
基于特征降维及参数优化的语音情感识别
2020-06-01 05:20俞颖黄风华刘永芬
延边大学学报(自然科学版) 2020年1期
俞颖, 黄风华, 刘永芬
(1.阳光学院 空间数据挖掘与应用福建省高校工程研究中心; 2.阳光学院 人工智能学院;3.福建农林大学 金山学院: 福建 福州 350001 )
0 引言
语音是人际交流的重要媒介.语音信号中不仅包含所要传递的语义信息,还包含丰富的情感信息,因此如何使计算机从语音信号中自动识别出说话人的情感状态及其变化,是实现自然人机交互技术的关键前提.目前,语音情感识别存在两大难点:一是如何寻找有效的语音情感特征,二是如何构造合适的语音情感识别模型[1].研究[2-3]显示,单一特征情感识别的效果并不理想,因此学者们更多的是采用多特征联合的方法来识别语音情感;但采用多特征联合的方法易使情感特征的维数偏高,进而增加计算的复杂度.近年来,支持向量机(SVM)和人工神经网络(ANN)模型被广泛应用于语音情感识别.例如:文献[4]通过构造多个SVM分类器进行语音感情识别,该方法虽然提高了语音情感识别率,但因所构造的SVM分类器较多使得识别过程较为复杂;文献[5]提出了一种将传统的主成份分析法(PCA算法)和SVM分类器相结合的语音情感识别方法,该方法可有效降低语音情感识别的计算量,但传统的PCA算法在降维过程中需要较高的时间耗费;文献[6]采用改进遗传算法优化BP神经网络来进行语音情感识别,该方法的语音情感识别率较高,但识别过程中所用的特征维数较高,增加了语音情感识别的计算量.基于上述研究,本文利用快速主成份分析法(Fast_PCA算法)和优化后的BP神经网络提出一种新的语音情感识别方法,并通过实验验证本文方法的有效性.
1 语音情感特征提取及Fast_PAC降维
1.1 语音情感特征参数的提取
常用的语音情感特征主要包含韵律学特征、基于谱的特征和音质特征.语音处理的特征参数通常是以帧为单位提取的,但由于单帧信号所含的信息量较少,因此用于情感识别的特征参数多采用连续多帧的提取特征值,然后通过计算这些特征值的统计量来组合情感识别的特征参数.基于中文与西方语种在语音和情感表达上存在的差异[5],本文将中西方语种语音信号中的基音频率、短时能量、短时幅值、短时平均过零率、共振峰、语音持续时间及梅尔频率倒谱系数(MFCC)作为原始的语音情感特征,并通过计算这7类原始语音的情感特征值及其一阶差分、二阶差分的统计值(统计值主要包括最大值、最小值、均值、中值、标准差、方差等)来获取语音信号的高维度联合特征.
1) 基音频率.基音频率(简称基频)是指发浊音时声带产生的周期性的振动频率,它能够反映声道的特征.一般来说,男性的基频较低,女性的基频较高,且不同情感状态下基频的大小不同[7].
2) 短时能量.短时能量是指每帧信号的短时平均能量,它反映的是语音的能量或语音振幅随时间缓慢变化的规律[8].设x(l)为语音时域信号,N为每帧的长度,w(m)为窗函数,xn(m)为加窗分帧处理后的第n帧语音信号.定义xn(m)=w(m)x(n+m), 则短时能量谱En的计算公式[5]为
(1)
3)短时幅值.短时幅值也是度量语音信号能量大小的一个指标,它与短时能量的区别在于计算时无论取何采样值,都不会因为对语音信号值取二次方而造成分帧之间的能量值有较大差异.短时幅值Mn的计算公式[5]为
(2)
4)短时平均过零率.短时平均过零率是指每帧语音信号在零值上下所波动的次数.浊音具有较低的过零率,清音具有较高的过零率,利用短时平均过零率可以从背景噪声中找出语音信号并判断出语音的起点和终点[9].
5)共振峰.共振峰是声源通过声道时产生的一组共振频率.当人处在不同的神经紧张程度下,声道发生形变,共振频率也发生改变[10].本文利用线性预测法提取语音信号中的共振峰频率,并计算第1至第3共振峰的相关统计特性.计算所得的相关统计特性作为语音信号的特征参数.
6)语音持续时间.语音持续时间是指情感发音的持续时间.因欢快、愤怒和惊奇的发音长度相对较短,而悲伤的语音持续时间相对较长,因此可以利用语音的时间构造来进行情感区分.
