
六级、雅思、托福阅读文本难度对比研究
——基于数据挖掘的方法
2021-01-07 06:22王萍OAE信息科技有限公司
外语与翻译 2020年4期
王萍 OAE信息科技有限公司
辜向东 重庆大学
【提 要】本研究采用了三种数据挖掘方法,对大学英语六级(以下简称“六级”)、雅思、托福阅读文本进行对比。运用Coh-Metrix对所收集的340篇三项考试的阅读文本进行特征提取,共获取106个文本特征,其中有43个被选为预测变量。然后分别训练决策树、逻辑回归、朴素贝叶斯模型对三项考试阅读文本进行分类。根据分类精确率、召回率、F1和ROC面积等指标对模型进行评估。结果表明,所选的43个文本特征能有效区分三项考试的阅读文本,分类准确率达到90.29%。在三种模型中,决策树的分类效果最好。研究发现,六级、雅思、托福考试的阅读文本在词汇、短语、句子和语篇层面存在诸多差异。研究结果有望在分数解释、测试材料选择、文本改编、计算机自适应测试和考试对接等方面对三项考试,甚至更广泛的语言测试领域产生实质性影响。
1.引言
阅读理解作为语言学习的重要技能之一,在外语考试中一直占据较大比重。阅读理解测试的难度一直是语言测试研究者关注的重要议题(杨惠中、Weir 1998),试题难度控制也是试题开发工作的重要步骤(杨惠中、金艳2018),只有难度适宜的试题才能测出考生真实的语言水平(Green 2014)。语言测试领域对阅读理解试题难度的研究较多,然而现有研究多集中于对阅读理解试题中单项选择题题目难度的研究(如Freedle&Kostin 1991,1992,1993,1996,1999;Perkins,Gupta&Tammana 1995;Rupp,Garcia&Jamieson 2001;Gao& Rogers2011;Aryadoust& Goh2014;Aryadoust,Alizadeh&Mehran 2016),对阅读文本本身的关注相对较少(江进林、韩宝成2018),而阅读文本难度在一定程度上直接影响阅读理解试题的整体难度。六级、雅思、托福分别是国内外大规模、高风险的英语考试,对比这三项考试阅读测试文本难度的异同有助于形成对这三项考试的关联论证,推动我国语言测试开发与研究的国际化。
2.文本难度研究文献综述
对英语文本难度的研究由来已久,文本难度研究方法大致可分为以下四种:基于文本易读度公式的方法、基于自然语言处理技术的方法、基于信息计算与应用的方法、数据挖掘方法。
基于文本易读度公式,此类方法主要是采用文本易读度公式来测量文本的易读度,如常见的弗莱士易读度(Flesch Reading Ease),计算出来的值介于0到100之间,数值越高,表明文本越易读。弗莱士-金凯德年级水平(Flesch-Kincaid Grade Level)计算出的值为对应的年级,即处于该年级的学生应该具备阅读相应难度级别文本的能力。上述文本易读度公式用于测量文本难度时简单易操作。然而,此类方法主要是对表层的语言形式进行量化,而文本阅读理解涉及众多层面,如文本加工过程中的心理认知因素(Carroll 2000;Gao&Rogers 2011;Schütze 2016)。因此,易读度公式不能全面表征文本难度(刑富坤2007;江进林、韩宝成 2018)。
