
一种优化的标签传播方法
2021-02-05 03:26张霄宏史爱静贾慧娟任建吉
小型微型计算机系统 2021年1期
张霄宏,史爱静,贾慧娟,2,任建吉
1(河南理工大学 计算机科学与技术学院,河南 焦作 454000) 2(吉林大学 计算机科学与技术学院,长春 130012)
1 引 言
复杂网络自诞生以来就引起了业界的极大关注.复杂网络具有明显的社区结构,社区内部的节点联系紧密,而社区之间的节点联系微弱[1,2].如果各个社区中的节点没有重合,则称这些社区为非重叠社区.如何发现非重叠社区一直是复杂网络分析中的一个研究重点.
研究人员提出了许多非重叠社区发现方法,如基于图划分的KL算法[3]、GN算法[4]、模块度优化算法[5]、基于遗传算法[6]等.其中,标签传播算法(Lable Propagation Algorithm,LPA)[7]因在处理复杂网络时具有线性时间复杂度,而受到广泛关注[8].然而,标签传播算法采用的随机策略降低了算法稳定性和效率.为优化标签传播算法,基于核心节点搜索[9]、节点重要性[10,11]、节点引力[12]等因素的优化方法不断提出,但由随机策略引起的问题仍然存在.虽然Zhang等人[13]针对由随机策略引起的问题提出了基于标签传播的局部优化方法Pre-LPA,但是如何解决由随机策略引起的问题,仍然是一个开放性问题.
针对这一问题,本文提出了一种优化的标签传播方法.该方法引入标签二元组,根据标签权重、节点间的联系度等因素为节点分配初始化标签;同时,在标签传播过程中根据节点间的联系度等因素进行标签更新.通过这些措施,降低随机策略对社区划分结果和效率的影响.
2 问题分析与相关工作
标签传播算法随机赋予每个节点唯一的标签,根据节点的随机顺序为每个节点选择在邻居节点上出现频率最高的标签,当多个标签出现频率相同时,随机选择一个标签分配给节点.这些随机策略降低了社区划分结果的稳定性和划分效率.
为改进标签传播算法,Shang等人[9]提出了一种通过循环搜索核心节点并根据节点的相似度进行标签传播的方法.Zhang等人[10]和Ma等人[11]提出了基于节点重要性进行社区检测的标签传播方法.Shen等人[12]提出了基于节点引力的标签传播方法.Zhang等人[14]提出了一种基于节点相似度运用并行计算的标签传播方法.Attal等人[15]提出了基于图形着色的标签传播方法.郑文萍等人[16]提出了基于参与系数、相似度和强弱社区进行两阶段社区发现的标签传播方法.许合力等人[17]提出了节点局部影响力来度量节点重要程度的标签传播算法.Tasgin等人[18]和Liu等人[19]分别提出了从边界节点和网络中核心领导节点出发加速标签传播速度的改进方法.张蕾等人[20]提出了基于三角结构来衡量标签权重的标签传播算法.Wang等人[21]提出了一种新的基于节点重要性的标签传播算法,该算法降低了LPA的随机策略引起的不稳定性.Li等人[22]设计了重新加权的网络,提出了基于主题的高阶结构以捕获网络的结构特征的标签传播算法.以上工作从不同角度对标签传播算法进行改进,虽然Zhang等人[13]针对由随机策略引起的问题提出了基于标签传播的局部优化方法,但如何解决由随机策略引起的社区划分的稳定性和效率问题仍是一个开放问题.
3 一种优化的标签传播方法
为应对标签传播算法采用的随机策略导致的稳定性和效率问题,本文拟通过节点间的联系度、标签权重等因素从标签初始化和标签传播两个过程入手对标签传播算法进行优化.
3.1 概念定义
本文用无向图表示复杂网络.图中节点代表复杂网络中的独立个体,边代表个体之间的联系.记图G为G=
为了便于介绍本文提出的方法,引入以下定义:
定义1.邻居节点.(∀vi)vi∈V,(∀vj)vj∈V,若存在(vi,vj)∈E,则节点vi和vj互为邻居节点.
定义2.邻居节点集合.(∀vi)vi∈V,vi的邻居节点集合记为Nvi,由式(1)描述.
Nvi={vj|(∃vj)vj∈Vand∃(vi,vj)∈E}
(1)
定义3.联系度.联系度刻画两个节点之间联系的紧密程度.
(∀vi)vi∈V,(∀vj)vj∈V且(vi,vj)∈E,vi和vj的联系度记为s(vi,vj)由式(2)计算.在该式中cvi,vj表示vi和vj邻居节点集合交集中共同节点之间的边数量.
(2)
定义4.节点影响力.节点影响力描述该节点对邻居节点影响的程度.
(∀vi)vi∈V,vi的节点影响力记为f(vi).文中f(vi)根据LeaderRank算法[23]求得.
定义5.标签权重.标签权重描述标签归属于某个节点的强度.

