
基于SysML&SystemC的GPU任务调度单元事务级建模
2021-03-16 08:30张少锋吴晓成
无线电工程 2021年2期
张少锋,田 泽,3,吴晓成,张 骏,3,陈 佳
(1.航空工业西安航空计算技术研究所,陕西 西安 710068;2.西安翔腾微电子科技有限公司,陕西 西安 710068;3.集成电路与微系统设计航空科技重点实验室,陕西 西安 710068)
0 引言
在人工智能技术和各种并行计算应用蓬勃发展的今天,GPU作为高性能计算平台扮演着极其重要的角色,随着GPU芯片规模的日益复杂和庞大,其设计难度也日益增高。传统的“瀑布”式芯片设计及验证方法存在架构、软件和RTL之间缺乏有效的协同设计验证手段,导致算法、硬件结构、软硬件交互和软件实现的问题直到RTL仿真阶段才集中暴露出来,再加上无法避免的RTL逻辑实现缺陷,芯片设计各环节之间的迭代周期和难度大幅增加,传统的芯片设计及验证方法已不能满足架构复杂的GPU的设计开发要求。综合运用SysML和SystemC软硬件设计语言的基于事务级模型的芯片设计验证方法应运而生,给架构、软件和RTL设计提供了统一的协同设计验证载体,缩短了芯片设计验证的迭代环,逐渐成为主要方法[1-3]。
GPU是涉及计算机学、图形学和微电子学等多学科交叉的高复杂度集成电路,模块化设计是必由之路,其中任务调度单元是GPU的关键子模块,是连接用户着色任务和GPU染色内核的纽带。本文采用SysML和SystemC构建了任务调度单元的视图模型和事务级建模(Transaction-Level Modeling,TLM)模型,通过软硬件协同仿真,验证和优化了任务调度单元架构和算法设计,为软件开发提供了虚拟原型,并为RTL设计验证提供了先验依据和参考模型[4-8],有效降低了GPU设计验证迭代的复杂度,加速了GPU的设计验证进度。
1 基于SysML&SystemC的GPU设计开发方法
基于SysML&SystemC的复杂芯片设计开发方法是在传统的开发流程中加入了TLM模型,TLM模型提供了架构、软件、RTL三者交互的媒介,降低了三者之间的耦合度,有效降低了GPU设计验证迭代的复杂度,加速了GPU的设计验证进度。基于SysML&SystemC的复杂芯片设计开发流程如图1所示。
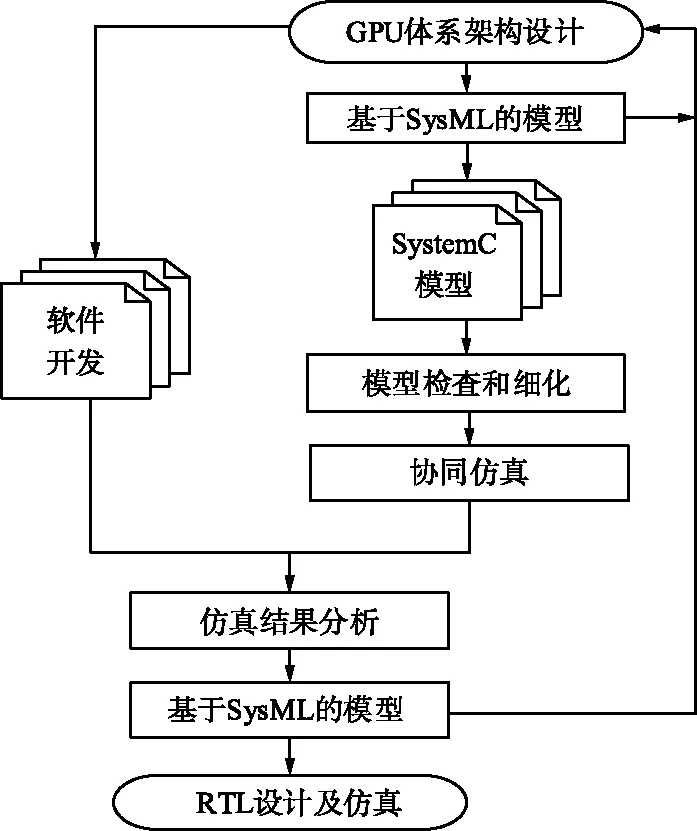
图1 基于SysML&SystemC的GPU设计开发流程Fig.1 GPU design and development process based on SysML&SystemC
在这种设计模式中,SysML用于系统架构的分析与设计,描述系统的需求、结构、功能及相应的行为,SystemC利用软硬件协同的思想建立事务级模型。首先根据体系架构设计建立SysML视图模型,然后将SysML视图模型映射为SystemC模型,SystemC模型经过检查和细化后形成TLM模型,然后联合软件进行软硬件协同仿真,最后对仿真结果进行分析以达到尽可能早的验证和优化架构以及算法的目的,并为RTL提供了参考设计。
1.1 SysML模型
