
Spark环境下网络数据安全监测技术
2021-11-07 09:17林丽星
安阳师范学院学报 2021年5期
林丽星
(闽西职业技术学院 信息与制造学院,福建 龙岩 364021)
0 引言
Spark集群环境使用内部分布数据集,不仅具备常规的数据交互查询功能,还对工作环境负载产生一定程度的优化作用,因此Spark集群在众多数据采集监测领域得到广泛应用。随着计算机网络技术日益优化,网络安全形势日益严峻,黑客企图通过入侵等方式获得私密的网络数据信息[1]。因此,Spark环境下网络数据安全监测问题亟待解决和优化。Spark集群继承了 Hadoop中Mapreduce的全部优越性能,适用于数据挖掘算法的运行。为此在Spark环境下布置了并行式的K-mean聚类模型以挖掘当前数据是否存在危险因素,进而监测网络数据的安全性能。
1 基于K-mean聚类算法的Spark环境网络数据安全监测技术
1.1 Spark环境下网络数据采集
Spark环境下网络数据采集的结构布局如图1所示,主要包括Spark集群、无线网络、Spark服务集群、数据采集单元等关键部分。其中,Spark集群由多个从节点、一个主节点构成,均通过交换机与数据采集单元进行指令传达与信息交互[2];数据采集单元包括数个数据流量采集节点,采集后的数据传输到Spark服务集群进行安全处理与存储,以网络为介质传输到用户端以供数据分析使用。
Spark大数据集群环境下数据采集由采集单元部署的大量节点完成,是网络数据安全监测的基础,数据流采集完毕将会进行安全存储以供安全监测环节使用。Spark环境下采集的数据流包括结构化数据与非结构化数据两种,采集节点需要零散布局在复杂的网络之中,通过并行化节点管理策略将分散的数据采集节点集中起来统一管理,以优化网络数据采集效果与效率。具体执行方式如下:首先以大数据平台为载体向各个数据采集节点发送独立的执行任务,引入流量采集技术获取网络中完整的流量数据;然后整合采集到的全部数据信息,统一进行数据预处理,提高网络数据安全监测的精准度、降低数据监测难度。
