
扫描电镜/能谱法结合多元统计学无损检验烟用接装纸的研究
2021-08-12 08:17付钧泽
中国造纸 2021年4期
付钧泽 姜 红
(中国人民公安大学侦查学院,北京,100038)
我国烟民数量日益增多,同时香烟具有镇定和缓解紧张情绪的作用,所以作案人常常会在作案时吸烟。香烟在燃灭后常会遗留下烟蒂部分,接装纸是包在香烟烟蒂外面的装饰用纸,与吸烟者嘴部直接接触,所以在案件现场常会提取到烟用接装纸物证,公安实战中通常会对接装纸物证上附着的生物物证做DNA鉴定,但由于生物物证极易受到环境的影响,故检出率不高。通过对接装纸物证的理化性质进行检验,可确定香烟种类,缩小侦查范围。接装纸是生产卷烟的重要材料,其作用是将滤嘴和卷烟烟支卷接起来,属于特种工业用纸[1]。接装纸的用途不仅是单纯的包装,更具有装饰性的作用,这使得不同品牌的接装纸组成成分具有差异。接装纸的颜色大部分为黄色,黄色基本为烤烟型香烟,如骆驼香烟、红塔山等。杂色香烟种类较少,如红色过滤嘴的中华5000、蓝色过滤嘴的芙蓉王(蔚蓝星空)、白沙(尚品蓝)等。薄荷型香烟基本上是白色,如万宝路[2]。目前,检验香烟接装纸的方法主要有原子吸收光谱法[3-4]、X射线荧光光谱法[5-6]、气相色谱法[7]、液相色谱法[8]、气质联用法[9]和液质联用法[10]等。但上述方法主要针对样品有机成分进行检验,并且检测成本价格高,样品的制备过程复杂,最佳操作条件遴选过程周期较长[11]。
本课题利用扫描电子显微镜结合X射线能谱仪对烟用接装纸样品进行检验。通过鉴别接装纸物证可大致判断购买人群,缩小检查范围。扫描电子显微镜可对样品微观放大成像,放大倍数达40万倍以上且分辨率高[12],X射线能谱仪可对样品无机元素进行无损分析。由于扫描电子显微镜及能谱仪可对样品同时做表面形貌分析和元素含量分析,在犯罪现场的物证快速检验有很大的应用前景。但获得样品元素数据后进行简单描述性统计并不能消除偶然误差和系统误差的影响,故引入多元统计学对样品能谱数据进行分析,可最大程度上克服误差达到准确分类与预判的目的。该研究可为烟用接装纸物证快速检验提供借鉴,为公安基层实际办案提供参考。
