
基于迁移学习的棉花识别
2020-08-30 12:38田光宝
浙江农业学报 2020年8期
王 见,田光宝,周 勤
(1.重庆大学 机械传动国家重点实验室,重庆 400044; 2.重庆大学 机械工程学院,重庆 400044)
我国是世界第二产棉大国,棉花在国民经济中占有重要地位。棉花产业是劳动密集型产业,我国的机械化采棉正处于起步阶段,随着劳动力成本的提高,机械化采棉成为必然趋势[1-2]。但机械化采棉在降低劳动强度和种植成本的同时,也降低了棉花的品质[3]。机械化采棉不但需要对棉株进行化学脱叶催熟,而且含杂率高达10%~30%,所需清理工序较多,导致机采棉纤维与手摘棉相比,强度降低,长度缩短[4-6]。智能采棉是降低劳动强度和种植成本,提高机采棉的品质的重要途径。智能采棉机是根据棉花的自然成熟多批次精准采摘,传统机械化采棉是脱叶催熟后一次收获,但效率低是阻碍智能采棉机推广的重要因素之一。智能采棉机精准快速采摘关键在于单个、重叠和部分遮挡棉花的精准识别。传统的基于特征分割在棉花的识别上取得了较好效果[7-9],但无法区分单个、重叠和部分遮挡棉花,导致重叠在一起的多个棉花误识别为一个只返回一个采摘点,部分遮挡棉花识别不出来,偏白非棉花物质误识别为棉花;误识别和漏识别导致智能采棉机采摘效率进一步降低。
近年流行的深度卷积神经网络属于端到端的策略,可以自动实现图像特征的学习与分类[10]。在ImageNet图像分类竞赛中,以卷积神经网络为基础的深度学习算法已经远远超越了传统的机器学习算法。2012年以后,以AlexNet[11]、GoogleNet[12]、ResNet[13]等模型的出现和发展,深度卷积神经网络在图像分类上开始井喷式发展。AlexNet相比之前的神经网络,使用了计算简单且不易发生梯度发散的非线性激活函数(rectified linear units,ReLU);提出了局部响应归一化(local response normalization,LRN),激励反馈较大的神经元,抑制反馈较小的神经元,增强了模型的泛化能力;使用Dropout技术降低神经元复杂的互适应关系,神经元不依赖其他特定的神经元而存在,增强模型的泛化性。GoogleNet继承了AlexNet的优点,提出了一种Inception结构,从上一层分出4块,每块使用不同大小的卷积核卷积后汇合在下一层,通过不同大小卷积核感受视野进行不同尺度特征的融合,提高模型的特征提取能力。ResNet继承了AlexNet的优点,引入了一种残差单元,将前面一层的输出直接连到后面的第2层,解决了网络太深,误差传到前面时梯度逐渐消失的问题。