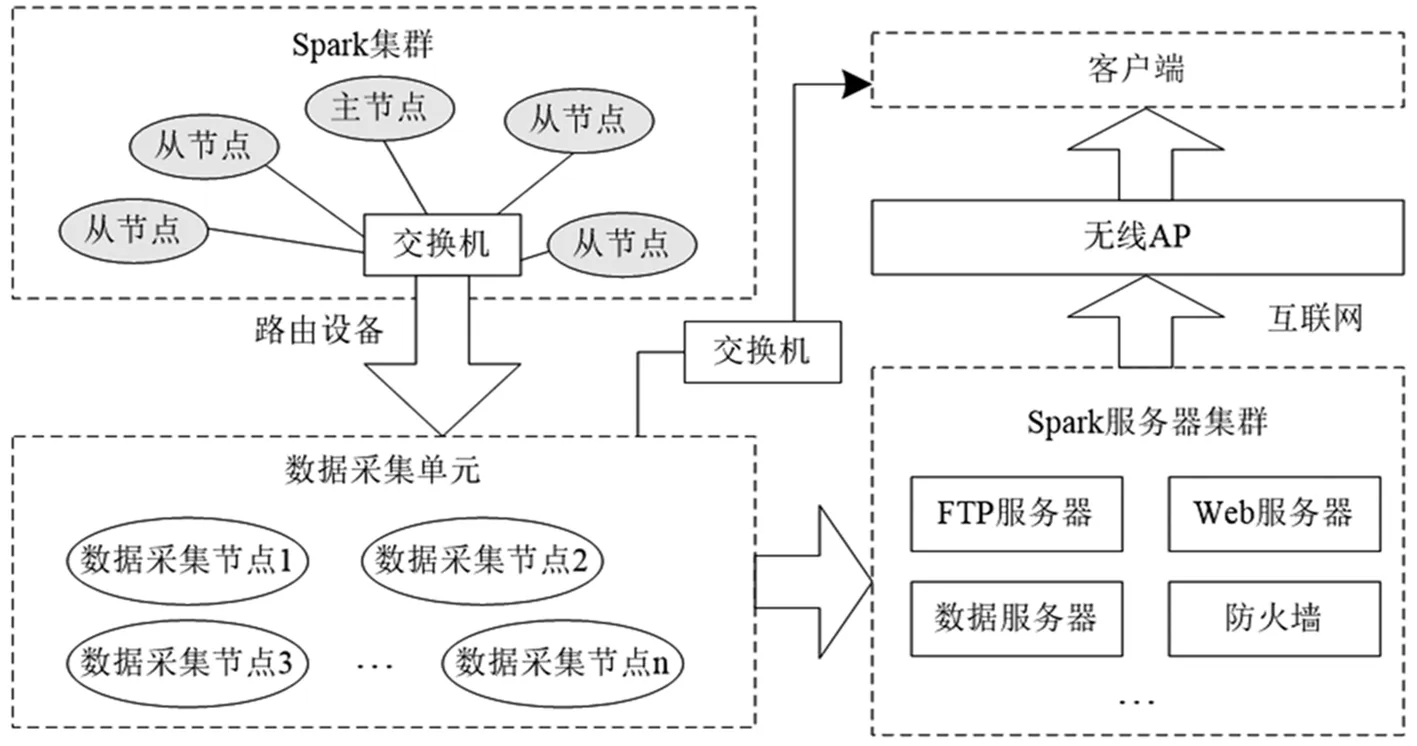
图1 Spark集群采集网络数据的拓扑结构布局
数据采集节点利用 Netsniff-ng抓包工具采集网络数据包[3],其优点是可以优化网络吞吐能力、降低计算机运行环境的CPU开销,减少对硬件软件运行环境的负载。
1.2 Spark环境下网络异常数据识别
1.2.1 并行化聚类流程设计
K-mean聚类算法是一种无监督的学习过程,将海量数据中某些相似的数据成员进行分类组织,获取大数据的某些内在结构特质,利用K-mean聚类算法识别网络数据中的异常因素功能,对 Spark环境下网络数据安全进行准确监测。Spark集群环境中产生的数据规模庞大,为高效率完成数据安全监测并及时发现异常因素,设计了K-mean聚类算法并行化执行流程,能在有限时间内完成更多的数据检测任务,具体执行流程如图2所示。
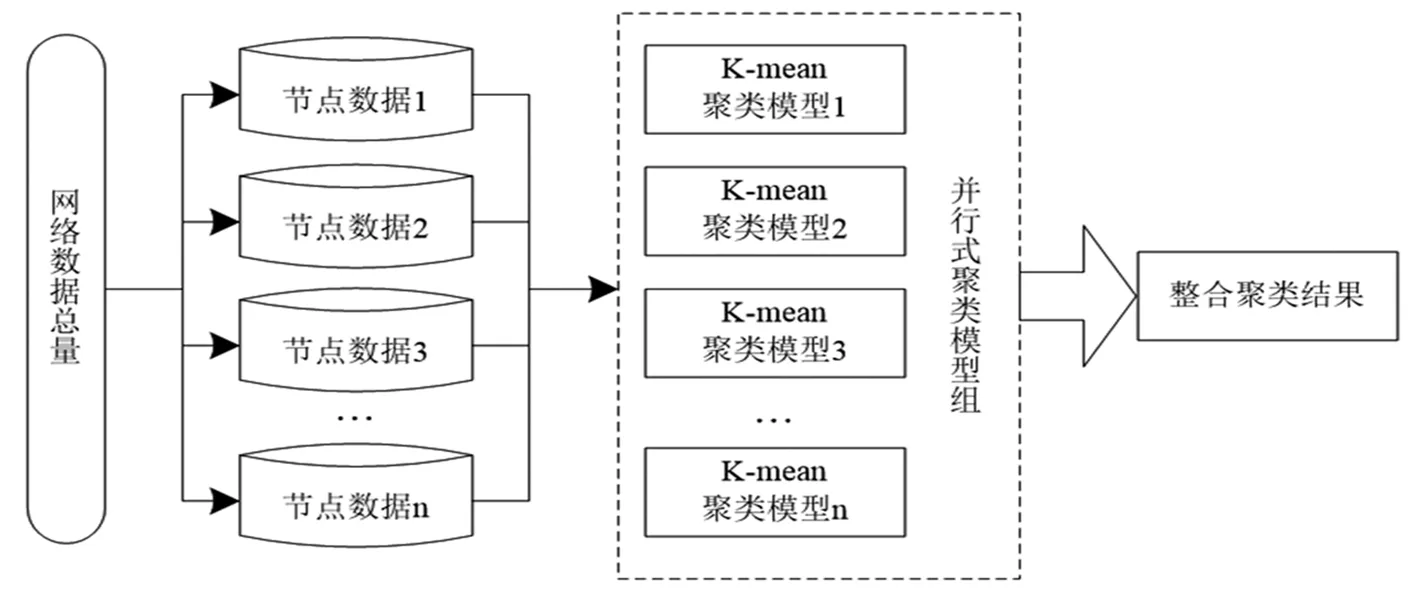
图2 K-mean聚类算法的并行化执行流程图
分析图2得知,布局在Spark环境下的网络数据总量被划分成无数个节点数据,节点数据异常检测任务一一指派给不同的K-mean聚类模型,在相同时间段内各节点一同完成数据检测任务[4];最后将并行式聚类结果进行集中整合,得到海量网络数据的安全监测结果。
1.2.2 基于K-mean聚类模型的网络异常数据检测
K-mean聚类算法识别网络异常数据的原理如下:1)采集原始网络数据集进行K均值聚类训练,生成异常数据检测模型,模型检测误差符合实际检测要求;2)将当前Spark环境下采集的网络数据作为模型的输入样本输入到训练好的K-mean聚类模型中,即可生成预期的数据异常检测结果,以此评估网络数据的安全性。