(3)
同一节点的标签对于不同的邻居节点会具有不同的权重.为此,引入了标签二元组(lvj,w(lvj,vi)),利用该二元组进行标签初始化处理.
3.2 标签初始化
为应对标签传播算法采用的随机初始化标签策略对社区划分结果带来的不利影响,本节借助标签二元组,根据标签权重、节点间联系度和节点影响力等因素对标签初始化过程进行改进.
具体来讲,先随机赋予节点唯一的标签,根据联系度等因素计算标签权重,构造标签二元组.从节点的邻居节点中选择权重最大的标签二元组对应的标签作为此节点初始化标签.

本文方法的标签初始化优化过程如算法1所示.该算法的时间复杂度约为:O(2n+mt+nlogn),n、m分别为网络中节点总数和总边数,t为LeaderRank算法收敛的迭代次数.
算法1.标签初始化优化
输入:G=
输出:V′
1.随机赋予每个节点一个唯一的标签.
2.计算各节点的影响力.
3.按节点影响力由大到小的顺序遍历节点.
4.对每个遍历到的节点按初始化规则1-规则4更新节点的初始化标签.
5.返回V′//V′是包含优化的初始化标签的节点集合.
图1展示了根据初始化规则1和规则3分别对示例网络中v8和v5进行标签初始化的过程.对于v8,3个邻居节点,v5,v6和v7相对于v8的标签二元组分别为(ε,2/5),(ζ,3/4)和(η,1/2).由这些二元组可知,v6的标签具备的标签权重最大,根据初始化规则1将标签ζ指定为v8的初始化标签.对于v5,3个邻居节点v4、v6、和v8相对于v5的标签二元组分别为(δ,1/6),(ζ,2/5)和(θ,2/5).由于v6和v8的标签权重相同,确定v5初始化标签时应摒弃初始化规则1;由于联系度s(v5,v6)和s(v5,v8)也相同,初始化规则2也不适用于v5;由于邻居节点v6和v8具有不同的影响力,故根据初始化规则3给v5指定初始化标签θ.

图1 节点的标签初始化过程的拓扑图Fig.1 Topological diagram of the label initialization process of nodes
3.3 标签传播

同时,在标签传播过程中,按节点影响力从大到小的顺序遍历节点,以此降低按随机顺序遍历节点带来的标签逆流及标签的无意义更新造成的效率问题[13,24].本文方法的标签更新过程如算法2所示.该算法的时间复杂度约为O(n),n为网络中节点总数.
算法2.本文方法的标签更新过程
输入:网络G=
输出:V″//包含最终标签传播结果的节点集合
1.按节点影响力由大到小的顺序遍历节点.
2.对于已标签初始化的每个节点执行以下步骤:
3.根据邻居节点的标签出现频率、节点间的联系度两项因素从传播规则1-传播规则3中选择合适的规则更新节点标签.
4.重复2-3直至满足收敛条件.
5.返回V″
4 方法评估
本文通过在真实网络数据集和人工生成的网络数据集上和不同的方法对比,来验证本文方法的正确性和有效性.
4.1 实验设置
实验中用到的所有的复杂网络均为无向无权网络.真实网络数据集包括7个,这些真实网络数据集的参数如表1所示.人工网络数据集由LFR基准发生器[25]生成的20个人工网络构成.前10个人工网络包含的节点总数均为1000,节点的平均度为15,最大度数为50,生成的社区规模从20~50不等.生成的第1个人工网络使用的混合参数μ为0.05,后续人工网络生成时采用的μ值是在前1个网络μ值的基础上增加0.05得到.后10个人工网络包含的节点总数均为3000,节点的平均度为35,最大度数为100,生成的社区规模从60-150不等.生成的第1个人工网络使用的混合参数μ为0.05,后续人工网络生成时采用的μ值是在前1个网络μ值的基础上增加0.05得到.