深度卷积网络已广泛运用于植物领域[14],解决植物分类识别的难点[15-17]。迁移学习解决了小样本训练深度卷积神经网络的问题[18-19]。张建华等[20]基于VGG卷积神经网络,更改分类器,优化全连接层,实现棉花病害的识别。郑一力等[21]在小样本的植物叶片数据库情况下,使用迁移学习的方法有效地提高了植物叶片识别准确率。迁移学习可提高识别准确率,同时避免大量数据标记工作和训练时长[22-30]。单个棉花、重叠棉花、部分遮挡棉花和棉田中的偏白非棉花物质这4类图像在灰度分布和形状上比较相似,如果通过传统的特征提取方法提取一些普通特征,如统计矩、傅里叶描绘子、纹理特征等,再将特征用支持向量机(support vector machine,SVM)等分类器进行分类效果并不理想,因为人为设定的特征只适用于部分特定场景,在复杂棉田环境中效果不稳定。卷积神经网络通过自主学习提取深层次的特征,并克服复杂环境的影响,在图像识别中准确性和稳定性较高,因此选择训练卷积神经网络模型进行不同形态棉花的识别,探讨AlexNet、GoogleNet、ResNet-50迁移模型对不同形态棉花的识别准确率,研究迁移模型特征提取与分类器相结合的方法进一步提高识别准确率。
1 理论基础
1.1 卷积神经网络
卷积神经网络是一种前反馈神经网络,它的神经元可响应一部分覆盖范围内的周围单元。在图像处理方面,卷积神经网络不是对单个像素的处理,而是对每一块像素区域进行处理,增强模型的泛化性。依次在ILSVRC(Large Scale Visual Recognition Challenge)大赛中得冠的AlexNet、GoogLeNet、ResNet-50模型的基本架构相同,其架构如图1所示。
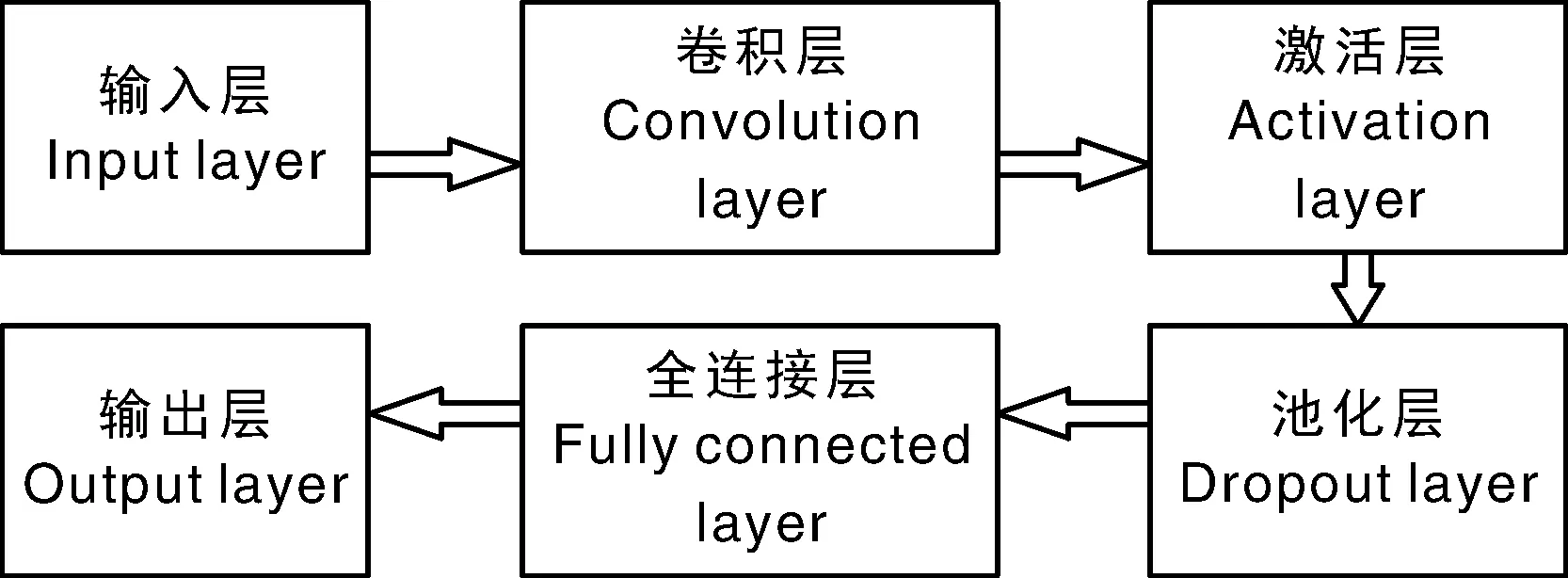
图1 卷积神经网络架构Fig.1 Convolutional neural network structure
其中卷积层具有提取图像局部特征的功能。组成卷积核的每个元素都对应一个权重系数和一个偏差量。上一层特征经过卷积操作后,再通过激活函数便可得到新一层的特征。每层卷积与激活过程如公式(1)所示:
(1)
式中:f代表激活函数;D代表输入图像维度;F代表卷积核的大小;wd,m,n代表卷积核第d层第m行第n列的权重;yd,i,j代表输出特征图第d层第i行第j列数值;Wb代表偏置项。
