
AABC算法优化ELM的心脏病辅助诊断
2020-05-23 10:05周孟然周悦尘闫鹏程
计算机工程与设计 2020年5期
周孟然,周悦尘,闫鹏程,胡 锋
(安徽理工大学 电气与信息工程学院,安徽 淮南 232001)
0 引 言
有数据显示[1],目前我国的心脏病患者超过六千万人,预计未来的发病率仍将持续走高,心脏病的及早发现和诊断,对于心脏病的治疗有重要意义。但是,部分心脏病检查手段会给患者带来创伤[2],诊断阶段严重依赖主治医师的临床经验,具有一定的随意性。随着计算机技术和机器学习理论的不断发展,计算机辅助诊断技术相比于传统诊断方法的优势日趋明显,在心脏病计算机辅助诊断领域,很多学者的研究较深且成果显著[3,4]。
极限学习机(extreme learning machine,ELM)由Huang等[5]提出,由于没有梯度下降等迭代过程,收敛速度更快。但是,ELM的隐层输入权值和偏置是随机确定的,容易出现分类预测精度较低的情况。为了解决该问题,不少学者采用群智能算法对ELM的隐层输入权值和偏置进行寻优的策略[6,7],ELM的分类预测性能均得到了较大改善。
人工蜂群算法(ABC)是一种新型群智能算法[8],相比于其它群算法,ABC在全局性上表现更好,但也存在局部搜索能力弱、搜索后期收敛速度慢等缺陷。针对这些缺陷,本文将最优解和次优解引入搜索机制中并且采用自适应算子μ对二者的权值进行动态调整,改进了跟随蜂概率选择机制,得到自适应人工蜂群算法(AABC),构建了基于AABC算法优化ELM参数的分类模型并结合自适应遗传算法的特征选择应用于心脏病的辅助诊断研究。
1 基于自适应遗传算法的特征选择
遗传算法(GA)作为一种群智能算法,其种群一般由二进制编码的个体组成,可直接代表一组特征子集的选定,相比于PSO等寻优算法需要对特征设定阈值或者权值来说,更加直接和简单。但是,由于其交叉概率Pc和变异概率Pm是预设常量,在种群进化后期优秀个体往往容易被破坏,有较高的“早熟”风险。针对这一问题,本文采用自适应进化机制[9]对Pc和Pm进行调整,使之能够适应每一代种群不同的进化情况,改进后的Pc和Pm如下所示