SysML是由统一建模语言(Unified Modeling Language,UML)继承发展而来的能够表达丰富内容的可视化系统建模语言,能够支持各种复杂系统的详细分析、设计、验证和说明,可以把系统的结构、行为、需求和参数可视化,然后与其他人沟通这些信息。SysML定义了9种基本图形如2所示,包含模块定义图(Block Definition Diagram,BDD)、内部模块图(Internal Block Diagram,IBD)、包图、用例图、活动图、序列图、状态机图、参数图和需求图,可以使用它们说明系统的所有设计信息。每种图都针对特定的目的,并说明系统一个方面的特定信息[9-12]。
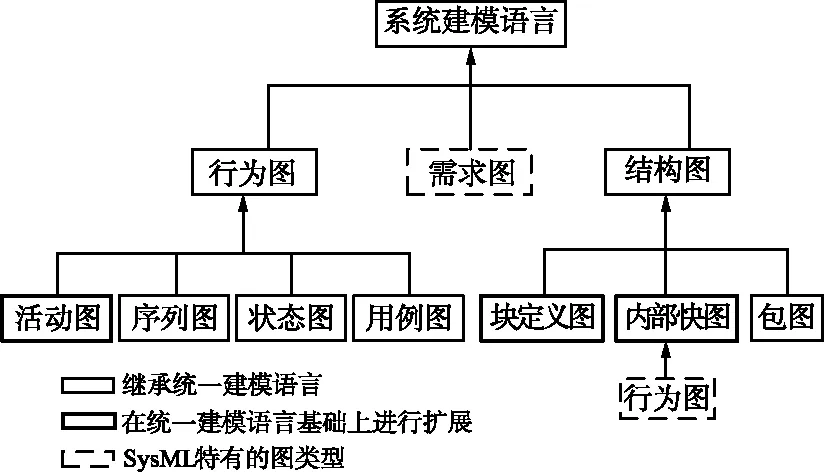
图2 SysML视图元素Fig.2 SysML view elements
1.2 基于SystemC的TLM模型
TLM模型是比RTL更高的抽象级别,是一种高级的数字系统模型化方法,它将模型间的通信细节与函数单元或通信架构的细节分离开来。由于TLM模型具有更高的抽象层次,它具备开发周期短和仿真速度快的特点,可以在项目早期验证算法和架构的正确性,为软件开发提供虚拟原型平台,还可以为RTL开发提供参考设计。
SystemC本质上是在C++的基础上添加了硬件扩展库和仿真内核,利用类的继承性来扩展C++在硬件开发验证领域的能力,所以它具备TLM的优势[9]。SystemC提供了必要的硬件时序、并发等概念,支持线程同步和通信细化,并提供了一个专门的扩展验证库,使得利用它可以建模不同抽象级别的复杂系统,既可以描述纯功能模型和系统体系结构,也可以描述软硬件的具体实现[13]。
如果迅速完成高层次系统行为的TLM描述,便可以确定最佳系统架构,进而逐步细化模型,并在模型基础上同时开展软件和硬件设计和验证,从而在保证设计优化的情况下减少仿真时间以加速设计收敛。TLM2.0中,事务级模型可以细分为非定时、松散定时、近似定时和周期精确模型,每个层次的模型应用场景有所不同,非定时模型可以提供虚拟原型,更快地验证架构和算法的正确性,松散定时模型主要用于体系结构分析、软件开发和软件性能评估,近似定时模型主要用于体系结构优化分析和硬件验证,周期精确模型更适合硬件RTL验证[14-15]。
本文采用SystemC TLM2.0进行松散时间的事务级建模,能在保证较快仿真速度的基础上快速建立硬件的可执行事务级模型,又能最大限度地精确描述硬件行为以评估优化体系架构。
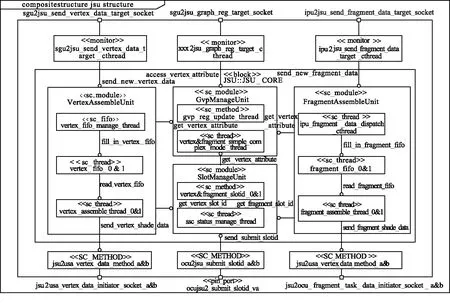
图3 GPU任务调度单元内部模块Fig.3 Internal block diagram of GPU task scheduling unit
2 SysML建模
SysML是UML在系统工程应用领域的延续和扩展,从视图模型的不同描述角度SysML视图可划分为需求图、参数图、结构图和行为图四大类。需求图和参数图是SysML语言针对复杂系统而设计的特有的图类,需求图用于识别、描述和管理芯片设计的需求,参数图用于说明系统的约束。SysML针对复杂系统在UML基础上对结构图和行为图进行了扩展。
本文采用Sparx Systems公司的Enterprise Architect建模工具构建SysML视图,通过梳理GPU架构和算法构建GPU任务调度单元的结构图和行为图。结构图和行为图的构建是逐步细化并且准确的过程,构建过程本身就达到了初步验证架构和算法的目的。SysML视图模型可以为架构、软件和RTL提供一个相对准确无歧义的信息交互媒介。