这3个模型都是使用ReLU作为激活函数,其作用是确保网络的非线性。ReLU函数还具有计算收敛快、不容易产生梯度消失、计算简单等优点。ReLU函数为分段线性函数,如公式(2)所示。
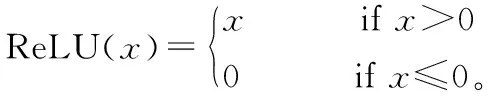
(2)
卷积层与池化层不一定是一一对应的关系,可以在多次卷积操作后叠加一个池化层。池化操作使模型更具泛化能力,模型关注特征本身而不是特征的具体位置。池化操作后,主要特征保留,次要特征包括干扰特征被去除,实现特征降维以减少计算量和参数个数,同时有利于防止过拟合。
卷积层、池化层和激活函数层等操作将原始数据映射到隐层特征空间,全连接层则将隐层特征空间映射到样本标记空间。全连接层的每一个结点都与上一层的所有结点相连,用于把前一层提取到的特征综合起来,将特征输入分类器中进行分类。
损失函数用来评价模型的预测值和真实值的偏离程度。卷积神经网络的训练目标是通过梯度下降优化使得损失函数达到最小。损失函数为交叉熵函数,其收敛较快,函数定义为:
(3)
1.2 迁移学习
迁移学习就是把已有训练好的模型更改相关层后,用于新任务的训练。建立并训练一个新的模型需要大量的训练数据和花费大量的时间,训练好的模型对类似的数据具有抽象的特征提取能力。使用迁移学习方法,可以避免大量数据标记工作和训练时长。
ILSVRC是计算机视觉领域最具有代表性的学术竞赛之一,竞赛使用的官方数据集有1 400万幅图像,其中包含1 000个类别标签。依次得冠的AlexNet、GoogleNet、ResNet-50模型已具有较强的特征提取功能,通过修改模型的分类层,使用棉花数据集对模型的参数进行微调优化,解决棉花的分类识别问题。
1.3 ELM分类算法
ELM是由Huang等[31]提出来的求解单隐层神经网络的算法,由输入层、隐含层、输出层组成,层与层之间全连接,如图2所示。输入层通过映射矩阵w(l×n矩阵,输入层n个神经元,隐含层l个神经元,wij为输入层第i个神经元与隐含层第j个神经元的连接权值)与隐含层连接;隐含层通过映射矩阵β(l×m矩阵,输出层对应m个神经元,βjk为隐含层第j个神经元与输出层第k个神经元与的连接权值)与输出层连接。ELM只需要设置网络的隐层节点个数,在算法执行过程中随机赋值网络的连接权值以及隐元的偏置,并且产生唯一的最优解,具有学习速度快且泛化性能好的优点。隐含层与输出层的映射矩阵可以通过求解如下方程式可得:
