
融合主题及上下文特征的汉缅双语词汇抽取方法
2021-02-05 03:26毛存礼余正涛高盛祥王振晗张亚飞
小型微型计算机系统 2021年1期
李 越,毛存礼,2,余正涛,2,高盛祥,2,王振晗,2,张亚飞,2
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 云南省人工智能重点实验室,昆明 650500)
1 引 言
缅甸语属于一种资源稀缺型语言,汉-缅双语平行资源相对稀缺,但互联网中有一定规模的汉语-缅语双语资源,这些双语资源大多是主题相关,内容相似的可比文档.汉-缅双语可比文档语料中存在一些具有互译关系的双语词汇数据,这些互译词语一般出现在语义相近但语言不同的上下文环境中.抽取这些数据能有效改善汉、缅双语平行资源稀缺问题,进一步为开展跨语言检索研究[1,2]及机器翻译[3,4]提供资源支撑.
在先前的工作中,有研究者利用双语LDA和上下文向量组合的方法从可比语料中抽取双语词汇,取得不错的效果.但对于资源稀缺的缅甸语来说,构建汉缅双语LDA需要大量标记好的双语平行语料,同时词袋模型表征的上下文向量没有考虑上下文语义和词语位置的影响,且维度较高.
在前人的基础上,为了获取具有上下文语义特征的上下文向量,克服汉缅双语LDA难以构建的问题.本文提出了一种融合主题及上下文特征的汉缅双语词汇抽取方法:本文首先利用单语LDA结合种子词典的方法抽取到具有主题特征的主题双语词汇,然后用多语言BERT对主题候选词的上下文语义进行向量化表示,得到具有上下文语义特征的表示向量,再计算上下文的相似度得到具有上下文语义特征的双语词汇,最后与主题双语词汇加权组合得到更高质量的双语词汇.
2 相关工作
目前,针对从可比语料抽取双语词汇问题,主要有以下四类方法:
1)基于双语词典的方法,其主要思想是通过一个种子词典学习到一个映射矩阵,将两种语言的词向量表示在同一语义空间中计算双语词向量的相似度抽取双语词汇,如,Artetxe[5,6]等人提出基于种子词典来抽取双语词汇,在大量的单语语料中训练表征成单语词向量,再通过种子词典学习到双语映射关系,将两种单语词向量映射到同一个语义空间,计算两种语言的词向量的相似度来抽取双语词汇.但此类方法依赖于大规模且高质量的双语词典.
2)基于枢轴语言的方法,其主要思想是将源语言和目标语言翻译成一种通用语言,在通用语言的语义空间中计算相似度抽取双语汇.如,Kim等人[7,8]提出一种基于枢轴语言抽取双语词汇的方法,首先将源语言转换为英语,再将目标语言转换到英语最后在同一语义空间下计算相似度完成双语词汇的抽取.然而此类方法需要建立大规模对齐语料库,并且依赖于机器翻译的翻译效果.

4)基于上下文的方法,其主要思想是具有相似含义的词很可能出现在跨语言的相似上下文中.如,从Rapp等人[12]开始,他们利用Harris(1954)[13]提出的分布假设,提出了一种基于上下文的方法(CBM)抽取双语词汇,将跨语言词汇相似度计算问题转化为计算源语言和目标语言词汇对应的上下文向量的相似性来抽取双语词汇.此类方法的缺点是忽略了词序关系对上下文向量的影响且容易出现高维问题.
3 融合主题及上下文特征的汉缅双语词汇抽取
我们提出的双语词汇抽取方法如图1所示,基本思路如下:

图1 融合主题特征及上下文特征的汉缅双语词汇抽取架构Fig.1 Chinese-Burmese bilingual vocabulary extraction architecture integrating topic features and context features


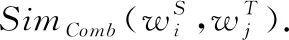
3.1 基于主题特征的汉缅双语候选词汇抽取
LDA(Latent Dirichlet Allocation)[14]是用来在一系列文档中发现抽象主题的一种统计模型.换句话说就是在一篇文章中有一个中心思想,那么一定存在一些出现频率比较高的词.LDA也是一种生成模型,一篇文章中每个词都是通过“以一定概率选择某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的.每个主题下的主题词都服从一个多项式分布(Multinomial distribution).LDA的概率图模型如图2所示.

