“年”、“半年”为单位时特征参数组的换算系数,M油田实例表明该换算关系式可靠的。3)HCZ模型与HC模型预测结果表明M油田二次开发提高采收率幅度为2.73%。
猜你喜欢
空间科学学报(2020年1期)2021-01-14
云南化工(2020年2期)2020-04-25
中国交通信息化(2019年12期)2019-08-13
制造技术与机床(2019年7期)2019-07-22
模具制造(2019年3期)2019-06-06
制造技术与机床(2017年11期)2017-12-18
制造技术与机床(2017年11期)2017-12-18
中国交通信息化(2017年8期)2017-06-06
汽车零部件(2014年5期)2014-11-11
中国科技信息(2012年9期)2012-10-26