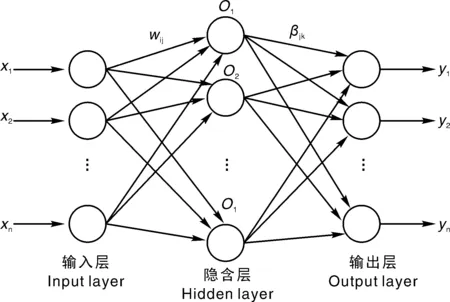
图2 ELM算法拓扑结构Fig.2 Topological structure of ELM algorithm
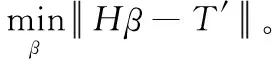
(4)
式中,H表示隐含层点输出,T′为期望输出。其解为
(5)
式中H+为隐含层输出矩阵H的Moore-Penrose广义逆。
2 实验设置
2.1 实验数据
实验数据集由单个棉花图片(single cotton)、重叠棉花图片(overlapped cottons)、遮挡图片(blocked cottons)和偏白非棉花图片(misrecognition cotton)组成,共1 240张。如图3所示。随机将数据集的70%用于训练模型,30%用于验证。数据集中的图片尺寸大小不一致,需要将图片通过插值预处理为各模型输入的标准要求,并使用旋转、平移、仿射变换等操作来防止模型训练过程出现过拟合现象。

图3 棉花数据集示例Fig.3 Example of cotton dataset
实验中使用的电脑为戴尔G33579、8 G内存、NVIDIA GeForce GTX 1050型显卡、win10操作系统,算法的实现使用matlab2019。
2.2 基于棉花数据集搭建的CNN模型
为了说明迁移模型适合小样本棉花识别,搭建基于棉花数据集的CNN模型,其由卷积层、归一化层、Relu激活层、MaxPooling层、Dropout层、全连接层和输出层组成。由于单个、重叠和遮挡棉花在形状和色差上极其相似,大的卷积核和大的步长不利于提取区分特征,实验中设置的卷积核为3,步长为1。由于数据集小,Dropout层的概率不宜过小;概率太大又会导致重要特征丢失,实验设置为0.5。MaxPooling层的池化区大小为2,步长也为2。通过实验得出卷积层为7时取得最好效果。每次卷积操作后做归一化处理并通过Relu激活函数做非线性处理后进行最大值池化,最后一层的MaxPooling层连接一个Dropout层后与全连接层相连,最终通过Softmax函数得到识别的结果,如图4所示。
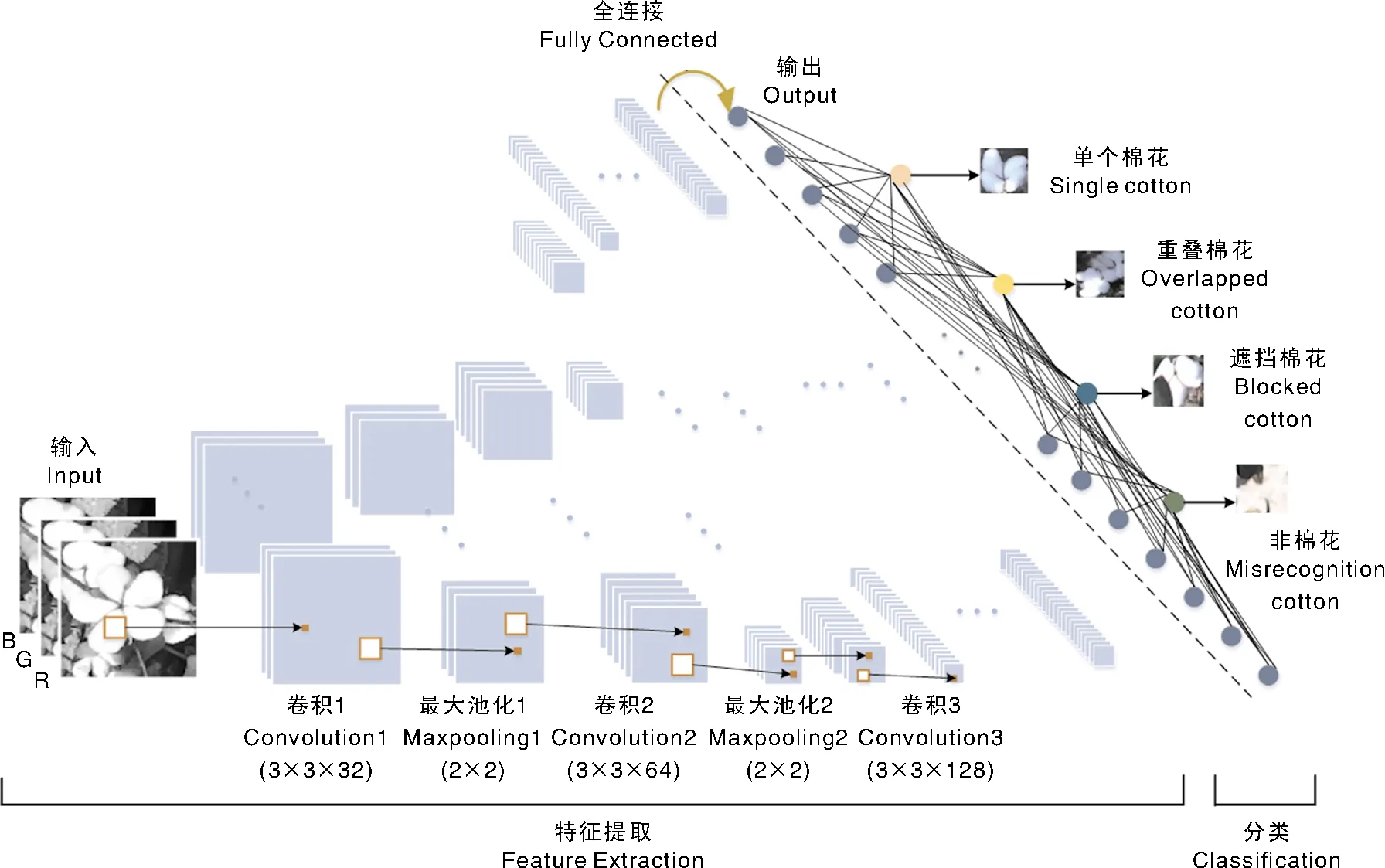
图4 用于棉花数据集识别的卷积神经网络结构Fig.4 The structure of convolutional neural network for cotton data set classification