(1)
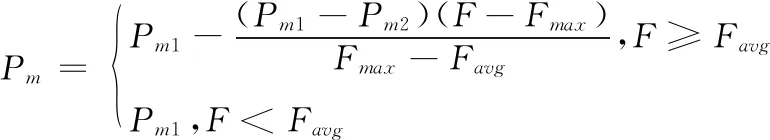
(2)
式中:Pc1和Pc2分别为最大交叉率和最小交叉率;Pm1和Pm2分别为最大变异率和最小变异率;Fmax为当前种群的最大适应度值;Favg为当前种群的平均适应度值;Fbetter为参与交叉操作的两个个体的较大适应度值;F为参与变异操作的个体的适应度值。
利用AGA进行特征选择的步骤如下:
(1)输入训练样本的特征集合和类别标签集合;
(2)种群初始化,个体维数等于特征数,每个个体由二进制编码随机产生,代表一组特征子集;
(3)计算适应度值,适应度函数采用基于类内类间距离的可分性判据,适应度公式如下
(3)
其中,Ft为当前种群第t个个体的适应度值;tr(Sb) 和tr(Sw) 分别为类间散度矩阵的迹和类内散度矩阵的迹。
(4)进行选择、交叉、变异操作并将当前种群中适应度最大的个体带入得到新种群,判断是否达到终止条件,达到条件则输出最优特征子集,否则,返回步骤(3)继续循环。
2 基于AABC-ELM算法的分类模型
2.1 极限学习机
ELM一般由单隐层前馈神经网络构成,也可拓展至深度网络。ELM算法的数学描述如下:
给定样本集
D={(xi,ti)|xi∈Rd,ti∈Rm,i=1,2,…,N}
(4)
对于含有L个隐层节点的单隐层神经网络输出可以表示为
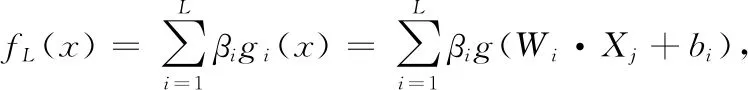
(5)
其中,g(x) 为激活函数,Xj为样本的输入,Wi为隐层输入权重,βi为隐层输出权重,bi为第i个隐层节点的偏置。
ELM的目标是使输出误差最小,即存在βi,Wi和bi,使得
(6)
可以矩阵表示为
Hβ=T
(7)
其中,H是隐层节点的输出,β为隐层输出权重,T为期望输出

(8)
(9)
(10)
其中,H+是矩阵H的Moore-Penrose广义逆。且可证明求得的解的范数是最小并且唯一。
2.2 人工蜂群算法