7) MFCC系数.MFCC系数反映的是人的感知能力与语音信号的频率之间存在的特定关系.MFCC系数的计算以Mel频率为基准,其计算表达式[11]为
mel(f)=2 595×log10(1+f/700),
(3)
其中f是语音频率.
1.2 Fast_PCA算法的特征参数降维
研究表明,利用PCA算法中的线性变换可将高维空间中的样本数据投影到低维空间中,从而达到特征降维的目的[12];但传统的PCA算法在特征降维过程中需要对样本的协方差矩阵进行本征值和本征向量的求解,计算量较大.快速主成份分析法[13]是PCA算法的一种改进方法,该方法在特征降维过程中能够通过求解低维度的协方差转置矩阵的本征向量值及本征值来代替求解高维度协方差矩阵本征向量值及本征值,因此可实现语音情感特征的高效降维.
设D是构成语音情感特征向量的样本矩阵,D∈Rn ×m, 其中n为语音样本数量,m为语音样本特征维数.设mA为样本均值,k为降维的维数.则Fast_PCA算法降维的具体步骤可描述为:
Step 1 将D矩阵中的每个样本减去mA, 得到中心化样本矩阵Zn ×m.
Step 2 计算协方差转置矩阵T,T=Z×ZT.
大禹集团持续稳步推进节水设施农业连锁服务中心建设,现有连锁直营店和加盟店近200家,向着逐步改善资本运营效率,快速扩大市场覆盖面方面持续迈进。科技研发实力是公司的核心竞争力,公司累计获得科研成果和专利技术共计180余项,成为国家知识产权局第一批国家级知识产权优势企业,并成立了节水灌溉产业战略联盟、大禹节水灌溉技术研究院、大禹节水院士专家工作站,力促公司科研水平迈向新高度。
Step 3 计算协方差转置矩阵T的最大k个特征值和特征向量V1.
Step 4 对特征向量V1左乘ZT, 得到协方差矩阵的特征向量V,V=ZT×V1.
Step 5 对V进行归一化处理.
Step 6 计算Z×V, 将特征向量线性降维到k维空间.
2 BP神经网络参数优化
2.1 BP神经网络原理

图1 3层BP神经网络的结构
BP神经网络具有较强的非线性映射能力,其能够通过学习自适应地更新神经网络的权值来逼近求解问题的最优解,因而被广泛应用于图像分类、语音识别等领域.BP神经网络属于多层前馈神经网络,包含1个输入层、多个隐含层和1个输出层,层与层之间采用全连接方式,其最大的优点是可以通过训练样本反向传播调节网络的权值和阀值来实现网络的误差平方和最小的目的[14].3层BP神经网络结构如图1所示.图1中,x1,x2,…,xn为BP神经网络的输入信号值,y1,y2,…,ym为BP神经网络的输出信号值.尽管BP神经网络具有很强的自学习和自适应能力,但其仍存在一些不足之处,如网络的权值及阀值是随机初始化的,网络的收敛速度较慢,当网络中存在多个极小值时问题的解容易陷入局部最优解.
2.2 遗传算法优化BP神经网络
为了克服BP神经网络自身存在的缺陷,本文采用遗传算法对BP神经网络的权值和阀值进行全局优化搜索,通过训练、搭建语音情感分析BP网络模型来提高语音情感识别的精度.利用遗传算法优化BP神经网络的具体步骤如下:
Step 1 初始化BP神经网络,确定网络的输入层、隐含层及输出层,产生网络的初始权值和阀值.
Step 3 随机产生一个种群,并进行染色体编码;计算BP网络误差,确定染色体的适应度值.
Step 4 对种群进行遗传迭代,根据个体适应度选择染色体并进行交叉和变异,由此产生一个新的种群.
Step 5 计算新种群的适应度,并更新该种群的染色体.
Step 6 判断是否满足退出条件,如果是则可获得最优BP神经网络的权值和阀值,转Step 7; 否则转Step 4, 继续迭代.
Step 7 更新BP神经网络的权值和阈值,生成优化BP神经网络模型.
3 算法流程

图2 改进的语音情感识别方法的流程图
本文提出的语音情感识别改进方法的具体工作流程如图2所示,具体操作步骤为:
1)对语音情感语料库进行预处理.首先通过分析语音情感语料库的特征为语料库中的语音数据添加识别标签,然后对语音数据进行特征提取、特征联合以及归一化处理.
2)建立训练集D1和测试集D2.首先利用Fast_PCA算法计算语音特征参数的主成份分量并分析其对语音特征的贡献度,然后通过确定有效的特征维数将语音特征集划分为训练集D1和测试集D2.