根据电脑的内存和CNN模型的大小,设置最大运行的epoch数为200,每个Mini-Batch大小为60。学习率太大,模型不容易收敛;学习率太小,模型收敛速度小,初始的学习率为0.01,每经过70个epoch时学习速率下降一半。前期较大的学习率加快学习速度,后期较小的学习率加快参数的收敛。
2.3 基于迁移学习的棉花识别
依次将基于ImageNet数据集训练好AlexNet、GoogleNet、ResNet-50模型调整模型结构,将全连接层由分类数为ImageNet数据集的1 000类修改为本文棉花数据集的4类。将学习率WeightLearnRateFactor设置为10,BiasLearn-RateFactor设置为10,加快修改后的分类层参数的学习速度。3个模型已具有提取有效特征的能力,迁移模型训练前期学习速率相对较大,全连接层和分类层的参数快速收敛,其后的学习速率快速下降,微调模型的参数,实现最佳的分类效果。3个迁移模型训练时初始学习速率设置为0.001,学习速率每经过25个epoch下降为原速率的30%,学习速率太大,模型结果产生波动无法收敛,学习率太小模型收敛太慢。
GoogleNet中前10个层和ResNet-50中前4个层构成了模型的初始“主干”部分,由于棉花数据集小,模型参数较多,为了防止模型较浅的层过拟合数据集,将GoogleNet中前10个层和ResNet-50中前4个层的学习率设置为0以“冻结”这些层的权重。由于这些层的参数在训练时保持不变,可以显著缩短训练时长。较低的初始学习速率保证高层的参数在训练过程中基本不变,加快收敛速度。
由于GoogleNet和ResNet-50模型较大,所以每个MiniBatch大小设置为40。迁移模型只需修改分类层参数和微调其他层参数,故最大运行的epoch数设置为70。将棉花训练数据用于训练新的模型结构,训练过程的损失函数采用SGDM来优化,更新模型中的参数权重,得到3个适用于棉花数据集图像识别的迁移学习模型。
2.4 迁移模型特征提取与ELM相结合棉花识别
基于迁移学习主要是利用已训练好的模型较强的特征提取能力进行特征提取并识别。为了进一步提高棉花识别准确率,将迁移学习模型作为特征提取模型,再选用优越的分类器进行分类。将迁移学习模型特征提取与分类器相结合的分类算法具体流程如图5所示。
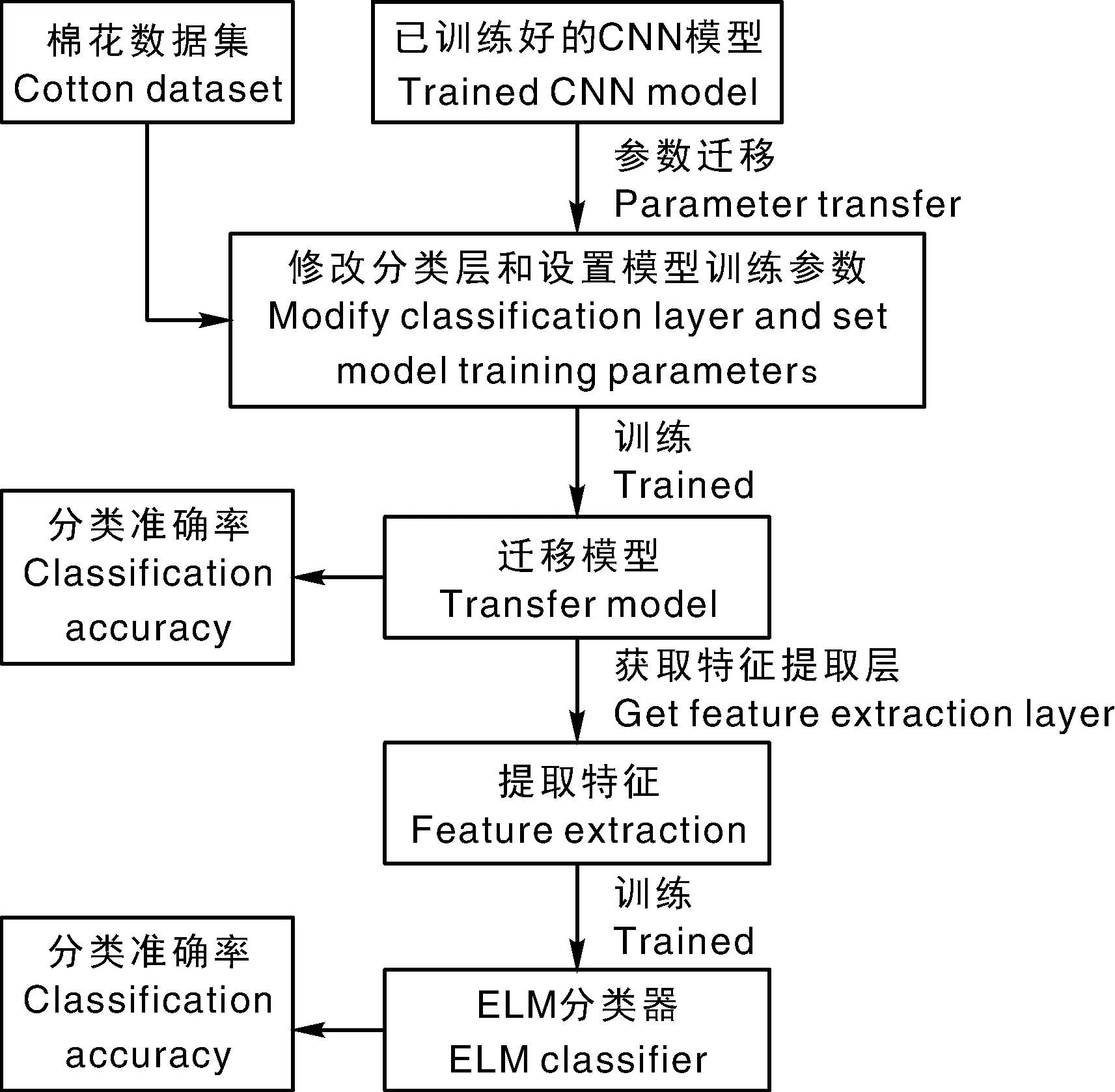