1 实 验
1.1 实验仪器及条件
Hitachi-3400N型扫描电子显微镜(SEM);EDAX Apollo型X射线能谱仪(EDS),低真空,加速电压20 kV,时间常数1.6μs,谱采集时间29 s,工作距离10 mm。
1.2 实验样品
从公共场所收集的烟用接装纸样品60个,样品具体名称见表1。
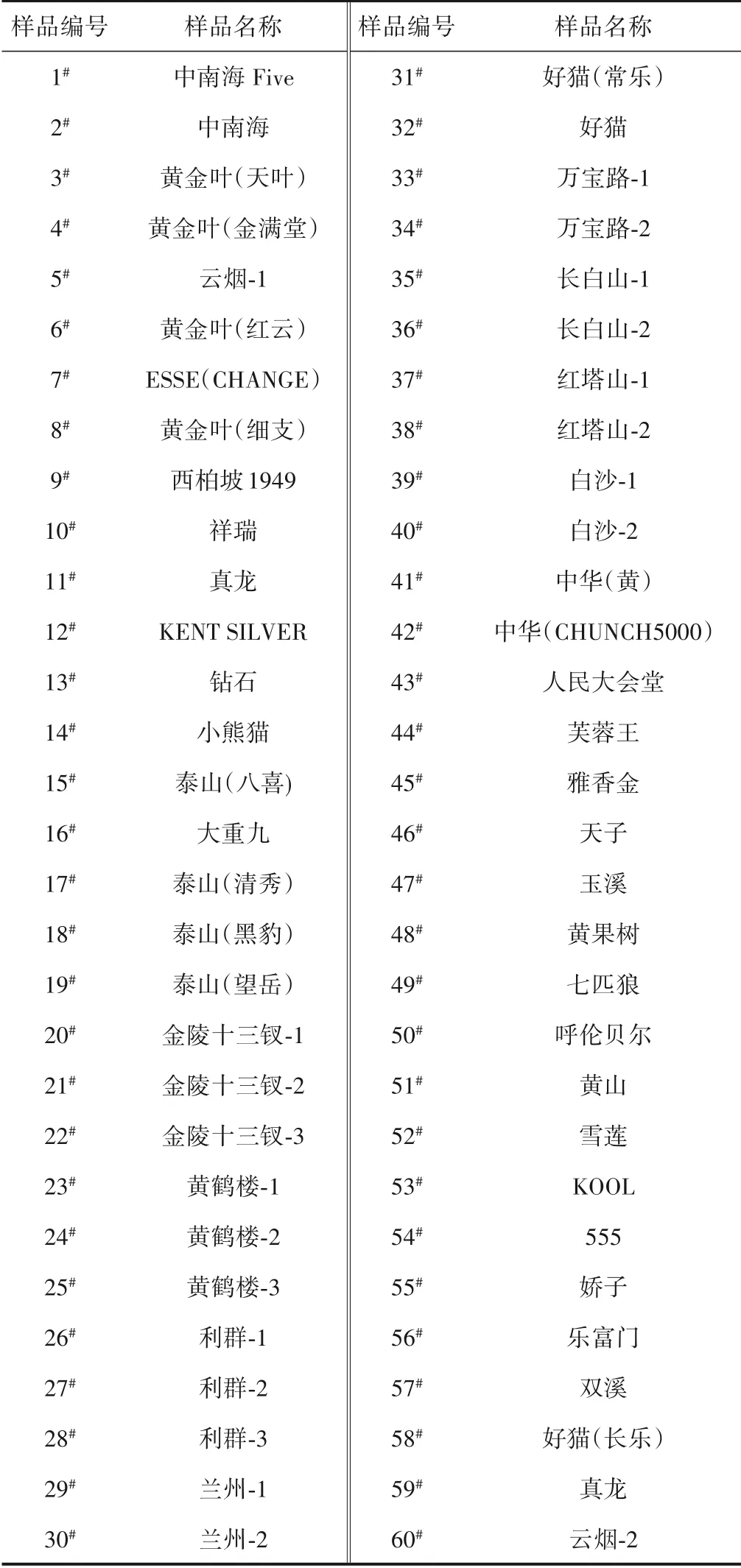
表1 烟用接装纸样品表Table 1 Samples of cigarette tipping paper
1.3 实验方法
用手术刀对接装纸样品进行取样,样品规格为2 mm×2 mm,固定于SEM导电胶样品台,进行检验分析。
2 结果与讨论
2.1 接装纸样品的初筛
通过观察,绝大部分接装纸主色调为黄色,说明黄色过滤嘴的香烟更受市场欢迎[13],其他少部分为红色、蓝色和白色等,所以可根据接装纸颜色将60个样品分为两大类:第Ⅰ类样品为黄色接装纸;第Ⅱ类为杂色接装纸。而后根据SEM图进一步对Ⅰ、Ⅱ类样品进行再分类,由于接装纸是由纤维相互交织而形成,样品表面存在大量的孔隙和凹凸不平处,加入细小颗粒填料后能提高纸张的柔软性、平滑性和可塑性。所以根据SEM图中显示的填料的多少,来判断接装纸平滑度的高低,并依此分为粗糙型和平滑型,其中45#接装纸是粗糙型的代表样品,52#接装纸是平滑型的代表样品,SEM图分别见图1、能谱图分别见图2。综合考虑接装纸样品外观颜色和表面微观形貌初步分为:Ⅰ-1(黄色粗糙型)、Ⅰ-2(黄色平滑型)、Ⅱ-1(杂色粗糙型)、Ⅱ-2(杂色平滑型),具体结果分类见表2。