基于K-mean聚类算法的网络数据异常识别过程需引入“信息熵”这一概念进行辅助分析:首先对网络数据流量实施信息熵量化处理,然后在此基础上使用K-mean聚类算法划分数据的类别,判别其属于安全数据还是异常数据。
信息熵自提出以来常用于随机事件概率量化分析,公式(1)描述了信息熵量化的基本原理:
(1)
公式中,信息基元类别数量以及信息熵分别使用L、S表示,不同类别的概率描述为Gi。
网络数据具有大量的特征属性,从时间与空间维度来讲特征属性排列复杂,所以将固定时间频率下的网络数据作为对象进行网络数据特征数据统计,减少数据特征统计的不确定性。为此设计如下信息熵统计策略[5]:1)以网络数据中的L个数据包为单位进行时间窗划分,L个数据包定义为g,定义各窗口的数据包为“单位流”;2)由此一来,信息熵的统计可基于单位流的所有特征属性进行求取。
定义单位时间内网络数据的特征属性为Ri,λi为Ri取值的种类数量,采用nj表示特征属性第j种取值在单位时间内网络数据流的数量,基于上述变量计算此刻数据的信息熵如公式(2)所示:
(2)
以上步骤完成了对网络数据流信息熵的量化过程,随后基于K-mean聚类算法进行聚类分析构建K-mean聚类模型。采集网络数据作为类标样本,种类为k个,即聚类算法的k值。每个类原始簇类中心即为该类全部样本的均值。基于就近分配原则完成样本划分工作,聚类质量则通过全部对象与聚类中心误差平方和θ进行计算,样本聚类质量与θ成反比,即高质量的聚类结果往往θ较小。采用公式(3)计算θ值:
(3)
聚类步骤中需要将k值加1,继续执行聚类操作选取新簇的中心。随机在没有进行标记的样本数据中选择一点命名为α,作为新簇中心,β也为样本中的一点,以α点、β点为依据可划分出新的具有中心点的簇,即α点需将β点距离当前簇较远的中心视为具有中心点的簇,β点与中心点的距离为缩小的趋势,此时距离计算方法如公式(4)所示,取该公式的最大值:
(4)
然后基于就近原则分配全部样本并求取各个类的聚类质量。当k个簇聚类质量大于k-1个簇的聚类质量,将k值加1继续执行下面的操作;当k个簇聚类质量小于或等于k-1个簇的聚类质量,将k值减1,执行以下操作:判断全部簇中是否存在孤立簇,孤立簇是只包含新增的簇中心点[6]。存在孤立簇时需删除其中心点集以及没有标记的样本,将k值减1,并从计算聚类中心误差平方和步骤开始执行后续操作;不存在孤立点时,将新k值和原始聚类中心点作为算法的初始输入,重复更新聚类中心,算法聚类中心合理收敛后终止计算。
K-mean聚类算法成功收敛后即可得到训练完成的异常数据识别模型,将Spark环境中实时采集的网络数据作为样本输入模型即可辨别数据是否存在异常,监测其安全性。
2 测试与分析
借助Intellij IDEA环境搭建数据安全监测实验平台,以验证提出的Spark环境中网络数据安全监测的性能。实验平台共设置6个服务器节点,1台为主节点,其余为从节点;单个节点内存为16GB;实验使用的Hadoop版本、Spark版本分别为2.6.4和2.1.1。实验中引入基于特征统计的网络数据安全监测方法、基于时间相关性的网络数据安全监测方法作为对比,以检验该方法的性能。
在Spark环境中每隔20min采集一次数据作为测试样本数据,2小时内共采集6个样本数据集,统计3种方法在每个样本数据上的安全监测结果,计算其误检率如图3所示。
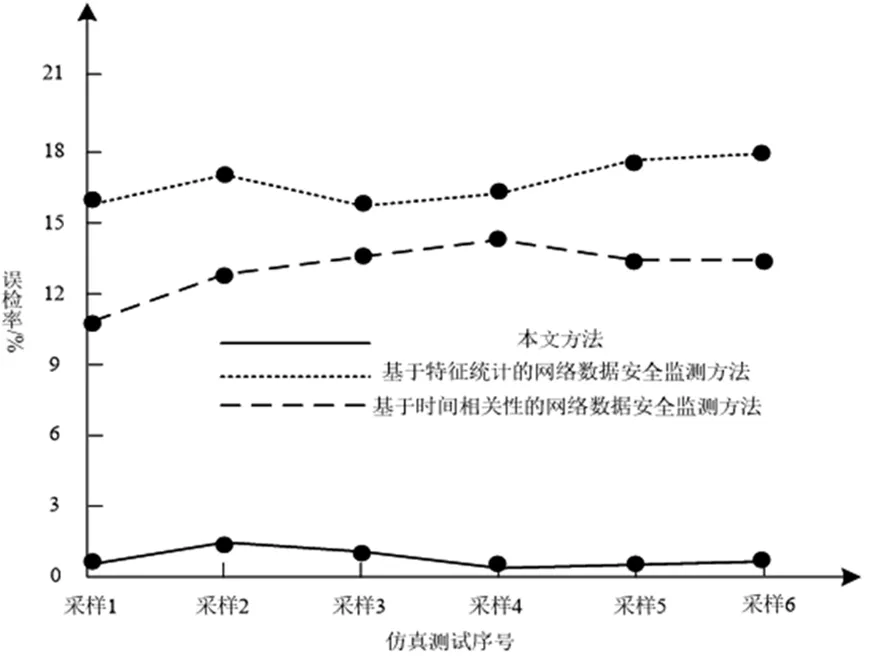
图3 3种方法的误检率统计
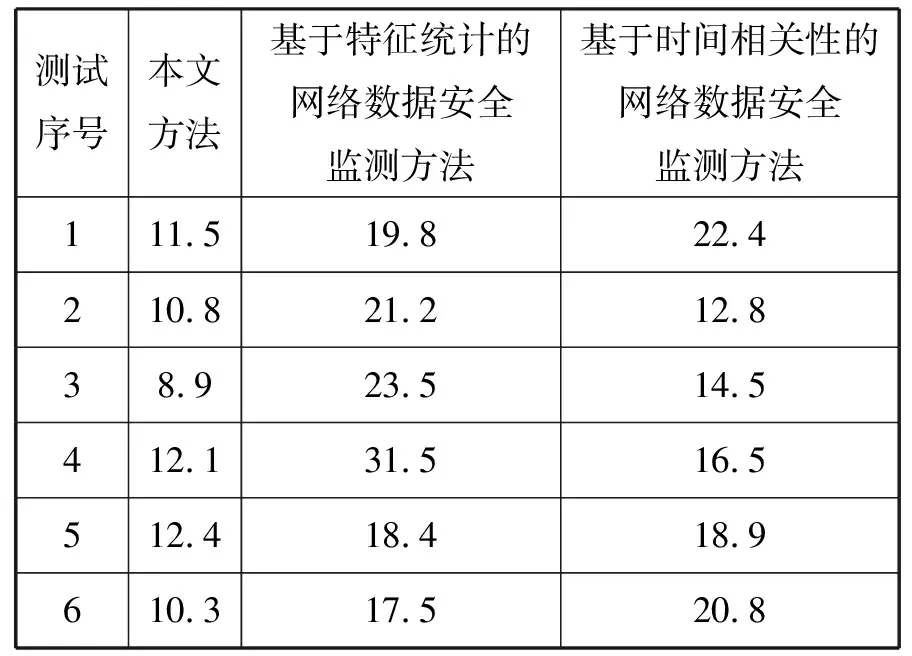
表1 3种算法安全监测中CPU占用率统计/%