基于自然语言处理技术,很多学者尝试将自然语言处理技术纳入文本难度的测量中,如Lu(2010)基于自然语言处理技术进行句子边界识别、分词、词性标注及句法分析,开发了二语句法复杂度分析器(L2 Syntactic Complexity Analyzer)。该分析工具提取语言单位长度、句子复杂度、从属子句使用量、并列结构使用量、特定短语结构等五个类别的文本复杂度测量指标,对文本的句法复杂度进行全面详细的测量(陆小飞、许琪2016)。然而,除了句法复杂度之外,文本难度还应包括词汇复杂度、语义复杂度等其他层面的难度因素。因此,句法复杂度的分析结果需要与其他文本层面复杂度的分析结果相结合,从而得出相对全面的文本难度指标。
基于信息计算与应用技术,很多学者将信息熵(Shannon 1948)引入文本复杂度的测量(如Juola 1998, 2008;Kockelman 2009;Febres&Jaffé 2017;Zhu&Lei 2018),信息熵越大表明文本所含的信息越多,文本越复杂。如Zhu&Lei(2018)分析了Hansard语料库中英国议会的演讲语料,通过计算不同时期语料的信息熵来分析其所反映的英国社会文化复杂度的历时变化。刑富坤、程东元、濮建忠(2008)通过计算词汇、句子、语篇层面的信息熵来测量文本复杂度,并开发了基于信息论的文本易读度测量系统(Informationbased Reada-bility Measuring System,IMRS)。将信息论与信息计算技术融入文本复杂度的测量超出了传统的主要关注文本表层信息如词长、句长、词频等范畴的文本复杂度测量,为文本复杂度的测量与研究提供了新思路。
基于数据挖掘技术,数据挖掘能高效处理大规模数据,从大量数据中发现隐藏的模式和知识(Gorunescu 2011)。由于此类方法以数据为驱动,无需对变量之间的关系做出预设,对数据的分布也没有严格要求(Perkins et al.1995;Keith 2006;Aryadoust 2015),越来越多的学者尝试将数据挖掘技术应用于文本复杂度研究。如付宇博(2018)用一系列文本特征如文章的总词数、词族、平均句子长度、从句数量等,通过构建决策树模型对文本难度进行预测,其预测准确率达92.5%,但尚未有研究将此类技术应用于三项考试的阅读文本难度对比研究。
本研究将采用数据挖掘方法对比研究六级、雅思、托福阅读文本的难度,主要解决以下三个研究问题:1)哪些文本难度特征能否有效区分六级、雅思、托福阅读文本?2)在这些区别性文本特征上,上述三项考试的阅读文本有何差异?3)在本文所使用的决策树、逻辑回归、朴素贝叶斯三种数据挖掘方法中,哪种方法最有效?
3.研究设计
3.1 研究数据
本研究收集了从2006年至2016年1六级真题阅读理解文本132篇,剑桥雅思真题4-12册阅读文本134篇,托福网上练习TPO 1-50阅读文本74篇。