图5 迁移学习模型特征提取与分类器相结合的分类算法Fig.5 Transfer learning model feature extraction and classifier combined classification algorithm
为了比较迁移模型和利用迁移模型进行特征提取后与分类器相结合2种方法的准确率,使用同一数据集。迁移学习模型训练好后,进行识别统计准确率,然后用训练好的模型提取训练迁移学习模型的训练集合和验证集的特征,即模型中最后一层全连接层的输出作为特征保存为样本。AlexNet、GoogleNet和ResNet-50迁移学习模型输出特征维度分别为4 096、1 024、2 048。因此,数据集转换为对应于各模型维度不同的特征数据集。
随机将AlexNet特征数据集、GoogleNet特征数据集、ResNet-50特征数据集中样本的训练集训练ELM模型,验证集测试ELM模型。统计隐含层的神经元个数从1 000到5 000变化时ELM的分类准确率。
3 结果与分析
每个模型重复3次,随机选其中一次进行分析,训练过程和结果如图6所示。图6-A是搭建的CNN模型的结果,模型经过1 400次迭代后,训练集的准确率在100%的下限微小波动,训练集的损失函数值接近于0;但是验证集准确率在89%上下波动,验证集的损失函数值在0.5上下波动;模型出现了过拟合现象,即模型的泛化能力不强,模型只是保存了训练集的特征,当验证集中出现和训练集有差异的图像就容易得到错误的分类识别结果,不具备强的提取特征能力。图6-B是基于AlexNet的迁移学习结果,可以看出模型在迭代600次过后便平稳了,验证集分类识别准确率维持在92%左右。图6-C是基于GoogleNet的迁移学习结果,经过700次后验证集的准确率保持在90%以上波动。70次epoch迭代完后验证集的准确率为92.47%。由于GoogleNet模型的层数比AlexNet多,其结果的波动也比AlexNet大。图6-D是ResNet-50的迁移学习结果,由于ResNet-50模型的层数最多,验证集的准确率波动也最大,最终验证集准确率高达94.62%,比基于AlexNet和GoogleNet的迁移学习的准确率大幅度提高。
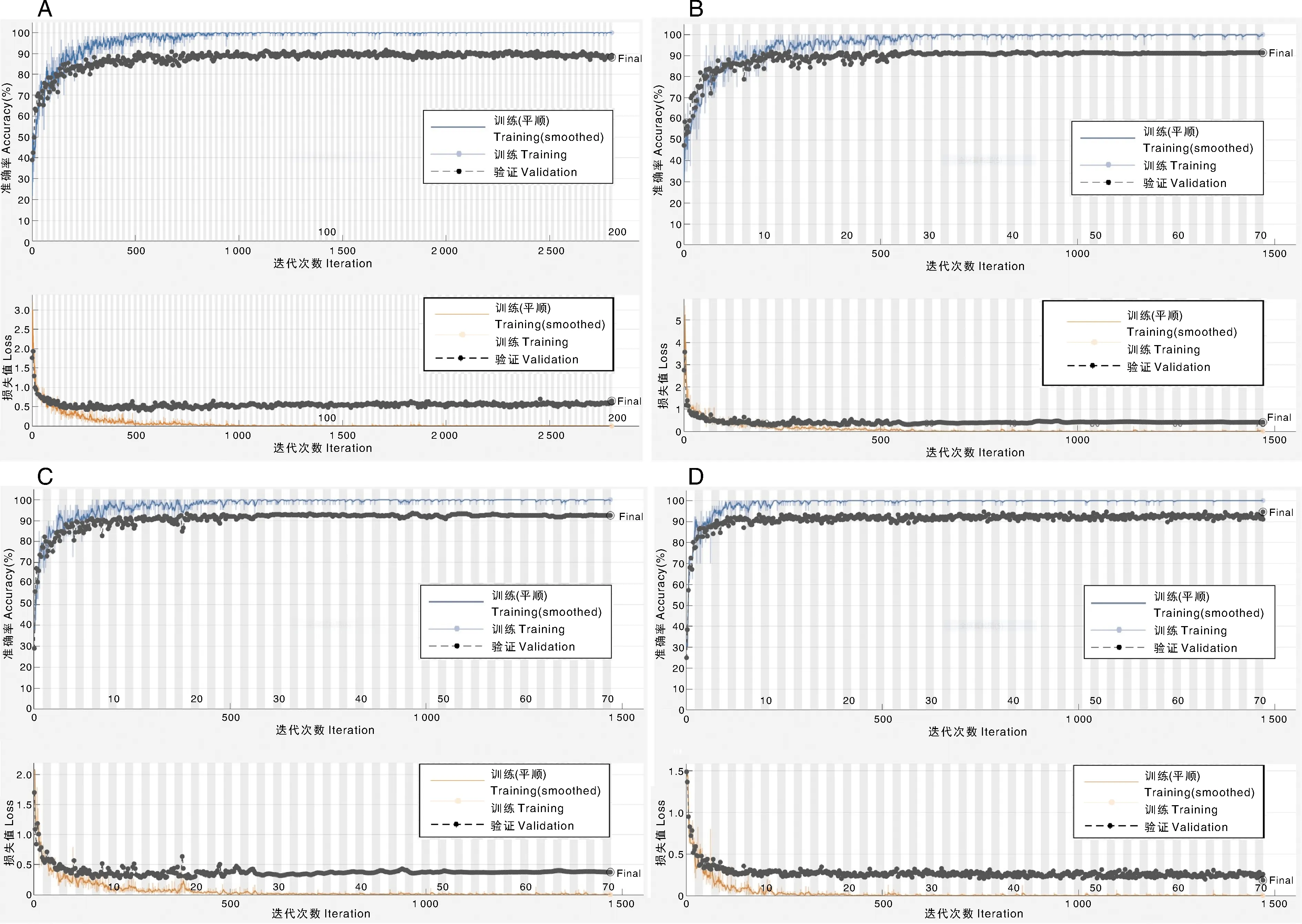