在ABC中,蜂群包含3种不同分工的蜜蜂:雇佣蜂(employed bees),跟随蜂(onlookers)和侦查蜂(scouts)。雇佣蜂发现食物源并记录食物源信息。跟随蜂根据雇佣蜂携带的食物源信息选择是否跟随。当一个食物源被放弃时,雇佣蜂转变为侦查蜂,随机寻找下一个食物源。
2.3 自适应人工蜂群算法
2.3.1 次优解与自适应算子μ的引入
在基本的ABC算法中,雇佣蜂和跟随蜂的搜索依赖于随机个体对每个个体的引导作用,导致算法的局部开发能力较弱。针对这一问题,本文对于雇佣蜂和跟随蜂分别采用了不同的搜索机制,在雇佣蜂阶段引入次优解得到新的雇佣蜂搜索公式
vi,j=xe,j+φi,j·(xe,j-xk,j)
(11)
式中:xe,j为次优解,即从种群中适应度最好的前10%个解中取一个随机解。φi,j为(-1,1)上的随机数。新的跟随蜂搜索公式如下所示
vi,j=μ·xe,j+(1-μ)·xbest,j+ψi,j·(xbest,j-xk,j)
(12)
其中,ψi,j为(-1,1)上的随机数,μ为自适应算子,能够根据迭代次数调整最优解和次优解的权值,本文提出了一种较为简单的线性表达式
(13)
式中:t为当前迭代次数,T为最大迭代次数,a和b为权值系数,经过多次实验得到a和b分别取0.4和0.1为最优。
2.3.2 概率选择机制的改进
在基本的ABC中,跟随蜂会根据雇佣蜂提供的食物源质量选择是否跟随,第i个食物源被选择的概率
(14)
其中,fit(i) 为第i个食物源的适应度值,SN为种群规模。
AABC算法的跟随蜂选择概率的表达式如下
(15)
其中,fitmax为当前代最大适应度值。通过对比不难发现,AABC算法的跟随蜂对于最大适应度值的食物源是一定跟随的,并且划定了跟随概率的下限,避免了在适应度值差距较小时,优秀个体不能被选择的情况发生。
2.3.3 AABC算法的有效性测试
为验证AABC算法的有效性,本文使用以下3个典型的无约束极小化问题进行测试,具体见表1。

表1 3个无约束极小化问题
