
基于卷积神经网络的图像识别算法研究
2021-11-07 09:17叶建龙胡新海
安阳师范学院学报 2021年5期
叶建龙,胡新海
(陇南师范高等专科学校,甘肃 成县 742500)
0 引言
科学技术的飞速发展,自媒体的日新月异,图像视频充斥着人类生活的方方面面,基于海量数据的图像分类和识别技术成为当前研究的热点,也对相关的研究提出了更高的要求[1]。目前,由于图像的复杂性以及各种算法本身固有的局限性,图像识别领域在海量图像识别的精度和性能等方面仍然是研究的难点,主流的技术包括支持向量机、基于纹理特征等图像特征提取和分类算法,其中传统的基于支持向量机的图像分类技术精度仅仅达到48%左右,距离期望值相去甚远[2]。Grishick等人提出了将卷积神经网络与推荐方法相结合进行图像特征提取和分类工作,提取精度较高但检测速度比较慢[3]。Zhou等学者将机器视觉与改进的SVM分类算法结合应用于农作物病虫害识别工作,检测准确率也有较大的提升,弊端在于算法复杂度较高[4]。2011年以后,深度学习技术日趋成熟并广泛应用,在自然语言处理、语言识别等很多领域都取得了良好的成果,如何将深度学习技术与图像识别深度融合提升识别的准确率和性能,是研究的重点所在。
基于前人研究的基础上,提出改进的卷积神经网络的图像识别算法,结合卷积神经网络具有的共享权值、自学习提取分类特征、网络训练的优势,在模型训练阶段通过归纳迁移算法构建模型网络及共享特征参数,图像分类过程中使用交叉熵损失函数提升模型的泛化性以及分类的准确率。实验选取了8个经典的图像分类数据集作为实验对象,经与经典的卷积神经网络模型对比,该算法在模型训练上速度更快,对于不同的数据集平均识别准确率达到了96.2%,对于不同数据集的泛化能力也较强,优势明显。
1 卷积神经网络
卷积神经网络是一种模仿人体神经组织的基本模型,采用卷积层和关联下采样层的双层网络关联结构构成的网络模型[5-6]。设定的规则上下层级间、相邻的神经组织间互相连接,从而形成层级之间的强约束的局部的关联关系,其结构如图1所示:
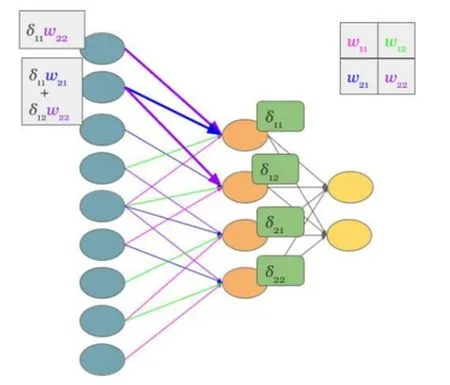
图1 卷积神经网络的网络结构图
图1所示的网络结构图的各个神经元之间互相连接,其局部空间滤波具有较强的强适应性[7]。结构上主要分为输入层和隐含层,其中隐含层再次细化为卷积层、下采样层以及池化层。核心原理是使用卷积和池化操作,构建有监督学习式的训练网,训练方式分为前项训练传播以及反向训练传播两种,二者互相结合,互为输入,具体算法如公式(1)所示:
(1)
在公式(1)中,使用s(i,j)标识特征向量矩阵,使用二维矩阵M×N标记二维输入矩阵,wm,n代表大小为M×N的卷积核矩阵,wb代表了偏移向量。网络模型构建过程中使用的损失函数采用损失熵计算方法,具体如公式(2):
(2)
公式(2)中使用L代表损失,x代表了输入的样本数据,a是指计算的结果,y代表了标签项值,n为样本总数。
2 归纳迁移模型训练
2.1 迁移模型训练流程
为了将卷积神经网络算法更好应用于图像识别,在构建CNN网络模型的过程中,引入了融合归纳迁移算法进行模型的搭建和学习,避免由于规范化样本数据过少以及计算资源和硬件资源不足产生的过度拟合等造成最终分类不准确的问题。融合归纳迁移学习法的核心思想是通过已知经验,识别位置环境进行辅助学习[8]。研究采用基于参数的归纳迁移算法进行模型训练。
应用归纳迁移模型进行样本识别训练过程如图2所示:
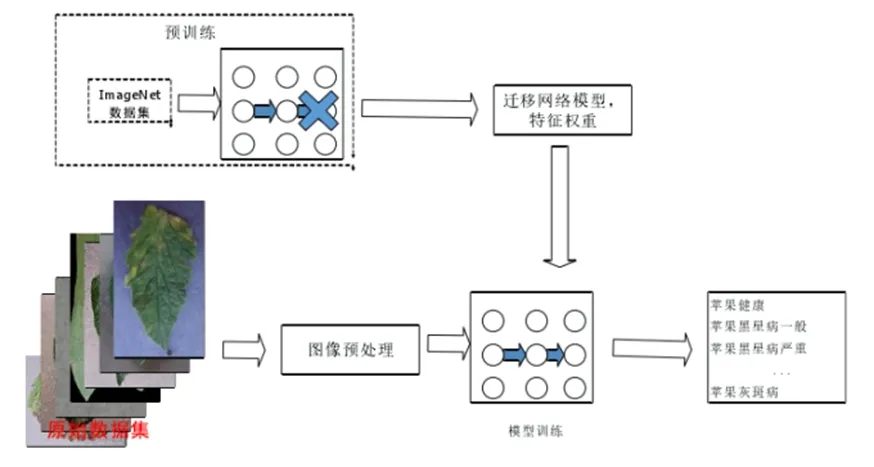
图2 归纳迁移进行样本训练识别流程
第一步:进行与训练模型的加载工作,初始化载入在数据集中已经训练的卷积神经网络模型,得到输入数据的张量数值以及计算存在瓶颈层的张量值。
第二步:完成CNN网络初始化输入工作,初始化学习率、训练次数、批量次数以及每层网络的Dropout数值。
第三步:提取训练图片特征。载入第一步中预训练的网络结构对应的特征值权重、节点计量公式,将其作为目标特征提取器,将待分类的样本图片作为CNN模型的输入,采用前馈神经网络模型,再次计算瓶颈层的张量值。
第四步:完成分类任务,在已经训练完的模型结构增加1层卷积模型,并对全连接层进行目标任务分类,并使用交叉熵损失函数构建损失层。
第五步:引入待测数据图像样本集进行特征分类,获得模型的准确率。
在训练模型过程中,采用组归一化(GroupNormalization, GN)算法与优化的交叉损失嫡算法用于优化识别网络结构。
2.2 组归一化
在第一步的模型训练环节,采用组归一化[9-10]处理。在对训练样本的分组完成后进行规一划化处理,进一步提升卷积神经网络模型识别的准确率。其计算过程首先进行通道分组及组内的计算方差和均值后完成归一化处理,使用公式(3)计算标准差及其均值对应图像像素点集合Si
(3)