3.2 数据分析方法
决策树、逻辑回归、朴素贝叶斯这三种方法是数据挖掘中最常用的分类算法,简单易操作且模型结果易解释(Aryadoust&Goh 2014;Meng et al.2017)。因此,本文将采用这三种方法对三项考试阅读文本进行自动分类。对于模型评估,本文采用常用的指标准确率(accuracy)、召回率(recall)、精确度(precision)、F1、ROC 面积等。
3.3 研究工具
研究使用的工具有Coh-Metrix和WEKA。Coh-Metrix是自动文本分析工具,能对文本进行11个模块的分析。这些模块包括描述性统计量、文本易读性主成分得分、指称衔接、潜语义分析、词汇多样性、连词、情景模式、句法复杂度、句法型式密度、词汇信息、可读性(McNamara et al.2014;江进林2016)。研究使用Coh-Metrix提取一系列用于自动文本分类的文本特征。
WEKA是较为成熟的数据挖掘工具,可以实现分类、聚类、关联规则分析等数据挖掘任务,具备特征选择以及结果可视化等功能,操作简单(Mark et al.2016)。研究将使用WEKA进行数据挖掘实验。
3.4 研究步骤
如图1所示,研究首先收集了六级、雅思、托福阅读文本,并做了相应的预处理,如删除原文中个别词语的中文释义、改正拼写错误、删除空格等。然后用Coh-Metrix对收集到的文本进行分析,共得到106个文本特征。因特征过多会影响模型的性能,也可能导致模型不易解释,故本研究从上述106个特征中选取43个特征(见表1)用于文本自动分类,选择的主要依据是已有文献基础,尤其是关于文本加工过程所涉及的认知因素、文本易读度、文本分析等相关研究,例如McNamara等(2014)发现文本包含的已知信息多,有助于文本的加工,因此新旧信息比这个文本特征被选用;Khalifa&Weir(2009)指出语义更具体的词语容易激活读者对该词语的心理意象,因此有助于文本的理解,于是词汇语义具体性这个特征被选用。本研究使用数据挖掘工具WEKA 3.9进行文本分类。

图1 研究步骤
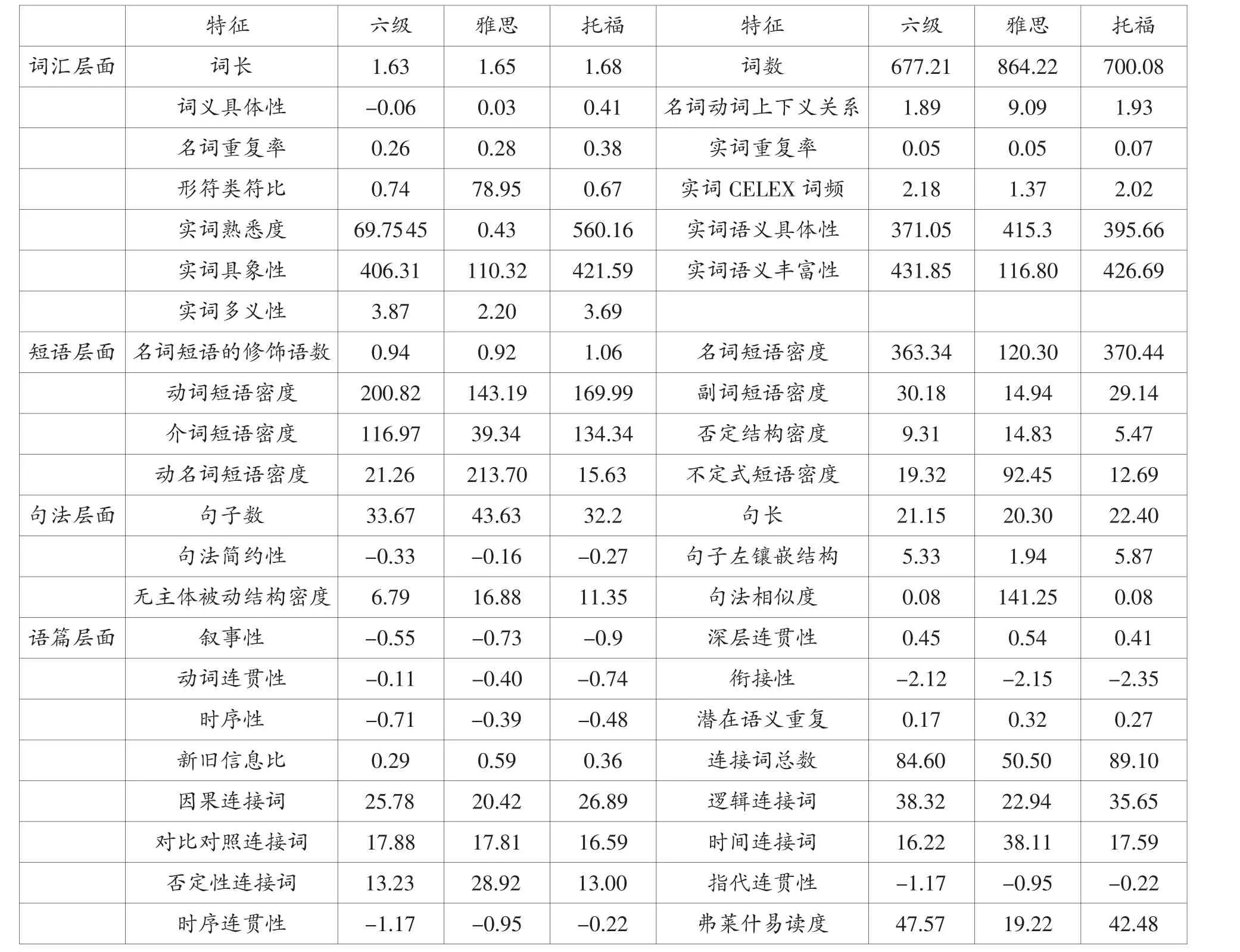
表1 三项考试阅读文本的43个特征及平均值
4.结果
本节将分别详细报告三种数据挖掘方法所得出的分类结果,然后选出分类效果最佳的模型。
4.1 决策树的分类结果
如表2所示,决策树分类的准确率达90.29%,即在所有样本中,90.29%的样本被正确分类;召回率达90.3%,即在所有正样本中,90.3%的正样本被正确分类,仅9.7%的正样本被错误地识别为负样本;精确度达90.4%,表明所有被识别为正样本的数据中,被正确识别的正样本占90.4%,原本为负样本却被错误地识别为正样本的数据仅9.6%;F1值和ROC面积分别为0.903和0.942,均非常接近1,表明分类结果较准确,决策树分类器的性能相当好。