本文选择了标准ABC算法、全局最优人工蜂群算法(GABC)[10]与AABC算法在给定迭代次数下进行多次独立测试。具体参数配置如下:最大迭代次数为3000代,种群规模NP取30,个体维数D为30,独立实验30次,个体的迭代限制limit取300。对实验所得目标函数值的最优精度,平均精度和精度标准差进行对比分析,测试结果见表2。
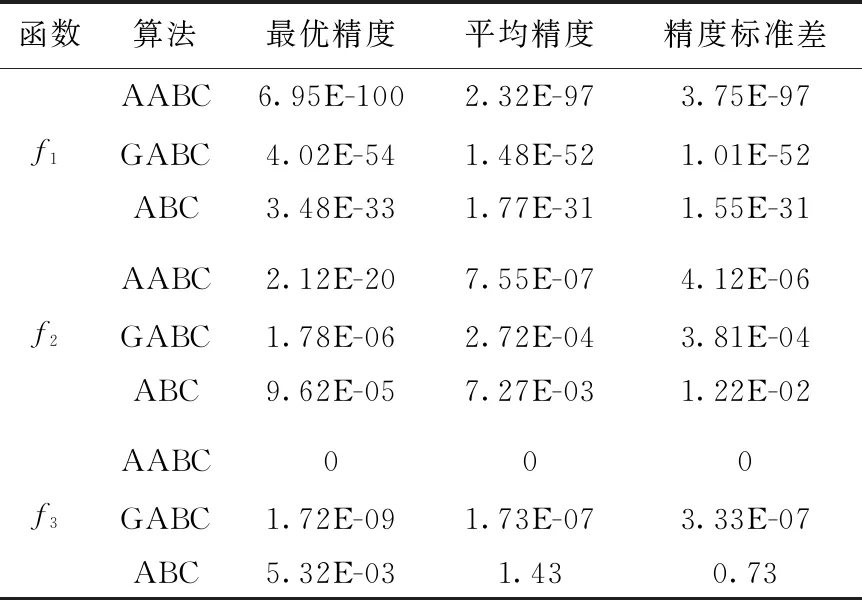
表2 目标函数测试结果
从表2可以看出,AABC算法与GABC和ABC相比,无论是在算法的收敛稳定性还是在收敛精度上,都有较大程度提升。对于Rastrigin函数,只有AABC得到了理论最优值0。对于Sphere和Rosenblock函数,虽然都未能找到理论最优值0,但AABC的收敛精度是GABC和ABC算法无法比拟的。
2.4 AABC算法优化的ELM
本文采用AABC算法对ELM的隐层输入权值和偏置进行寻优,寻优流程如图1所示。AABC-ELM算法的实现步骤如下所示:①初始化AABC-ELM网络的参数,包括:最大迭代次数,种群规模,隐层节点数,个体维度,个体迭代限制等;②以ELM隐层输入权值和偏置作为种群个体,随机产生初始种群;③导入训练集数据并计算目标函数值和适应度值,其中目标函数值为样本标签与网络输出标签的均方差,ELM隐层节点的激活函数采用sigmod函数;④执行AABC算法的雇佣蜂搜索、跟随蜂概率选择以及跟随蜂搜索;⑤判断是否满足循环终止条件。若满足则输出最优ELM隐层输入权值和偏置,否则返回步骤④。

图1 AABC算法优化ELM的基本流程
3 数据与材料
3.1 数据的获取及预处理
仿真数据采用克利夫兰医学中心捐赠给UCI数据库的Heart Disease数据集,该数据集共有303组数据,因存在数据缺失,本文只选用其中297组完整数据。此原始数据集包含了心脏病病例的76个特征,但其中存在一些明显属于无关特征的数据,例如患者编号、社会安全号码、姓名等;以及一些未使用的特征,在数据集中以-9表示,包括胸痛位置、是否吸烟、吸烟年数等,共计26个无关和未使用特征,挑选剩余50组特征作为可用数据。数据标签按照有无心脏病(>0,0)划分为137组和160组,其中有心脏病类按照患病程度又被分为4类(1-4),Ⅰ类54组,Ⅱ类35组,Ⅲ类35组,Ⅳ类13组。考虑到数据特征之间量纲的差别,对数据进行归一化处理,得到的数据取值范围为[0,1]。