A,CNN的训练过程;B,基于AlexNet的迁移学习训练过程;C,基于GoogleNet的迁移学习训练过程;D,基于ResNet-50的迁移学习训练过程。A, Training process of CNN; B, Training process of transfer learning based on AlexNet; C, Training process of transfer learning based on GoogleNet; D, Training process of transfer learning based on ResNet-50.图6 迁移学习训练过程Fig.6 The transfer learning process
迁移学习模型训练集损失函数值在0的上限值处波动,验证集损失函数值在0.4以下波动。迁移学习不是简单继承原模型的特征提取能力,而是在更改分类层和修改相关参数后,再通过棉花数据集训练激发了对棉花特征敏感的神经元,故有较高的准确率。
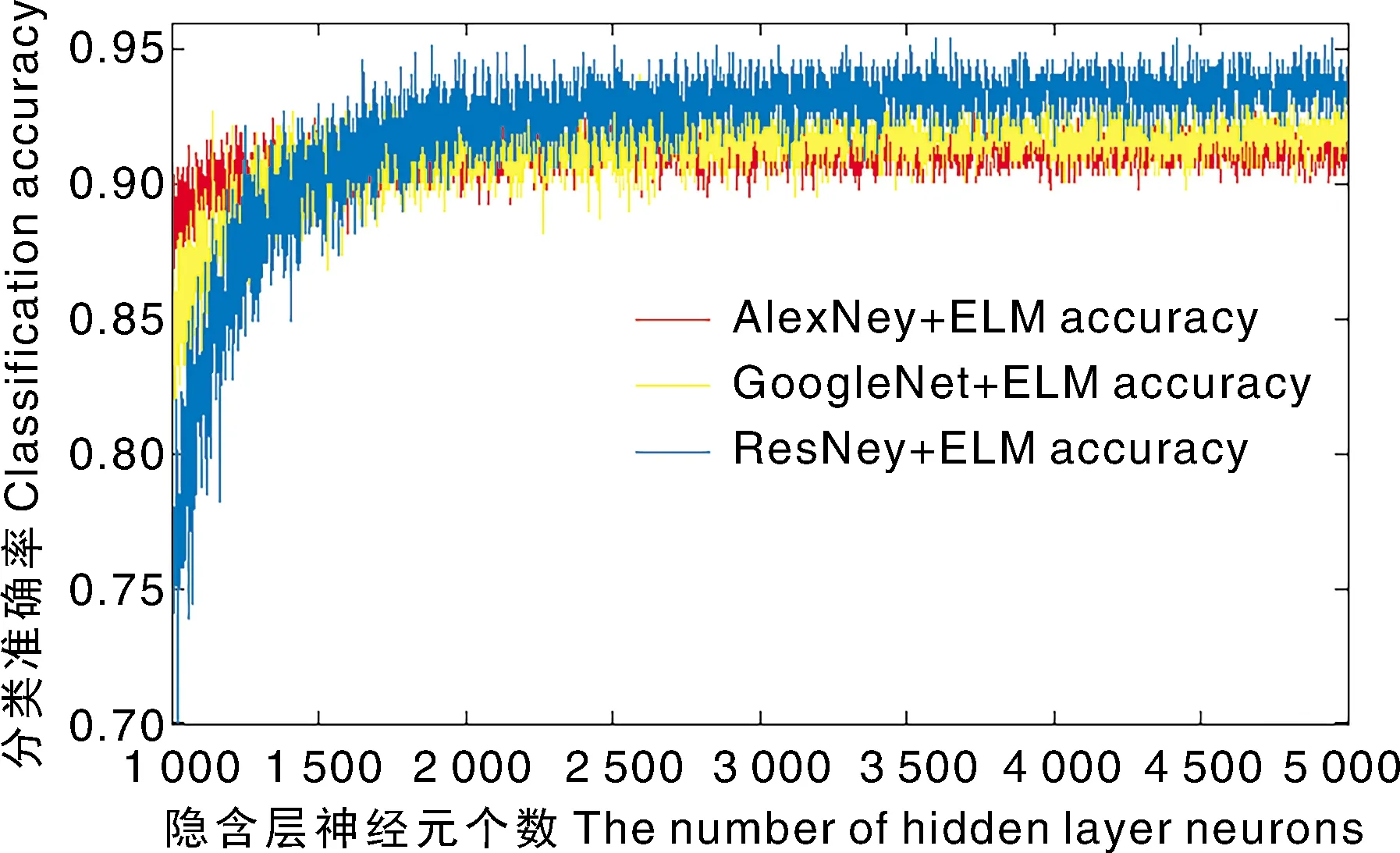
图7 隐含层神经元个数对ELM分类正确率的影响Fig.7 Influence of the number of hidden layer neurons on ELM classification accuracy
用上述对应的迁移模型提取的特征训练和测试ELM分类器,统计隐含层的神经元个数从1 000到5 000变化时ELM的分类准确率。隐含层神经元个数与验证集预测准确率之间的关系如图7所示。3个模型的准确率都是随着隐含层神经元个数增加快速增加,然后趋于平稳的小幅度锯齿状波动的过程。小幅度锯齿状波动是因为ELM模型每次重新训练都需要随机初始化参数,导致结果出现小幅度波动。从图7中可看出,1 800左右个隐含层神经元个数是3个模型的准确率分界点,在分界点以下的准确率依次为AlexNet、GoogleNet、ResNet-50,在分界点以上更好相反。因为模型随着层数增多,其提取的特征越抽象,较多的神经元个数才能更好地分类这些特征。
本文还进行迁移学习模型提取特征后用SVM分类工作。基于CNN、迁移学习和通过各迁移学习模型提取特征后用分类器的结果进行对比,如表1所示,对比内容为重复3次实验后,验证集的分类识别准确率的平均值。