表1 真实网络数据集基本结构参数Table 1 Basic data parameters of the real network data set
实验通过和Pre-LPA[13],LPA[7],LPAm[26],fastgreedy[27]共4种不同的方法对比,来验证本文方法的正确性和有效性,所有的方法均在Windows 10操作系统中运行,该操作系统运行在由Intel i5-7200U CPU、8.00GB内存等硬件构成的实验平台上.
在实验过程中,采用模块度Q和标准互信息NMI作为评价标准,且所有的评价都是运行50次产生的平均结果.
4.2 结果分析
图2展示了5种不同的方法在真实网络数据集上的运行结果计算的Q平均值.由图2可知,本文方法在真实网络数据集Karate、Football、Dolphins、Polblogs和Lesmis上取得的Q平均值比其他方法都大,在Physicians数据集上与fastgreedy方法取得相同的Q平均值,在Polbooks网络数据集上,获得的Q平均值比LPAm方法较低.
图3展示了5种不同的方法在真实网络数据集上运行结果计算的NMI平均值.由图3可知,本文方法在真实网络数据集Polbook,Football,Dolphins上取得的NMI平均值比其他方法都大,在Polblogs数据集上与Pre_LPA方法取得相同的NMI平均值,在Karate网络数据集上,获得的NMI平均值比Pre_LPA方法较低.
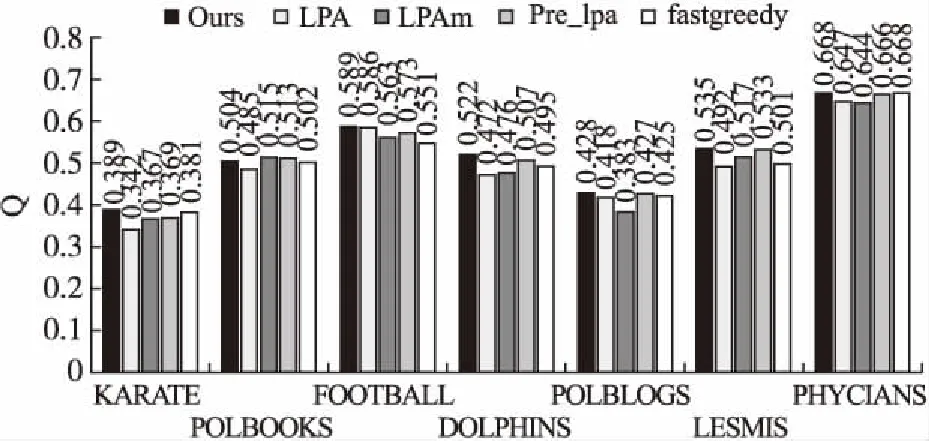
图2 真实网络数据集上的Q平均值对比Fig.2 Comparison of Q averages on real network data sets