3.2 选定训练集和测试集
按照2∶1的比例将预处理后的心脏病数据随机划分成训练集和测试集,采用顺序划分法,得到训练集198组,测试集99组。
4 仿真实验与结果分析
4.1 仿真实验平台
仿真实验平台硬件条件为英特尔奔腾G4560处理器,16 GB内存,win10专业版操作系统,在软件Matlab R2016b环境下利用算法对数据进行仿真测试。
4.2 基于AGA的特征选择
本文对AGA的参数配置如下:最大交叉率Pc1=0.9,最小交叉率Pc2=0.3;最大变异率Pm1=0.1,最小变异率Pm2=0.01;种群规模SN=50,最大迭代次数取1000代,最优个体适应度值随迭代次数的变化曲线如图2所示。
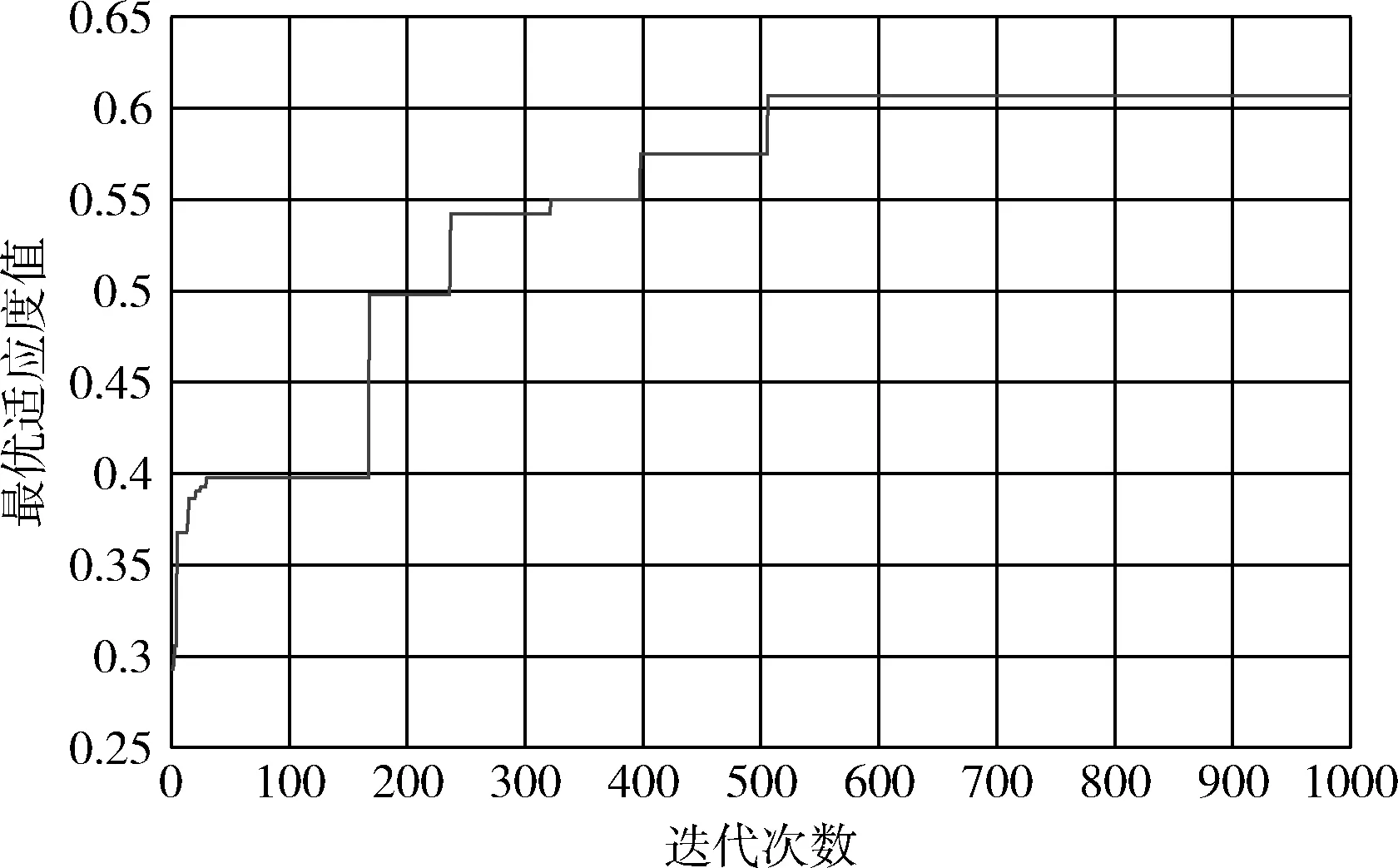
图2 最优适应度值随迭代次数进化曲线
从图2可以看出AGA在算法演化初期的收敛速度较快,适应度值在50代以内就已经达到了0.4左右,之后适应度值逐步增大并在500代左右收敛,得到的最优适应度值为0.607,最优特征13个,特征序列为{6 16 18 21 27 32 34 38 40 41 42 43 45},对应的特征依次为年龄,性别,胸痛型, 静息血压,血清胆固醇,空腹血糖,静息心电图结果,达到最大心率,运动诱发心绞痛,运动引起ST段压降相对于休息,高峰运动ST段的斜率,通过荧光检查着色的主要血管(0-3)的数量,地中海贫血症。
4.3 模型参数对诊断结果的影响
针对ELM和AABC算法的特点,本文主要从以下两个参数的选取对心脏病诊断结果的影响进行分析,按照原始数据标签进行5分类。
4.3.1 隐层节点数对诊断结果的影响
对于存在神经网络结构的算法来说,隐层节点的个数对网络的输出影响巨大,也直接影响了心脏病诊断结果。本文将AABC-ELM与PSO-ELM以及ELM算法进行比较,总体分类准确率随隐层节点数的变化曲线如图3所示。