2.1 结构图
结构图中描述子模块结构的图是IBD,通过组件、端口和连接器来用于描述系统模块的内部结构和交互,组件包括SC_THREAD、SC_METHOD、sc_fifo和monitor,端口和连接器包括pin-port、 socket和API,socket是TLM2.0的核心内容。
GPU任务调度单元IBD如图3所示。
图3主要包括2个block:接口适配(JSU_Adapter)和内核(JSU_CORE)。接口适配一方面通过monitor监控和解析其他模块发送的控制信息和数据交给本单元的处理进程,另一方面通过SC_METHOD驱动本单元的输出信息到其他单元。与其他模块交互的通道是pin-port和socket,socket将在TLM建模中详细描述。任务调度单元内核包括顶点组装单元、片段组装单元、染色阵列管理单元和组装控制寄存器组管理单元。每个子单元都包含了若干个用于描述行为的组件。
通过JSU_Adapter和JSU_CORE的互联通信,完成GPU染色任务的调度工作包括:① 顶点组装单元按照组装控制寄存器组的控制信息将用户下发的符合OpenGL和GLSL标准的顶点着色任务进行组装并下发至分配的染色阵列单元;② 片段组装单元按照组装控制寄存器组的控制信息将图像处理单元或几何引擎单元下发的片段着色任务进行组装并下发至分配的统一染色阵列单元;③ 染色内核管理负责染色阵列资源分配映射和任务管理;④ 组装控制寄存器组管理单元用于接收和管理用户的组装控制信息。
2.2 行为图
行为图主要关注控制流程和模块内部状态变化,描述在事件触发下的不同状态间的转换和输入转化为输出的过程。在描述GPU任务调度单元时,行为图是对内部块图的一种细化,描述了线程或对象的关键成员函数的处理流程,展现一个线程基于事件反应的动态行为,显示了该线程如何根据当前所处的状态对不同事件做出不同的反应。
GPU任务调度单元是GPU的调度中枢,功能比较复杂,由于篇幅有限,只描述顶点组装单元的行为图。根据着色任务的复杂性,组装过程分为简单模式和复杂模式2种。不同的工作模式下,顶点组装单元的行为也不同,如图4所示。工作模式由组装控制寄存器组管理单元根据包括纹理开关、光照开关、雾开关等一系列开关计算形成的。顶点组装单元的fifo管理进程将来自状态参数与图形处理管理单元(SGU)的多个顶点的属性存入vertex_fifo,顶点属性包括坐标属性、颜色属性、纹理属性和光照属性等;然后由顶点组装进程组装为一个统一染色阵列(USA)上能够运行的vertex WARP,WARP是USA处理的最小单元;最后WARP被调度到对应的USA内核进行顶点着色处理。
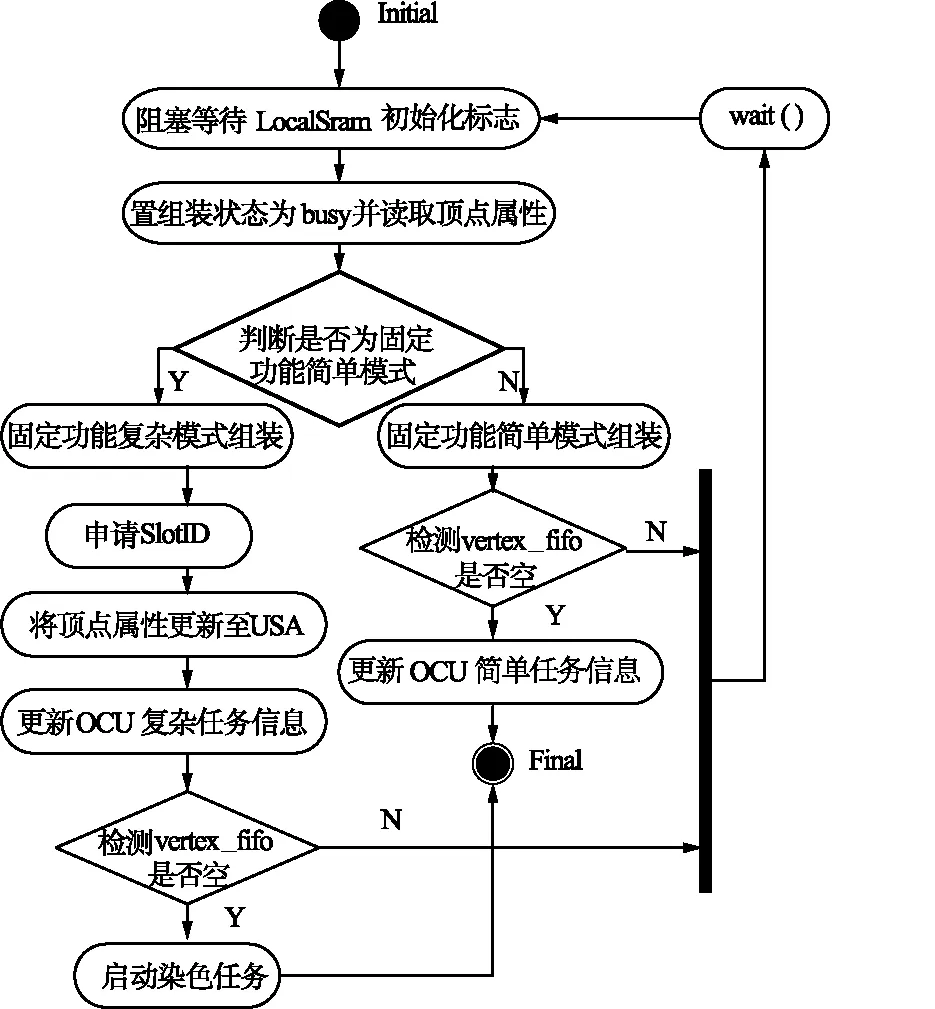
图4 顶点组装线程行为图Fig.4 Vertex assembling thread behavior diagram
3 基于SystemC的事务级建模及仿真
SysML视图模型经过多次迭代和梳理验证后,能较精准地描述芯片体系架构和算法流程,这时可以自然且直观地将视图模型以某种方式映射为事务级模型。本文采用SystemC&TLM2.0将SysML视图“翻译”为松散时间的事务级模型。结构图可以映射为模块定义,行为图可以映射为线程定义。
3.1 模块定义