结合图3与表1数据分析3种方法进行网络数据安全监测的性能,其中,本文方法无论在误检率还是CPU占用率方面均取得了优异的测试成绩,6次数据安全测试中误检率均保持在1%左右,而基于特征统计的网络数据安全监测方法、基于时间相关性的网络数据安全监测方法误检率均超过10%,最高分别达到18%和13.5%。Spark环境中网络数据规模庞大,本文方法CPU占用率保持在8.9%~12.4%之间,相对稳定;而基于特征统计的网络数据安全监测方法、基于时间相关性的网络数据安全监测方法均呈现CPU占用率过高且波动较大特征,相比之下,本文方法对计算环境的负载依赖较小。
3 结论
提出一种适用于Spark环境的网络数据安全监测方法,该方法采用并行式计算策略布局K-mean聚类模型,模型挖掘网络数据异常信息后其结果进行统一整合。这种并行式K-mean聚类算法在同一时间段内完成多个聚类任务,能够高效率挖掘数据异常情况、监测数据的安全;该方法由于在数据采集阶段使用了Netsniff-ng抓包工具,大幅度降低计算机运行环境的CPU开销,所以在实验分析取得了相对优异的CPU占用率成绩,总体而言对计算环境的负载依赖较小。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军民两用技术与产品(2022年1期)2022-06-01
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
中国计算机报(2020年25期)2020-07-18
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
当代贵州(2018年21期)2018-08-29
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国计算机报(2018年46期)2018-02-24
中国水运(2016年11期)2017-01-04
