
面向关联数据联合式实体识别方法及应用研究
2021-11-07 09:17张静
安阳师范学院学报 2021年5期
张 静
(六安职业技术学院,安徽 六安 237158)
近年来,很多系统选取实体为开发中心,根据系统开发需求,将不同材料植入到系统当中。其中,实体可以是电影、图片,也可以是单位主页[1]。由于单一的实体很难表达系统访问需求,需要建立网络关联关系,同时选取多个实体材料作为系统开发材料,通过分析实体之间的关联关系,建立联合式实体模型结构,并有序地识别实体,这是未来5年重点发展目标[2]。本文将探究面向关联数据的联合式实体识别方法,并将该方法投入到实践应用中进行检验。
1 联合式实体识别方法
联合式实体识别方法与普通的实体识别方法不同,该方法借助实体数据对象之间的关联关系建立识别模型,以便准确、高效地识别实体数据对象。该研究以图的迭代处理方式为例,来探究联合式实体识别方法。
1.1 实体数据对象关系
为了掌握实体数据对象之间的关系,简化实体识别工作内容,该文对数据对象之间存在的关联关系进行分析,从中挖掘对象特点信息[3]。
关于数据对象关系的定义:利用有向图来解析数据对象关系,假设有向图为G(O,L),其中L包含于O×O,用于描述语义链接,将这些链接组合到一起,形成的集合就是实体数据关联关系分析依据,O代表对象集合。存在此类映射函数Ψ:L→Γ对象类映射函数ζ,O→N则对于任意一个对象p均存在关系:ζ(p)∈N。其中,p∈O。关于对象语义的描述,均有Ψ(w)∈Γ存在,其中,w∈L,Γ代表所有连接类型的集合,O代表所有对象类型的集合。
通常情况下,利用模式图来表达各个实体数据对象之间的关系[4]。例如,作者、文章、会议之间的关系,用带有箭头的直线来连接各个对象,利用语义关系建立模型方,形成如图1所示的模型。
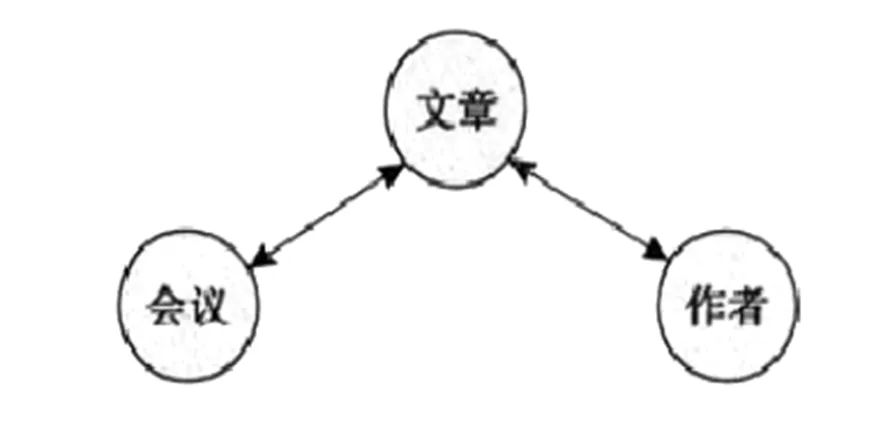
图1 对象关系模型图
图1中,利用双向箭头来描述两个对象之间的关系,分别是“会议与文章”“作者与文章”,通过创建集合,分析映射关系,从而获取数据对象关系。
1.2 GBi-JER工作流程
关于实体数据对象关系分析的方法有很多,其中应用比较多的是GBi-JER[5]。该方法是对图像采取迭代处理后,经过数据收敛统计,建立联合式识别体系。如图2所示为GBi-JER工作流程。
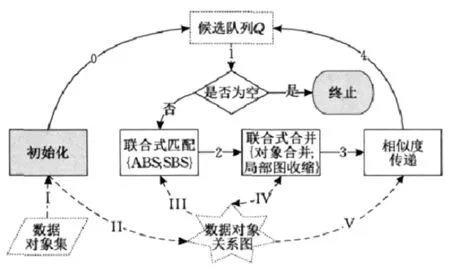
图2 GBi-JER工作流程
图2中,将数据对象集录入到系统中,经过初始化处理后,将其转入候选池中,组成候选队列,记为Q。与此同时,初始化后的数据对象还被发送到数据对象关系图集合中,按照相关步骤执行,分别得到联合式匹配、合并处理对象关系,并为相似度传递提供可靠依据。进入候选队列中的数据对象,需要经过空集判断,才能够达到匹配环节,如果集合非空,则利用SBS和ABS进行联合式匹配,依据数据关系,合并对象,得到局部收缩图,采取相似度传递处理,得到候选队列[6]。按照这个工作流程循环处理图像,直至队列Q为空为止。
1.3 初始化处理
初始化处理作为工作流程的第一步,需要构建多个小型对象图,按照类别不同,将其划分为多个子对象图,采取局部收缩或者合并处理方式,将原始图像融合为一体,通过增加数据对象密度,达到丰富语义的目的[7]。研究选取Canopy分块技术作为处理工具,在对象进入候选队列时,将其拆分为多个对象模块,按照结点不同,排列候选优先顺序,使得实体数据识别更加有序化。