与Verilog类似,模块是SystemC设计中完成特定功能的最基本单元,主要包含用于模块间通信的端口或信道,用于实现内部行为的方法、线程和存储模型。任务调度单元定义了2个module,分别是G3D_JSU_ADAPTER和G3D_JSU_CORE,G3D_JSU_ADAPTER继承于G3D_JSU_CORE,G3D_JSU_CORE继承于sc_module。
TLM2.0中,用pin-port来实现功能简单的信号并传递信息;完成同一类较复杂事务的多组信号可以封装为socket,利用TLM2.0对socket通信的支持来完成事务通信。发起事务的模块称为发起者(initiator),而接收该事务并作出响应的模块称为目标(target),发起者和目标之间通过套接字(socket)连接。发起者和目标模块必须遵守在TLM2.0中称为事务处理核心接口的接口标准才能互联互通。
TLM2.0提供了丰富的socket方法来建模功能行为,包括双向的非阻塞接口方法、阻塞接口方法、双向的DMI(Direct Memory Interface)接口方法、调试接口方法。这些方法用于解析模块间传递的控制信息和数据。
任务调度单元的G3D_JSU_ADAPTER包含了pin-ports、soket、socket function、api、thread的声明,实现的功能包括:① 将其他模块输入的信息或数据在socket function或thread 中进行解析,并调用api触发内核的相关处理操作;② 将内核要传输的信息在socket function中组包为payload通过socket发送,或者在thread中驱动pin-port端口通信。
G3D_JSU_CORE包含了api、method和thread的声明,实现的功能主要接收G3D_JSU_ADAPTER下发的信息交由method或thread进行处理,将处理结果通过纯虚函数API(该API在G3D_JSU_CORE 中声明,在G3D_JSU_ADAPTER实现)传送给G3D_JSU_ADAPTER再发送出去。2个module具体的实现如下:
classG3D_JSU_CORE:public
sc_core::sc_module
{protected: ∥ api functions
virtual void api1_send_vertex_shade_
data_to_usa_a () = 0;
private: ∥ process functions
∥顶点组装线程进程
void vertex_assemble_cthread_0();
∥片段组装线程进程
void fragment_assemble_cthread_0 ();
∥顶点FIFO管理进程
void vertex_fifo_manage_cthread();};
class G3D_JSU_ADAPTER: public G3D_JSU_CORE
{public: ∥ pin-ports
sc_core::sc_in
sc_core::sc_in
∥简单复杂模式,
sc_core::sc_out
JSU2SGU_VERTEX_SIMPLE_COMPLEX_MODE;
sc_core::sc_out
JSU2SGU_FRAGMENT_SIMPLE_COMPLEX_MODE;
public: ∥ socket