图1 接装纸45#和52#样品扫描电镜图Fig.1 SEM images of 45#and 52#tipping paper

图2 接装纸45#和52#样品能谱图Fig.2 EDS spectra of 45#and 52#tipping paper
由表2可知,对于Ⅰ-2、Ⅱ-1、Ⅱ-2类的样品,样品数量均不大于10个。Ⅰ-2类各样品中元素种类和含量均有不同,对于未知的黄色平滑型的接装纸样品,可计算其与Ⅰ-2类各样品元素含量的欧氏距离,以此确定样品品牌。对于杂色样品,由于杂色接装纸本身就具有很强的特征性,结合元素含量与成分的不同,将未知的杂色接装纸样品与Ⅱ-1、Ⅱ-2类样品比较,也可快速锁定样品品牌。故以样品数量最多的Ⅰ-1为例,结合多元统计学,建立未知烟用接装纸的归类模型。

表2 接装纸样品分类结果表Table 2 Classification results of tipping paper sample
2.2 K-均值聚类
K-均值聚类算法是一种迭代求解的聚类分析算法,其步骤是预先把数据分为K组,再选取K个对象作为初始聚类中心,计算每个对象和每个聚类中心的距离,把对象依次分配给它距离最近的聚类中心。每分配给聚类中心1个样品,聚类中心会根据聚类中现有的样品被重新计算,不断重复直到满足终止条件为止。
经典的K均值算法是一种无监督分类算法,使用贪心策略,多重迭代求得近似解。其目标函数如式(1)所示[14]。

式中,k为聚类的个数,xi为第i个样本点,θj为第j个类别质心。每次迭代,通过最小化欧几里得距离将每个样本点xi分配到指定类别Ci。
在进行K-均值聚类时要提前设定1个K值,即样品被分为K个类别,K值的确定影响整个算法。在K值接近于真实值时,组内平方和(sum of squares due to error,SSE)的斜率会发生骤变,从而在图像上形成1个“肘部”,该拐点即为真实的K值。其中SSE可作为评价聚类结果好坏的标准。Ⅰ-1类样品SSE折线图见图3。

图3 SSE与聚类数目关系图Fig.3 The quantitative graph of SSE and clusters
当聚类数目逐渐增多时,每个类别中样品数量逐渐减少,故SSE的下降幅度会突然放慢,随着K值的增大而逐渐平缓。当SSE减少很缓慢时,存在的这个“肘部”就是最佳聚类数目,由图3可知,SSE在1~4时下降得很快,当K值>4后,曲线下降逐渐变缓,所以最佳聚类个数为4。K-均值聚类结果见表3。

表3 I-1接装纸样品聚类结果表Table 3 Classification results of I-1 tipping paper
烟用接装纸的填料主要有CaCO3、TiO2、高岭土(Al2(Si2O5)(OH)4)等[15],颜料主要为铁黄和铁红。通过分析表3聚类结果中各组样品能谱数据中元素含量的差异(结果略),发现I-1-1组中所有样品均含有Ca、Si、Ti 3种元素,说明I-1-1组样品填料种类最多,均包含CaCO3、高岭土和TiO2这3种填料。I-1-2组样品中所含元素种类最少;I-1-3组样品Al元素含量最多,说明该组样品填料主要是高岭土。I-1-4组样品Fe元素含量最多,说明该组样品的颜料含量最多。通过K-均值聚类和样品成分元素信息的相互印证,完成样品进一步分组。
2.3 主成分分析
主成分分析是因子分析的一种,是一种将多个变量通过线性变换达到降维的目的,选出少数几个重要变量的多元统计分析方法,几个较少的综合变量就可以尽可能多地反映原来变量的信息[16]。为了验证K-均值聚类结果的准确性,将聚类结果作为样品分组标签,提取贡献率最高的前3个因子。对聚类结果三维可视化验证,各因子累计方差解释率见表4。
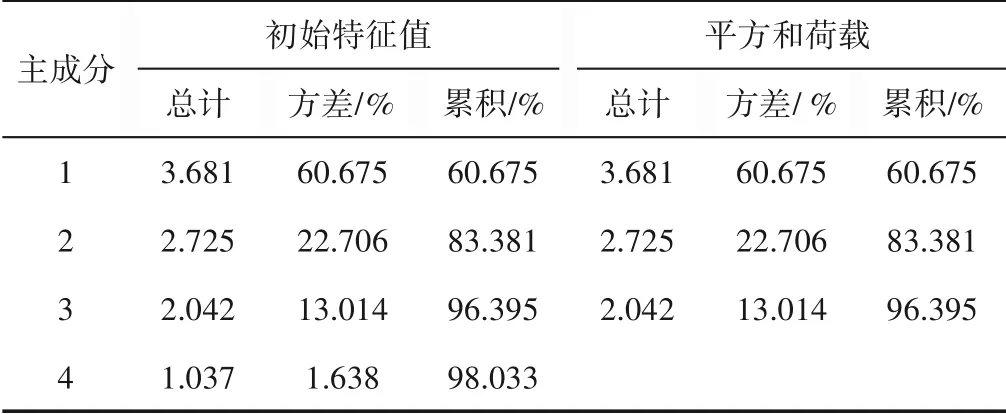
表4 累计解释方差贡献率Table 4 Contribution rate of cumulative explanatoryvariance
由表4可知,前3个主成分(PC)累计贡献率达到了96.395%,可认为前3个因子承载了原始数据绝大部分信息。计算38个烟用接装纸样品在各因子上的得分,即各元素变量在PC1、PC2、PC3的重要程度,得分图如图4所示。