由于棉花的样本较小,搭建的CNN模型出现了过拟合现象;迁移学习可将从通用大数据集上学习的特征提取迁移到数据集相对较小的领域。从表1中可以看出,使用AlexNet、GoogleNet和ResNet-50迁移学习模型比CNN模型识别的准确率分别提高了2.38、3.54和4.03百分点。使用特征提取再与ELM结合的方法,准确率比对应迁移模型分别提高了1.97、1.34、1.55百分点,准确率提高的原因在于棉花样本较小,且四类样本在灰度分布和形状上比较相似,使用迁移模型进行特征提取相当于进行滤波,排除干扰信息,再使用ELM便可进一步提高准确率。GoogleNet在继承了AlexNet优点基础上使用了一种Inception结构,通过不同大小卷积核感受视野进行不同尺度特征的融合,其提取的特征信燥比更高,其迁移模型比AlexNet提高了1.16百分点,而其特征提取与ELM结合的方法准确率提高在对应3个模型中最低。ResNet在继承AlexNet优点基础上引入了一种残差单元,其网络更深,可提取更深层次的有效特征,故其准确率在对应3个迁移模型中最高,其特征提取与ELM结合在对应的3个模型中也是最高的。然而用迁移学习提取特征,再使用SVM进行分类却略降低了分类识别准确率,因为SVM是根据提取特征的空间分布进行分类,忽略特征中个别分量的权重。
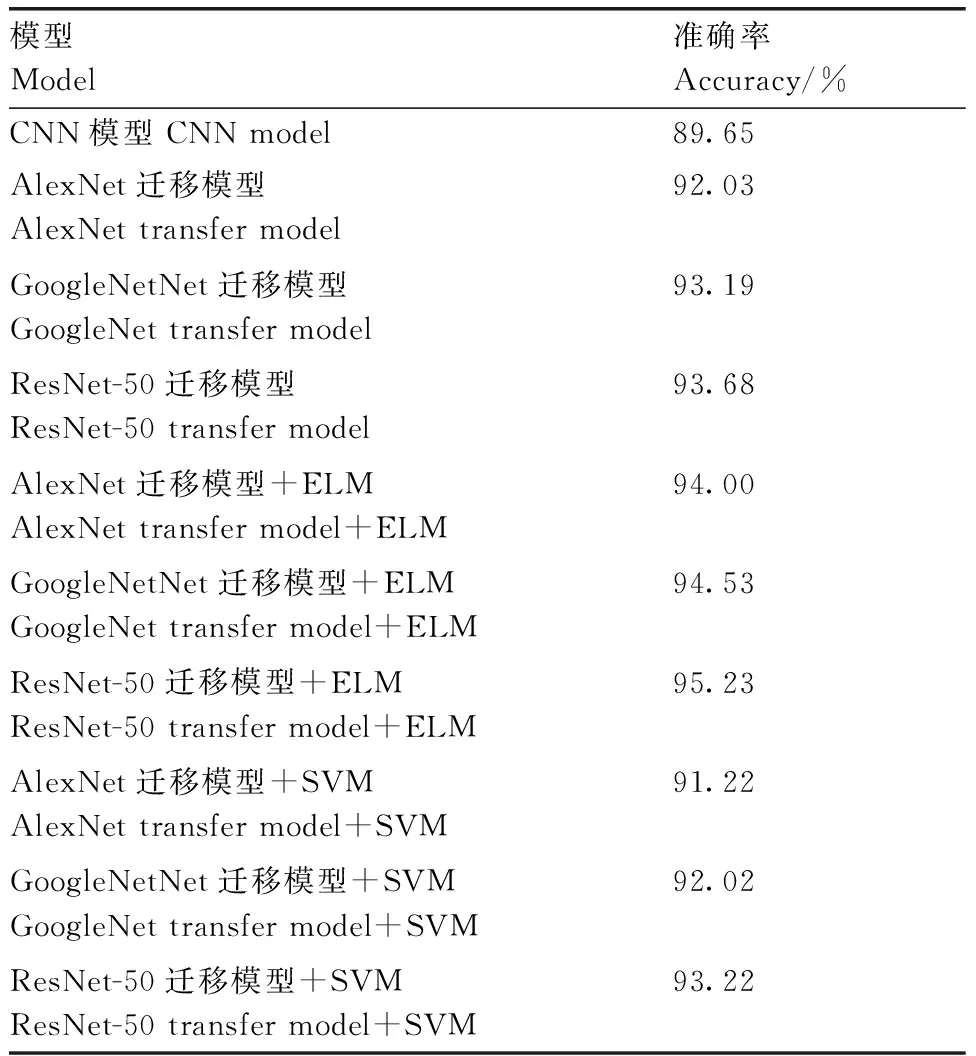
表1 各算法的分类结果对比
4 结论
为了实现4类棉花图像快速准确分类识别,本文引入迁移学习方法。为了验证迁移学习方法的优异性,与搭建的CNN模型进行了对照试验。在训练中,CNN模型出现了过拟合,模型的泛化能力不强。迁移学习的模型具有较强的特征提取能力,将原模型修改分类层、微调参数后,即有很高的准确率。其中基于ResNet-50的迁移模型准确率高达到93.68%。
为了进一步提高棉花分类的准确率,本文引入了迁移学习特征提取与ELM相结合棉花分类识别方法,将迁移学习模型作为特征提取工具,再训练ELM进行分类。在相同的数据集下,准确率都有了小幅提高。
在小样本的情况下,迁移学习比从零开始训练CNN模型更有效,训练时长更短。基于迁移学习的特征提取与优越分类器组合比常规的迁移学习性能更优越。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子产品世界(2021年8期)2021-01-16
健康体检与管理(2021年10期)2021-01-03
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
中国计算机报(2019年49期)2019-02-07
雷达学报(2018年5期)2018-12-05