图2 LDA概率模型图Fig.2 LDA probability model
在图2中,α,β分别是文本-主题和主题-词汇分布的先验参数.d代表一篇文本.θ为文本中主题-文档的概率分布参数,φ则为每一个主题分布下词语的分布参数.Z表示为其中一个主题,W表示为一个词汇,M表示文档总数,N表示所有文档中的词的总数.由于吉普斯采样具有简单、快速的特点,所以本文采用吉布斯采样[15]方法来训练.假设我们从一组汉语词汇表WS抽取出一个词wi,给定一个汉语主题分布zk.则其词-主题概率分布为:
(1)
其中,n代表主题分配到词汇表中的单词次数.|WS|代表词汇表中不同单词的总数.∑j=1|WS|n分配给主题的单词总数.首先利用LDA主题模型从汉缅新闻篇章抽取到汉缅主题集合,得到每个主题下的词-概率分布,其次通过汉语篇章文本和缅甸语篇章文本抽取到的各自主题来训练汉语和缅甸语的主题词向量,分别令xi表示汉语主题词的连续向量表示,zj表示缅语主题词的连续向量表示.利用种子词典学习到映射矩阵W,通过映射Wxi到缅语语言空间,计算Wxi与zj向量之间的余弦相似度,如果汉缅双语词向量之间的相似性越高,那它们之间是互译词汇的准确率也越高.本文采用余弦相似度计算汉缅双语词向量之间的相似度,计算公式如下所示:
(2)
然后对上述相似度进行排序,选取前N个缅语作为汉语单词的候选翻译列表.
3.2 基于BERT的候选词汇的上下文表征
基于此,本文采用 Google开源的BERT模型来构造候选词汇的上下文特征表示,可以从候选词汇的前后单词中学习其上下文关系.BERT的设计基于Transformer[19]网络结构.Transformer对当前的输入,分别计算Key,Query,Value向量,并基于上述向量对每个输入使用注意力机制,以获得当前输入与上下文语义的关系和自身所包含的信息.通过多层累加和多头注意力机制,不断获取当前输入更为合适的向量表示.所以利用多语言BERT模型训练主题双语词汇能得到更好的上下文特征表示,设Si为汉语主题词的上下文特征表示,Tj为缅语主题词的上下文特征表示,则余弦相似度为:
(3)
一旦提取上下文双语词汇,我们将它们与主题双语词汇相结合.结合后,词汇的质量将得到提高.因此,我们进一步使用组合词汇作为新的种子词典,继而抽取到更好的汉缅双语词汇.通过重复这些步骤,上下文双语词汇和组合双语词汇质量将被反复改进,直至模型收敛.
3.3 基于联合的方法抽取汉缅双语词汇

(4)
其中λ是两种方法线性结合过程中的超参数.我们首先使用主题特征的方法为汉语单词生成一个前N个候选列表(缅甸语候选词).然后通过上下文特征向量计算候选列表词中的相似度.最后,我们进行组合.因此,组合过程是一次对基于主题特征抽取的候选词的重新排序实现汉缅双语词汇抽取.
4 实验结果与分析
4.1 实验数据跟参数设置
为了避免数据的单一性,我们分别从汉-缅双语网站、缅甸官方新闻网站、中文新闻网站、微信公众号等网络平台获取778篇汉-缅双语可比文档,覆盖了政治,军事,娱乐等多个方面,这些语料包括政治领域271篇,军事领域296篇,娱乐领域211篇,合计778篇.其中汉语的平均句子长度为23,缅语的平均句子长度为18,如表1所示.

表1 汉-缅双语可比文档数据集Table 1 Chinese-Burmese comparable document data set
接着我们对搜集到的语料进行预处理,利用昆明理工大学智能信息处理重点实验室研发的缅甸语分词工具对缅甸语进行分词,利用jieba分词工具对汉语进行分词,去除停用词等处理.此外,通过人工方式构建了一个小规模的汉-缅双语种子词典,如表2所示.