tlm::tlm_initiator_socket<>
jsu2usa_vertex_data_initiator_socket_a;
tlm::tlm_target_socket<>
sgu2jsu_send_vertex_data_target_socket;
public: ∥ constructior and destructor
G3D_JSU_CORE
( sc_core::sc_module_name _name );
virtual ~G3D_JSU_CORE();
private: ∥ socket function
void b_transport(
tlm::tlm_generic_payload &payload
,sc_core::sc_time &delay_time );∥阻塞
tlm::tlm_sync_enum
b_transport_fw(tlm::tlm_generic_payload &gp
, tlm::tlm_phase &phase, sc_core::sc_time
&delay_time );∥非阻塞-前向
tlm::tlm_sync_enum
nb_transport_bw(tlm::tlm_generic_payload
&payload,tlm::tlm_phase phase,sc_core::sc_time
&delta ); ∥非阻塞-后向
protected: ∥ api functions
void
api1_send_vertex_shade_data_to_usa_a ();
void api0_send_new_vertex_data();
private: ∥ process function
∥用于监控和解析SGU发送的顶点数据
voidsgu2jsu_send_vertex_data_target_cthread();};
3.2 进程定义
SystemC进程是任务调度单元处理事务的载体,包括方法进程SC_METHOD、线程进程SC_THREAD和钟控线程进程SC_CTHREAD,它们被调用来仿真目标系统的行为,实现模块的算法和控制细节。最常用的是线程进程,特点是它能够被挂起和重新激活:线程进程使用wait()挂起,当敏感表中有事件发生,线程进程被重新激活运行到遇到新的wait()语句再重新挂起。
定义了大量的进程来协同完成GPU的任务调度,下面以顶点组装线程进程为例来说明进程的实现,包括进程的注册和定义:
SC_THREAD(Vertex_Assemble_Cthread_0);∥启动进程
sensitive_pos << clock;∥注册敏感事件为时钟
void G3D_JSU_VAU:: Vertex_Assemble_Cthread_0 ()∥进程的定义
{ while(true)
{ wait();
jsuVertexBusy.write(1);∥
∥ read sgu2jsu_fifo
do{ wait();
} while(sguVertexFifoEmpty == ds_basic::EMPTY);
sgu2jsu_fifo->read()
∥ update GVP Reg
Update_Gvp_Vertex_Attribute(graphDrawData);