2 关联数据联合式匹配
2.1 联合式匹配函数
假设存在Oi,Oj∈Ot,定义对象的相似度函数,该函数由多个类别数据对象组成,记为simhyb,以下为该函数计算公式:
simhyb(Oi,Oj)=(1-λ)×simabs(Oi,Oj)
+×simsbs(Oi,Oj)
(1)
公式(1)中,Oi,Oj属性相似度为simabs;Oi,Oj结构层面判定的相似度为simsbs;λ代表不同相似度对应的权值分配系数,以相似度重要性作为划分依据,设定具体数值。两种算法中,simabs为基础算法,可以分析属性层面的相似度问题,simsbs建立在simabs基础上,通过分析数据对象结构,计算其相似度。simhyb是将这两种算法融合为一体,形成联合匹配函数,记为GBi-JER。
GBi-JER函数的应用,首先计算Oi,Oj两个数据对象的相似度;其次,将计算结果与匹配阈值进行对比,判断两者之间的大小关系,如果前者大于后者,则认为GBi-JER函数存在相似度,反之,认为该函数不存在相似度。其中,匹配阈值由专家给出。
2.2 基于语义路径的相似度算法
假设两个对象为Oo,Ow∈Omr沿着某语义路径分析两个对象之间存在的关联度,从中挖掘相似度数据对象。其中,语义路径记为sp(Oo,Ow),对应的关联度计算公式为:
con(sp(Oo,Ow))=prht(sp(Oo,Ow))
×con(sch(Oo,Ow))
(2)
公式(2)中,con(sch(Oo,Ow))代表语义路径的关联度,可以将其理解为当前路径对整个语义的重要性。prht(sp(Oo,Ow))代表语义路径中的随机游走概率。
经过关联度分析已经剔除了无关语义路径,缩小了相似性判断范围。接下来,定义语义路径对应的相似度,计算公式如下:
(3)
公式(3)中,len代表路径长度,研究取值上限值为8,从而避免路径过长,加大相似度计算工作量。在计算语义路径相似度时,采用组合处理方式匹配对象,经过语义路径判断,分析是否存在相似性,最终得到两对象是否匹配判断结论。
3 联合式合并与相似度传递
3.1 数据对象合并
该文以属性代表值合并作为实体识别处理方法,将对象合并,而后分别为各个属性设定数值,要求此数值具有一定代表性,能够涵盖相关信息。该处理方法不同于简单的合并方法,它可以同时处理多个数据冲突,经过多趟比较,剔除冲突数据,从而缩小实体识别范围,使得到的结果更加精准。在实际应用中,可以先合并第一趟实体数据,经过一系列比较后,得到比较结果,以此节省存储开销,而后按照此方法,对比第二趟、第三趟实体数据,将得到的对比结果集中到一起,解决数据冲突问题,从而得到准确的计算结果。
3.2 局部图收缩与相似度传递
为了提高实体识别效率,需要去除冗余部分,随机保留其中具有代表性的一条实体数据链路即可。定义两个对象Oi,Oj∈Ot,假设这两个对象数值基本相等,将两者合并起来,设定结点〈Oi,Oj〉。将该结点与两个对象Oi,Oj对应的语义链接建立关联关系,从中剔除冗余语义链接,使得实体识别范围得以缩小。