式(3)中,i和k是代表图像索引坐标,其处在同一通道,N为样本数量,C/G代表每一组的通道个数。
像素点对应的均值和方差计算公式如(4)、(5)所示:
(4)
(5)
公式中的xk代表需要计算的像素点,ε代表维持数据稳定的参数,m代表Si的长度值。
对于每个通道组内的像素使用公式(4)、(5)完成归一化处理后,由于不能对学习的特征分布进行破坏,需要进行数据的规范化处理,通过重构和尺度偏移变化完成,具体如公式(6)、(7)
(6)
yi=γxi+β
(7)
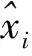
经过上述步骤处理后,获得新的特征分布yi,使用组归一化方法,在样本图像进行神经网生产的过程中,确保神经网络模型的性能达到最优,加速收敛。
2.3 优化损失函数
损失网络用于更新神经网络的参数,以便不同类型图像进行对应风格的迁移模型的训练,考虑到图像数据集分类本身存在分布均匀性不足、比例不均衡等问题,对深度神经网络的损失函数进行了优化,改进交叉熵函数对于正向样本的深入挖掘,增加正向样本的权重和出现概率,进一步提升图像识别的准确度。具体如公式(8)所示
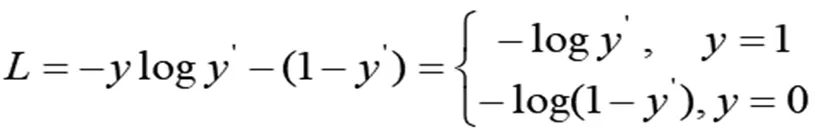
(8)
由于该损失函数的正向样本与损失函数呈现负相关,相反的负样本y′与损失函数为正相关,所以无法适应大量样本数据,基于此,通过加入调节参数γ和α来降低易分类样本的损失值,平衡正负样存在的分布不均衡问题,具体如公式(9)所示:
(9)
其中实验证实调节参数γ取值为2,α取值为0.25。
引入组归一化和交叉熵损失函数后的图像识别过程如图3所示:
该算法的核心为首先去掉预训练模型的分类层,然后冻结前面的层提取特征,后续经过组归一化完成网络构建后,调整样本训练权重,完成损失层的优化,最终完成目标任务分类。
3 实证结果与分析
3.1 训练及测试样本的选择
选用的训练数据样本为包含约1500个图片、约2万个分类的ImageNet数据集,用于网络模型的训练。选择该数据库的89个物种图像20000幅图像划分数据子集合其中70%用于训练集、30%作为测试集。
3.2 结果与分析
根据以往图像分类识别的算法的性能研究发现,模型样本训练的过程占有资源较多且运行时间较长,为避免实验中断和内存溢出的问题,采用分组循环迭代的方式进行实验,设定了实验执行的次数和时间。主要与文献[1]和文献[2]中的基于卷积网络和支持向量机的图像识别算法进行了对比实验,实验结果如表1所示:
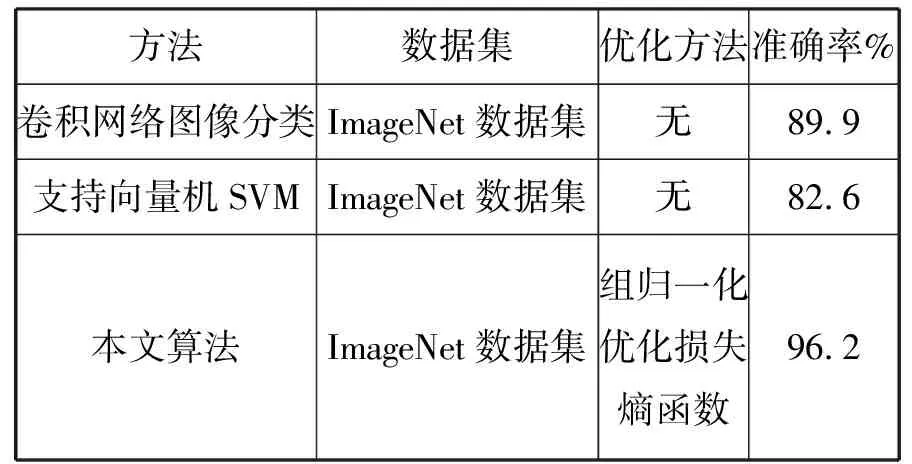
表1 不同算法结果对比
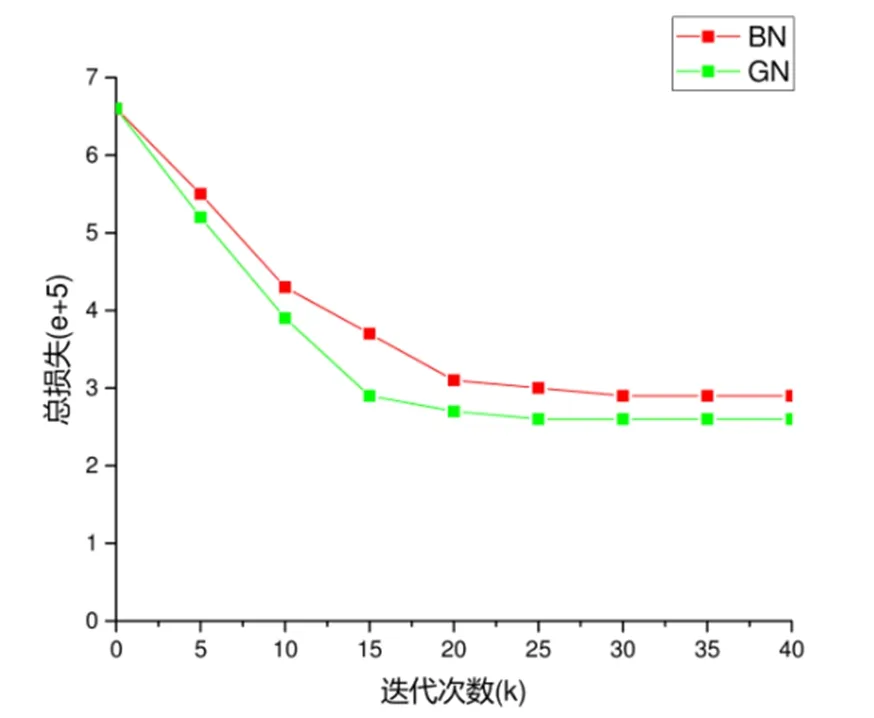
图4 算法收敛性测试图
根据表1显示结果可以发现,对应用于同一训练集而言,使用经典的卷积网络模型进行图像识别平均识别率对比支持向量机算法提高较多,支持向量机算法更适用于文本分类,而本文对于卷积网络模型进行了组归一化处理并优化损失熵函数后,执行效率提升了约6个百分点。 实验过程中,对算法的收敛速度进行了测试,重点对比了组归一化和批量归一化两种方法进行模型训练的收敛情况,迭代次数设置为 40000 次,实验结果如图4 所示,在应用组归一化处理的模型的损失函数的下降速度更快,其在20000次的循环迭代时已经达到最小值完成收敛,而对于批量归一化方法的收敛速度明显较慢。
对于该算法的鲁棒性,该算法模型在农作物数据集Potato dataset的鲁棒性表现比普通数据集、医疗数据集的表现更好,识别的准确率能够达到98%以上。
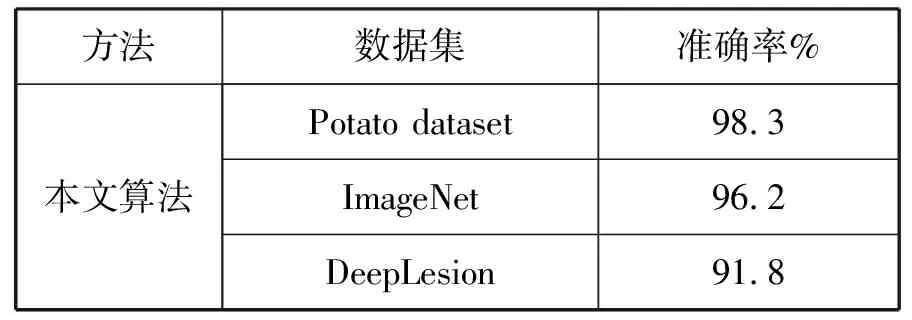
表2 本文算法应用不同数据集结果对比
4 结论
深度学习与图像分类识别在进入智能化、大数据时代逐步成为数据挖掘和机器学习领域研究的热点,为更精确、智能化的图像分类识别提供了可能。本文对卷积神经网络的损失熵进行了优化,在模型训练阶段通过归纳迁移算法构建模型网络及共享特征参数,图像分类过程中使用交叉熵损失函数提升模型的泛化性以及分类的准确率,过程中结合卷积神经网络具有的共享权值、自学习提取分类特征、网络训练的优势,将基于卷积网络分类模型用于图像识别,在算法性能以及识别准确率上均有大幅提升。不足之处在于训练环节资源占用率过高,后续将重点对此问题进行研究解决。
猜你喜欢
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
国际商业技术(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小天使·二年级语数英综合(2019年10期)2019-11-08
数码世界(2019年6期)2019-09-09
中国信息技术教育(2016年21期)2016-12-05
读者·校园版(2015年19期)2015-05-14