具体对比三项考试阅读文本的分类结果发现,六级阅读文本分类的召回率(93.9%)、精确度(96.9%)、F1值(0.954)最高,其次为雅思阅读文本(分别是89.6%,86.3%,0.879),最后是托福阅读文本(分别是85.1%,86.3%,0.857)。值得特别一提的是,三项考试阅读文本分类结果中,ROC面积均大于0.92,表明分类效果相当好。由此可见,在三项考试的阅读文本分类中,六级阅读文本的分类效果最好,雅思阅读文本次之,最后是托福阅读文本。

表2 决策树分类结果
4.2 逻辑回归分类结果
如表3所示,逻辑回归分类的准确率为78.82%,召回率为78.8%,精确度为78.7%,F1值为0.787,ROC面积为0.911。上述指标表明逻辑回归的分类效果不理想。对比三项考试阅读文本的分类结果发现,除ROC面积外,六级阅读文本和雅思阅读文本的各项分类指标比较接近,而托福阅读文本的各项分类指标则远低于前两项考试阅读文本。由此可见,六级阅读文本和雅思阅读文本的分类结果相当,托福阅读文本的分类结果较差。

表3 逻辑回归分类结果
4.3 朴素贝叶斯分类结果
如表4所示,朴素贝叶斯分类的准确率为88.52%,召回率为88.5%,精确度为90.2%,F1值为0.882,ROC面积为0.955。上述指标表明,朴素贝叶斯的分类效果较好。
具体对比三项考试阅读文本分类结果发现,六级阅读文本分类的召回率(100%)和托福阅读文本分类的召回率(94.6%)远高于雅思阅读文本分类的召回率(73.9%);雅思阅读文本分类的精确度(100%)远高于六级阅读文本(84.1%)和托福阅读文本(83.3%);六级阅读文本分类的F1值(0.913)和ROC面积最高(0.983),托福阅读文本次之,最后是雅思阅读文本。上述模型评估指标表明,在朴素贝叶斯分类结果中,三项考试阅读文本的分类效果没有呈现明显的优劣趋势。
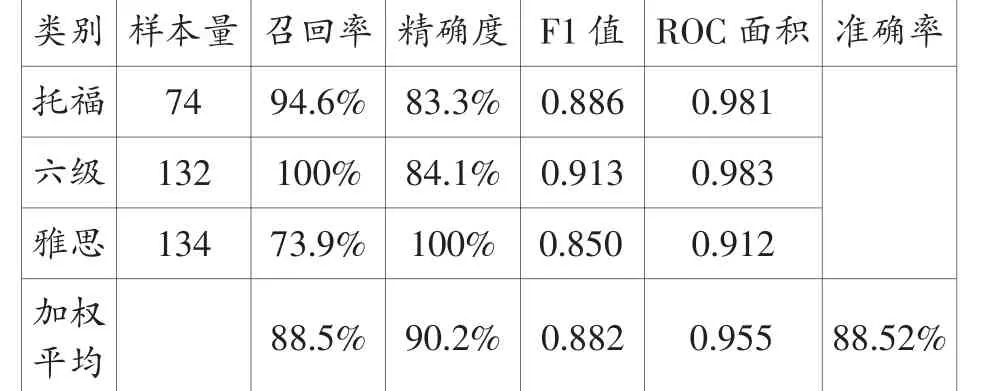
表4 朴素贝叶斯分类结果
4.4 三种数据挖掘方法分类结果对比
由表5可以看出,决策树和朴素贝叶斯的各项指标较接近,且二者都远高于逻辑回归;朴素贝叶斯的ROC面积最大,决策树次之,最后是逻辑回归。综合上述模型评估指标发现,决策树的分类效果最佳,朴素贝叶斯次之,最后是逻辑回归。
由分类效果最好的决策树文本分类结果可以看出,本研究所考查的43个文本特征确实能够非常准确地将六级、雅思和托福的阅读文本区分出来。换言之,三项考试的阅读文本在上述43个文本特征上存在差异。
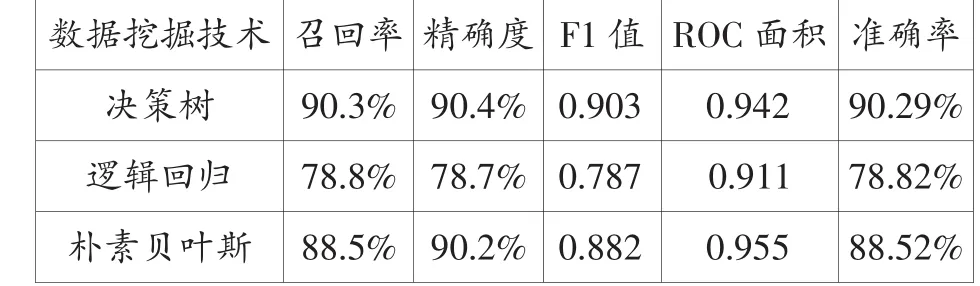
表5 数据分类结果对比
5.讨论
本研究的数据分析结果表明,三项考试的阅读文本在本文所选取的43个文本特征上存在差异,这些文本特征可以分为词汇、短语、句法、语篇四个层面,下文将从上述四个层面对本研究的数据分析结果进行讨论。
在词汇层面,从表1可以看出,雅思阅读文本的词汇(78.95)比六级(0.74)和托福(0.67)多样;托福阅读文本的词义具体性最高(0.41),而六级阅读文本的词义具体性最低(-0.06);较之雅思(450.43)和托福(560.16),六级阅读文本的实词熟悉度最低(69.75);雅思阅读词汇具象性(110.32)远低于六级(406.31)和托福(421.59);雅思阅读词汇丰富性(116.80)远低于六级(431.85)和托福(426.69);与六级(1.89)和托福(1.93)相比,雅思阅读文本的词汇上下义关系指标显示,雅思阅读文本使用了更多语义具体的词汇(9.09)。