3)建立语音情感识别模型.首先利用训练集D1对BP神经网络进行训练,并采用遗传算法对网络模型的参数进行优化;然后利用迭代动态调节神经网络权值(阈值)获得最优的语音情感识别模型.
4)分析语音情感的识别性能.首先利用测试集D2对建立的最优语音情感识别模型进行验证,然后计算情感识别精度并进行精度分析.
4 算法的实验验证
4.1 实验环境及数据
算法在Matlab R2014a环境下实现编程,计算机的配置为:Intel(R) i5-4570R, 8 G内存,Windows7.为了更好地进行语音情感识别效果对比,分别选择国内具有代表性的中科院自动化所模式识别实验室提供的CASIA汉语情感语料库[15]和柏林工业大学提供的德语情感语料库[16]进行语音情感识别验证.这两个情感语料均在无噪声环境下获取,采样率为16 kHz,采样精度为16 bit.情感语料库的基本信息如表1所示.

表1 语料库信息表
4.2 实验及结果分析
在CASIA汉语情感语料库、柏林德语情感语料库中提取每句语料的7类原始语音情感特征(基音频率、短时能量、短时幅值、短时平均过零率、共振峰、语音持续时间及MFCC),然后计算这7类原始特征的特征值及其一阶差分、二阶差分的统计值.根据计算所得结果,将其组合成186维的语音情感联合特征,用以表示每句语料的情感信息.
为了验证本文所提出的语音情感识别改进方法对语音情感特征的降维效果,采用Fast_PCA算法分别对2个语料库的特征参数进行降维处理.图3和图4为2个语料库降维后的前10维主成份分量对原始语料信息的贡献比例,表2为2个语料库在不同降维处理时所耗费的时间及对原始语料信息的贡献比例.从图3和图4可以看出,第1维到第10维对原始语料信息的贡献比例呈逐渐降低的趋势,其中第1维对原始语料信息的贡献比例分别为36.87%和28.29%,第2维对原始语料信息的贡献比例均为15%左右,第10维对原始语料信息的贡献比例均低于5%以下.这表明经过Fast_PCA算法特征降维后,对原始语料信息的贡献程度起主要作用的主成份分量集中在低维区.从表2可以看出,增加维数时降维时间虽呈增加趋势,但CASIA汉语情感语料库和柏林德语情感语料库的特征降维时间分别均低于0.1 s和0.2 s;当语料情感特征维度降维至35维时,其对原始语料信息的累计贡献比例已经超过95%.上述结果表明,采用Fast_PCA算法的降维效果较好.
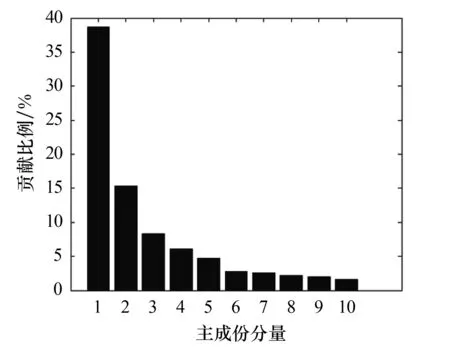
图3 降维后CASIA汉语情感语料库的前10维主成份分量对原始语料信息的贡献比例