图4 主成分得分图Fig.4 Principal component score
图4显示38个烟用接装纸样品在三维主成分得分图中被明显地分为了4类,1代表I-1-1组,2代表I-1-2组,3代表I-1-3组,4代表I-1-4组(下同)。除I-1-1组内2个样品外,各组内空间距离较小,组间距离较大,各组在三维空间上显著区分开来。
2.4 多元线性回归分析
2.3 中前3个主成分并不能完全保留全部数据信息,可能是导致I-1-1组中2个样品距离组内质心较远的原因。所以引入多元线性回归分析验证K-均值聚类中不同组别和各个元素变量之间的依赖关系。回归分析可以用来研究变量之间相关关系,运用十分广泛,这种技术通常用于预测分析[16]。回归模型的方差分析结果见表5,标准化残差预期累积概率-累积目标概率如图5所示。

表5 方差分析结果表Table 5 Analysis of variance results

图5 标准化残差预期累积概率-累积目标概率图Fig.5 Expected cumulative probability-cumulative probability of observation of standardized residual
由表5可知,线性回归模型的显著性水平为0.001(预测变量:常数、Cl、Si、Cu、Fe、Mg、K、Ti、Na、O、S、Al、Ca),其显著性概率远远小于0.01,可说明该模型内各个元素变量对组别变量具有显著影响。
由图5可知,标准化残差的预期累积概率-累积目标概率图中样品散点密集分布在斜线两侧,和直线拟合度较高,可认为残差符合正态分布。残差正态性检验的结果表明数据基本满足线性回归要求,即2.2中K-均值聚类得到的样品组别与各元素之间可建立良好的拟合关系,印证了聚类结果的准确性。
2.5 判别模型的建立
判别分析是化学模式识别中的热点,目前应用较多的是贝叶斯判别和Fisher判别预测样品的某一指标[17]。判别分析可以在已知分组的基础上,建立判别函数模型,判别观测样品归属。
2.5.1 贝叶斯判别分析
给定1个输入的x,目的是确定它是属于w1类还是w2类,根据贝叶斯判别思想,需要计算x属于w1类概率和w2类概率并判断样品的归属。若P(w1|x)>P(w2|x),则x∈w1;相反,则x∈w2。由贝叶斯定理可知,后验概率P(wi|x)可由类别的先验概率P(wi|x)和x的先验概率P(x|wi)得到,具体计算见式(2)。
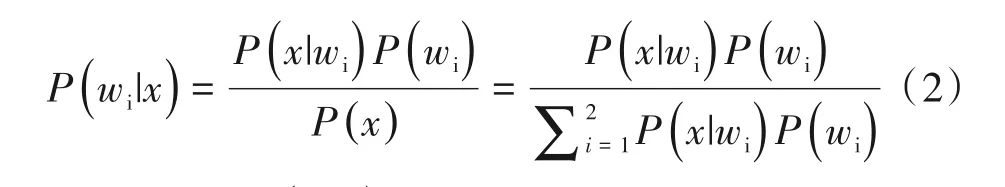
式(2)中,P(x|wi)也被成为似然函数。所以原判别式可改写为,若P(x|w1)P(w1)>P(x|w2)P(w2),则x∈w1;相反,则x∈w2。上述贝叶斯判别式函数系数见表6。

表6 分组函数系数Table 6 Coefficient of group function
由表6可知,将各样品的自变量值代入上述4个贝叶斯判别函数,得到4个函数值。比较这4个函数值,函数值较大的组别就可以将样品判入该组。
2.5.2 Fisher判别分析
Fisher判别的原理也是一种降维的思想,是将多维度空间的样品进行降维,并投射到低位空间,使样品在新的子空间上有最小的组内距离和最大的组间距离,使其在该子空间上有最佳的可分离性。Fisher判别式通过计算各观测值在低维空间上的坐标,从而确定各样品的具体空间位置。群组重心为各组别重心在空间中的坐标位置。只要计算出各观测值的具体坐标位置后,再计算出它们分别离各重心的距离,就可以得知它们的分类了。
2.2 中4个类别Wilk的Lambda检验判别结果见表7。