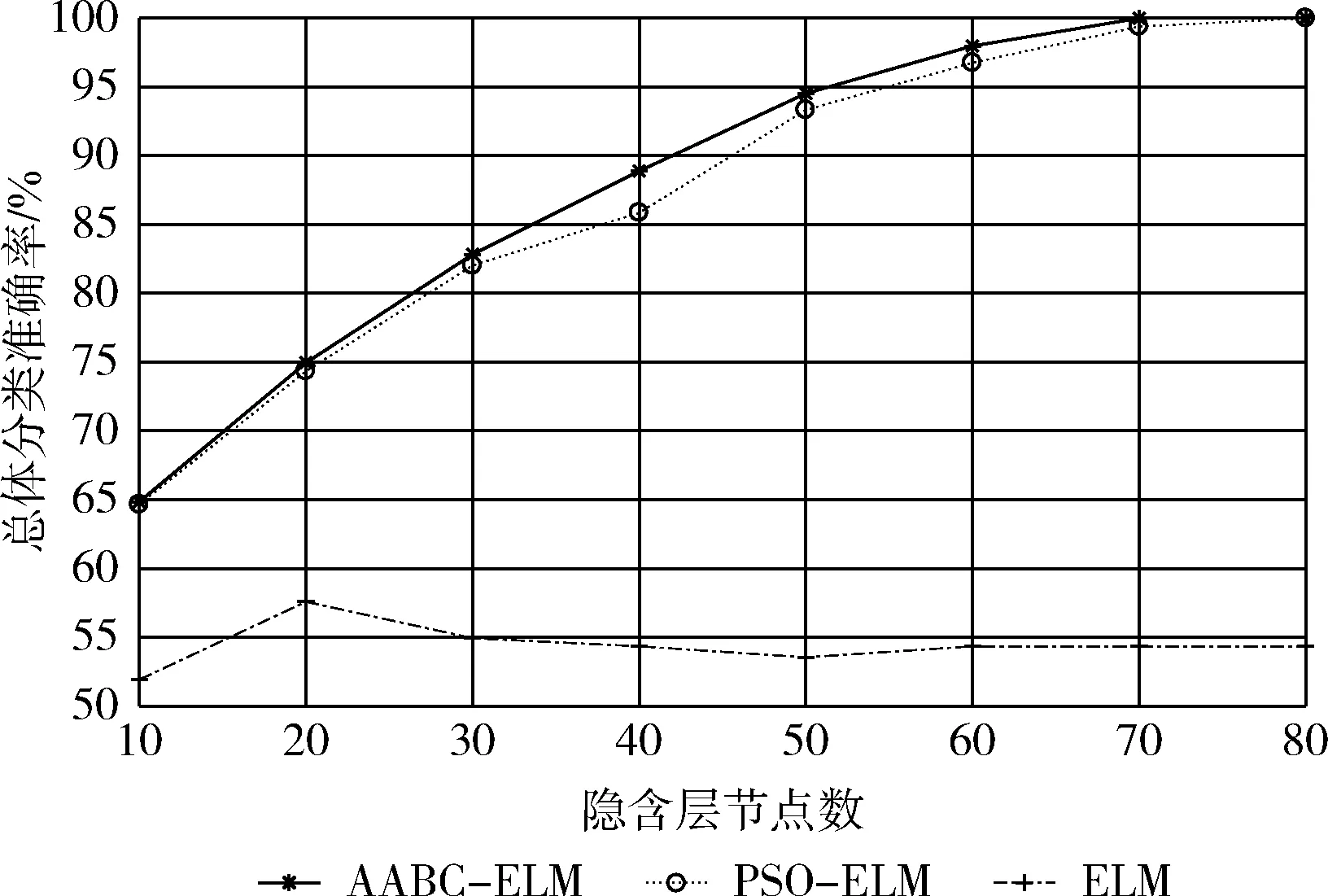
图3 总体分类准确率随隐层节点数变化曲线
从图3可以看出,两种改进后的ELM算法相比原始ELM算法在总体分类准确率上有显著提升,表明对于ELM参数采用寻优策略进行优化是十分有效的。在相同隐层节点范围内,相比于PSO-ELM算法,AABC-ELM算法的收敛速度更快,即在相同分类准确率的情况下所需要的隐层节点数更少,降低了网络的复杂程度。
AABC-ELM算法在70个隐层节点时已经达到100%的分类准确率而PSO-ELM算法在80个隐层节点时才能达到,本文优先考虑分类准确率,同时尽量降低网络的复杂程度,突出不同算法的对比效果,最后确定隐层节点数为70。
4.3.2 算法迭代次数对诊断结果的影响
因为原始的ELM算法没有迭代寻优过程,所以本文采用AABC-ELM、PSO-ELM以及ABC-ELM这3种改进ELM算法进行仿真对比,总体分类准确率随迭代次数的变化曲线如图4所示。
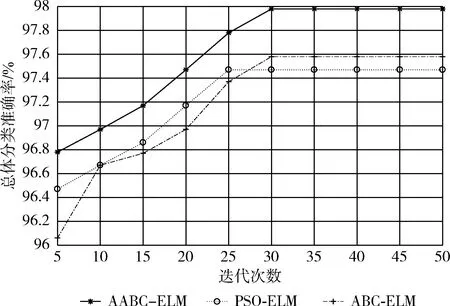
图4 总体分类准确率随迭代次数变化曲线
从图4可以看出,AABC-ELM算法的收敛精度明显高于其它两种算法,虽然PSO-ELM算法要更早收敛。ABC-ELM算法的收敛曲线波动要更大一些,但收敛精度却略高于PSO-ELM算法,可见ABC-ELM算法全局性能更优。
4.4 心脏病诊断的仿真结果分析
为了测试AABC-ELM算法对Heart Disease数据的分类识别效果,本文采用AABC-ELM、IAFSA-ELM、ABC-ELM、PSO-ELM、ELM以及BP神经网络对心脏病诊断的198个训练样本和99个测试样本分别进行学习和分类。按照原始数据标签(0-4)进行5分类以及按照有无心脏病(0,大于等于1的值为1)进行2分类。测试集各标签样本个数见表3。

表3 测试集各标签的样本数
对于心脏病诊断的仿真参数配置如下:最大迭代次数为100,个体迭代次数限制为20,种群规模NP取50,独立实验20次。各算法对于五分类和二分类平均心脏病分类结果见表4、表5。