图3 真实网络数据集上的NMI平均值对比Fig.3 Comparison of NMI averages on real network data sets
表2展示了5种不同的方法在节点总数均为1000的人工网络数据集上运行结果计算的Q平均值.由表2可知,本文方法和Pre_LPA比其他方法划分结果质量要高.且在绝大多数人工网络数据集上,本文方法比Pre_LPA效果要好.
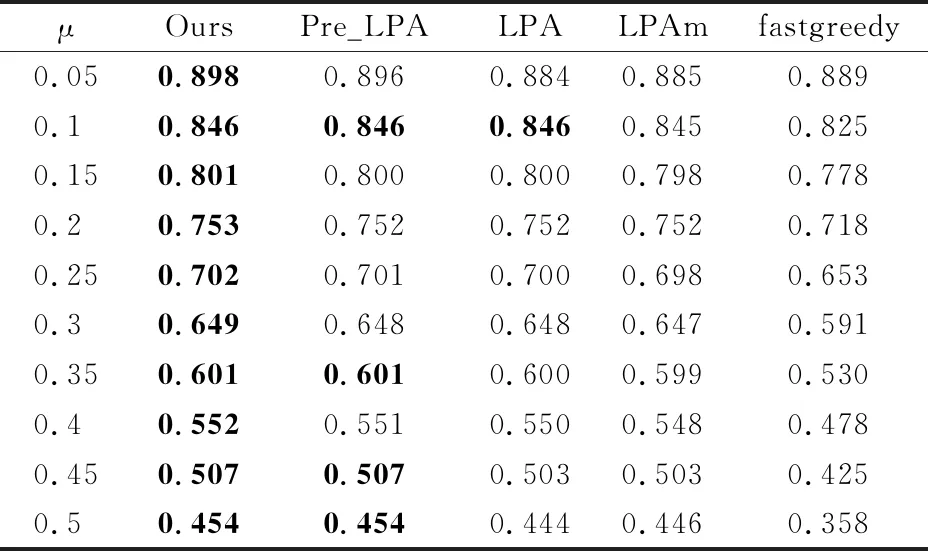
表2 节点总数均为1000的人工网络上的Q平均值对比Table 2 Comparison of Q on artificial network data sets
表3展示了5种不同的方法在节点总数均为1000的人工网络数据集上运行结果计算的NMI平均值.由表3可知,随着μ值的增大,方法LPA,LPAm,fastgreedy所得NMI值都有明显下降,稳定性比本文方法和Pre-LPA要差.从μ为0.45、0.5时对应的人工网络上的结果来看,本文方法比Pre-LPA方法有更高的结果.
表4展示了5种不同的方法在节点总数均为3000的人工网络数据集上运行结果计算的Q平均值.由表4可知,随着μ值的增大,5种不同的方法取得的Q平均值均有所减小.当μ为0.05时,本文方法、Pre_LPA和LPA取得的Q平均值相等,除此之外,本文方法比其他方法划分结果质量要高.

表3 节点总数均为1000的人工网络上的NMI平均值对比Table 3 Comparison of NMI on artificial network data sets

表4 节点总数均为3000的人工网络上的Q平均值对比Table 4 Comparison of Q on artificial network data sets
表5展示了5种不同的方法在节点总数均为3000的人工网络数据集上运行结果计算的NMI平均值.由表5可知,随着μ值的增大,方法LPA,LPAm,fastgreedy所得NMI值都

表5 节点总数均为3000的人工网络上的NMI平均值对比Table 5 Comparison of NMI on artificial network data sets
有明显下降,稳定性比本文方法和Pre-LPA要差.从μ为0.25、0.3、0.35、0.4、0.5时对应的人工网络上的结果来看,本文方法比Pre-LPA方法有更高的结果.
5 结束语
本文提出了一种优化的标签传播方法,该方法引入标签权重与标签一起组成标签二元组,根据标签权重、节点间的联系度等因素为节点分配初始化标签;同时,在标签传播过程中根据节点间的联系度等因素进行标签更新.实验结果证明了本文方法的有效性和有用性.
猜你喜欢
军事文摘(2022年8期)2022-11-03
计算机研究与发展(2022年1期)2022-01-19
哈哈画报(2021年11期)2021-02-28
新课程·下旬(2018年7期)2018-01-19
家教世界·创新阅读(2016年9期)2016-05-14
文苑(2015年9期)2015-09-10
文理导航(2015年14期)2015-05-22
中学数学杂志(高中版)(2014年2期)2014-05-26
新课程学习·中(2013年3期)2013-06-14
科学启蒙(2009年12期)2009-12-15