表2 训练汉-缅双语词向量的种子词典规模Table 2 Seed dictionary scale for training Chinese-Burmese bilingual word vectors
LDA模型中设置训练的超参数α=0.1,β=0.1,迭代次数为500次,每篇文章的主题数为5;词向量维度设置300维;对于我们提出的方法,我们根据经验设置线性组合参数λ=0.8.
4.2 实验方法和评价指标
为了验证本文方法在汉缅双语词汇抽取的效果,设计了3组对比实验.
对比实验1.本文与当前其他方法的对比实验
对比实验2.不同种子词典规模对词汇抽取的影响
对比实验3.在不同P@N值下词汇抽取的准确率
本文将准确率P@N(前N个候选翻译的准确率)作为评价指标,定义如下:
(5)
其中,S代表实验中对应的是测试词典中词的总数;wi代表测试词典中的源词,|T(wi)|代表在测试词典中源词对应的目标词汇.
4.3 实验分析
实验1.当前的双语词汇抽取方法与本文方法实验结果比较.

表3 本文方法与其他方法抽取双语词汇的准确率Table 3 Accuracy of bilingual vocabulary extraction with this method and other methods
由表3可知,我们提出的方法可以显著提高汉缅双语词汇的准确率.实验结果也表明明显优于其他几种方法,同基于双语LDA+CBW的方法相比,本文方法准确率提升了3.82%,主要原因在于BERT不仅仅是只关注一个词前文或后文的信息,而是整个模型的所有层都去关注其整个上下文的语境信息,得到更好的上下文特征表示向量.同基于双语词典的方法和基于枢轴语言的方法相比,本文方法准确率分别提升了11.07%和13.27%.主要原因在于基于双语词典的方法未考虑到双语可比文档的主题特征对候选翻译的有效约束和基于枢轴语言的方法容易出现一词多译,错译等问题.
实验2.种子词典规模对抽取词汇效果的影响.

图3 不同种子词典规模下的准确率Fig.3 Accuracy at different seed dictionary sizes
其次,种子词典是汉缅两种语义空间的中间桥梁,其规模大小对抽取的准确率也有着非常重要的影响.我们将种子词典分成不同比例的规模大小,然后进行对比实验.实验结果如图3所示.从图3中可以看出,伴随着种子词典规模的扩大,抽取到的汉缅双语词汇准确率一直在逐渐上升.当词典规模比例从0.8增加到1的时候,准确率上升的比较慢,主要原因是汉缅可比文档中,常见词已经得到补充,而生僻词的出现导致模型达到饱和.
实验3.为验证方法的准确率与抽取的候选词个数之间的关系,实验还比较了P@1、P@5 和 P@10 的准确率.具体实验结果见表4.

表4 本文方法在不同P@N值下的准确率Table 4 Accuracy of this method under different P@N values
分析表4可知,本文方法的准确率随候选词的增多而逐渐上升,当候选词数量为 1 时便可获得较高的准确率,而当候选词为10 时,准确率可以达到74.58%,这同时说明了不同语言在向量空间上具有同构性.
5 总 结
为了抽取汉缅双语词汇,本文提出了一种融合主题及上下文特征的汉缅双语词汇抽取方法.有效利用了汉缅双语主题的特征信息和上下文信息,进而抽取到质量更高的双语词汇.实验结果表明,本文方法相比其他仅使用主题特征和上下文特征的方法相比,准确率有明显提升.同基于双语LDA+CBW的方法相比,本文克服了汉缅双语LDA难以构建的问题,同时利用BERT训练得到具有上下文语义特征的上下文表示向量,进一步提升了汉缅双语词汇的准确率.在未来的研究当中,我们可以将该方法用于其他稀缺语言中,如汉语-老挝语、柬埔寨等东南亚语言双语词汇抽取,为开展面向汉语-东南亚语跨语言检索及机器翻译研究提供数据支撑.
猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
新晨(2013年7期)2014-09-29
新晨(2013年5期)2014-09-29
新晨(2013年10期)2014-09-29