在经过局部图收缩处理后的实体中,选取相似度较高的实体信息进行传递,使得相似实体得以快速匹配。在候选队列中,新的候选实体插入位置决定了下一步识别工作开展顺序,建立新的对象集。为了提高识别效率,该算法中以相似度估计结果作为传递顺序排列依据,而后利用优先级打分函数,确定相似度传递体系。
定义4个对象Oi,Oj∈Ox,Og,Oh∈Oy,假设前两个对象相似,列入候选队列,并生成匹配对,界定参数x和参数y的取值范围在[1,T]之间,则对象Og,Oh的优先级打分函数如下:
score(Og,Oh)=(1-η)×simcancpy-abs(Og,Oh)+η×con(schp(sp(Oi,Og)))
(4)
公式(4)中,参数Og,Oh均代表对象匹配情况判断的相似度;η代表对象权值分配系数,而语义路径中传递对象的关联度用con(schp(sp(Oi,Og)))表示。
利用上述打分函数,确定实体信息传递优先等级,将其插入到指定位置,以此简化联合式实体识别结构,将复杂的实体识别问题转化为结构简单问题,对数据检验等工作开展帮助较大。
4 联合式实体识别方法在Giteseer数据检验中的应用
4.1 准备工作
该研究根据实体识别方法应用需求,搭建应用实验测试环境。其中,操作系为Windows7,内存8GB,主频3.4GHz,处理器i7-2600。在测试该识别方案可靠性之前,准备Giteseer数据集,将GBi-JER设定为实验组,传统识别方法GJ-3设定为对照组,通过对比两组测试结果,判断GBi-JER实体识别方法是否在相似度识别速率和对象插入完成时间两个方面有所改进。
4.2 识别结果分析
关于相似度识别速率的改进测试,是将两种实体识别方法均投入到Giteseer识别中,观察F-均达到最大值耗用的时间。如果耗用时间越短,则认为该方法识别速率更高一些。如图3所示为识别速率结果。
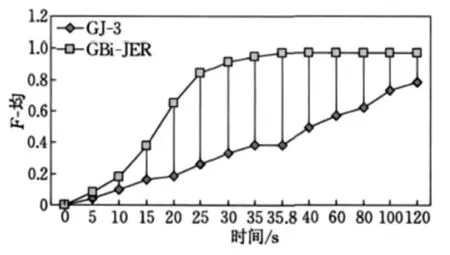
图3 识别速率结果
观察图3中的识别速率结果可知,GBi-JER实体识别方法F-均在35.8s左右达到最大值,而GJ-3识别方法在120s还未出现F-均最大值。
另外,该次应用测试还添加了对象插入完成时间测试项目,测试结果如表1所示。
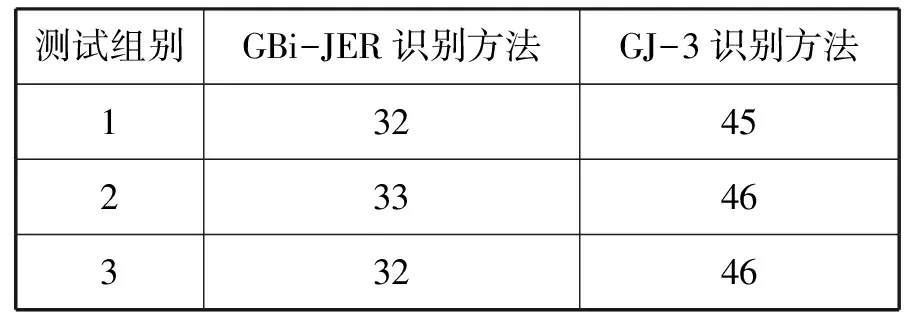
表1 对象插入完成时间统计结果(单位:s)
表1中统计结果显示,GBi-JER识别方法在对象插入完成时间方面表现出较大优势,达到了实体识别改进策略研究要求。
5 总结
为了减少实体识别计算量,该文提出对象相似性分析,依据实体数据之间的关联关系,展开对象之间的相似性判断分析,并收缩局部图,经过相似度传递,确定联合式实体最佳识别体系。应用测试结果显示,该文提出的GBi-JER方法识别速率较高,对象插入完成耗费的时间更少,可以作为实体识别的有效工具。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
汽车工程(2021年12期)2021-03-08
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
青年文学家(2016年32期)2016-12-23
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