在短语层面上,与六级和托福相比,雅思阅读文本的名词短语、动词短语、副词短语、介词短语少很多;相反,雅思阅读文本的动名词短语比六级和托福多得多(15.63<21.26<213.70),其不定式短语比六级和托福多得多(12.69<19.32<92.45),其否定结构也比六级和托福多(5.47<9.31<14.83)。
在句子层面上,雅思阅读文本的句子中左镶嵌结构比六级和托福少(1.94<5.33<5.87);雅思阅读文本的无主体被动结构最多(16.88),托福阅读文本次之(11.35),六级阅读文本的无主体被动结构最少(6.79)。
在语篇层面上,与六级阅读文本(84.60)和托福阅读文本(89.10)相比,雅思阅读文本(50.50)的连接词总数较前两者少;雅思阅读文本的逻辑连接词比六级和托福少,但其时间性连接词和否定连接词较其他两者多,其弗莱士易读度指标比其他两者低。
6.结语
本文采用三种数据挖掘方法,对六级、雅思、托福阅读文本进行对比,运用Coh-Metrix对所收集的340篇三项考试的阅读文本进行特征提取,共获取106个文本特征,其中有43个被选为预测变量。然后分别训练决策树、逻辑回归、朴素贝叶斯模型对三项考试阅读文本进行分类。根据分类精确率、召回率、F1和ROC面积等指标对模型进行评估。结果表明,所选的43个文本特征能有效区分三项考试的阅读文本,分类准确率达到90.29%。在三种模型中,决策树的分类效果最好,朴素贝叶斯次之,最后是逻辑回归。研究发现,六级、雅思、托福考试的阅读文本在词汇、短语、句子和语篇层面存在诸多具体的差异。探明这些差异,有助于试题开发者进一步明确三项考试阅读文本的不同,在分数解释、测试材料选择、文本改编、计算机自适应测试和考试对接等方面对三项考试,甚至更广泛的语言测试领域产生实质性的影响。此外,本文尝试数据挖掘方法,有望为相关研究提供思路和方法上的参考。
注释:
1 因2006年大学英语四、六级改革,至2016年有10年的时间跨度,2006年也是托福网考全面实施的一年,因此本文选用了2006-2016年三项考试的阅读文本进行对比研究。
猜你喜欢
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
留学(2019年14期)2019-08-23
留学(2018年24期)2018-05-14
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
甘肃教育(2017年15期)2017-09-30
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
中学生天地·高中学习版(2015年5期)2015-06-02