∥ check workMode is simple or complex
if(vdauGetServicePort->Get_Vertex_Simple_Complex_Mode() == ds_basic::SIMPLE) ∥ simple mode{Update_Ocu_Simple_Vertex_Task(ds_func_jsu::VERTEX_TYPE);}
else ∥ complex mode
{ Get_Vertex_Slot_Id(gotSlotId);
Update_Usa_Vertex_Attrib_From_Gvp(ds_func_jsu::VERTEX_TYPE,gotSlotId,updateMask,graphDrawData.type);}
jsuVertexBusy.write(0);
return;}}
3.3 仿真验证
任务调度单元的TLM模型开发完成后与其他模块的TLM模型进行互联构成整个GPU的TLM模型,TLM模型之间依靠时钟和动态事件同步,通过pin-port、socket进行事务通信。接下来的工作就是基于SystemC simulation kernel的仿真验证,该kernel的主要任务是控制仿真、响应event、对不同线程进行切换等。本文采用的SystemC库版本为2.3.3,参考平台采用Mesa,Mesa是以开源软件形式实现的OpenGL标准应用程序接口模型,不依赖任何硬件。
采用OpenGL2.0,构造如下的测试场景:利用glViewPort将屏幕划分为4个子窗口,第1个窗口中使用一维纹理和二维纹理贴图功能,第2个窗口中使用了压缩纹理功能,第3个窗口中使用了位图(glBitmap)功能,第4个窗口中绘制了平滑着色的多边形带。验证场景涵盖了顶点着色和片段着色的典型功能,能触发任务调度单元的关键控制通路。图5显示了TLM模型输出了跟MESA相同的正确结果图,并且该验证项在TLM仿真平台仅耗时10 min,相同的验证项在RTL虚拟仿真平台将耗时数小时,由此可见TLM模型功能正确并且仿真速度得到了巨大提升。
图5 TLM模型结果和MESA参考Fig.5 TLM model result figure and MESA reference figure
4 结束语
采用基于TLM模型的GPU设计验证方法,能尽早验证优化算法、架构和电路功能,并为RTL设计提供了参考模型,加速了GPU的软硬件协同设计。TLM模型采用SysML和SystemC联合开发,首先构建任务调度单元的SysML视图模型,然后将其映射为事务级模型,最后进行仿真验证。本文主要研究松散定时的功能性建模,后续将建立近似定时TLM模型和时钟周期精确TLM模型,以此进行体系结构的性能分析向模块设计提供性能指标依据,以及硬件RTL和TLM模型的混合仿真验证。
猜你喜欢
山西电子技术(2021年3期)2021-06-28
数字通信世界(2020年3期)2020-04-06
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
制造技术与机床(2019年4期)2019-04-04
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
现代防御技术(2016年1期)2016-06-01