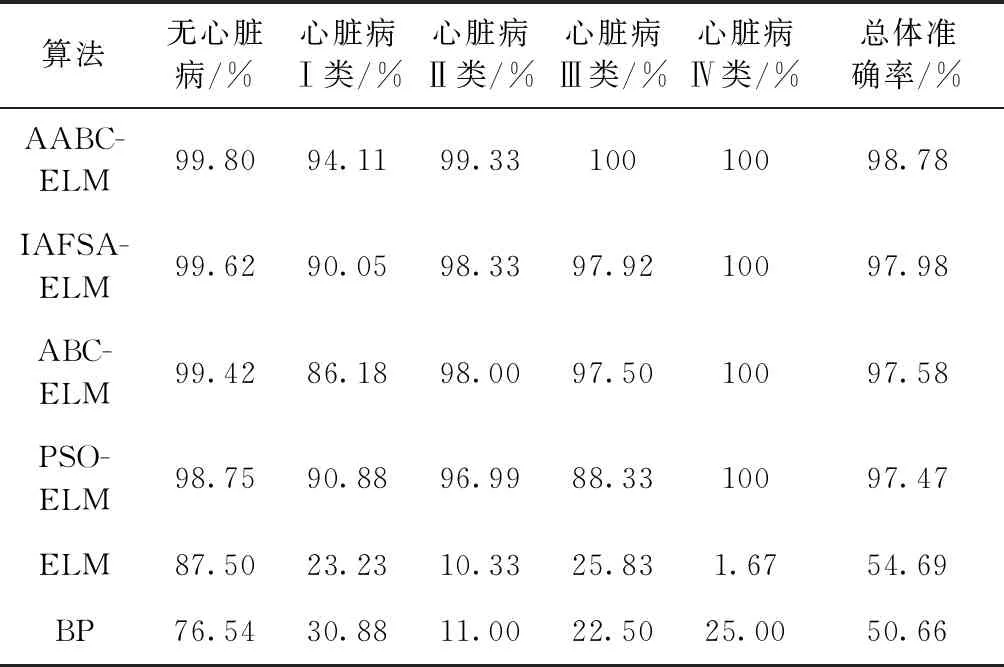
表4 几种算法的五分类平均心脏病分类结果
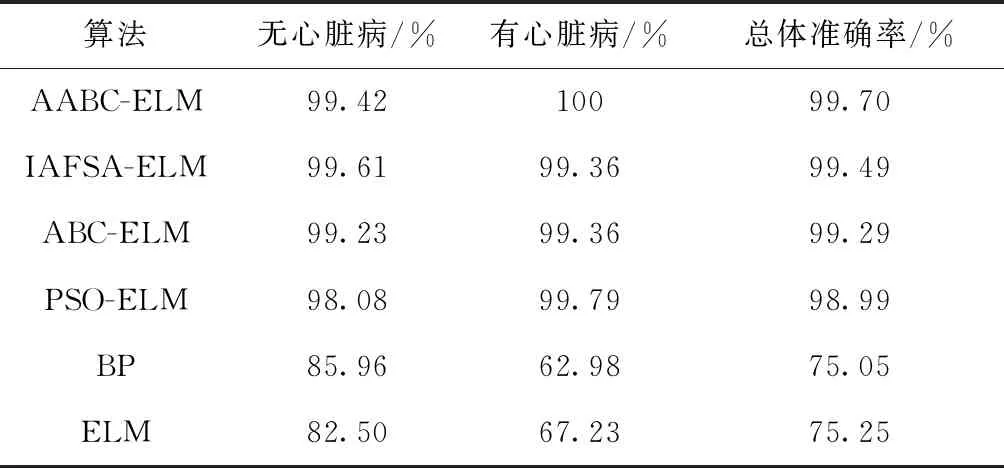
表5 几种算法的二分类平均心脏病分类结果
结合表3~表5不难看出,无论是五分类还是二分类,几种改进ELM算法的分类结果要明显好于ELM和BP。值得注意的是,在样本分布不均匀的五分类中,ELM和BP对于小样本数据分类的表现很差,ELM算法对于样本数最少的心脏病Ⅳ类几乎无法识别。然而对于样本数量相近的二分类(无心脏病52组,有心脏病47组),总体分类准确率相比于五分类要高出20%左右。在五分类中,AABC-ELM对于各标签的分类准确率均为最高,其中心脏病Ⅲ类和Ⅳ类的分类准确率达到了100%;在二分类中,AABC-ELM对于无心脏病类的分类准确率要略小于IAFSA-ELM,对于有心脏病类的分类准确率达到了100%,相比于ELM算法,五分类和二分类的总体分类准确率分别高出44.09%和24.45%。
对于心脏病诊断耗时的研究,由于不同算法达到不同的分类准确率的耗时各不相同,所以本文以97%的五分类准确率为标准,而ELM和BP无法达到这个标准,所以只采用AABC-ELM、IAFSA-ELM、ABC-ELM以及PSO-ELM进行对比,4种算法的平均耗时见表6。
从表6可知,AABC-ELM相比于IAFSA-ELM、ABC-ELM以及PSO-ELM算法,网络的训练以及测试耗时大大缩短,表明在保证一定的分类准确率下,AABC-ELM算法的学习速度更快,能更好满足心脏病诊断的时间要求。
4.5 算法泛化性能测试
泛化性能,即对新鲜数据的适应能力是衡量一种算法是否可靠的关键因素之一,如果说本文算法对于不同的心脏病数据都能取得良好的分类效果,则可以说本算法具有较强的泛化性能。为对本文算法的泛化性能进行测试,现采用UCI数据库中的SPECT心脏病数据集进行仿真实验,单光子发射计算机断层成像术(single-photon emission computed tomography,SPECT)是一种核医学CT技术,可以对心脏灌注断层进行显像。