表7 Wilk的Lambda检验判别结果Table 7 Wilk Lambda test discriminant result
由表7可知,在Fisher判别分析中建立了3个判别函数,函数1、2、3的显著性水平均小于阈值0.05,可说明前3个判别函数显著成立[18],所以利用这3个函数作为Fisher判别函数,其特征值见表8。

表8 判别函数特征值Table 8 Eigenvalue of discriminant function
表8反映了判别函数的累积贡献率和方差变异程度,判别函数1的方差贡献率为60.0%,判别函数2的方差贡献率为38.4%,判别函数3的方差贡献率为1.7%。判别函数1和判别函数2携带的信息远大于判别函数3。判别函数1与判别函数2之间典型相关性系数分别为0.966和0.949,说明样品在函数1和函数2这两个维度上具有显著差异。故选择函数1和函数2建立二维空间分布图,见图6。

图6 判别函数联合分布图Fig.6 Joint distribution of discriminant functions
由图6可知,实心三角形代表组质心,1代表I-1-1,2代表I-1-2,3代表I-1-3,4代表I-1-4。4组样品在函数1、函数2组成的二维空间上区分明显,同组的样品都落在了同一区域,结果显示样品回判正确率为100%,说明该判别模型与K-均值聚类结果相互印证,将未知样品元素变量输入判别函数中,根据在联合分布图上反映的位置找到与之距离最近的组质心就可完成对未知样品的准确归类。
2.6 未知样品的检验
选取模拟案件现场提取到的红云红河烟草有限公司生产的“云烟(塞上江南)”和河南中烟工业有限责任公司生产的“黄金叶(摩卡)”2个接装纸样品验证上述归类模型的准确性与应用性。首先通过观察外观颜色,验证样品的接装纸颜色均为黄色,故将其归入Ⅰ类,再利用扫描电子显微镜对其微观形貌进行观察,发现为粗糙型,应归入I-1类,如图7所示。

图7 云烟和黄金叶的SEM图Fig.7 SEM images of Yunyan(Saishangjiangnan)and Huangjinye(Moka)
将上述2个样品的X射线能谱数据分别代入贝叶斯判别函数和Fisher判别函数中,结果显示在贝叶斯判别中I-1-1组的判别函数值最大。Fisher判别函数显示验证样品质心距离I-1-1组质心最近,见图6(5和6代表验证样品)。故可认为2个验证样品被判入I-1-1组。I-1-1组样品和验证样品的X射线能谱数据见表9。

表9 样品元素含量表Table 9 Element content of samples %
由表9可知,I-1-1组的13个样品中只有15#和60#样品元素种类与云烟(塞上江南)、6#和37#与黄金叶(摩卡)的元素种类相同;分别计算15#、60#样品与云烟(塞上江南),6#、37#样品与黄金叶(摩卡)元素的欧几里得距离,发现60#样品成分特征与云烟(塞上江南)、6#样品与黄金叶(摩卡)最为相似,通过查询样品表可知60#样品品牌同样为“云烟”、6#样品为黄金叶。说明该验证样品的预测结果与实际情况吻合,检验了该分类模型的应用性和可靠性。
3 结论
本课题采用扫描电子显微镜/能谱仪对烟用接装纸样品进行了快速检测,首先通过样品颜色和表面形貌对样品初筛分类,而后对样品进行K-均值聚类,进一步对烟用接装纸样品聚类。通过主成分分析和线性回归分析验证了K-均值聚类的可行性,最后建立了2种判别函数模型,借助判别函数对未知样品进行预测并得出了准确的结论。对于现场提取到的未知烟用接装纸物证,可通过该模型进行快速分类识别,缩小侦查范围。在后续的研究中,将进一步扩大样品库并融入深度学习模型,提高该模型的精确度。
猜你喜欢
云南化工(2020年11期)2021-01-14
中国市场(2020年19期)2020-08-13
中国特种设备安全(2019年5期)2019-07-16
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
现代营销(创富信息版)(2018年10期)2018-10-12
中国科技纵横(2018年3期)2018-03-15
中国集体经济(2016年5期)2016-05-14
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
郑州大学学报(理学版)(2014年4期)2014-03-01