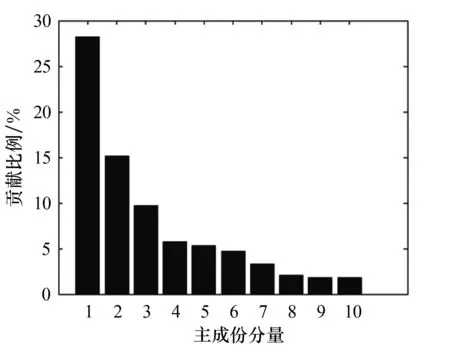
图4 降维后柏林德语情感语料库的前10维主成份分量对原始语料信息的贡献比例
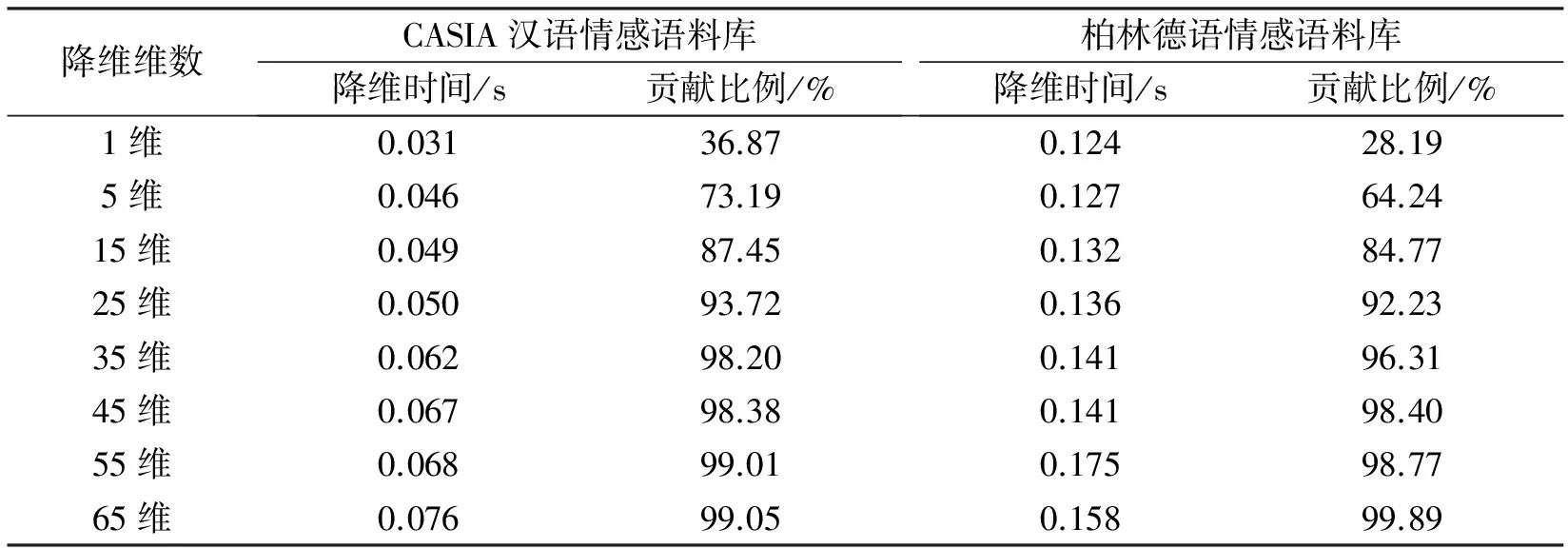
表2 不同维数的降维处理时间及对原始语料信息的贡献比例
为了进一步验证本文方法对语音情感识别的有效性,将本文方法与传统的无特征降维的SVM情感识别方法(SVM)、文献[4]方法(PCA+多级SVM)及文献[5]方法(PCA+SVM)进行对比.BP神经网络和遗传算法的相关参数设置如下:BP神经网络的输出层采用二进制进行识别,CASIA汉语情感语料库识别网络的输出层节点数为6, 柏林德语情感语料库识别网络的输出层节点数为7; BP神经网络的最大迭代次数为2 000,学习率为0.01,目标精度为0.001;遗传算法的初始种群规模为30,交叉概率为0.3.
表3为基于CASIA汉语情感语料库(其中50%用于训练集,50%用于测试集)的不同方法的语音情感识别效果.表4为基于柏林德语情感语料库(其中70%用于训练集,30%用于测试集)的不同方法的语音情感识别效果.由表3和表4可以看出,本文方法的语音情感平均识别率显著优于其他3种方法(SVM、PCA+SVM和PCA+多级SVM).

表3 不同方法对CASIA汉语情感语料库中的语音数据进行情感识别的结果 %

表4 不同方法对柏林德语情感语料库中的语音数据进行情感识别的结果 %
5 结束语
研究表明,与传统的SVM情感识别方法、PCA+SVM方法及PCA+多级SVM方法相比,本文提出的基于Fast_PCA算法的快速降维及遗传算法参数优化的BP神经网络语音情感识别方法,不仅能够以较低的时间代价实现特征维数降维,有效克服局部最优问题,而且情感识别的平均精度显著优于上述3种方法,因此本文方法具有很好的实用价值.本文所采用的语音情感语料库均是在无噪声条件下提取的,而在实际中语音信号的提取往往会受到背景噪声的影响,因此今后我们将进一步研究噪声环境下的语音情感识别算法.
猜你喜欢
车主之友(2022年4期)2022-08-27
通信技术(2021年12期)2022-01-25
天津外国语大学学报(2020年1期)2020-03-25
海峡姐妹(2019年12期)2020-01-14
火控雷达技术(2016年1期)2016-02-06
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年4期)2014-06-13