该数据集共有267组样本,样本特征为心脏SPECT-CT图像的感兴趣区域,共有44组特征,样本标签分为正常(0)和异常(1);原始数据集已将样本划分为187组测试集(正常15组,异常172组)和80组训练集(正常40组,异常40组),首先采用AGA对数据特征进行选择,得到12个最优特征,再进行AABC-ELM建模,与ELM的仿真结果对比见表7。虽然本文算法对正常样本的分类准确率仅为73.33%,但较ELM仍提高了40%,对于异常样本则全部分类正确,总体分类准确率提高了34.12%。
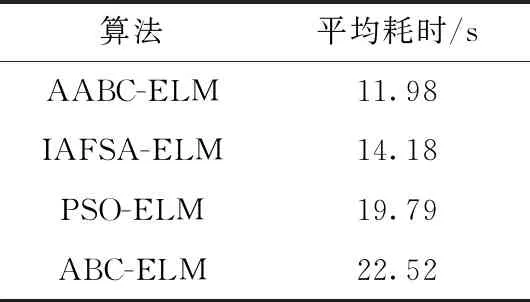
表6 4种算法对心脏病诊断的平均耗时
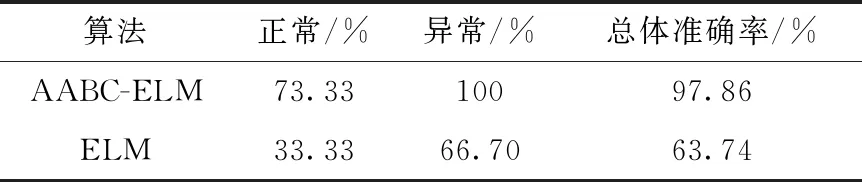
表7 两种算法在SPECT数据集上的分类结果
5 结束语
本文利用AGA对心脏病数据集进行特征选择,结合AABC算法优化的ELM建立了心脏病辅助诊断模型。仿真结果表明:①本文算法有效的弥补了ELM对于不均衡心脏病样本识别精度不足的缺陷,具有较高的分类准确率、较短的训练时间,降低了算法欠拟合风险;②本文算法对新鲜数据具有较好的适应能力,泛化性能较强,不仅适用于心脏病患病程度的识别,还适用于心肌缺血的识别。
在本文基础上,可以考虑将ELM与深度学习相结合,对心脏病图像的识别分类进行深入研究。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
今日农业(2022年15期)2022-09-20
浙江大学学报(理学版)(2022年4期)2022-07-25
湖南电力(2021年1期)2021-04-13
商洛学院学报(2020年4期)2020-07-08
人民珠江(2019年4期)2019-04-20
红土地(2018年7期)2018-09-26
铁路计算机应用(2018年5期)2018-06-01
郑州大学学报(工学版)(2018年2期)2018-04-13
中国塑料(2016年11期)2016-04-16
